 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCCSBench: Evaluating Compositional Controllability in LLMs for Scientific Document Summarization
Oct 16, 2024



To broaden the dissemination of scientific knowledge to diverse audiences, scientific document summarization must simultaneously control multiple attributes such as length and empirical focus. However, existing research typically focuses on controlling single attributes, leaving the compositional control of multiple attributes underexplored. To address this gap, we introduce CCSBench, a benchmark for compositional controllable summarization in the scientific domain. Our benchmark enables fine-grained control over both explicit attributes (e.g., length), which are objective and straightforward, and implicit attributes (e.g., empirical focus), which are more subjective and conceptual. We conduct extensive experiments on GPT-4, LLaMA2, and other popular LLMs under various settings. Our findings reveal significant limitations in large language models' ability to balance trade-offs between control attributes, especially implicit ones that require deeper understanding and abstract reasoning.
A Fundamental Trade-off in Aligned Language Models and its Relation to Sampling Adaptors
Jun 14, 2024



The relationship between the quality of a string and its probability $p(\boldsymbol{y})$ under a language model has been influential in the development of techniques to build good text generation systems. For example, several decoding algorithms have been motivated to manipulate $p(\boldsymbol{y})$ to produce higher-quality text. In this work, we examine the probability--quality relationship in language models explicitly aligned to human preferences, e.g., through Reinforcement Learning through Human Feedback (RLHF). We find that, given a general language model and its aligned version, for corpora sampled from an aligned language model, there exists a trade-off between the average reward and average log-likelihood of the strings under the general language model. We provide a formal treatment of this issue and demonstrate how a choice of sampling adaptor allows for a selection of how much likelihood we exchange for the reward.
ISQA: Informative Factuality Feedback for Scientific Summarization
Apr 20, 2024



We propose Iterative Facuality Refining on Informative Scientific Question-Answering (ISQA) feedback\footnote{Code is available at \url{https://github.com/lizekai-richard/isqa}}, a method following human learning theories that employs model-generated feedback consisting of both positive and negative information. Through iterative refining of summaries, it probes for the underlying rationale of statements to enhance the factuality of scientific summarization. ISQA does this in a fine-grained manner by asking a summarization agent to reinforce validated statements in positive feedback and fix incorrect ones in negative feedback. Our findings demonstrate that the ISQA feedback mechanism significantly improves the factuality of various open-source LLMs on the summarization task, as evaluated across multiple scientific datasets.
The ACL OCL Corpus: advancing Open science in Computational Linguistics
May 24, 2023



We present a scholarly corpus from the ACL Anthology to assist Open scientific research in the Computational Linguistics domain, named as ACL OCL. Compared with previous ARC and AAN versions, ACL OCL includes structured full-texts with logical sections, references to figures, and links to a large knowledge resource (semantic scholar). ACL OCL contains 74k scientific papers, together with 210k figures extracted up to September 2022. To observe the development in the computational linguistics domain, we detect the topics of all OCL papers with a supervised neural model. We observe ''Syntax: Tagging, Chunking and Parsing'' topic is significantly shrinking and ''Natural Language Generation'' is resurging. Our dataset is open and available to download from HuggingFace in https://huggingface.co/datasets/ACL-OCL/ACL-OCL-Corpus.
Challenges for Open-domain Targeted Sentiment Analysis
Apr 15, 2022
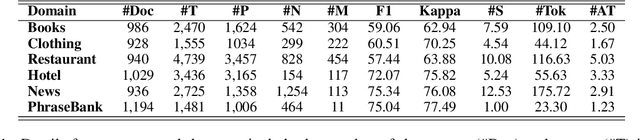
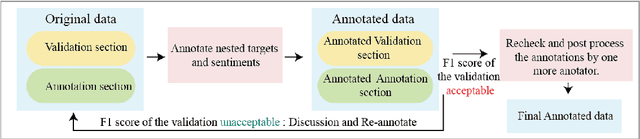
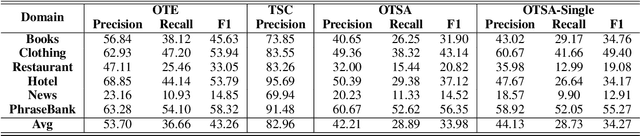
Since previous studies on open-domain targeted sentiment analysis are limited in dataset domain variety and sentence level, we propose a novel dataset consisting of 6,013 human-labeled data to extend the data domains in topics of interest and document level. Furthermore, we offer a nested target annotation schema to extract the complete sentiment information in documents, boosting the practicality and effectiveness of open-domain targeted sentiment analysis. Moreover, we leverage the pre-trained model BART in a sequence-to-sequence generation method for the task. Benchmark results show that there exists large room for improvement of open-domain targeted sentiment analysis. Meanwhile, experiments have shown that challenges remain in the effective use of open-domain data, long documents, the complexity of target structure, and domain variances.