 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLikelihood-Based Reward Designs for General LLM Reasoning
Feb 03, 2026Fine-tuning large language models (LLMs) on reasoning benchmarks via reinforcement learning requires a specific reward function, often binary, for each benchmark. This comes with two potential limitations: the need to design the reward, and the potentially sparse nature of binary rewards. Here, we systematically investigate rewards derived from the probability or log-probability of emitting the reference answer (or any other prompt continuation present in the data), which have the advantage of not relying on specific verifiers and being available at scale. Several recent works have advocated for the use of similar rewards (e.g., VeriFree, JEPO, RLPR, NOVER). We systematically compare variants of likelihood-based rewards with standard baselines, testing performance both on standard mathematical reasoning benchmarks, and on long-form answers where no external verifier is available. We find that using the log-probability of the reference answer as the reward for chain-of-thought (CoT) learning is the only option that performs well in all setups. This reward is also consistent with the next-token log-likelihood loss used during pretraining. In verifiable settings, log-probability rewards bring comparable or better success rates than reinforcing with standard binary rewards, and yield much better perplexity. In non-verifiable settings, they perform on par with SFT. On the other hand, methods based on probability, such as VeriFree, flatline on non-verifiable settings due to vanishing probabilities of getting the correct answer. Overall, this establishes log-probability rewards as a viable method for CoT fine-tuning, bridging the short, verifiable and long, non-verifiable answer settings.
Teaching Models to Teach Themselves: Reasoning at the Edge of Learnability
Jan 26, 2026Can a model learn to escape its own learning plateau? Reinforcement learning methods for finetuning large reasoning models stall on datasets with low initial success rates, and thus little training signal. We investigate a fundamental question: Can a pretrained LLM leverage latent knowledge to generate an automated curriculum for problems it cannot solve? To explore this, we design SOAR: A self-improvement framework designed to surface these pedagogical signals through meta-RL. A teacher copy of the model proposes synthetic problems for a student copy, and is rewarded with its improvement on a small subset of hard problems. Critically, SOAR grounds the curriculum in measured student progress rather than intrinsic proxy rewards. Our study on the hardest subsets of mathematical benchmarks (0/128 success) reveals three core findings. First, we show that it is possible to realize bi-level meta-RL that unlocks learning under sparse, binary rewards by sharpening a latent capacity of pretrained models to generate useful stepping stones. Second, grounded rewards outperform intrinsic reward schemes used in prior LLM self-play, reliably avoiding the instability and diversity collapse modes they typically exhibit. Third, analyzing the generated questions reveals that structural quality and well-posedness are more critical for learning progress than solution correctness. Our results suggest that the ability to generate useful stepping stones does not require the preexisting ability to actually solve the hard problems, paving a principled path to escape reasoning plateaus without additional curated data.
Finer Behavioral Foundation Models via Auto-Regressive Features and Advantage Weighting
Dec 05, 2024



The forward-backward representation (FB) is a recently proposed framework (Touati et al., 2023; Touati & Ollivier, 2021) to train behavior foundation models (BFMs) that aim at providing zero-shot efficient policies for any new task specified in a given reinforcement learning (RL) environment, without training for each new task. Here we address two core limitations of FB model training. First, FB, like all successor-feature-based methods, relies on a linear encoding of tasks: at test time, each new reward function is linearly projected onto a fixed set of pre-trained features. This limits expressivity as well as precision of the task representation. We break the linearity limitation by introducing auto-regressive features for FB, which let finegrained task features depend on coarser-grained task information. This can represent arbitrary nonlinear task encodings, thus significantly increasing expressivity of the FB framework. Second, it is well-known that training RL agents from offline datasets often requires specific techniques.We show that FB works well together with such offline RL techniques, by adapting techniques from (Nair et al.,2020b; Cetin et al., 2024) for FB. This is necessary to get non-flatlining performance in some datasets, such as DMC Humanoid. As a result, we produce efficient FB BFMs for a number of new environments. Notably, in the D4RL locomotion benchmark, the generic FB agent matches the performance of standard single-task offline agents (IQL, XQL). In many setups, the offline techniques are needed to get any decent performance at all. The auto-regressive features have a positive but moderate impact, concentrated on tasks requiring spatial precision and task generalization beyond the behaviors represented in the trainset.
Simple Ingredients for Offline Reinforcement Learning
Mar 19, 2024



Offline reinforcement learning algorithms have proven effective on datasets highly connected to the target downstream task. Yet, leveraging a novel testbed (MOOD) in which trajectories come from heterogeneous sources, we show that existing methods struggle with diverse data: their performance considerably deteriorates as data collected for related but different tasks is simply added to the offline buffer. In light of this finding, we conduct a large empirical study where we formulate and test several hypotheses to explain this failure. Surprisingly, we find that scale, more than algorithmic considerations, is the key factor influencing performance. We show that simple methods like AWAC and IQL with increased network size overcome the paradoxical failure modes from the inclusion of additional data in MOOD, and notably outperform prior state-of-the-art algorithms on the canonical D4RL benchmark.
Does Zero-Shot Reinforcement Learning Exist?
Sep 29, 2022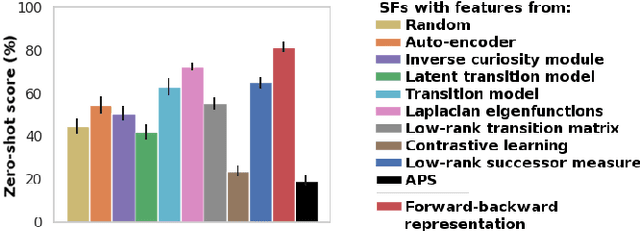

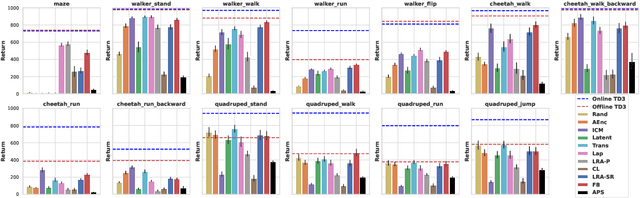
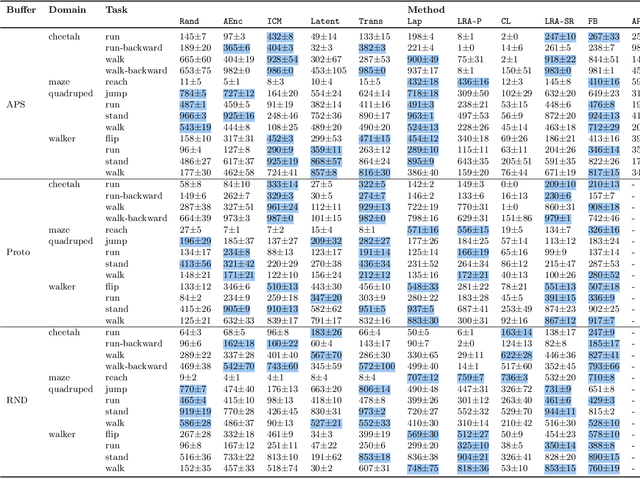
A zero-shot RL agent is an agent that can solve any RL task in a given environment, instantly with no additional planning or learning, after an initial reward-free learning phase. This marks a shift from the reward-centric RL paradigm towards "controllable" agents that can follow arbitrary instructions in an environment. Current RL agents can solve families of related tasks at best, or require planning anew for each task. Strategies for approximate zero-shot RL ave been suggested using successor features (SFs) [BBQ+ 18] or forward-backward (FB) representations [TO21], but testing has been limited. After clarifying the relationships between these schemes, we introduce improved losses and new SF models, and test the viability of zero-shot RL schemes systematically on tasks from the Unsupervised RL benchmark [LYL+21]. To disentangle universal representation learning from exploration, we work in an offline setting and repeat the tests on several existing replay buffers. SFs appear to suffer from the choice of the elementary state features. SFs with Laplacian eigenfunctions do well, while SFs based on auto-encoders, inverse curiosity, transition models, low-rank transition matrix, contrastive learning, or diversity (APS), perform unconsistently. In contrast, FB representations jointly learn the elementary and successor features from a single, principled criterion. They perform best and consistently across the board, reaching 85% of supervised RL performance with a good replay buffer, in a zero-shot manner.
Agnostic Physics-Driven Deep Learning
May 30, 2022
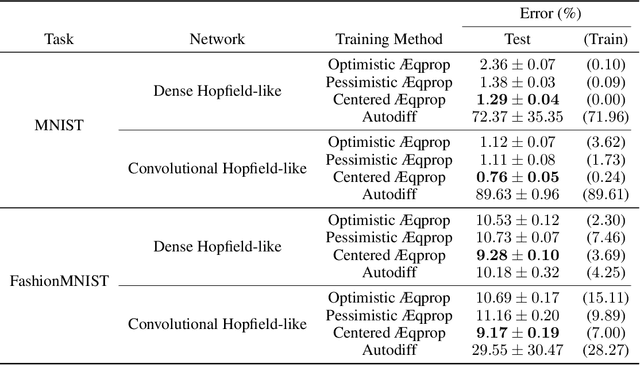

This work establishes that a physical system can perform statistical learning without gradient computations, via an Agnostic Equilibrium Propagation (Aeqprop) procedure that combines energy minimization, homeostatic control, and nudging towards the correct response. In Aeqprop, the specifics of the system do not have to be known: the procedure is based only on external manipulations, and produces a stochastic gradient descent without explicit gradient computations. Thanks to nudging, the system performs a true, order-one gradient step for each training sample, in contrast with order-zero methods like reinforcement or evolutionary strategies, which rely on trial and error. This procedure considerably widens the range of potential hardware for statistical learning to any system with enough controllable parameters, even if the details of the system are poorly known. Aeqprop also establishes that in natural (bio)physical systems, genuine gradient-based statistical learning may result from generic, relatively simple mechanisms, without backpropagation and its requirement for analytic knowledge of partial derivatives.
Unbiased Methods for Multi-Goal Reinforcement Learning
Jun 16, 2021
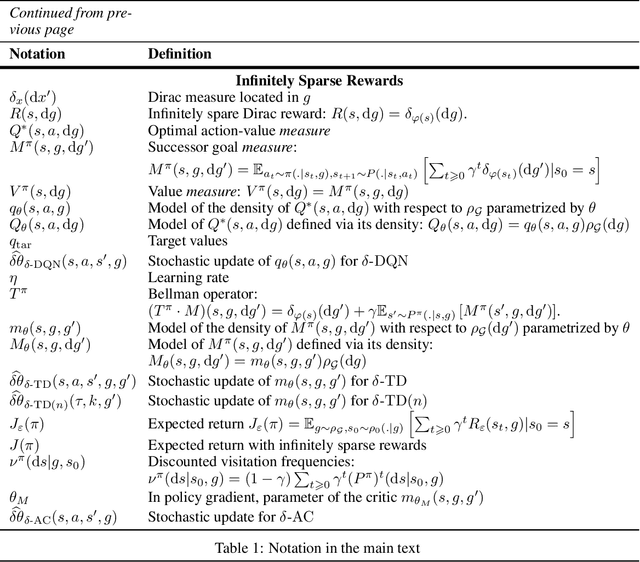
In multi-goal reinforcement learning (RL) settings, the reward for each goal is sparse, and located in a small neighborhood of the goal. In large dimension, the probability of reaching a reward vanishes and the agent receives little learning signal. Methods such as Hindsight Experience Replay (HER) tackle this issue by also learning from realized but unplanned-for goals. But HER is known to introduce bias, and can converge to low-return policies by overestimating chancy outcomes. First, we vindicate HER by proving that it is actually unbiased in deterministic environments, such as many optimal control settings. Next, for stochastic environments in continuous spaces, we tackle sparse rewards by directly taking the infinitely sparse reward limit. We fully formalize the problem of multi-goal RL with infinitely sparse Dirac rewards at each goal. We introduce unbiased deep Q-learning and actor-critic algorithms that can handle such infinitely sparse rewards, and test them in toy environments.
Learning One Representation to Optimize All Rewards
Mar 14, 2021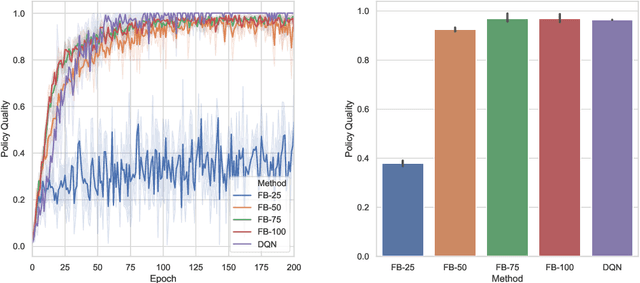
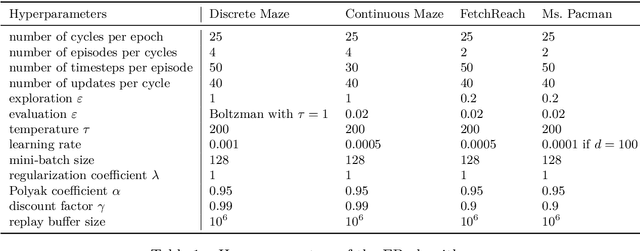
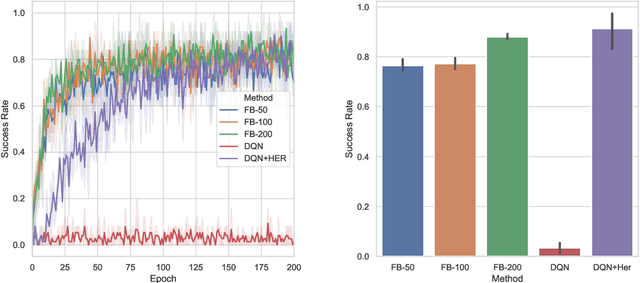
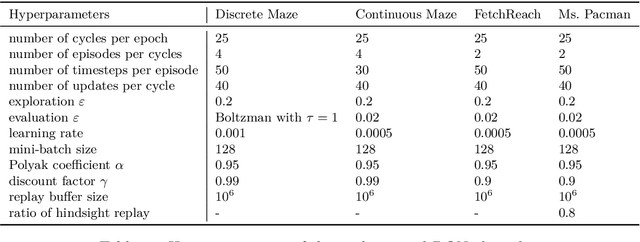
We introduce the forward-backward (FB) representation of the dynamics of a reward-free Markov decision process. It provides explicit near-optimal policies for any reward specified a posteriori. During an unsupervised phase, we use reward-free interactions with the environment to learn two representations via off-the-shelf deep learning methods and temporal difference (TD) learning. In the test phase, a reward representation is estimated either from observations or an explicit reward description (e.g., a target state). The optimal policy for that reward is directly obtained from these representations, with no planning. The unsupervised FB loss is well-principled: if training is perfect, the policies obtained are provably optimal for any reward function. With imperfect training, the sub-optimality is proportional to the unsupervised approximation error. The FB representation learns long-range relationships between states and actions, via a predictive occupancy map, without having to synthesize states as in model-based approaches. This is a step towards learning controllable agents in arbitrary black-box stochastic environments. This approach compares well to goal-oriented RL algorithms on discrete and continuous mazes, pixel-based MsPacman, and the FetchReach virtual robot arm. We also illustrate how the agent can immediately adapt to new tasks beyond goal-oriented RL.
Learning Successor States and Goal-Dependent Values: A Mathematical Viewpoint
Jan 18, 2021
In reinforcement learning, temporal difference-based algorithms can be sample-inefficient: for instance, with sparse rewards, no learning occurs until a reward is observed. This can be remedied by learning richer objects, such as a model of the environment, or successor states. Successor states model the expected future state occupancy from any given state for a given policy and are related to goal-dependent value functions, which learn how to reach arbitrary states. We formally derive the temporal difference algorithm for successor state and goal-dependent value function learning, either for discrete or for continuous environments with function approximation. Especially, we provide finite-variance estimators even in continuous environments, where the reward for exactly reaching a goal state becomes infinitely sparse. Successor states satisfy more than just the Bellman equation: a backward Bellman operator and a Bellman-Newton (BN) operator encode path compositionality in the environment. The BN operator is akin to second-order gradient descent methods and provides the true update of the value function when acquiring more observations, with explicit tabular bounds. In the tabular case and with infinitesimal learning rates, mixing the usual and backward Bellman operators provably improves eigenvalues for asymptotic convergence, and the asymptotic convergence of the BN operator is provably better than TD, with a rate independent from the environment. However, the BN method is more complex and less robust to sampling noise. Finally, a forward-backward (FB) finite-rank parameterization of successor states enjoys reduced variance and improved samplability, provides a direct model of the value function, has fully understood fixed points corresponding to long-range dependencies, approximates the BN method, and provides two canonical representations of states as a byproduct.
Convergence of Online Adaptive and Recurrent Optimization Algorithms
May 12, 2020We prove local convergence of several notable gradient descentalgorithms used inmachine learning, for which standard stochastic gradient descent theorydoes not apply. This includes, first, online algorithms for recurrent models and dynamicalsystems, such as \emph{Real-time recurrent learning} (RTRL) and its computationally lighter approximations NoBackTrack and UORO; second,several adaptive algorithms such as RMSProp, online natural gradient, and Adam with $\beta^2\to 1$.Despite local convergence being a relatively weak requirement for a newoptimization algorithm, no local analysis was available for these algorithms, as far aswe knew. Analysis of these algorithms does not immediately followfrom standard stochastic gradient (SGD) theory. In fact, Adam has been provedto lack local convergence in some simple situations. For recurrent models, online algorithms modify the parameterwhile the model is running, which further complicates the analysis withrespect to simple SGD.Local convergence for these various algorithms results from a single,more general set of assumptions, in the setup of learning dynamicalsystems online. Thus, these results can cover other variants ofthe algorithms considered.We adopt an ``ergodic'' rather than probabilistic viewpoint, working withempirical time averages instead of probability distributions. This ismore data-agnostic andcreates differences with respect to standard SGD theory,especially for the range of possible learning rates. For instance, withcycling or per-epoch reshuffling over a finite dataset instead of purei.i.d. sampling with replacement, empiricalaverages of gradients converge at rate $1/T$ insteadof $1/\sqrt{T}$ (cycling acts as a variance reduction method),theoretically allowingfor larger learning rates than in SGD.