 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-augmented Data Selection for Few-shot Dialogue Generation
May 19, 2022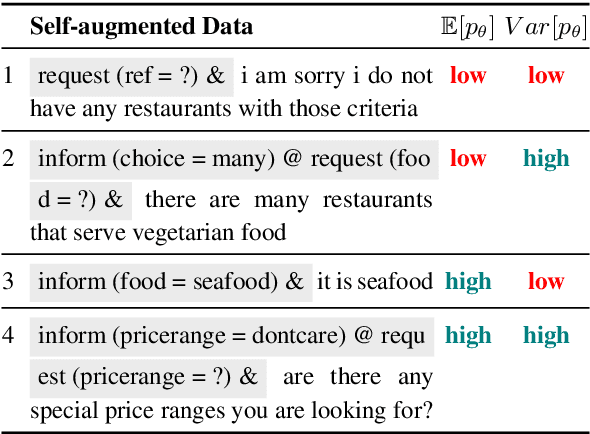
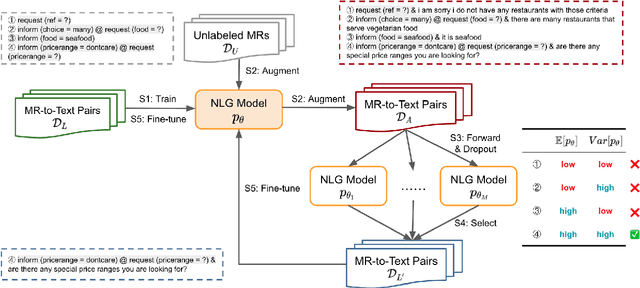

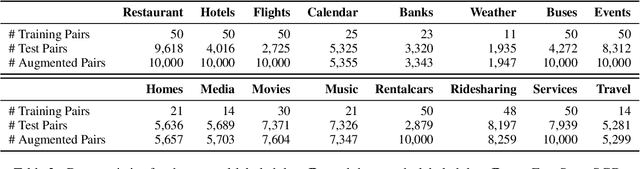
The natural language generation (NLG) module in task-oriented dialogue systems translates structured meaning representations (MRs) into text responses, which has a great impact on users' experience as the human-machine interaction interface. However, in practice, developers often only have a few well-annotated data and confront a high data collection cost to build the NLG module. In this work, we adopt the self-training framework to deal with the few-shot MR-to-Text generation problem. We leverage the pre-trained language model to self-augment many pseudo-labeled data. To prevent the gradual drift from target data distribution to noisy augmented data distribution, we propose a novel data selection strategy to select the data that our generation model is most uncertain about. Compared with existing data selection methods, our method is: (1) parameter-efficient, which does not require training any additional neural models, (2) computation-efficient, which only needs to apply several stochastic forward passes of the model to estimate the uncertainty. We conduct empirical experiments on two benchmark datasets: FewShotWOZ and FewShotSGD, and show that our proposed framework consistently outperforms other baselines in terms of BLEU and ERR.
White-box Testing of NLP models with Mask Neuron Coverage
May 10, 2022
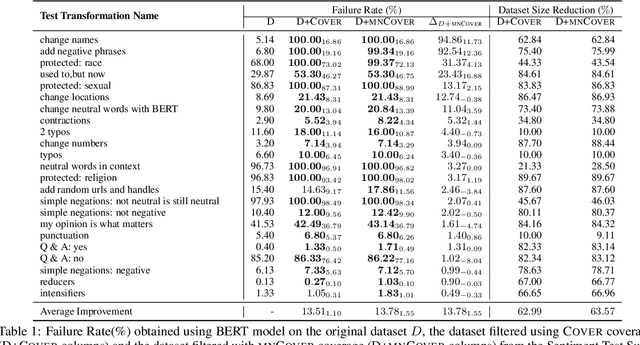
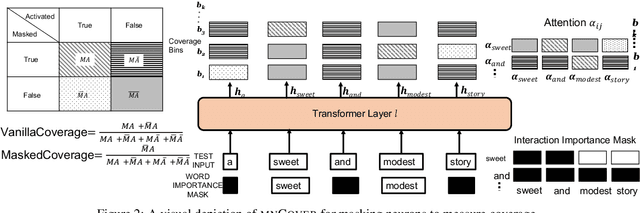
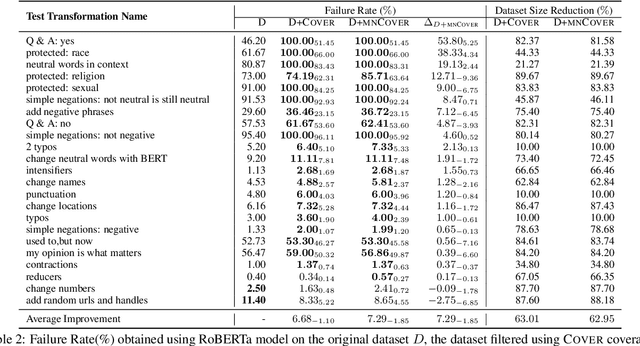
Recent literature has seen growing interest in using black-box strategies like CheckList for testing the behavior of NLP models. Research on white-box testing has developed a number of methods for evaluating how thoroughly the internal behavior of deep models is tested, but they are not applicable to NLP models. We propose a set of white-box testing methods that are customized for transformer-based NLP models. These include Mask Neuron Coverage (MNCOVER) that measures how thoroughly the attention layers in models are exercised during testing. We show that MNCOVER can refine testing suites generated by CheckList by substantially reduce them in size, for more than 60\% on average, while retaining failing tests -- thereby concentrating the fault detection power of the test suite. Further we show how MNCOVER can be used to guide CheckList input generation, evaluate alternative NLP testing methods, and drive data augmentation to improve accuracy.
* Findings of NAACL 2022 submission, 12 pages
Pathologies of Pre-trained Language Models in Few-shot Fine-tuning
Apr 17, 2022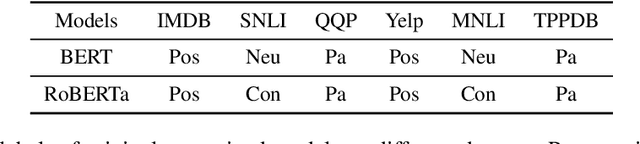
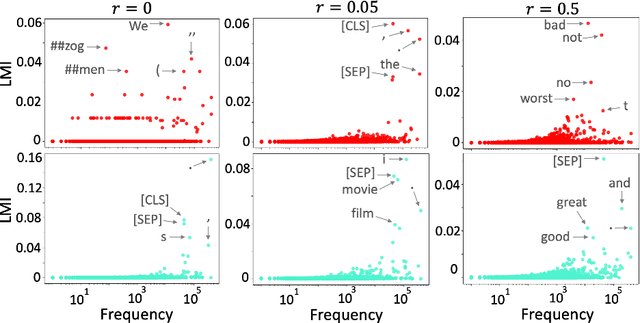
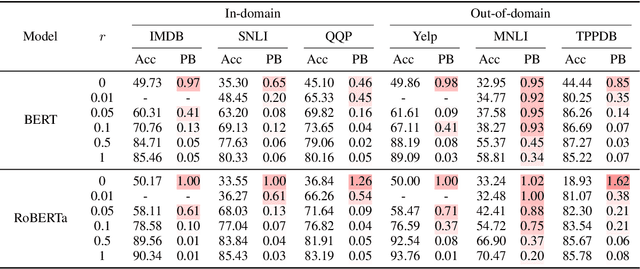
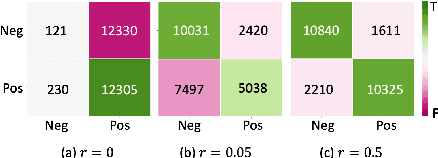
Although adapting pre-trained language models with few examples has shown promising performance on text classification, there is a lack of understanding of where the performance gain comes from. In this work, we propose to answer this question by interpreting the adaptation behavior using post-hoc explanations from model predictions. By modeling feature statistics of explanations, we discover that (1) without fine-tuning, pre-trained models (e.g. BERT and RoBERTa) show strong prediction bias across labels; (2) although few-shot fine-tuning can mitigate the prediction bias and demonstrate promising prediction performance, our analysis shows models gain performance improvement by capturing non-task-related features (e.g. stop words) or shallow data patterns (e.g. lexical overlaps). These observations alert that pursuing model performance with fewer examples may incur pathological prediction behavior, which requires further sanity check on model predictions and careful design in model evaluations in few-shot fine-tuning.
Diverse Text Generation via Variational Encoder-Decoder Models with Gaussian Process Priors
Apr 04, 2022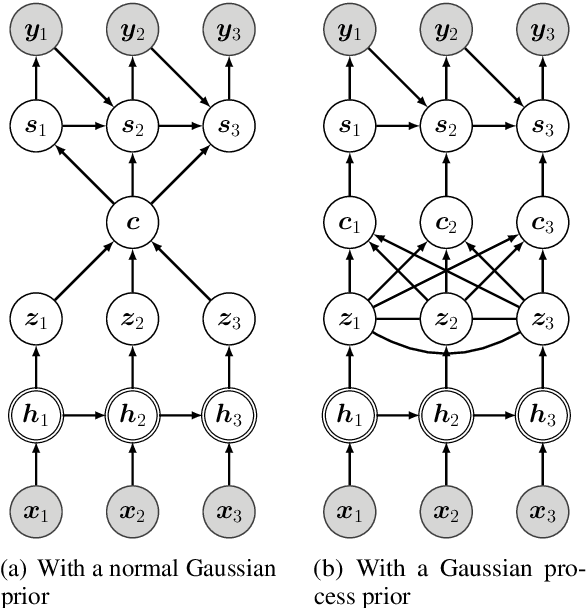

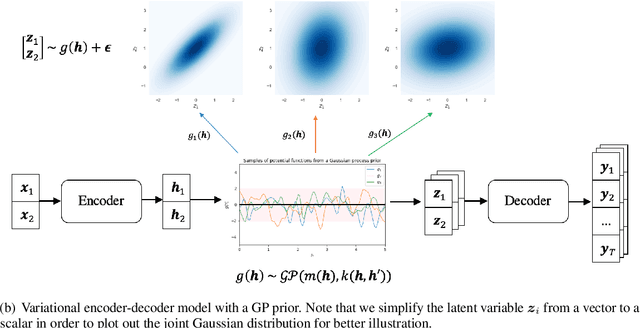
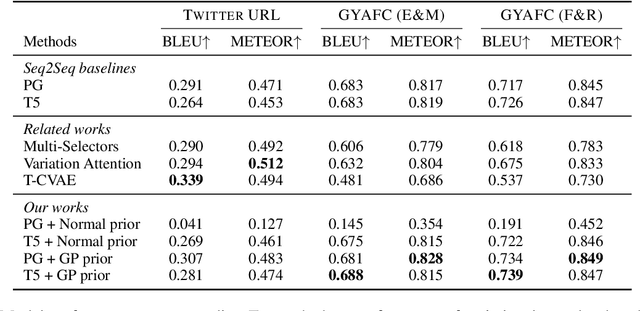
Generating high quality texts with high diversity is important for many NLG applications, but current methods mostly focus on building deterministic models to generate higher quality texts and do not provide many options for promoting diversity. In this work, we present a novel latent structured variable model to generate high quality texts by enriching contextual representation learning of encoder-decoder models. Specifically, we introduce a stochastic function to map deterministic encoder hidden states into random context variables. The proposed stochastic function is sampled from a Gaussian process prior to (1) provide infinite number of joint Gaussian distributions of random context variables (diversity-promoting) and (2) explicitly model dependency between context variables (accurate-encoding). To address the learning challenge of Gaussian processes, we propose an efficient variational inference approach to approximate the posterior distribution of random context variables. We evaluate our method in two typical text generation tasks: paraphrase generation and text style transfer. Experimental results on benchmark datasets demonstrate that our method improves the generation quality and diversity compared with other baselines.
Adversarial Training for Improving Model Robustness? Look at Both Prediction and Interpretation
Mar 23, 2022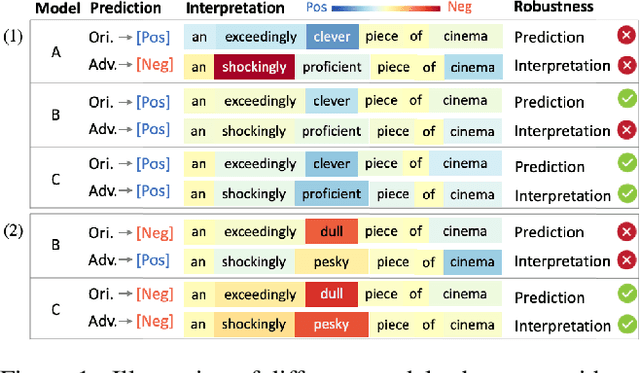
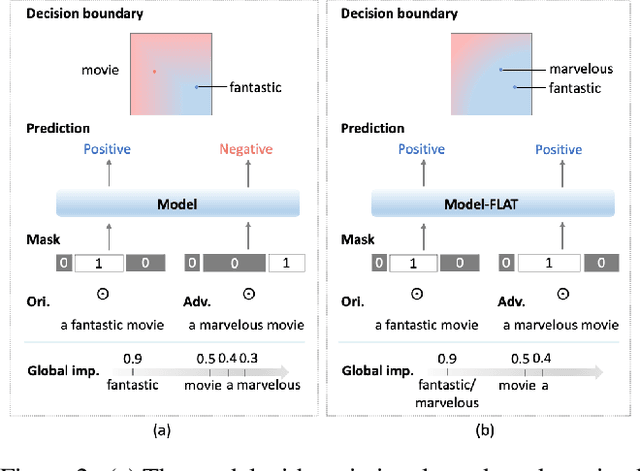
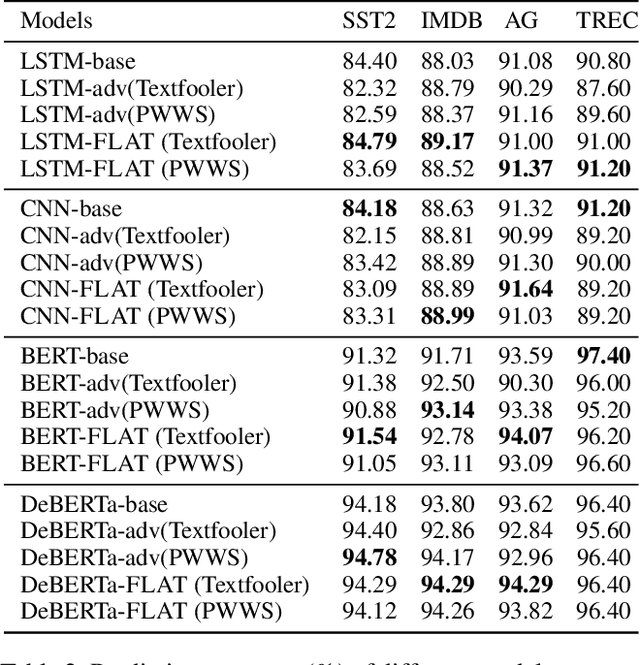
Neural language models show vulnerability to adversarial examples which are semantically similar to their original counterparts with a few words replaced by their synonyms. A common way to improve model robustness is adversarial training which follows two steps-collecting adversarial examples by attacking a target model, and fine-tuning the model on the augmented dataset with these adversarial examples. The objective of traditional adversarial training is to make a model produce the same correct predictions on an original/adversarial example pair. However, the consistency between model decision-makings on two similar texts is ignored. We argue that a robust model should behave consistently on original/adversarial example pairs, that is making the same predictions (what) based on the same reasons (how) which can be reflected by consistent interpretations. In this work, we propose a novel feature-level adversarial training method named FLAT. FLAT aims at improving model robustness in terms of both predictions and interpretations. FLAT incorporates variational word masks in neural networks to learn global word importance and play as a bottleneck teaching the model to make predictions based on important words. FLAT explicitly shoots at the vulnerability problem caused by the mismatch between model understandings on the replaced words and their synonyms in original/adversarial example pairs by regularizing the corresponding global word importance scores. Experiments show the effectiveness of FLAT in improving the robustness with respect to both predictions and interpretations of four neural network models (LSTM, CNN, BERT, and DeBERTa) to two adversarial attacks on four text classification tasks. The models trained via FLAT also show better robustness than baseline models on unforeseen adversarial examples across different attacks.
FlowEval: A Consensus-Based Dialogue Evaluation Framework Using Segment Act Flows
Feb 14, 2022Despite recent progress in open-domain dialogue evaluation, how to develop automatic metrics remains an open problem. We explore the potential of dialogue evaluation featuring dialog act information, which was hardly explicitly modeled in previous methods. However, defined at the utterance level in general, dialog act is of coarse granularity, as an utterance can contain multiple segments possessing different functions. Hence, we propose segment act, an extension of dialog act from utterance level to segment level, and crowdsource a large-scale dataset for it. To utilize segment act flows, sequences of segment acts, for evaluation, we develop the first consensus-based dialogue evaluation framework, FlowEval. This framework provides a reference-free approach for dialog evaluation by finding pseudo-references. Extensive experiments against strong baselines on three benchmark datasets demonstrate the effectiveness and other desirable characteristics of our FlowEval, pointing out a potential path for better dialogue evaluation.
Explaining Prediction Uncertainty of Pre-trained Language Models by Detecting Uncertain Words in Inputs
Jan 11, 2022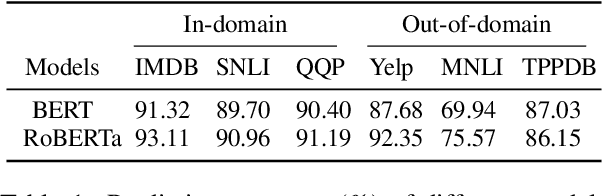
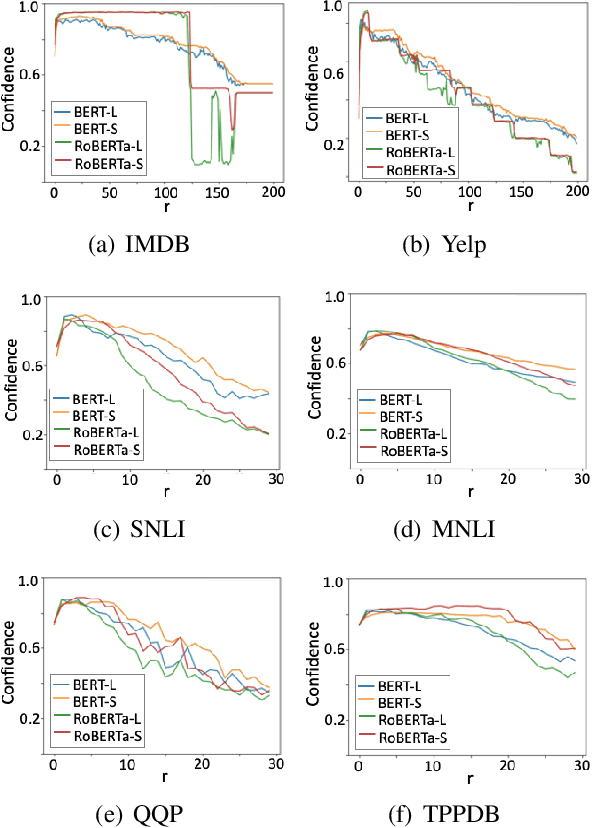

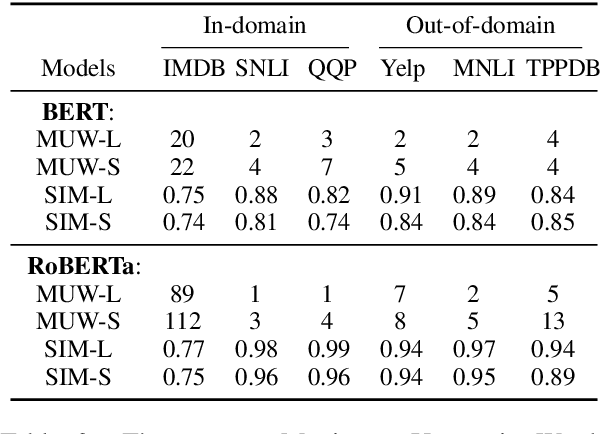
Estimating the predictive uncertainty of pre-trained language models is important for increasing their trustworthiness in NLP. Although many previous works focus on quantifying prediction uncertainty, there is little work on explaining the uncertainty. This paper pushes a step further on explaining uncertain predictions of post-calibrated pre-trained language models. We adapt two perturbation-based post-hoc interpretation methods, Leave-one-out and Sampling Shapley, to identify words in inputs that cause the uncertainty in predictions. We test the proposed methods on BERT and RoBERTa with three tasks: sentiment classification, natural language inference, and paraphrase identification, in both in-domain and out-of-domain settings. Experiments show that both methods consistently capture words in inputs that cause prediction uncertainty.
Simple Text Detoxification by Identifying a Linear Toxic Subspace in Language Model Embeddings
Dec 15, 2021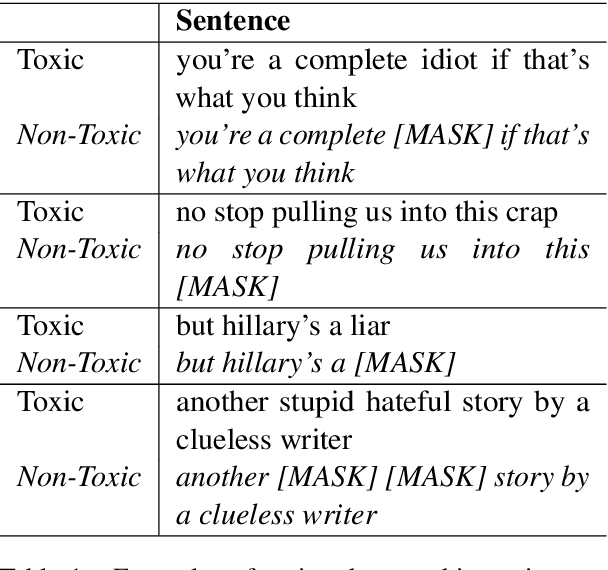
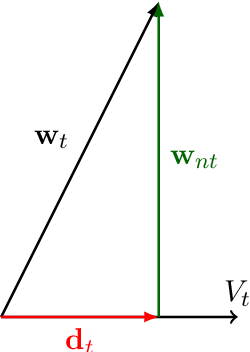
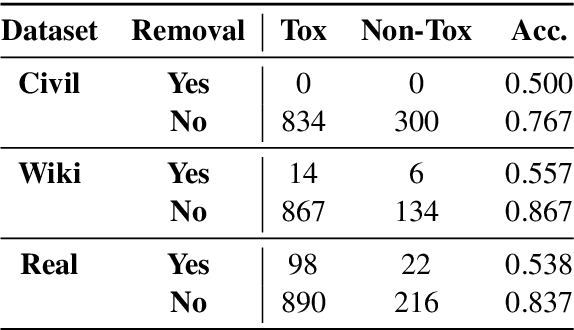
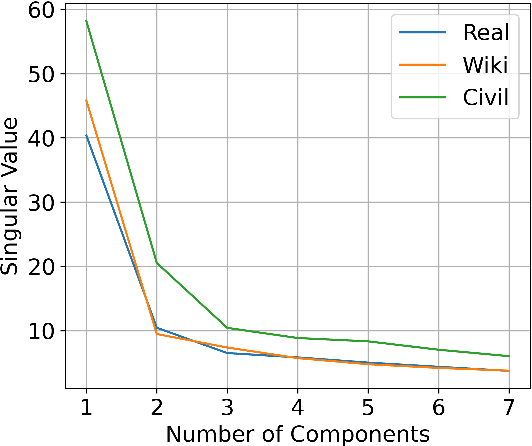
Large pre-trained language models are often trained on large volumes of internet data, some of which may contain toxic or abusive language. Consequently, language models encode toxic information, which makes the real-world usage of these language models limited. Current methods aim to prevent toxic features from appearing generated text. We hypothesize the existence of a low-dimensional toxic subspace in the latent space of pre-trained language models, the existence of which suggests that toxic features follow some underlying pattern and are thus removable. To construct this toxic subspace, we propose a method to generalize toxic directions in the latent space. We also provide a methodology for constructing parallel datasets using a context based word masking system. Through our experiments, we show that when the toxic subspace is removed from a set of sentence representations, almost no toxic representations remain in the result. We demonstrate empirically that the subspace found using our method generalizes to multiple toxicity corpora, indicating the existence of a low-dimensional toxic subspace.
SideControl: Controlled Open-domain Dialogue Generation via Additive Side Networks
Sep 05, 2021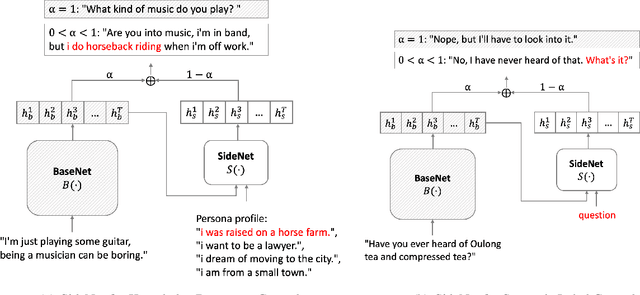
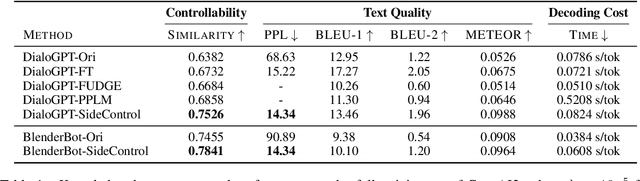
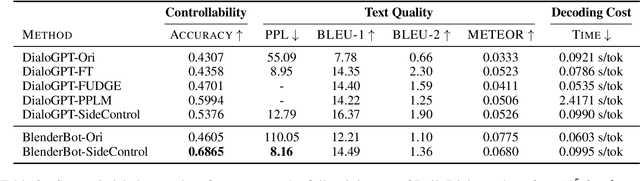
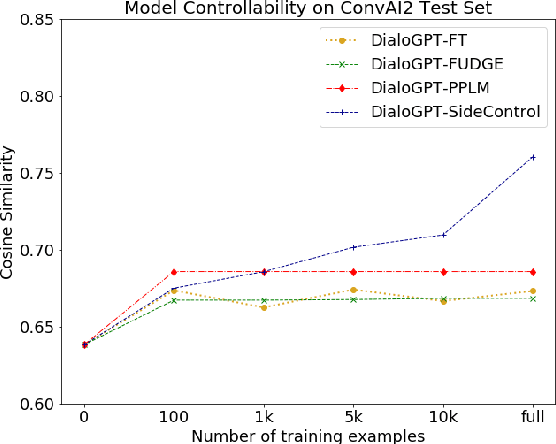
Transformer-based pre-trained language models boost the performance of open-domain dialogue systems. Prior works leverage Transformer-based pre-trained language models to generate texts with desired attributes in two general approaches: (1) gradient-based methods: updating all latent representations of pre-trained models with gradients from attribute models; (2) weighted-decoding methods: re-ranking beam candidates from pre-trained models with attribute functions. However, gradient-based methods lead to high computation cost and can easily get overfitted on small training sets, while weighted-decoding methods are inherently constrained by the low-variance high-bias pre-trained model. In this work, we propose a novel approach to control the generation of Transformer-based pre-trained language models: the SideControl framework, which leverages a novel control attributes loss to incorporate useful control signals, and is shown to perform well with very limited training samples. We evaluate our proposed method on two benchmark open-domain dialogue datasets, and results show that the SideControl framework has better controllability, higher generation quality and better sample-efficiency than existing gradient-based and weighted-decoding baselines.
Contextualizing Variation in Text Style Transfer Datasets
Aug 17, 2021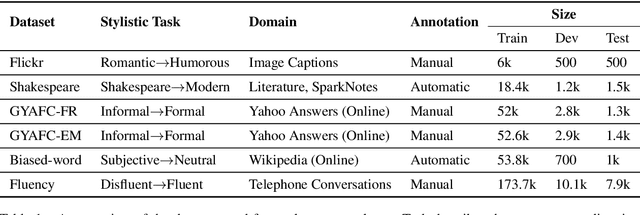

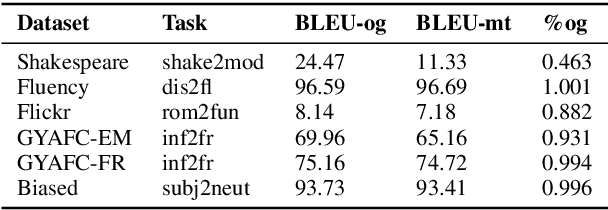
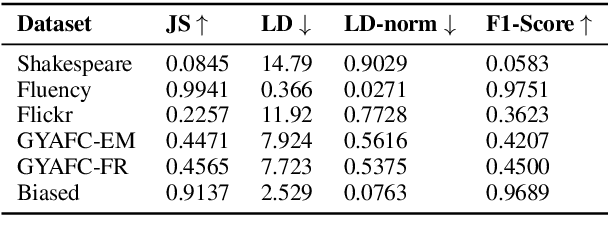
Text style transfer involves rewriting the content of a source sentence in a target style. Despite there being a number of style tasks with available data, there has been limited systematic discussion of how text style datasets relate to each other. This understanding, however, is likely to have implications for selecting multiple data sources for model training. While it is prudent to consider inherent stylistic properties when determining these relationships, we also must consider how a style is realized in a particular dataset. In this paper, we conduct several empirical analyses of existing text style datasets. Based on our results, we propose a categorization of stylistic and dataset properties to consider when utilizing or comparing text style datasets.