 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViterbi Decoding of Directed Acyclic Transformer for Non-Autoregressive Machine Translation
Oct 11, 2022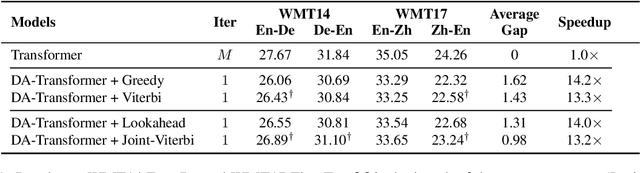
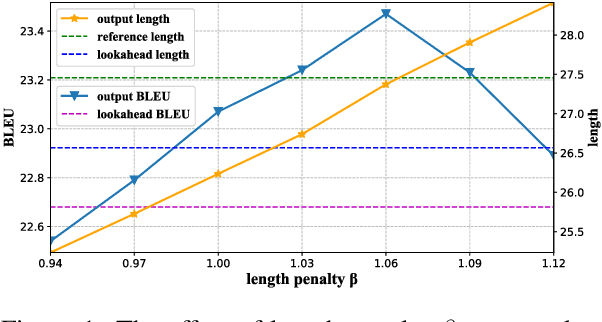
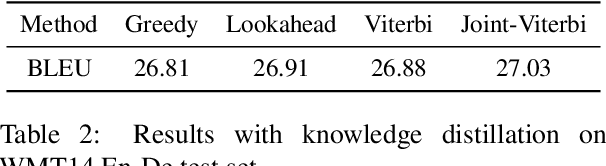
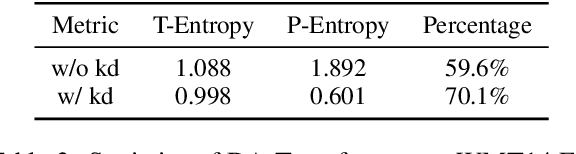
Non-autoregressive models achieve significant decoding speedup in neural machine translation but lack the ability to capture sequential dependency. Directed Acyclic Transformer (DA-Transformer) was recently proposed to model sequential dependency with a directed acyclic graph. Consequently, it has to apply a sequential decision process at inference time, which harms the global translation accuracy. In this paper, we present a Viterbi decoding framework for DA-Transformer, which guarantees to find the joint optimal solution for the translation and decoding path under any length constraint. Experimental results demonstrate that our approach consistently improves the performance of DA-Transformer while maintaining a similar decoding speedup.
Non-Monotonic Latent Alignments for CTC-Based Non-Autoregressive Machine Translation
Oct 08, 2022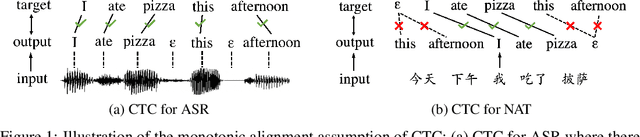
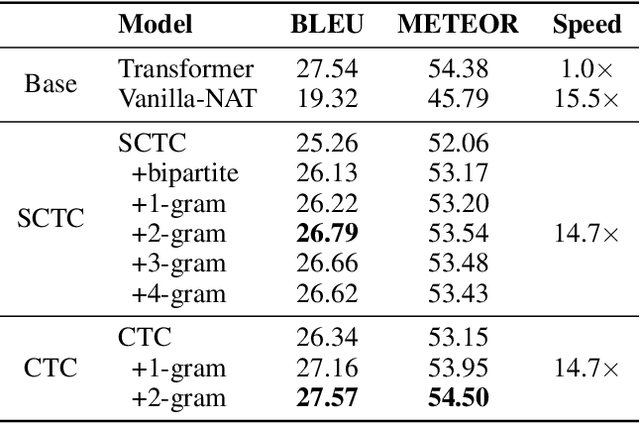
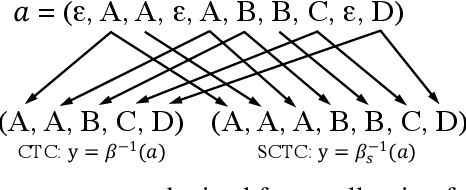
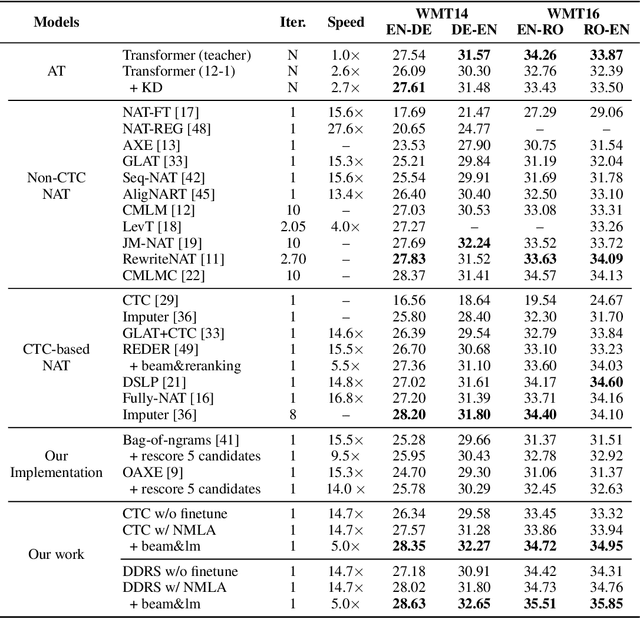
Non-autoregressive translation (NAT) models are typically trained with the cross-entropy loss, which forces the model outputs to be aligned verbatim with the target sentence and will highly penalize small shifts in word positions. Latent alignment models relax the explicit alignment by marginalizing out all monotonic latent alignments with the CTC loss. However, they cannot handle non-monotonic alignments, which is non-negligible as there is typically global word reordering in machine translation. In this work, we explore non-monotonic latent alignments for NAT. We extend the alignment space to non-monotonic alignments to allow for the global word reordering and further consider all alignments that overlap with the target sentence. We non-monotonically match the alignments to the target sentence and train the latent alignment model to maximize the F1 score of non-monotonic matching. Extensive experiments on major WMT benchmarks show that our method substantially improves the translation performance of CTC-based models. Our best model achieves 30.06 BLEU on WMT14 En-De with only one-iteration decoding, closing the gap between non-autoregressive and autoregressive models.
Unsupervised Multi-task and Transfer Learning on Gaussian Mixture Models
Sep 30, 2022

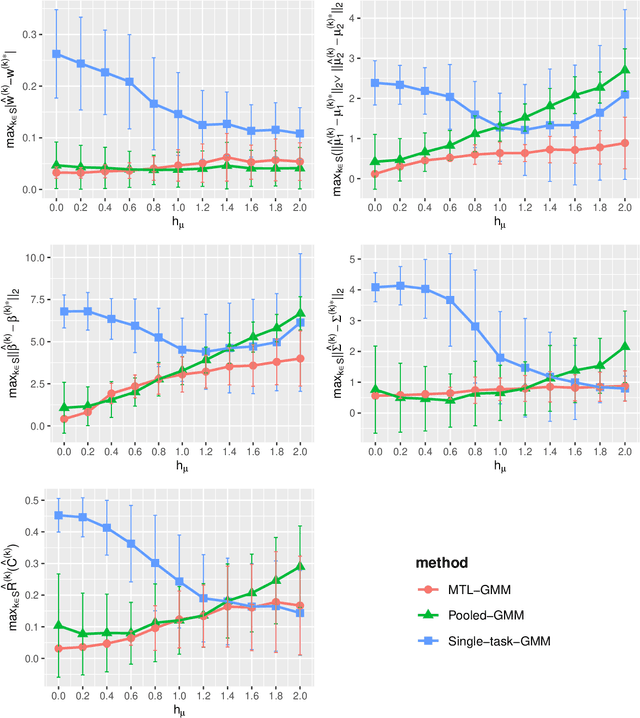

Unsupervised learning has been widely used in many real-world applications. One of the simplest and most important unsupervised learning models is the Gaussian mixture model (GMM). In this work, we study the multi-task learning problem on GMMs, which aims to leverage potentially similar GMM parameter structures among tasks to obtain improved learning performance compared to single-task learning. We propose a multi-task GMM learning procedure based on the EM algorithm that not only can effectively utilize unknown similarity between related tasks but is also robust against a fraction of outlier tasks from arbitrary sources. The proposed procedure is shown to achieve minimax optimal rate of convergence for both parameter estimation error and the excess mis-clustering error, in a wide range of regimes. Moreover, we generalize our approach to tackle the problem of transfer learning for GMMs, where similar theoretical results are derived. Finally, we demonstrate the effectiveness of our methods through simulations and a real data analysis. To the best of our knowledge, this is the first work studying multi-task and transfer learning on GMMs with theoretical guarantees.
GReS: Graphical Cross-domain Recommendation for Supply Chain Platform
Sep 02, 2022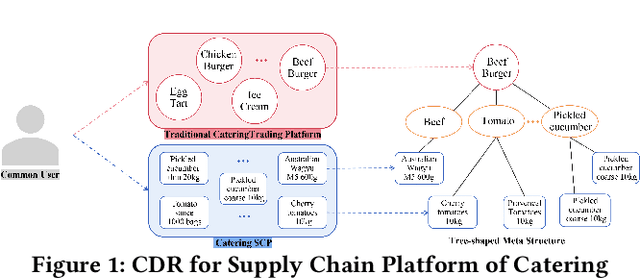
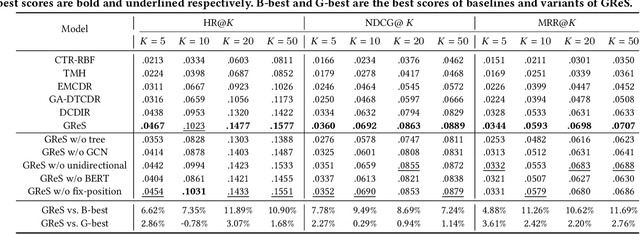
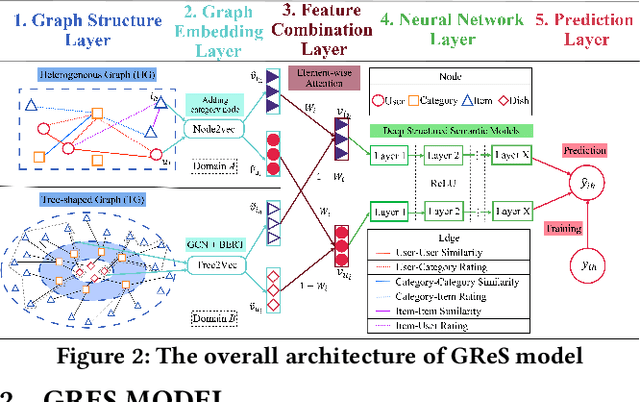
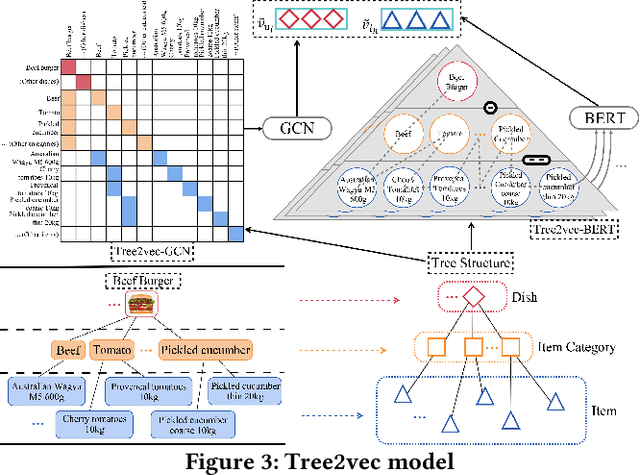
Supply Chain Platforms (SCPs) provide downstream industries with numerous raw materials. Compared with traditional e-commerce platforms, data in SCPs is more sparse due to limited user interests. To tackle the data sparsity problem, one can apply Cross-Domain Recommendation (CDR) which improves the recommendation performance of the target domain with the source domain information. However, applying CDR to SCPs directly ignores the hierarchical structure of commodities in SCPs, which reduce the recommendation performance. To leverage this feature, in this paper, we take the catering platform as an example and propose GReS, a graphical cross-domain recommendation model. The model first constructs a tree-shaped graph to represent the hierarchy of different nodes of dishes and ingredients, and then applies our proposed Tree2vec method combining GCN and BERT models to embed the graph for recommendations. Experimental results on a commercial dataset show that GReS significantly outperforms state-of-the-art methods in Cross-Domain Recommendation for Supply Chain Platforms.
One Reference Is Not Enough: Diverse Distillation with Reference Selection for Non-Autoregressive Translation
May 28, 2022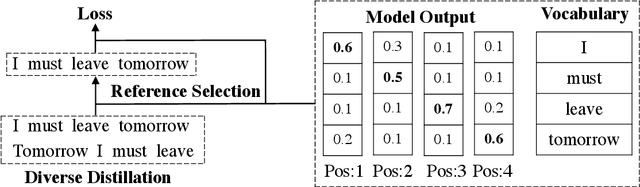

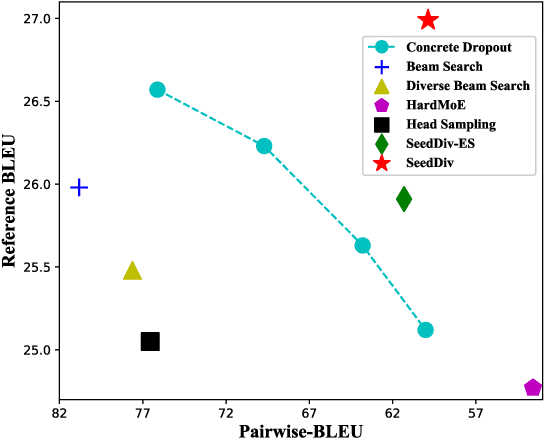
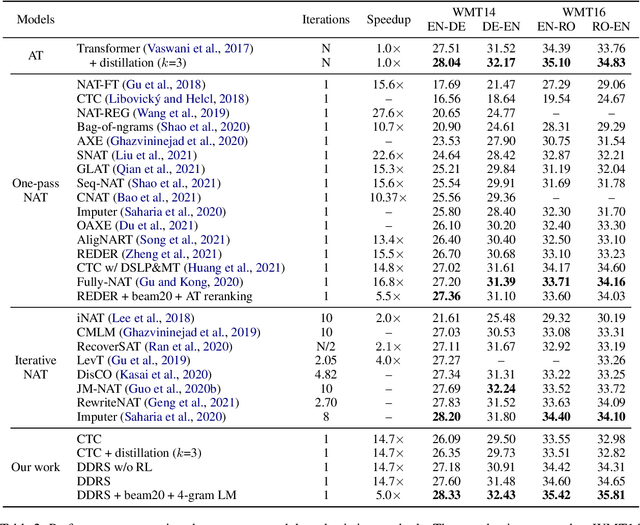
Non-autoregressive neural machine translation (NAT) suffers from the multi-modality problem: the source sentence may have multiple correct translations, but the loss function is calculated only according to the reference sentence. Sequence-level knowledge distillation makes the target more deterministic by replacing the target with the output from an autoregressive model. However, the multi-modality problem in the distilled dataset is still nonnegligible. Furthermore, learning from a specific teacher limits the upper bound of the model capability, restricting the potential of NAT models. In this paper, we argue that one reference is not enough and propose diverse distillation with reference selection (DDRS) for NAT. Specifically, we first propose a method called SeedDiv for diverse machine translation, which enables us to generate a dataset containing multiple high-quality reference translations for each source sentence. During the training, we compare the NAT output with all references and select the one that best fits the NAT output to train the model. Experiments on widely-used machine translation benchmarks demonstrate the effectiveness of DDRS, which achieves 29.82 BLEU with only one decoding pass on WMT14 En-De, improving the state-of-the-art performance for NAT by over 1 BLEU. Source code: https://github.com/ictnlp/DDRS-NAT
Distributed Feature Selection for High-dimensional Additive Models
May 16, 2022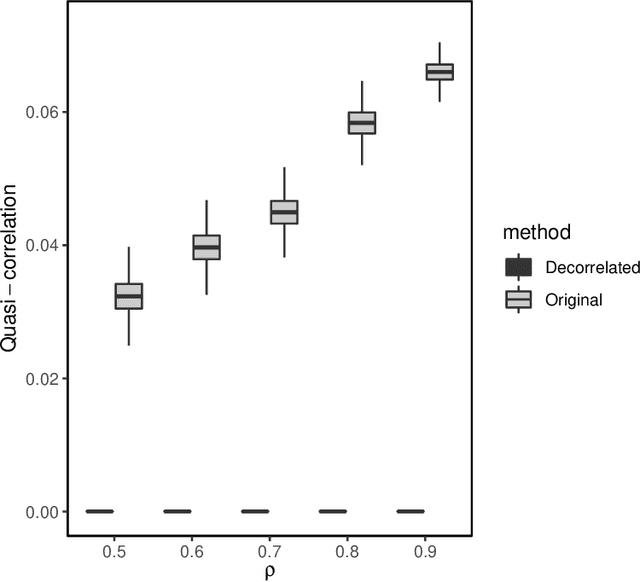
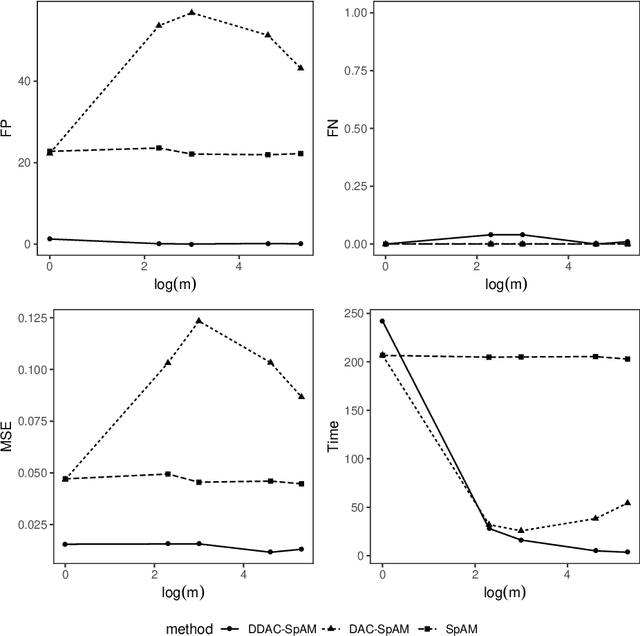
Distributed statistical learning is a common strategy for handling massive data where we divide the learning task into multiple local machines and aggregate the results afterward. However, most existing work considers the case where the samples are divided. In this work, we propose a new algorithm, DDAC-SpAM, that divides features under the high-dimensional sparse additive model. The new algorithm contains three steps: divide, decorrelate, and conquer. We show that after the decorrelation operation, every local estimator can recover the sparsity pattern for each additive component consistently without imposing strict constraints to the correlation structure among variables. Theoretical analysis of the aggregated estimator and empirical results on synthetic and real data illustrate that the DDAC-SpAM algorithm is effective and competitive in fitting sparse additive models.
Reducing Position Bias in Simultaneous Machine Translation with Length-Aware Framework
Mar 23, 2022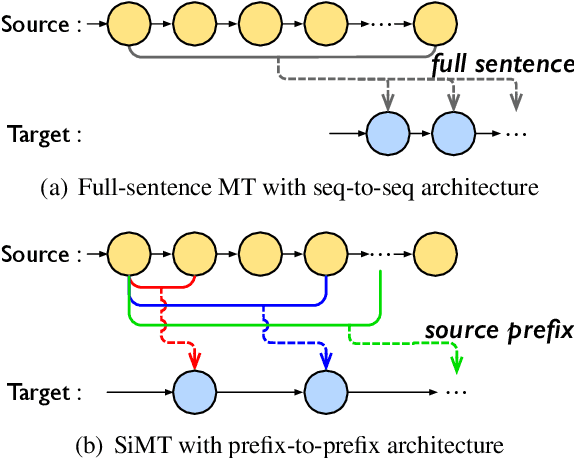

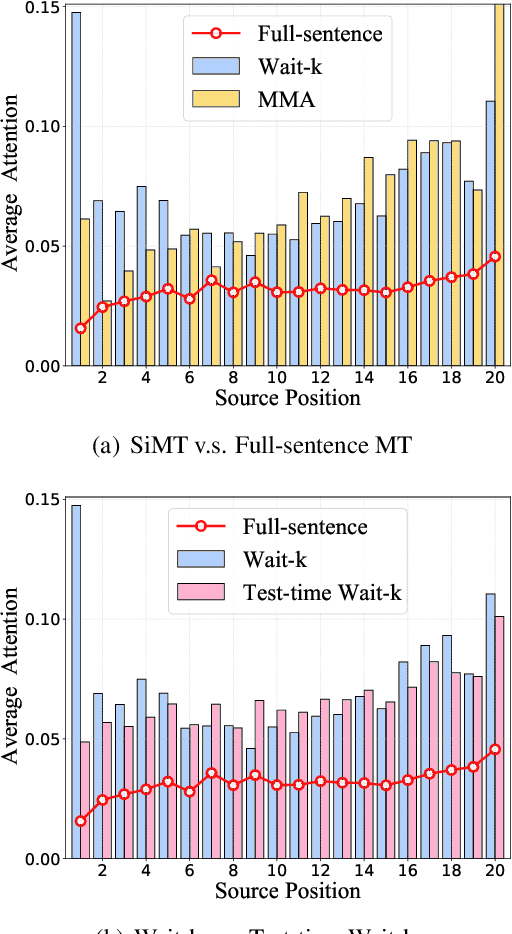
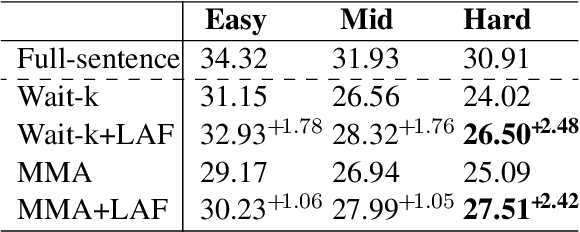
Simultaneous machine translation (SiMT) starts translating while receiving the streaming source inputs, and hence the source sentence is always incomplete during translating. Different from the full-sentence MT using the conventional seq-to-seq architecture, SiMT often applies prefix-to-prefix architecture, which forces each target word to only align with a partial source prefix to adapt to the incomplete source in streaming inputs. However, the source words in the front positions are always illusoryly considered more important since they appear in more prefixes, resulting in position bias, which makes the model pay more attention on the front source positions in testing. In this paper, we first analyze the phenomenon of position bias in SiMT, and develop a Length-Aware Framework to reduce the position bias by bridging the structural gap between SiMT and full-sentence MT. Specifically, given the streaming inputs, we first predict the full-sentence length and then fill the future source position with positional encoding, thereby turning the streaming inputs into a pseudo full-sentence. The proposed framework can be integrated into most existing SiMT methods to further improve performance. Experiments on two representative SiMT methods, including the state-of-the-art adaptive policy, show that our method successfully reduces the position bias and thereby achieves better SiMT performance.
Modeling Dual Read/Write Paths for Simultaneous Machine Translation
Mar 22, 2022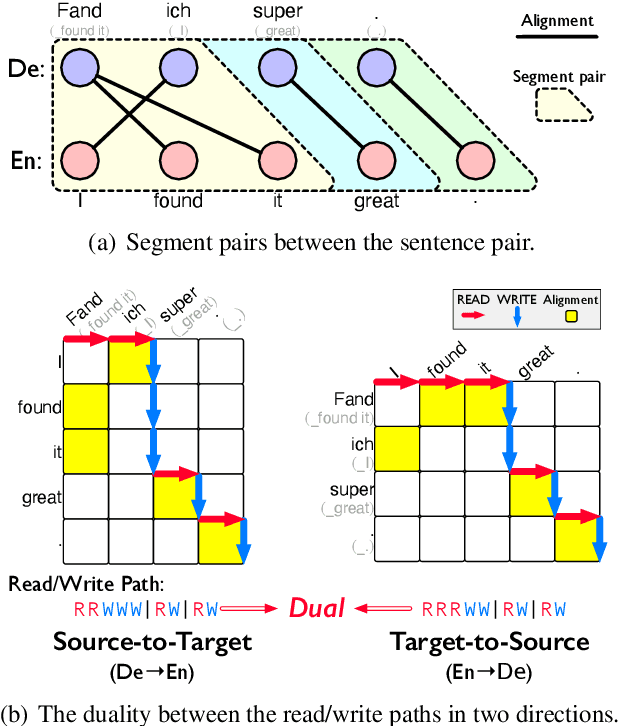
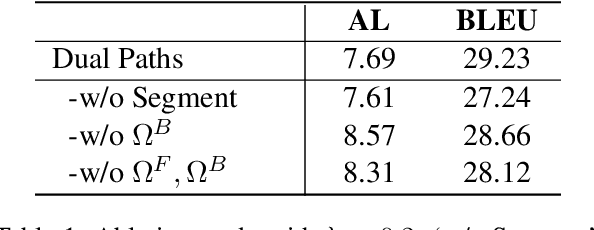
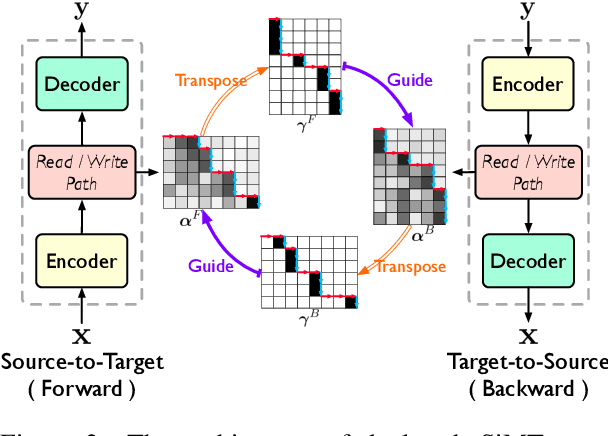
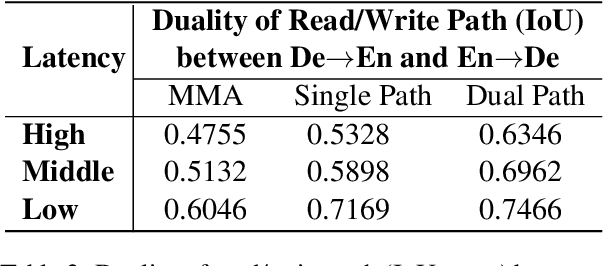
Simultaneous machine translation (SiMT) outputs translation while reading source sentence and hence requires a policy to decide whether to wait for the next source word (READ) or generate a target word (WRITE), the actions of which form a read/write path. Although the read/write path is essential to SiMT performance, no direct supervision is given to the path in the existing methods. In this paper, we propose a method of dual-path SiMT which introduces duality constraints to direct the read/write path. According to duality constraints, the read/write path in source-to-target and target-to-source SiMT models can be mapped to each other. As a result, the two SiMT models can be optimized jointly by forcing their read/write paths to satisfy the mapping. Experiments on En-Vi and De-En tasks show that our method can outperform strong baselines under all latency.
STEMM: Self-learning with Speech-text Manifold Mixup for Speech Translation
Mar 20, 2022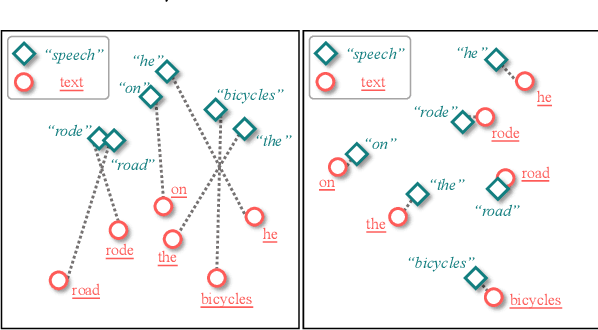
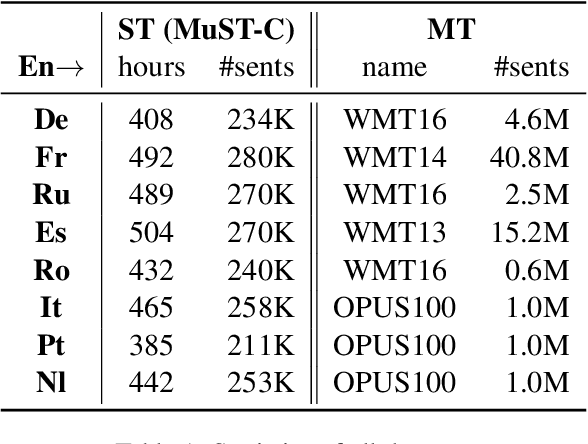
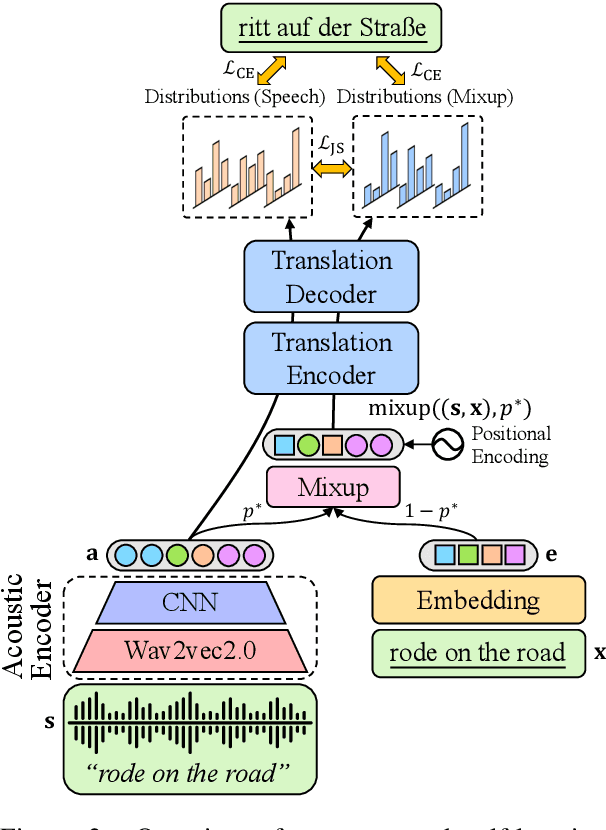
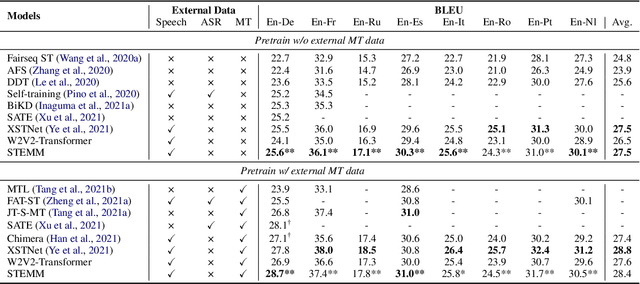
How to learn a better speech representation for end-to-end speech-to-text translation (ST) with limited labeled data? Existing techniques often attempt to transfer powerful machine translation (MT) capabilities to ST, but neglect the representation discrepancy across modalities. In this paper, we propose the Speech-TExt Manifold Mixup (STEMM) method to calibrate such discrepancy. Specifically, we mix up the representation sequences of different modalities, and take both unimodal speech sequences and multimodal mixed sequences as input to the translation model in parallel, and regularize their output predictions with a self-learning framework. Experiments on MuST-C speech translation benchmark and further analysis show that our method effectively alleviates the cross-modal representation discrepancy, and achieves significant improvements over a strong baseline on eight translation directions.
Neural Machine Translation with Phrase-Level Universal Visual Representations
Mar 19, 2022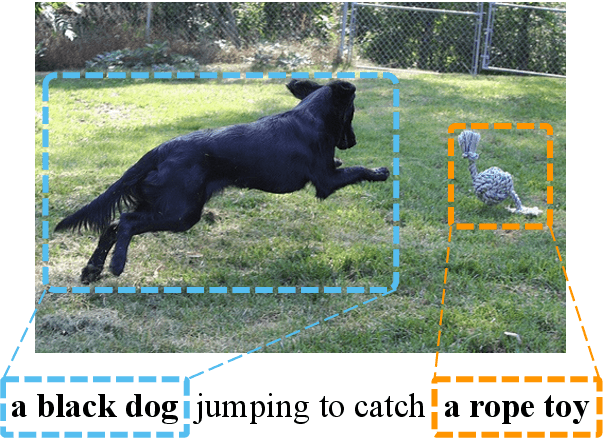

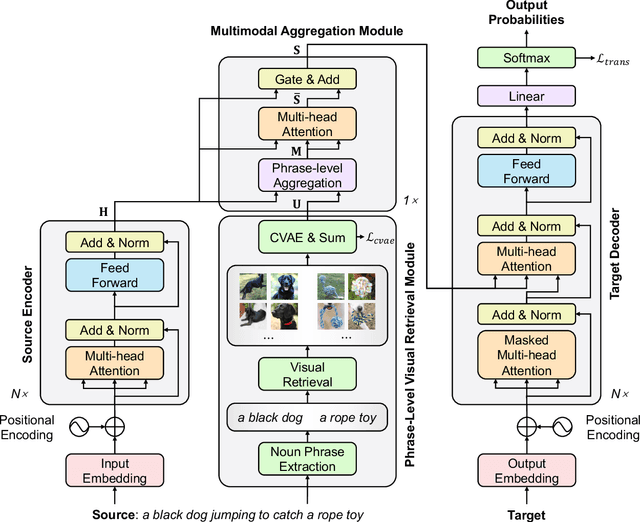
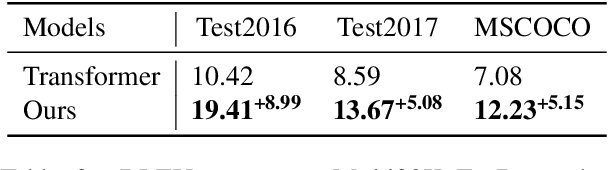
Multimodal machine translation (MMT) aims to improve neural machine translation (NMT) with additional visual information, but most existing MMT methods require paired input of source sentence and image, which makes them suffer from shortage of sentence-image pairs. In this paper, we propose a phrase-level retrieval-based method for MMT to get visual information for the source input from existing sentence-image data sets so that MMT can break the limitation of paired sentence-image input. Our method performs retrieval at the phrase level and hence learns visual information from pairs of source phrase and grounded region, which can mitigate data sparsity. Furthermore, our method employs the conditional variational auto-encoder to learn visual representations which can filter redundant visual information and only retain visual information related to the phrase. Experiments show that the proposed method significantly outperforms strong baselines on multiple MMT datasets, especially when the textual context is limited.