 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVowelPrompt: Hearing Speech Emotions from Text via Vowel-level Prosodic Augmentation
Feb 06, 2026Emotion recognition in speech presents a complex multimodal challenge, requiring comprehension of both linguistic content and vocal expressivity, particularly prosodic features such as fundamental frequency, intensity, and temporal dynamics. Although large language models (LLMs) have shown promise in reasoning over textual transcriptions for emotion recognition, they typically neglect fine-grained prosodic information, limiting their effectiveness and interpretability. In this work, we propose VowelPrompt, a linguistically grounded framework that augments LLM-based emotion recognition with interpretable, fine-grained vowel-level prosodic cues. Drawing on phonetic evidence that vowels serve as primary carriers of affective prosody, VowelPrompt extracts pitch-, energy-, and duration-based descriptors from time-aligned vowel segments, and converts these features into natural language descriptions for better interpretability. Such a design enables LLMs to jointly reason over lexical semantics and fine-grained prosodic variation. Moreover, we adopt a two-stage adaptation procedure comprising supervised fine-tuning (SFT) followed by Reinforcement Learning with Verifiable Reward (RLVR), implemented via Group Relative Policy Optimization (GRPO), to enhance reasoning capability, enforce structured output adherence, and improve generalization across domains and speaker variations. Extensive evaluations across diverse benchmark datasets demonstrate that VowelPrompt consistently outperforms state-of-the-art emotion recognition methods under zero-shot, fine-tuned, cross-domain, and cross-linguistic conditions, while enabling the generation of interpretable explanations that are jointly grounded in contextual semantics and fine-grained prosodic structure.
Differentiable Channel Selection in Self-Attention For Person Re-Identification
May 13, 2025In this paper, we propose a novel attention module termed the Differentiable Channel Selection Attention module, or the DCS-Attention module. In contrast with conventional self-attention, the DCS-Attention module features selection of informative channels in the computation of the attention weights. The selection of the feature channels is performed in a differentiable manner, enabling seamless integration with DNN training. Our DCS-Attention is compatible with either fixed neural network backbones or learnable backbones with Differentiable Neural Architecture Search (DNAS), leading to DCS with Fixed Backbone (DCS-FB) and DCS-DNAS, respectively. Importantly, our DCS-Attention is motivated by the principle of Information Bottleneck (IB), and a novel variational upper bound for the IB loss, which can be optimized by SGD, is derived and incorporated into the training loss of the networks with the DCS-Attention modules. In this manner, a neural network with DCS-Attention modules is capable of selecting the most informative channels for feature extraction so that it enjoys state-of-the-art performance for the Re-ID task. Extensive experiments on multiple person Re-ID benchmarks using both DCS-FB and DCS-DNAS show that DCS-Attention significantly enhances the prediction accuracy of DNNs for person Re-ID, which demonstrates the effectiveness of DCS-Attention in learning discriminative features critical to identifying person identities. The code of our work is available at https://github.com/Statistical-Deep-Learning/DCS-Attention.
Diffusion on Graph: Augmentation of Graph Structure for Node Classification
Mar 16, 2025Graph diffusion models have recently been proposed to synthesize entire graphs, such as molecule graphs. Although existing methods have shown great performance in generating entire graphs for graph-level learning tasks, no graph diffusion models have been developed to generate synthetic graph structures, that is, synthetic nodes and associated edges within a given graph, for node-level learning tasks. Inspired by the research in the computer vision literature using synthetic data for enhanced performance, we propose Diffusion on Graph (DoG), which generates synthetic graph structures to boost the performance of GNNs. The synthetic graph structures generated by DoG are combined with the original graph to form an augmented graph for the training of node-level learning tasks, such as node classification and graph contrastive learning (GCL). To improve the efficiency of the generation process, a Bi-Level Neighbor Map Decoder (BLND) is introduced in DoG. To mitigate the adverse effect of the noise introduced by the synthetic graph structures, a low-rank regularization method is proposed for the training of graph neural networks (GNNs) on the augmented graphs. Extensive experiments on various graph datasets for semi-supervised node classification and graph contrastive learning have been conducted to demonstrate the effectiveness of DoG with low-rank regularization. The code of DoG is available at https://github.com/Statistical-Deep-Learning/DoG.
IDNet: A Novel Dataset for Identity Document Analysis and Fraud Detection
Aug 03, 2024



Effective fraud detection and analysis of government-issued identity documents, such as passports, driver's licenses, and identity cards, are essential in thwarting identity theft and bolstering security on online platforms. The training of accurate fraud detection and analysis tools depends on the availability of extensive identity document datasets. However, current publicly available benchmark datasets for identity document analysis, including MIDV-500, MIDV-2020, and FMIDV, fall short in several respects: they offer a limited number of samples, cover insufficient varieties of fraud patterns, and seldom include alterations in critical personal identifying fields like portrait images, limiting their utility in training models capable of detecting realistic frauds while preserving privacy. In response to these shortcomings, our research introduces a new benchmark dataset, IDNet, designed to advance privacy-preserving fraud detection efforts. The IDNet dataset comprises 837,060 images of synthetically generated identity documents, totaling approximately 490 gigabytes, categorized into 20 types from $10$ U.S. states and 10 European countries. We evaluate the utility and present use cases of the dataset, illustrating how it can aid in training privacy-preserving fraud detection methods, facilitating the generation of camera and video capturing of identity documents, and testing schema unification and other identity document management functionalities.
Efficient Visual Transformer by Learnable Token Merging
Jul 21, 2024



Self-attention and transformers have been widely used in deep learning. Recent efforts have been devoted to incorporating transformer blocks into different neural architectures, including those with convolutions, leading to various visual transformers for computer vision tasks. In this paper, we propose a novel and compact transformer block, Transformer with Learnable Token Merging (LTM), or LTM-Transformer. LTM-Transformer performs token merging in a learnable scheme. LTM-Transformer is compatible with many popular and compact transformer networks, and it reduces the FLOPs and the inference time of the visual transformers while maintaining or even improving the prediction accuracy. In the experiments, we replace all the transformer blocks in popular visual transformers, including MobileViT, EfficientViT, ViT-S/16, and Swin-T, with LTM-Transformer blocks, leading to LTM-Transformer networks with different backbones. The LTM-Transformer is motivated by reduction of Information Bottleneck, and a novel and separable variational upper bound for the IB loss is derived. The architecture of mask module in our LTM blocks which generate the token merging mask is designed to reduce the derived upper bound for the IB loss. Extensive results on computer vision tasks evidence that LTM-Transformer renders compact and efficient visual transformers with comparable or much better prediction accuracy than the original visual transformers. The code of the LTM-Transformer is available at \url{https://github.com/Statistical-Deep-Learning/LTM}.
Low-Rank Graph Contrastive Learning for Node Classification
Feb 14, 2024



Graph Neural Networks (GNNs) have been widely used to learn node representations and with outstanding performance on various tasks such as node classification. However, noise, which inevitably exists in real-world graph data, would considerably degrade the performance of GNNs revealed by recent studies. In this work, we propose a novel and robust GNN encoder, Low-Rank Graph Contrastive Learning (LR-GCL). Our method performs transductive node classification in two steps. First, a low-rank GCL encoder named LR-GCL is trained by prototypical contrastive learning with low-rank regularization. Next, using the features produced by LR-GCL, a linear transductive classification algorithm is used to classify the unlabeled nodes in the graph. Our LR-GCL is inspired by the low frequency property of the graph data and its labels, and it is also theoretically motivated by our sharp generalization bound for transductive learning. To the best of our knowledge, our theoretical result is among the first to theoretically demonstrate the advantage of low-rank learning in graph contrastive learning supported by strong empirical performance. Extensive experiments on public benchmarks demonstrate the superior performance of LR-GCL and the robustness of the learned node representations. The code of LR-GCL is available at \url{https://anonymous.4open.science/r/Low-Rank_Graph_Contrastive_Learning-64A6/}.
A Learning-based Declarative Privacy-Preserving Framework for Federated Data Management
Jan 22, 2024It is challenging to balance the privacy and accuracy for federated query processing over multiple private data silos. In this work, we will demonstrate an end-to-end workflow for automating an emerging privacy-preserving technique that uses a deep learning model trained using the Differentially-Private Stochastic Gradient Descent (DP-SGD) algorithm to replace portions of actual data to answer a query. Our proposed novel declarative privacy-preserving workflow allows users to specify "what private information to protect" rather than "how to protect". Under the hood, the system automatically chooses query-model transformation plans as well as hyper-parameters. At the same time, the proposed workflow also allows human experts to review and tune the selected privacy-preserving mechanism for audit/compliance, and optimization purposes.
RecMind: Large Language Model Powered Agent For Recommendation
Aug 28, 2023



Recent advancements in instructing Large Language Models (LLMs) to utilize external tools and execute multi-step plans have significantly enhanced their ability to solve intricate tasks, ranging from mathematical problems to creative writing. Yet, there remains a notable gap in studying the capacity of LLMs in responding to personalized queries such as a recommendation request. To bridge this gap, we have designed an LLM-powered autonomous recommender agent, RecMind, which is capable of providing precise personalized recommendations through careful planning, utilizing tools for obtaining external knowledge, and leveraging individual data. We propose a novel algorithm, Self-Inspiring, to improve the planning ability of the LLM agent. At each intermediate planning step, the LLM 'self-inspires' to consider all previously explored states to plan for next step. This mechanism greatly improves the model's ability to comprehend and utilize historical planning information for recommendation. We evaluate RecMind's performance in various recommendation scenarios, including rating prediction, sequential recommendation, direct recommendation, explanation generation, and review summarization. Our experiment shows that RecMind outperforms existing zero/few-shot LLM-based recommendation methods in different recommendation tasks and achieves competitive performance to a recent model P5, which requires fully pre-train for the recommendation tasks.
RNAS-CL: Robust Neural Architecture Search by Cross-Layer Knowledge Distillation
Jan 19, 2023Deep Neural Networks are vulnerable to adversarial attacks. Neural Architecture Search (NAS), one of the driving tools of deep neural networks, demonstrates superior performance in prediction accuracy in various machine learning applications. However, it is unclear how it performs against adversarial attacks. Given the presence of a robust teacher, it would be interesting to investigate if NAS would produce robust neural architecture by inheriting robustness from the teacher. In this paper, we propose Robust Neural Architecture Search by Cross-Layer Knowledge Distillation (RNAS-CL), a novel NAS algorithm that improves the robustness of NAS by learning from a robust teacher through cross-layer knowledge distillation. Unlike previous knowledge distillation methods that encourage close student/teacher output only in the last layer, RNAS-CL automatically searches for the best teacher layer to supervise each student layer. Experimental result evidences the effectiveness of RNAS-CL and shows that RNAS-CL produces small and robust neural architecture.
FEC: Fast Euclidean Clustering for Point Cloud Segmentation
Aug 16, 2022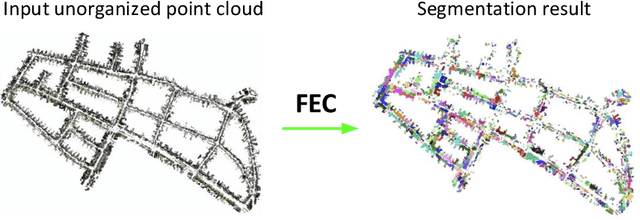

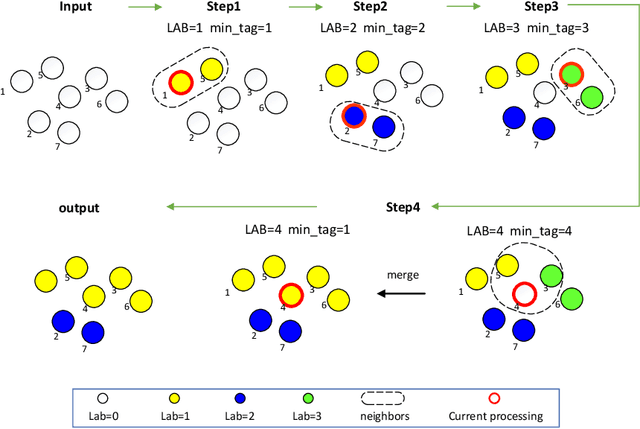
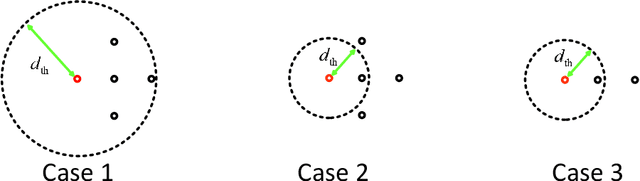
Segmentation from point cloud data is essential in many applications such as remote sensing, mobile robots, or autonomous cars. However, the point clouds captured by the 3D range sensor are commonly sparse and unstructured, challenging efficient segmentation. In this paper, we present a fast solution to point cloud instance segmentation with small computational demands. To this end, we propose a novel fast Euclidean clustering (FEC) algorithm which applies a pointwise scheme over the clusterwise scheme used in existing works. Our approach is conceptually simple, easy to implement (40 lines in C++), and achieves two orders of magnitudes faster against the classical segmentation methods while producing high-quality results.