 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-scale Quaternion CNN and BiGRU with Cross Self-attention Feature Fusion for Fault Diagnosis of Bearing
May 25, 2024In recent years, deep learning has led to significant advances in bearing fault diagnosis (FD). Most techniques aim to achieve greater accuracy. However, they are sensitive to noise and lack robustness, resulting in insufficient domain adaptation and anti-noise ability. The comparison of studies reveals that giving equal attention to all features does not differentiate their significance. In this work, we propose a novel FD model by integrating multi-scale quaternion convolutional neural network (MQCNN), bidirectional gated recurrent unit (BiGRU), and cross self-attention feature fusion (CSAFF). We have developed innovative designs in two modules, namely MQCNN and CSAFF. Firstly, MQCNN applies quaternion convolution to multi-scale architecture for the first time, aiming to extract the rich hidden features of the original signal from multiple scales. Then, the extracted multi-scale information is input into CSAFF for feature fusion, where CSAFF innovatively incorporates cross self-attention mechanism to enhance discriminative interaction representation within features. Finally, BiGRU captures temporal dependencies while a softmax layer is employed for fault classification, achieving accurate FD. To assess the efficacy of our approach, we experiment on three public datasets (CWRU, MFPT, and Ottawa) and compare it with other excellent methods. The results confirm its state-of-the-art, which the average accuracies can achieve up to 99.99%, 100%, and 99.21% on CWRU, MFPT, and Ottawa datasets. Moreover, we perform practical tests and ablation experiments to validate the efficacy and robustness of the proposed approach. Code is available at https://github.com/mubai011/MQCCAF.
Learning Multi-dimensional Human Preference for Text-to-Image Generation
May 23, 2024Current metrics for text-to-image models typically rely on statistical metrics which inadequately represent the real preference of humans. Although recent work attempts to learn these preferences via human annotated images, they reduce the rich tapestry of human preference to a single overall score. However, the preference results vary when humans evaluate images with different aspects. Therefore, to learn the multi-dimensional human preferences, we propose the Multi-dimensional Preference Score (MPS), the first multi-dimensional preference scoring model for the evaluation of text-to-image models. The MPS introduces the preference condition module upon CLIP model to learn these diverse preferences. It is trained based on our Multi-dimensional Human Preference (MHP) Dataset, which comprises 918,315 human preference choices across four dimensions (i.e., aesthetics, semantic alignment, detail quality and overall assessment) on 607,541 images. The images are generated by a wide range of latest text-to-image models. The MPS outperforms existing scoring methods across 3 datasets in 4 dimensions, enabling it a promising metric for evaluating and improving text-to-image generation.
Learning Coarse-Grained Dynamics on Graph
May 15, 2024We consider a Graph Neural Network (GNN) non-Markovian modeling framework to identify coarse-grained dynamical systems on graphs. Our main idea is to systematically determine the GNN architecture by inspecting how the leading term of the Mori-Zwanzig memory term depends on the coarse-grained interaction coefficients that encode the graph topology. Based on this analysis, we found that the appropriate GNN architecture that will account for $K$-hop dynamical interactions has to employ a Message Passing (MP) mechanism with at least $2K$ steps. We also deduce that the memory length required for an accurate closure model decreases as a function of the interaction strength under the assumption that the interaction strength exhibits a power law that decays as a function of the hop distance. Supporting numerical demonstrations on two examples, a heterogeneous Kuramoto oscillator model and a power system, suggest that the proposed GNN architecture can predict the coarse-grained dynamics under fixed and time-varying graph topologies.
FORESEE: Multimodal and Multi-view Representation Learning for Robust Prediction of Cancer Survival
May 13, 2024Integrating the different data modalities of cancer patients can significantly improve the predictive performance of patient survival. However, most existing methods ignore the simultaneous utilization of rich semantic features at different scales in pathology images. When collecting multimodal data and extracting features, there is a likelihood of encountering intra-modality missing data, introducing noise into the multimodal data. To address these challenges, this paper proposes a new end-to-end framework, FORESEE, for robustly predicting patient survival by mining multimodal information. Specifically, the cross-fusion transformer effectively utilizes features at the cellular level, tissue level, and tumor heterogeneity level to correlate prognosis through a cross-scale feature cross-fusion method. This enhances the ability of pathological image feature representation. Secondly, the hybrid attention encoder (HAE) uses the denoising contextual attention module to obtain the contextual relationship features and local detail features of the molecular data. HAE's channel attention module obtains global features of molecular data. Furthermore, to address the issue of missing information within modalities, we propose an asymmetrically masked triplet masked autoencoder to reconstruct lost information within modalities. Extensive experiments demonstrate the superiority of our method over state-of-the-art methods on four benchmark datasets in both complete and missing settings.
Knowledge Adaptation from Large Language Model to Recommendation for Practical Industrial Application
May 07, 2024



Contemporary recommender systems predominantly rely on collaborative filtering techniques, employing ID-embedding to capture latent associations among users and items. However, this approach overlooks the wealth of semantic information embedded within textual descriptions of items, leading to suboptimal performance in cold-start scenarios and long-tail user recommendations. Leveraging the capabilities of Large Language Models (LLMs) pretrained on massive text corpus presents a promising avenue for enhancing recommender systems by integrating open-world domain knowledge. In this paper, we propose an Llm-driven knowlEdge Adaptive RecommeNdation (LEARN) framework that synergizes open-world knowledge with collaborative knowledge. We address computational complexity concerns by utilizing pretrained LLMs as item encoders and freezing LLM parameters to avoid catastrophic forgetting and preserve open-world knowledge. To bridge the gap between the open-world and collaborative domains, we design a twin-tower structure supervised by the recommendation task and tailored for practical industrial application. Through offline experiments on the large-scale industrial dataset and online experiments on A/B tests, we demonstrate the efficacy of our approach.
Stochastic Constrained Decentralized Optimization for Machine Learning with Fewer Data Oracles: a Gradient Sliding Approach
Apr 03, 2024



In modern decentralized applications, ensuring communication efficiency and privacy for the users are the key challenges. In order to train machine-learning models, the algorithm has to communicate to the data center and sample data for its gradient computation, thus exposing the data and increasing the communication cost. This gives rise to the need for a decentralized optimization algorithm that is communication-efficient and minimizes the number of gradient computations. To this end, we propose the primal-dual sliding with conditional gradient sliding framework, which is communication-efficient and achieves an $\varepsilon$-approximate solution with the optimal gradient complexity of $O(1/\sqrt{\varepsilon}+\sigma^2/{\varepsilon^2})$ and $O(\log(1/\varepsilon)+\sigma^2/\varepsilon)$ for the convex and strongly convex setting respectively and an LO (Linear Optimization) complexity of $O(1/\varepsilon^2)$ for both settings given a stochastic gradient oracle with variance $\sigma^2$. Compared with the prior work \cite{wai-fw-2017}, our framework relaxes the assumption of the optimal solution being a strict interior point of the feasible set and enjoys wider applicability for large-scale training using a stochastic gradient oracle. We also demonstrate the efficiency of our algorithms with various numerical experiments.
The state-of-the-art in Cardiac MRI Reconstruction: Results of the CMRxRecon Challenge in MICCAI 2023
Apr 01, 2024



Cardiac MRI, crucial for evaluating heart structure and function, faces limitations like slow imaging and motion artifacts. Undersampling reconstruction, especially data-driven algorithms, has emerged as a promising solution to accelerate scans and enhance imaging performance using highly under-sampled data. Nevertheless, the scarcity of publicly available cardiac k-space datasets and evaluation platform hinder the development of data-driven reconstruction algorithms. To address this issue, we organized the Cardiac MRI Reconstruction Challenge (CMRxRecon) in 2023, in collaboration with the 26th International Conference on MICCAI. CMRxRecon presented an extensive k-space dataset comprising cine and mapping raw data, accompanied by detailed annotations of cardiac anatomical structures. With overwhelming participation, the challenge attracted more than 285 teams and over 600 participants. Among them, 22 teams successfully submitted Docker containers for the testing phase, with 7 teams submitted for both cine and mapping tasks. All teams use deep learning based approaches, indicating that deep learning has predominately become a promising solution for the problem. The first-place winner of both tasks utilizes the E2E-VarNet architecture as backbones. In contrast, U-Net is still the most popular backbone for both multi-coil and single-coil reconstructions. This paper provides a comprehensive overview of the challenge design, presents a summary of the submitted results, reviews the employed methods, and offers an in-depth discussion that aims to inspire future advancements in cardiac MRI reconstruction models. The summary emphasizes the effective strategies observed in Cardiac MRI reconstruction, including backbone architecture, loss function, pre-processing techniques, physical modeling, and model complexity, thereby providing valuable insights for further developments in this field.
A Novel Loss Function-based Support Vector Machine for Binary Classification
Mar 25, 2024



The previous support vector machine(SVM) including $0/1$ loss SVM, hinge loss SVM, ramp loss SVM, truncated pinball loss SVM, and others, overlooked the degree of penalty for the correctly classified samples within the margin. This oversight affects the generalization ability of the SVM classifier to some extent. To address this limitation, from the perspective of confidence margin, we propose a novel Slide loss function ($\ell_s$) to construct the support vector machine classifier($\ell_s$-SVM). By introducing the concept of proximal stationary point, and utilizing the property of Lipschitz continuity, we derive the first-order optimality conditions for $\ell_s$-SVM. Based on this, we define the $\ell_s$ support vectors and working set of $\ell_s$-SVM. To efficiently handle $\ell_s$-SVM, we devise a fast alternating direction method of multipliers with the working set ($\ell_s$-ADMM), and provide the convergence analysis. The numerical experiments on real world datasets confirm the robustness and effectiveness of the proposed method.
A Unified and General Framework for Continual Learning
Mar 20, 2024Continual Learning (CL) focuses on learning from dynamic and changing data distributions while retaining previously acquired knowledge. Various methods have been developed to address the challenge of catastrophic forgetting, including regularization-based, Bayesian-based, and memory-replay-based techniques. However, these methods lack a unified framework and common terminology for describing their approaches. This research aims to bridge this gap by introducing a comprehensive and overarching framework that encompasses and reconciles these existing methodologies. Notably, this new framework is capable of encompassing established CL approaches as special instances within a unified and general optimization objective. An intriguing finding is that despite their diverse origins, these methods share common mathematical structures. This observation highlights the compatibility of these seemingly distinct techniques, revealing their interconnectedness through a shared underlying optimization objective. Moreover, the proposed general framework introduces an innovative concept called refresh learning, specifically designed to enhance the CL performance. This novel approach draws inspiration from neuroscience, where the human brain often sheds outdated information to improve the retention of crucial knowledge and facilitate the acquisition of new information. In essence, refresh learning operates by initially unlearning current data and subsequently relearning it. It serves as a versatile plug-in that seamlessly integrates with existing CL methods, offering an adaptable and effective enhancement to the learning process. Extensive experiments on CL benchmarks and theoretical analysis demonstrate the effectiveness of the proposed refresh learning. Code is available at \url{https://github.com/joey-wang123/CL-refresh-learning}.
Knowledge Condensation and Reasoning for Knowledge-based VQA
Mar 15, 2024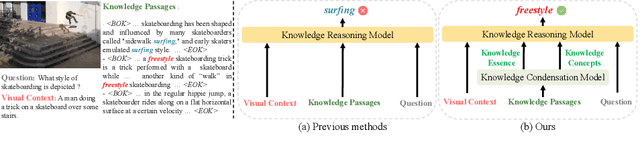
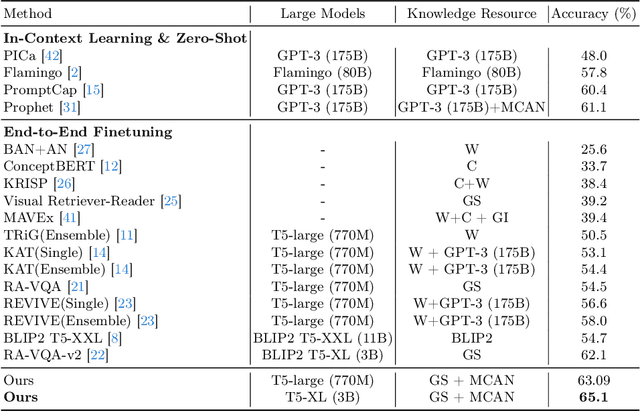
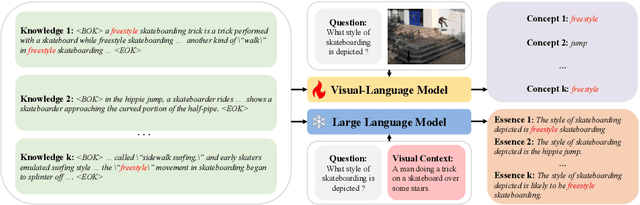

Knowledge-based visual question answering (KB-VQA) is a challenging task, which requires the model to leverage external knowledge for comprehending and answering questions grounded in visual content. Recent studies retrieve the knowledge passages from external knowledge bases and then use them to answer questions. However, these retrieved knowledge passages often contain irrelevant or noisy information, which limits the performance of the model. To address the challenge, we propose two synergistic models: Knowledge Condensation model and Knowledge Reasoning model. We condense the retrieved knowledge passages from two perspectives. First, we leverage the multimodal perception and reasoning ability of the visual-language models to distill concise knowledge concepts from retrieved lengthy passages, ensuring relevance to both the visual content and the question. Second, we leverage the text comprehension ability of the large language models to summarize and condense the passages into the knowledge essence which helps answer the question. These two types of condensed knowledge are then seamlessly integrated into our Knowledge Reasoning model, which judiciously navigates through the amalgamated information to arrive at the conclusive answer. Extensive experiments validate the superiority of the proposed method. Compared to previous methods, our method achieves state-of-the-art performance on knowledge-based VQA datasets (65.1% on OK-VQA and 60.1% on A-OKVQA) without resorting to the knowledge produced by GPT-3 (175B).