 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction-Adaptive Continual Learning: Enabling Policy Generalization under Dynamic Action Spaces
Jun 06, 2025Continual Learning (CL) is a powerful tool that enables agents to learn a sequence of tasks, accumulating knowledge learned in the past and using it for problem-solving or future task learning. However, existing CL methods often assume that the agent's capabilities remain static within dynamic environments, which doesn't reflect real-world scenarios where capabilities dynamically change. This paper introduces a new and realistic problem: Continual Learning with Dynamic Capabilities (CL-DC), posing a significant challenge for CL agents: How can policy generalization across different action spaces be achieved? Inspired by the cortical functions, we propose an Action-Adaptive Continual Learning framework (AACL) to address this challenge. Our framework decouples the agent's policy from the specific action space by building an action representation space. For a new action space, the encoder-decoder of action representations is adaptively fine-tuned to maintain a balance between stability and plasticity. Furthermore, we release a benchmark based on three environments to validate the effectiveness of methods for CL-DC. Experimental results demonstrate that our framework outperforms popular methods by generalizing the policy across action spaces.
Sequential three-way decisions with a single hidden layer feedforward neural network
Mar 14, 2023



The three-way decisions strategy has been employed to construct network topology in a single hidden layer feedforward neural network (SFNN). However, this model has a general performance, and does not consider the process costs, since it has fixed threshold parameters. Inspired by the sequential three-way decisions (STWD), this paper proposes STWD with an SFNN (STWD-SFNN) to enhance the performance of networks on structured datasets. STWD-SFNN adopts multi-granularity levels to dynamically learn the number of hidden layer nodes from coarse to fine, and set the sequential threshold parameters. Specifically, at the coarse granular level, STWD-SFNN handles easy-to-classify instances by applying strict threshold conditions, and with the increasing number of hidden layer nodes at the fine granular level, STWD-SFNN focuses more on disposing of the difficult-to-classify instances by applying loose threshold conditions, thereby realizing the classification of instances. Moreover, STWD-SFNN considers and reports the process cost produced from each granular level. The experimental results verify that STWD-SFNN has a more compact network on structured datasets than other SFNN models, and has better generalization performance than the competitive models. All models and datasets can be downloaded from https://github.com/wuc567/Machine-learning/tree/main/STWD-SFNN.
Test-cost-sensitive attribute reduction of data with normal distribution measurement errors
Jun 03, 2013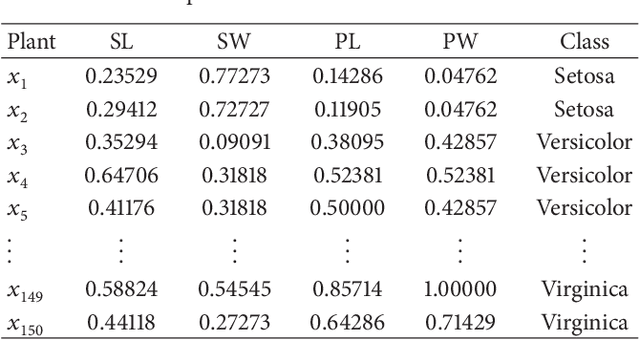
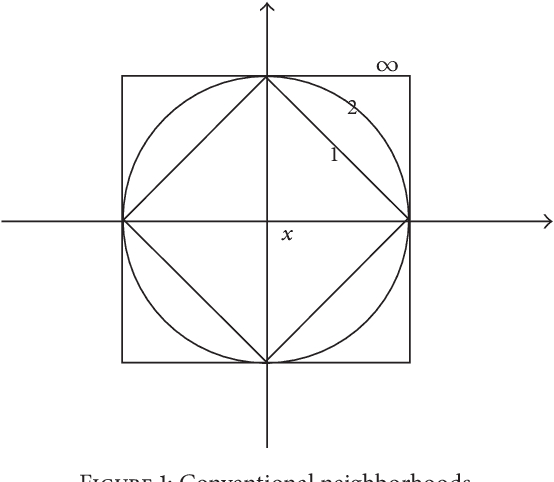
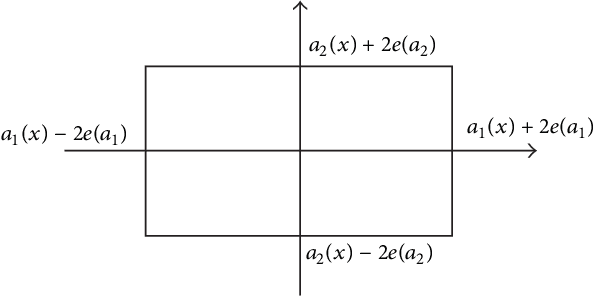
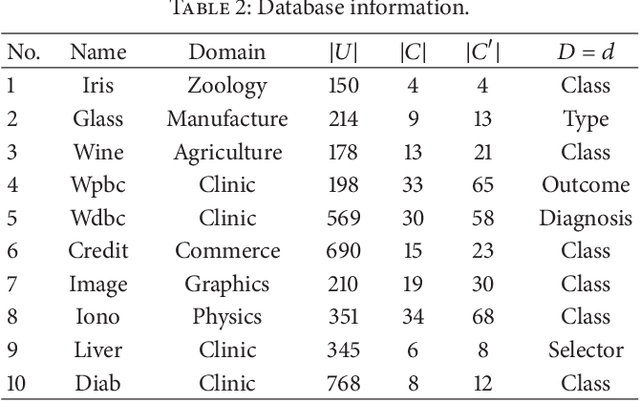
The measurement error with normal distribution is universal in applications. Generally, smaller measurement error requires better instrument and higher test cost. In decision making based on attribute values of objects, we shall select an attribute subset with appropriate measurement error to minimize the total test cost. Recently, error-range-based covering rough set with uniform distribution error was proposed to investigate this issue. However, the measurement errors satisfy normal distribution instead of uniform distribution which is rather simple for most applications. In this paper, we introduce normal distribution measurement errors to covering-based rough set model, and deal with test-cost-sensitive attribute reduction problem in this new model. The major contributions of this paper are four-fold. First, we build a new data model based on normal distribution measurement errors. With the new data model, the error range is an ellipse in a two-dimension space. Second, the covering-based rough set with normal distribution measurement errors is constructed through the "3-sigma" rule. Third, the test-cost-sensitive attribute reduction problem is redefined on this covering-based rough set. Fourth, a heuristic algorithm is proposed to deal with this problem. The algorithm is tested on ten UCI (University of California - Irvine) datasets. The experimental results show that the algorithm is more effective and efficient than the existing one. This study is a step toward realistic applications of cost-sensitive learning.
Minimal cost feature selection of data with normal distribution measurement errors
Jun 03, 2013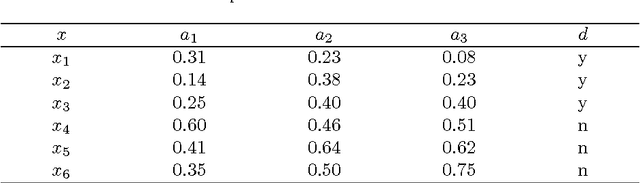
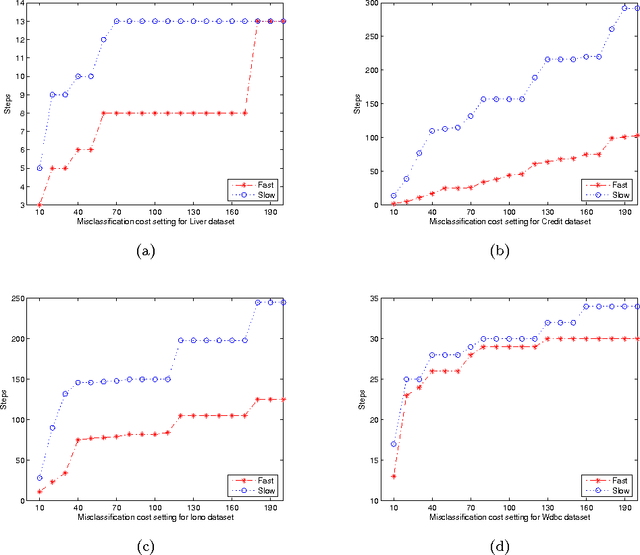

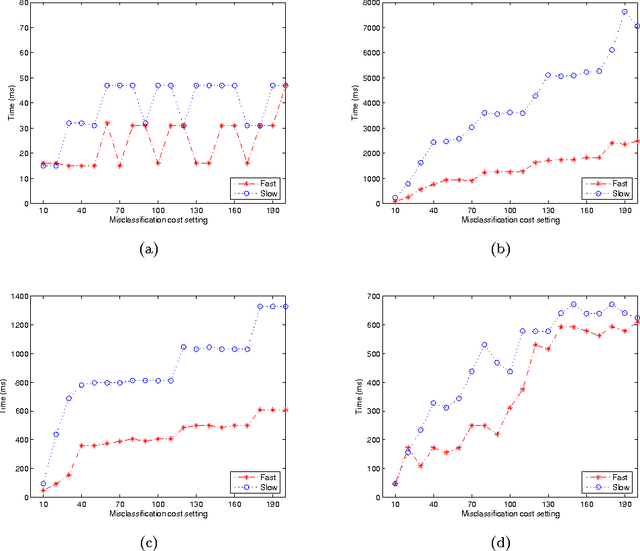
Minimal cost feature selection is devoted to obtain a trade-off between test costs and misclassification costs. This issue has been addressed recently on nominal data. In this paper, we consider numerical data with measurement errors and study minimal cost feature selection in this model. First, we build a data model with normal distribution measurement errors. Second, the neighborhood of each data item is constructed through the confidence interval. Comparing with discretized intervals, neighborhoods are more reasonable to maintain the information of data. Third, we define a new minimal total cost feature selection problem through considering the trade-off between test costs and misclassification costs. Fourth, we proposed a backtracking algorithm with three effective pruning techniques to deal with this problem. The algorithm is tested on four UCI data sets. Experimental results indicate that the pruning techniques are effective, and the algorithm is efficient for data sets with nearly one thousand objects.
Cost-Sensitive Feature Selection of Data with Errors
Jun 03, 2013In data mining applications, feature selection is an essential process since it reduces a model's complexity. The cost of obtaining the feature values must be taken into consideration in many domains. In this paper, we study the cost-sensitive feature selection problem on numerical data with measurement errors, test costs and misclassification costs. The major contributions of this paper are four-fold. First, a new data model is built to address test costs and misclassification costs as well as error boundaries. Second, a covering-based rough set with measurement errors is constructed. Given a confidence interval, the neighborhood is an ellipse in a two-dimension space, or an ellipsoidal in a three-dimension space, etc. Third, a new cost-sensitive feature selection problem is defined on this covering-based rough set. Fourth, both backtracking and heuristic algorithms are proposed to deal with this new problem. The algorithms are tested on six UCI (University of California - Irvine) data sets. Experimental results show that (1) the pruning techniques of the backtracking algorithm help reducing the number of operations significantly, and (2) the heuristic algorithm usually obtains optimal results. This study is a step toward realistic applications of cost-sensitive learning.
Characteristic matrix of covering and its application to boolean matrix decomposition and axiomatization
Mar 03, 2013Covering is an important type of data structure while covering-based rough sets provide an efficient and systematic theory to deal with covering data. In this paper, we use boolean matrices to represent and axiomatize three types of covering approximation operators. First, we define two types of characteristic matrices of a covering which are essentially square boolean ones, and their properties are studied. Through the characteristic matrices, three important types of covering approximation operators are concisely equivalently represented. Second, matrix representations of covering approximation operators are used in boolean matrix decomposition. We provide a sufficient and necessary condition for a square boolean matrix to decompose into the boolean product of another one and its transpose. And we develop an algorithm for this boolean matrix decomposition. Finally, based on the above results, these three types of covering approximation operators are axiomatized using boolean matrices. In a word, this work borrows extensively from boolean matrices and present a new view to study covering-based rough sets.
Cost-sensitive C4.5 with post-pruning and competition
Nov 17, 2012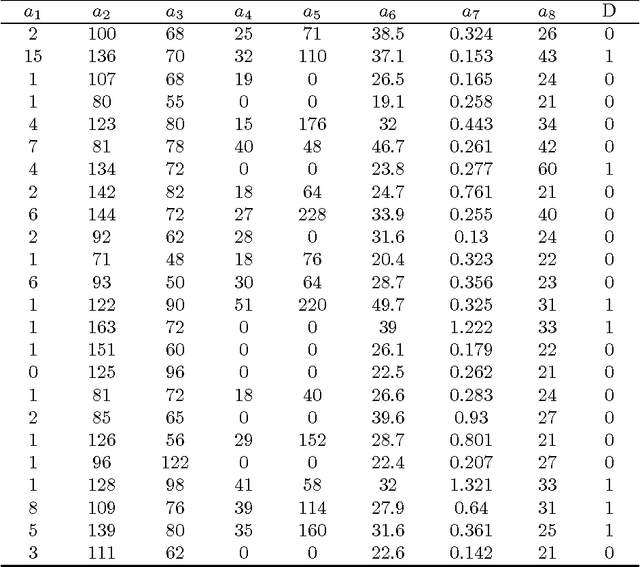
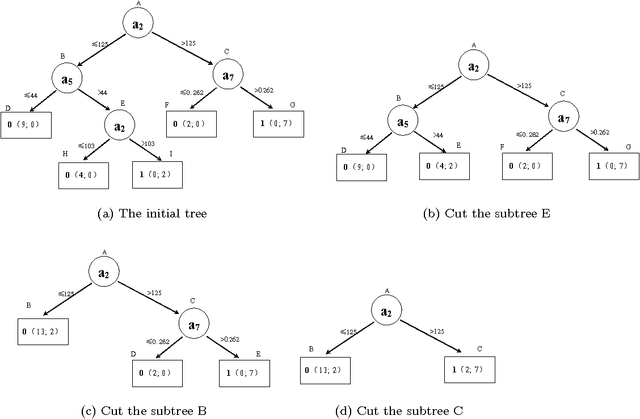

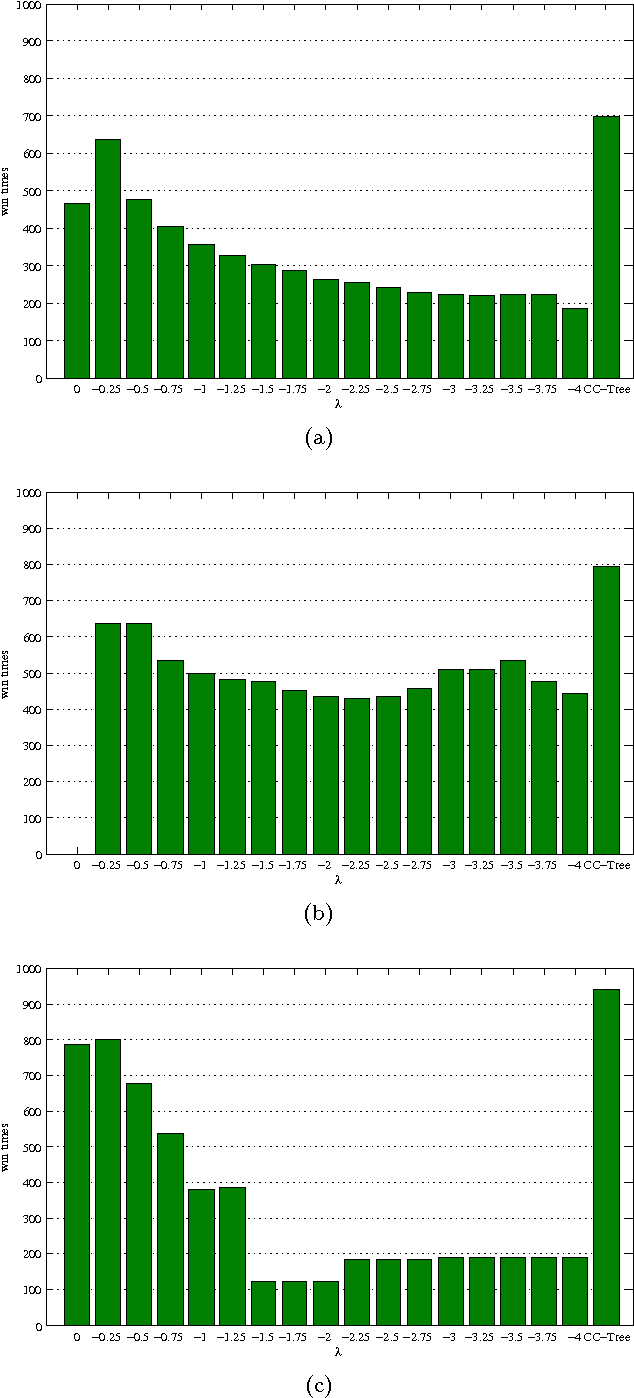
Decision tree is an effective classification approach in data mining and machine learning. In applications, test costs and misclassification costs should be considered while inducing decision trees. Recently, some cost-sensitive learning algorithms based on ID3 such as CS-ID3, IDX, \lambda-ID3 have been proposed to deal with the issue. These algorithms deal with only symbolic data. In this paper, we develop a decision tree algorithm inspired by C4.5 for numeric data. There are two major issues for our algorithm. First, we develop the test cost weighted information gain ratio as the heuristic information. According to this heuristic information, our algorithm is to pick the attribute that provides more gain ratio and costs less for each selection. Second, we design a post-pruning strategy through considering the tradeoff between test costs and misclassification costs of the generated decision tree. In this way, the total cost is reduced. Experimental results indicate that (1) our algorithm is stable and effective; (2) the post-pruning technique reduces the total cost significantly; (3) the competition strategy is effective to obtain a cost-sensitive decision tree with low cost.
Feature selection with test cost constraint
Sep 25, 2012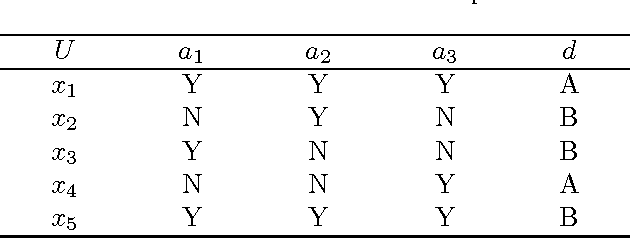
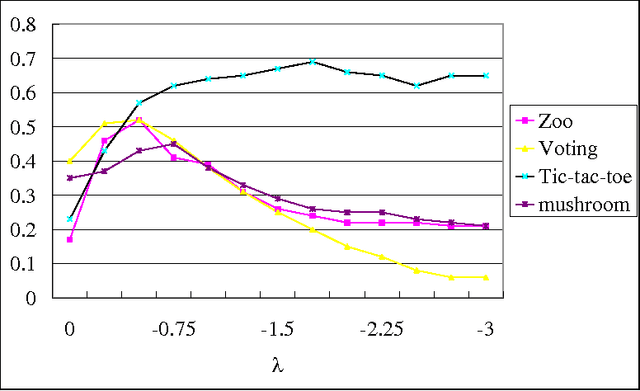
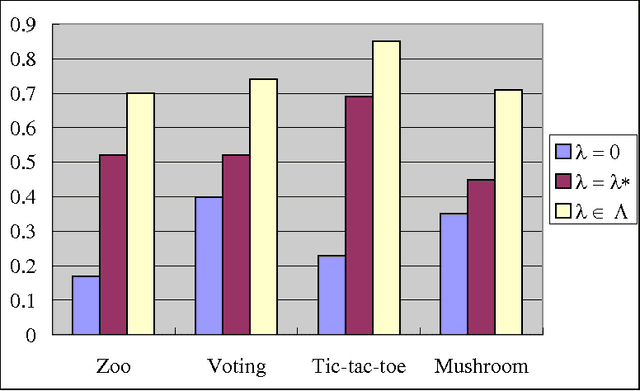
Feature selection is an important preprocessing step in machine learning and data mining. In real-world applications, costs, including money, time and other resources, are required to acquire the features. In some cases, there is a test cost constraint due to limited resources. We shall deliberately select an informative and cheap feature subset for classification. This paper proposes the feature selection with test cost constraint problem for this issue. The new problem has a simple form while described as a constraint satisfaction problem (CSP). Backtracking is a general algorithm for CSP, and it is efficient in solving the new problem on medium-sized data. As the backtracking algorithm is not scalable to large datasets, a heuristic algorithm is also developed. Experimental results show that the heuristic algorithm can find the optimal solution in most cases. We also redefine some existing feature selection problems in rough sets, especially in decision-theoretic rough sets, from the viewpoint of CSP. These new definitions provide insight to some new research directions.