 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Refinement: Joint Label and Feature Refinement for Unsupervised Domain Adaptive Person Re-Identification
Jan 17, 2021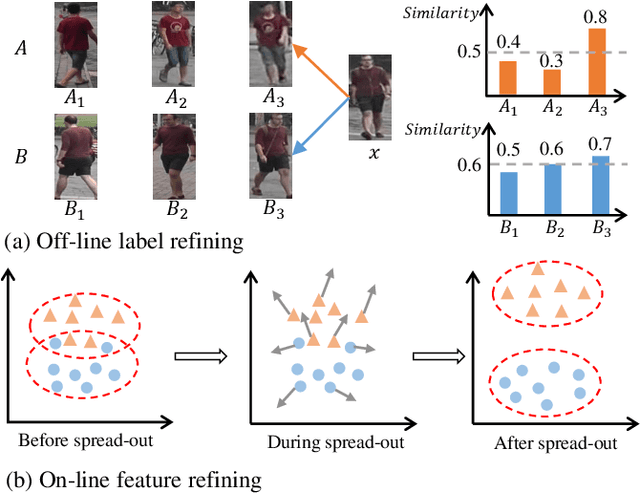
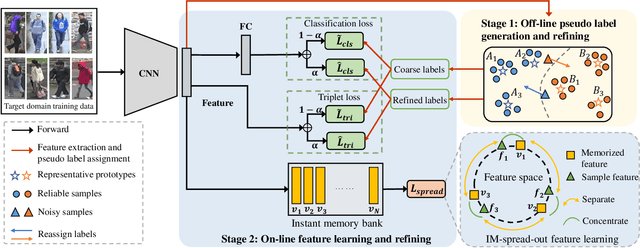
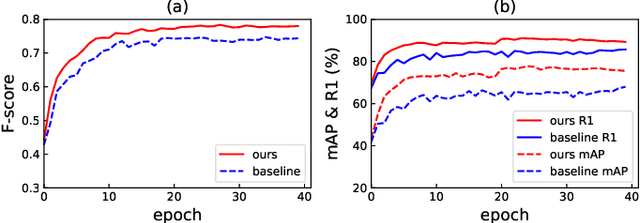
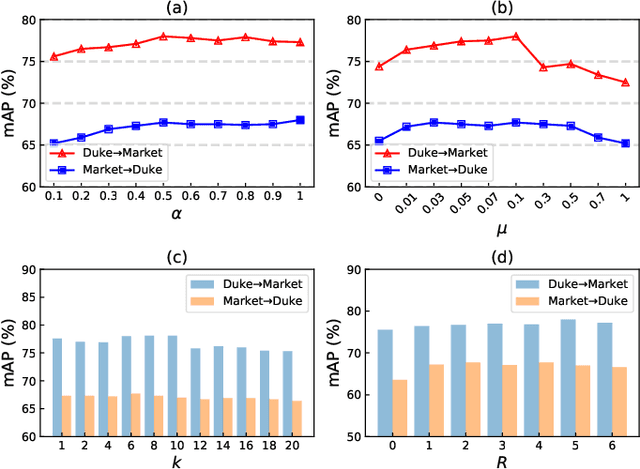
Unsupervised domain adaptive (UDA) person re-identification (re-ID) is a challenging task due to the missing of labels for the target domain data. To handle this problem, some recent works adopt clustering algorithms to off-line generate pseudo labels, which can then be used as the supervision signal for on-line feature learning in the target domain. However, the off-line generated labels often contain lots of noise that significantly hinders the discriminability of the on-line learned features, and thus limits the final UDA re-ID performance. To this end, we propose a novel approach, called Dual-Refinement, that jointly refines pseudo labels at the off-line clustering phase and features at the on-line training phase, to alternatively boost the label purity and feature discriminability in the target domain for more reliable re-ID. Specifically, at the off-line phase, a new hierarchical clustering scheme is proposed, which selects representative prototypes for every coarse cluster. Thus, labels can be effectively refined by using the inherent hierarchical information of person images. Besides, at the on-line phase, we propose an instant memory spread-out (IM-spread-out) regularization, that takes advantage of the proposed instant memory bank to store sample features of the entire dataset and enable spread-out feature learning over the entire training data instantly. Our Dual-Refinement method reduces the influence of noisy labels and refines the learned features within the alternative training process. Experiments demonstrate that our method outperforms the state-of-the-art methods by a large margin.
Spherical Feature Transform for Deep Metric Learning
Aug 04, 2020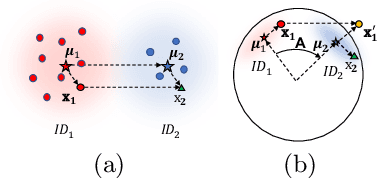
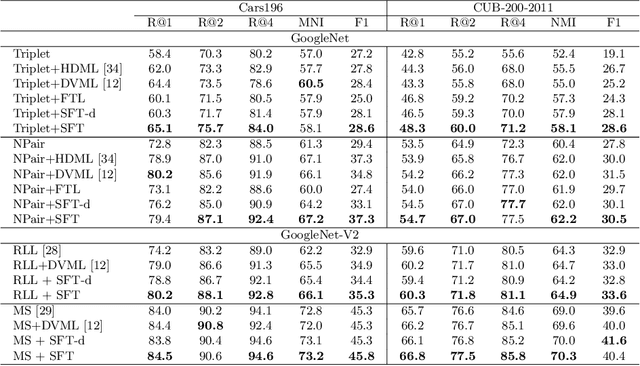


Data augmentation in feature space is effective to increase data diversity. Previous methods assume that different classes have the same covariance in their feature distributions. Thus, feature transform between different classes is performed via translation. However, this approach is no longer valid for recent deep metric learning scenarios, where feature normalization is widely adopted and all features lie on a hypersphere. This work proposes a novel spherical feature transform approach. It relaxes the assumption of identical covariance between classes to an assumption of similar covariances of different classes on a hypersphere. Consequently, the feature transform is performed by a rotation that respects the spherical data distributions. We provide a simple and effective training method, and in depth analysis on the relation between the two different transforms. Comprehensive experiments on various deep metric learning benchmarks and different baselines verify that our method achieves consistent performance improvement and state-of-the-art results.
Prime-Aware Adaptive Distillation
Aug 04, 2020
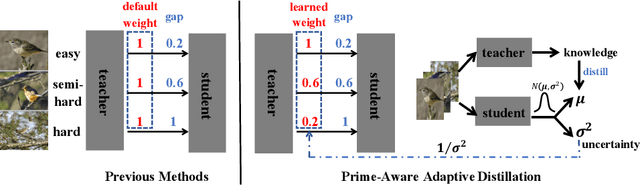
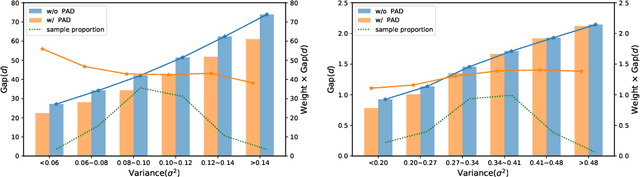

Knowledge distillation(KD) aims to improve the performance of a student network by mimicing the knowledge from a powerful teacher network. Existing methods focus on studying what knowledge should be transferred and treat all samples equally during training. This paper introduces the adaptive sample weighting to KD. We discover that previous effective hard mining methods are not appropriate for distillation. Furthermore, we propose Prime-Aware Adaptive Distillation (PAD) by the incorporation of uncertainty learning. PAD perceives the prime samples in distillation and then emphasizes their effect adaptively. PAD is fundamentally different from and would refine existing methods with the innovative view of unequal training. For this reason, PAD is versatile and has been applied in various tasks including classification, metric learning, and object detection. With ten teacher-student combinations on six datasets, PAD promotes the performance of existing distillation methods and outperforms recent state-of-the-art methods.
Compact Descriptors for Video Analysis: the Emerging MPEG Standard
Apr 26, 2017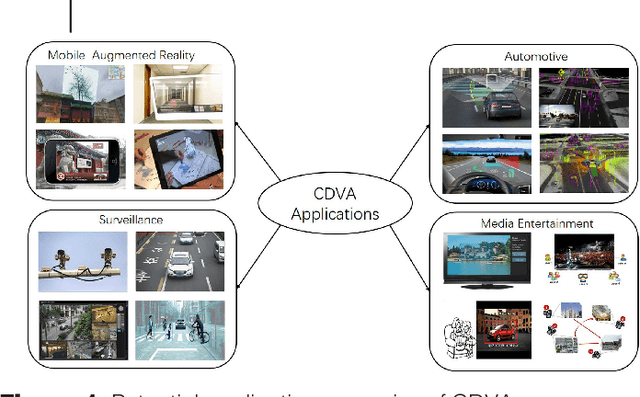
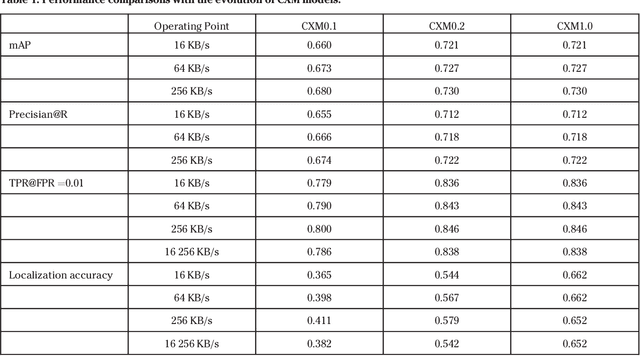
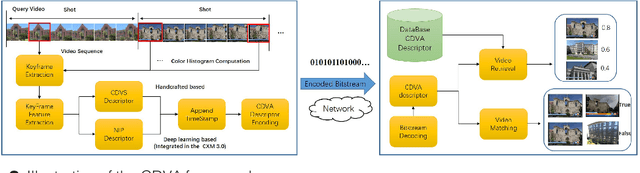
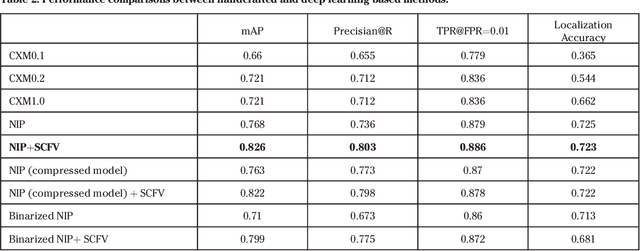
This paper provides an overview of the on-going compact descriptors for video analysis standard (CDVA) from the ISO/IEC moving pictures experts group (MPEG). MPEG-CDVA targets at defining a standardized bitstream syntax to enable interoperability in the context of video analysis applications. During the developments of MPEGCDVA, a series of techniques aiming to reduce the descriptor size and improve the video representation ability have been proposed. This article describes the new standard that is being developed and reports the performance of these key technical contributions.
Improving Object Detection with Region Similarity Learning
Mar 01, 2017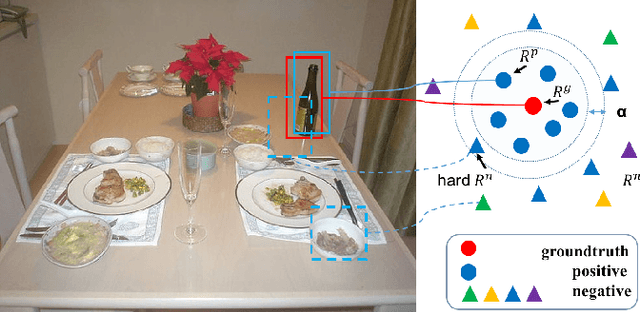
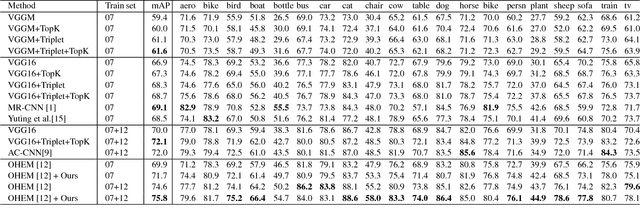

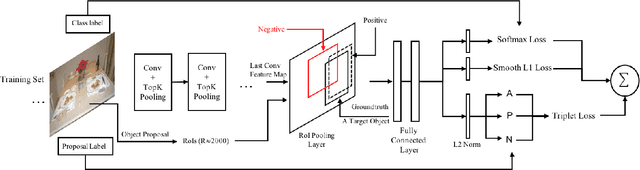
Object detection aims to identify instances of semantic objects of a certain class in images or videos. The success of state-of-the-art approaches is attributed to the significant progress of object proposal and convolutional neural networks (CNNs). Most promising detectors involve multi-task learning with an optimization objective of softmax loss and regression loss. The first is for multi-class categorization, while the latter is for improving localization accuracy. However, few of them attempt to further investigate the hardness of distinguishing different sorts of distracting background regions (i.e., negatives) from true object regions (i.e., positives). To improve the performance of classifying positive object regions vs. a variety of negative background regions, we propose to incorporate triplet embedding into learning objective. The triplet units are formed by assigning each negative region to a meaningful object class and establishing class- specific negatives, followed by triplets construction. Over the benchmark PASCAL VOC 2007, the proposed triplet em- bedding has improved the performance of well-known FastRCNN model with a mAP gain of 2.1%. In particular, the state-of-the-art approach OHEM can benefit from the triplet embedding and has achieved a mAP improvement of 1.2%.
Incorporating Intra-Class Variance to Fine-Grained Visual Recognition
Mar 01, 2017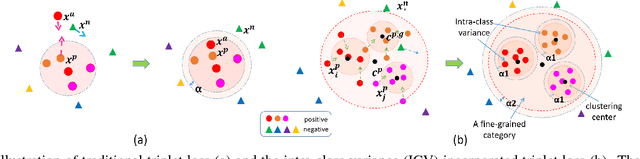
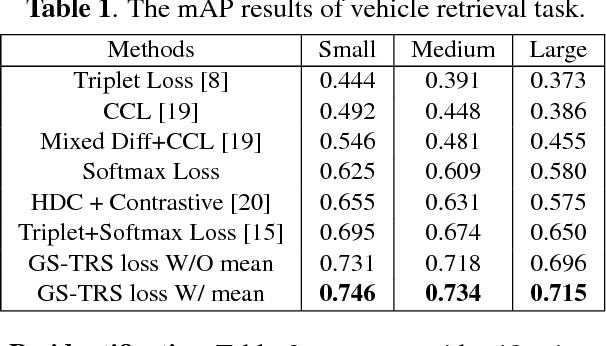

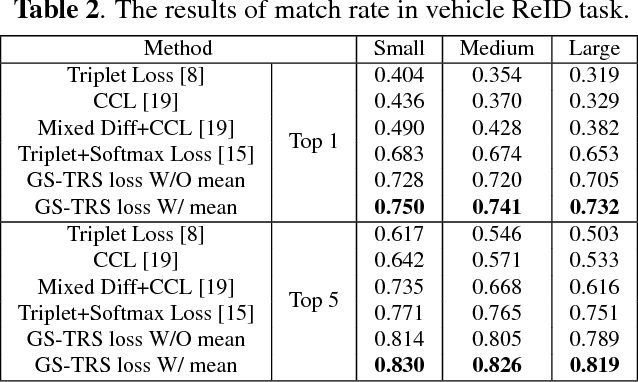
Fine-grained visual recognition aims to capture discriminative characteristics amongst visually similar categories. The state-of-the-art research work has significantly improved the fine-grained recognition performance by deep metric learning using triplet network. However, the impact of intra-category variance on the performance of recognition and robust feature representation has not been well studied. In this paper, we propose to leverage intra-class variance in metric learning of triplet network to improve the performance of fine-grained recognition. Through partitioning training images within each category into a few groups, we form the triplet samples across different categories as well as different groups, which is called Group Sensitive TRiplet Sampling (GS-TRS). Accordingly, the triplet loss function is strengthened by incorporating intra-class variance with GS-TRS, which may contribute to the optimization objective of triplet network. Extensive experiments over benchmark datasets CompCar and VehicleID show that the proposed GS-TRS has significantly outperformed state-of-the-art approaches in both classification and retrieval tasks.