 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaphors in Pre-Trained Language Models: Probing and Generalization Across Datasets and Languages
Mar 26, 2022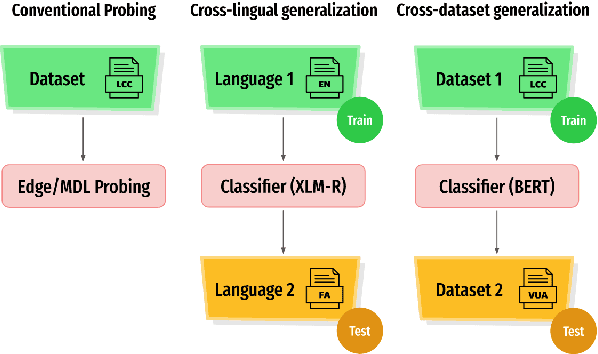

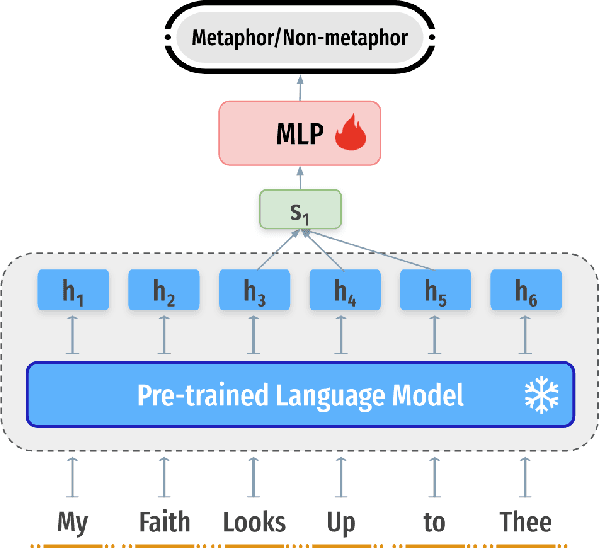
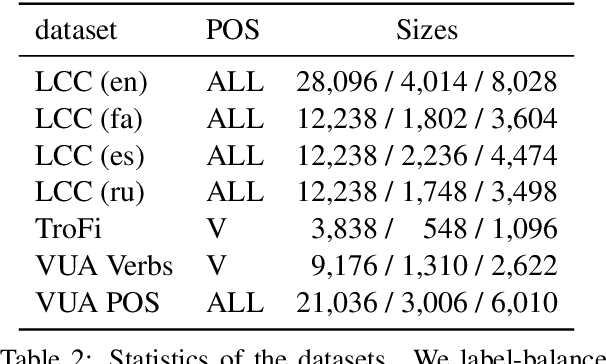
Human languages are full of metaphorical expressions. Metaphors help people understand the world by connecting new concepts and domains to more familiar ones. Large pre-trained language models (PLMs) are therefore assumed to encode metaphorical knowledge useful for NLP systems. In this paper, we investigate this hypothesis for PLMs, by probing metaphoricity information in their encodings, and by measuring the cross-lingual and cross-dataset generalization of this information. We present studies in multiple metaphor detection datasets and in four languages (i.e., English, Spanish, Russian, and Farsi). Our extensive experiments suggest that contextual representations in PLMs do encode metaphorical knowledge, and mostly in their middle layers. The knowledge is transferable between languages and datasets, especially when the annotation is consistent across training and testing sets. Our findings give helpful insights for both cognitive and NLP scientists.
PerCQA: Persian Community Question Answering Dataset
Dec 25, 2021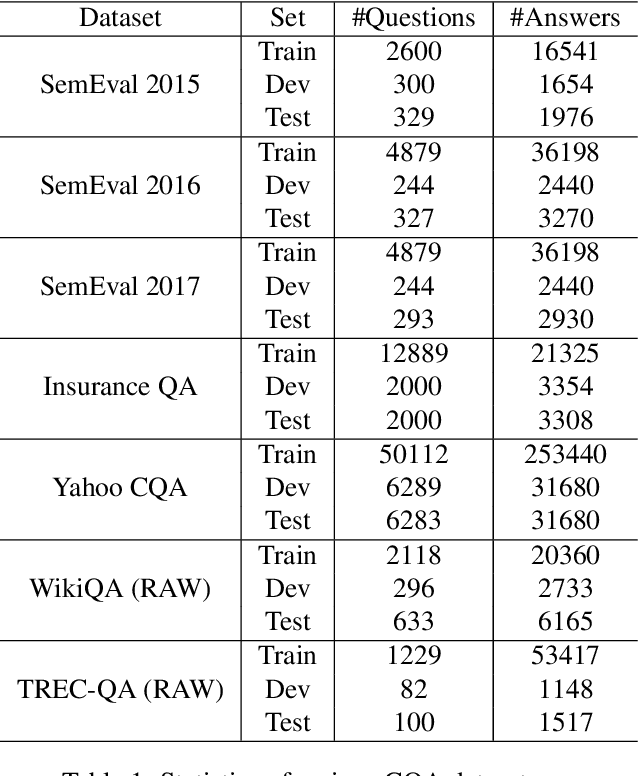


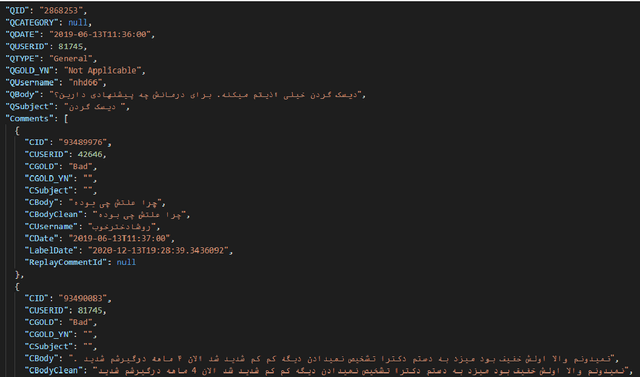
Community Question Answering (CQA) forums provide answers for many real-life questions. Thanks to the large size, these forums are very popular among machine learning researchers. Automatic answer selection, answer ranking, question retrieval, expert finding, and fact-checking are example learning tasks performed using CQA data. In this paper, we present PerCQA, the first Persian dataset for CQA. This dataset contains the questions and answers crawled from the most well-known Persian forum. After data acquisition, we provide rigorous annotation guidelines in an iterative process, and then the annotation of question-answer pairs in SemEvalCQA format. PerCQA contains 989 questions and 21,915 annotated answers. We make PerCQA publicly available to encourage more research in Persian CQA. We also build strong benchmarks for the task of answer selection in PerCQA by using mono- and multi-lingual pre-trained language models
ParsiNLU: A Suite of Language Understanding Challenges for Persian
Dec 11, 2020
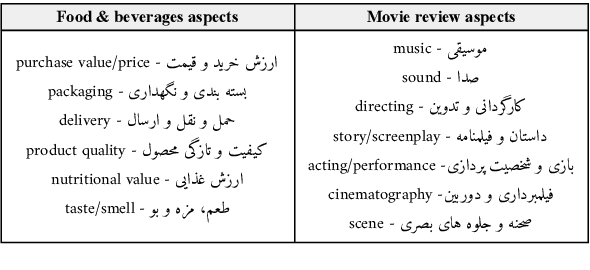
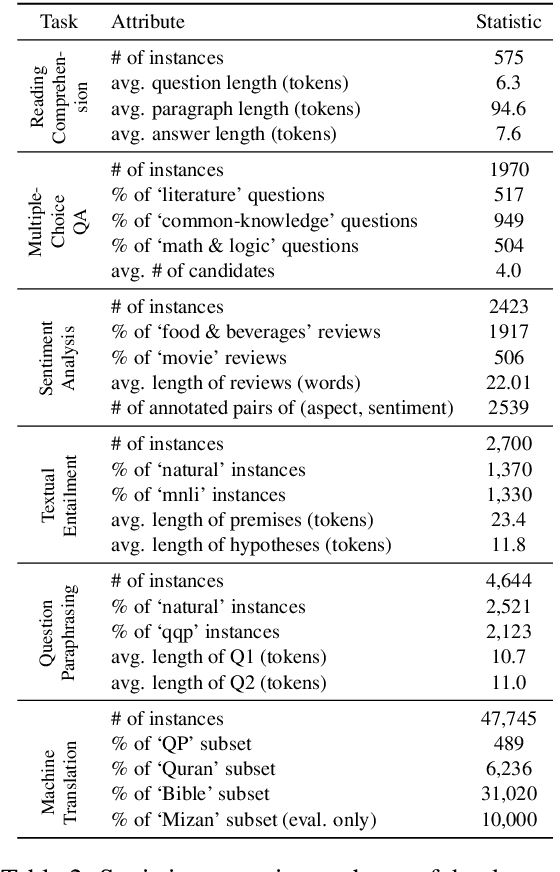
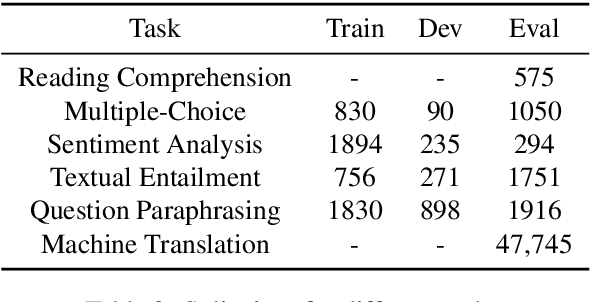
Despite the progress made in recent years in addressing natural language understanding (NLU) challenges, the majority of this progress remains to be concentrated on resource-rich languages like English. This work focuses on Persian language, one of the widely spoken languages in the world, and yet there are few NLU datasets available for this rich language. The availability of high-quality evaluation datasets is a necessity for reliable assessment of the progress on different NLU tasks and domains. We introduce ParsiNLU, the first benchmark in Persian language that includes a range of high-level tasks -- Reading Comprehension, Textual Entailment, etc. These datasets are collected in a multitude of ways, often involving manual annotations by native speakers. This results in over 14.5$k$ new instances across 6 distinct NLU tasks. Besides, we present the first results on state-of-the-art monolingual and multi-lingual pre-trained language-models on this benchmark and compare them with human performance, which provides valuable insights into our ability to tackle natural language understanding challenges in Persian. We hope ParsiNLU fosters further research and advances in Persian language understanding.
Cross-Domain Generalization Through Memorization: A Study of Nearest Neighbors in Neural Duplicate Question Detection
Nov 22, 2020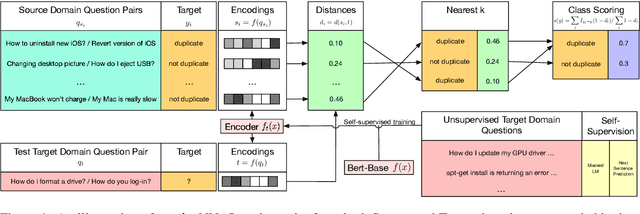
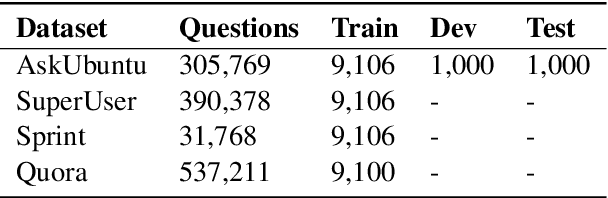
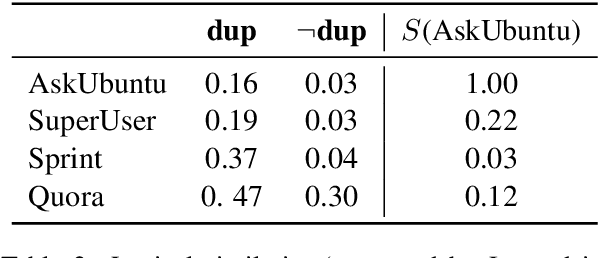
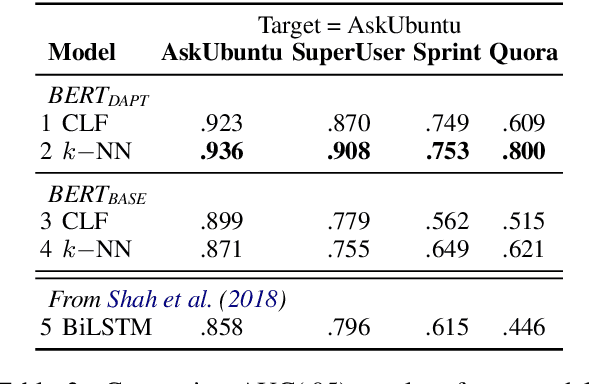
Duplicate question detection (DQD) is important to increase efficiency of community and automatic question answering systems. Unfortunately, gathering supervised data in a domain is time-consuming and expensive, and our ability to leverage annotations across domains is minimal. In this work, we leverage neural representations and study nearest neighbors for cross-domain generalization in DQD. We first encode question pairs of the source and target domain in a rich representation space and then using a k-nearest neighbour retrieval-based method, we aggregate the neighbors' labels and distances to rank pairs. We observe robust performance of this method in different cross-domain scenarios of StackExchange, Spring and Quora datasets, outperforming cross-entropy classification in multiple cases.
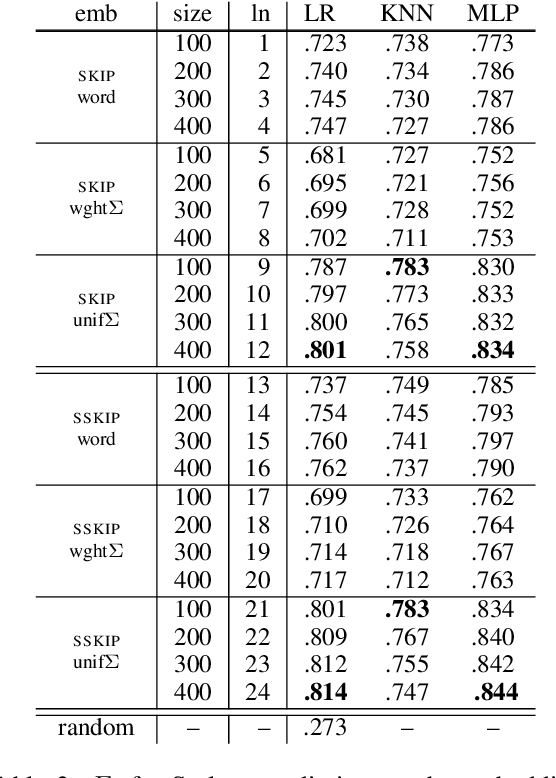
Quantifying the Contextualization of Word Representations with Semantic Class Probing
Apr 25, 2020

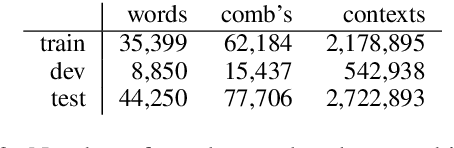
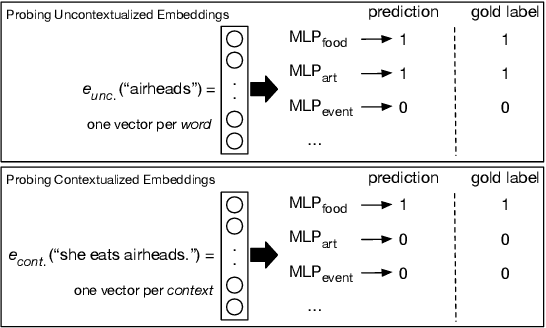
Pretrained language models have achieved a new state of the art on many NLP tasks, but there are still many open questions about how and why they work so well. We investigate the contextualization of words in BERT. We quantify the amount of contextualization, i.e., how well words are interpreted in context, by studying the extent to which semantic classes of a word can be inferred from its contextualized embeddings. Quantifying contextualization helps in understanding and utilizing pretrained language models. We show that top layer representations achieve high accuracy inferring semantic classes; that the strongest contextualization effects occur in the lower layers; that local context is mostly sufficient for semantic class inference; and that top layer representations are more task-specific after finetuning while lower layer representations are more transferable. Finetuning uncovers task related features, but pretrained knowledge is still largely preserved.
Robust Natural Language Inference Models with Example Forgetting
Nov 10, 2019
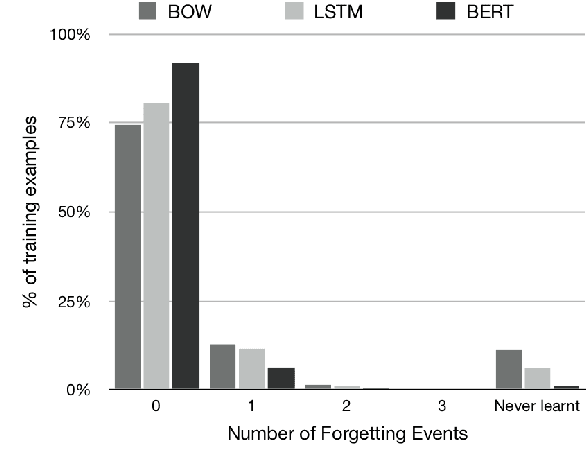
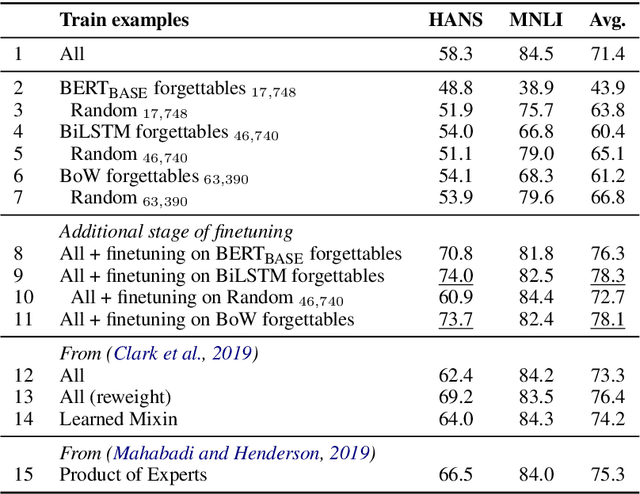
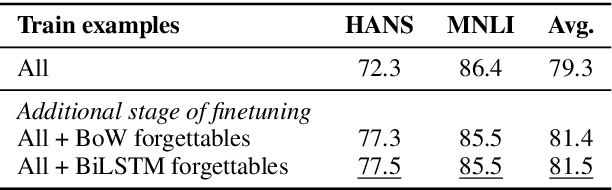
We investigate whether example forgetting, a recently introduced measure of hardness of examples, can be used to select training examples in order to increase robustness of natural language understanding models in a natural language inference task (MNLI). We analyze forgetting events for MNLI and provide evidence that forgettable examples under simpler models can be used to increase robustness of the recently proposed BERT model, measured by testing an MNLI trained model on HANS, a curated test set that exhibits a shift in distribution compared to the MNLI test set. Moreover, we show that, the "large" version of BERT is more robust than its "base" version but its robustness can still be improved with our approach.
Unsupervised Domain Adaptation of Contextual Embeddings for Low-Resource Duplicate Question Detection
Nov 06, 2019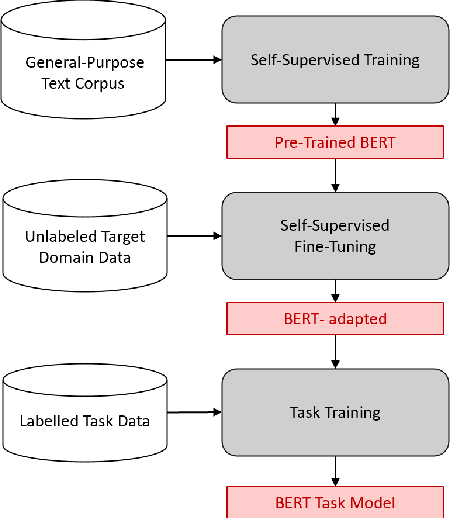
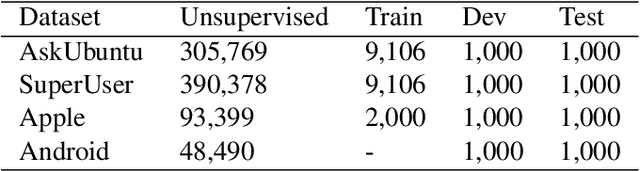
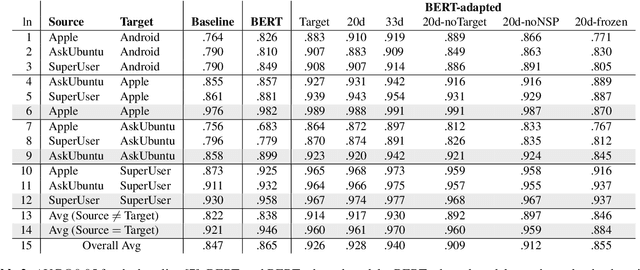
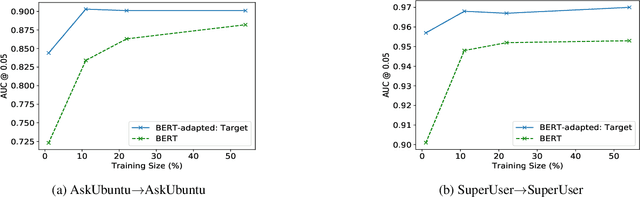
Answering questions is a primary goal of many conversational systems or search products. While most current systems have focused on answering questions against structured databases or curated knowledge graphs, on-line community forums or frequently asked questions (FAQ) lists offer an alternative source of information for question answering systems. Automatic duplicate question detection (DQD) is the key technology need for question answering systems to utilize existing online forums like StackExchange. Existing annotations of duplicate questions in such forums are community-driven, making them sparse or even completely missing for many domains. Therefore, it is important to transfer knowledge from related domains and tasks. Recently, contextual embedding models such as BERT have been outperforming many baselines by transferring self-supervised information to downstream tasks. In this paper, we apply BERT to DQD and advance it by unsupervised adaptation to StackExchange domains using self-supervised learning. We show the effectiveness of this adaptation for low-resource settings, where little or no training data is available from the target domain. Our analysis reveals that unsupervised BERT domain adaptation on even small amounts of data boosts the performance of BERT.
Toward Understanding The Effect Of Loss function On Then Performance Of Knowledge Graph Embedding
Oct 10, 2019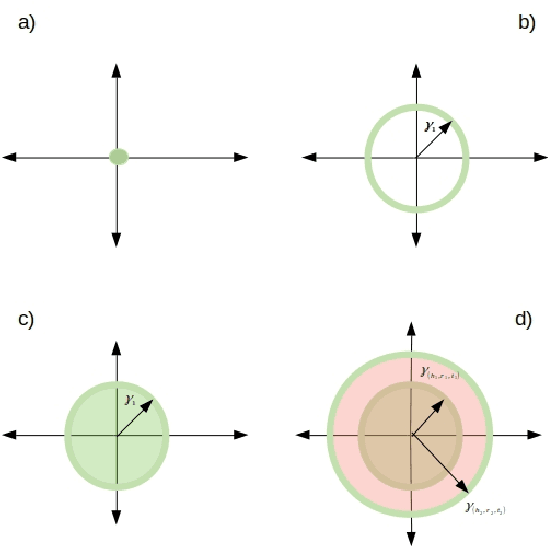
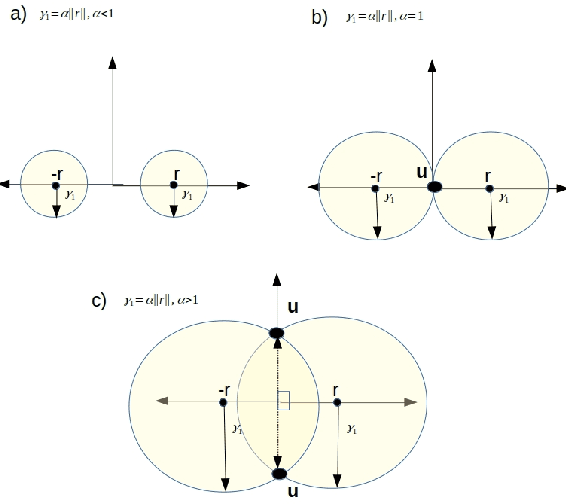
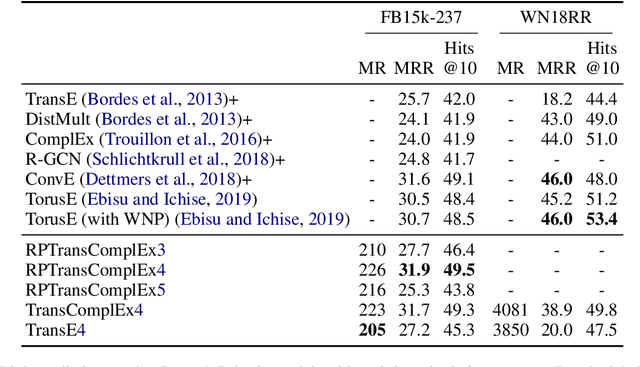
Knowledge graphs (KGs) represent world's facts in structured forms. KG completion exploits the existing facts in a KG to discover new ones. Translation-based embedding model (TransE) is a prominent formulation to do KG completion. Despite the efficiency of TransE in memory and time, it suffers from several limitations in encoding relation patterns such as symmetric, reflexive etc. To resolve this problem, most of the attempts have circled around the revision of the score function of TransE i.e., proposing a more complicated score function such as Trans(A, D, G, H, R, etc) to mitigate the limitations. In this paper, we tackle this problem from a different perspective. We show that existing theories corresponding to the limitations of TransE are inaccurate because they ignore the effect of loss function. Accordingly, we pose theoretical investigations of the main limitations of TransE in the light of loss function. To the best of our knowledge, this has not been investigated so far comprehensively. We show that by a proper selection of the loss function for training the TransE model, the main limitations of the model are mitigated. This is explained by setting upper-bound for the scores of positive samples, showing the region of truth (i.e., the region that a triple is considered positive by the model). Our theoretical proofs with experimental results fill the gap between the capability of translation-based class of embedding models and the loss function. The theories emphasise the importance of the selection of the loss functions for training the models. Our experimental evaluations on different loss functions used for training the models justify our theoretical proofs and confirm the importance of the loss functions on the performance.
Probing for Semantic Classes: Diagnosing the Meaning Content of Word Embeddings
Jun 09, 2019

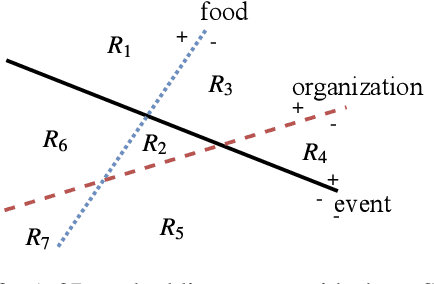
Word embeddings typically represent different meanings of a word in a single conflated vector. Empirical analysis of embeddings of ambiguous words is currently limited by the small size of manually annotated resources and by the fact that word senses are treated as unrelated individual concepts. We present a large dataset based on manual Wikipedia annotations and word senses, where word senses from different words are related by semantic classes. This is the basis for novel diagnostic tests for an embedding's content: we probe word embeddings for semantic classes and analyze the embedding space by classifying embeddings into semantic classes. Our main findings are: (i) Information about a sense is generally represented well in a single-vector embedding - if the sense is frequent. (ii) A classifier can accurately predict whether a word is single-sense or multi-sense, based only on its embedding. (iii) Although rare senses are not well represented in single-vector embeddings, this does not have negative impact on an NLP application whose performance depends on frequent senses.
Multi-Multi-View Learning: Multilingual and Multi-Representation Entity Typing
Oct 24, 2018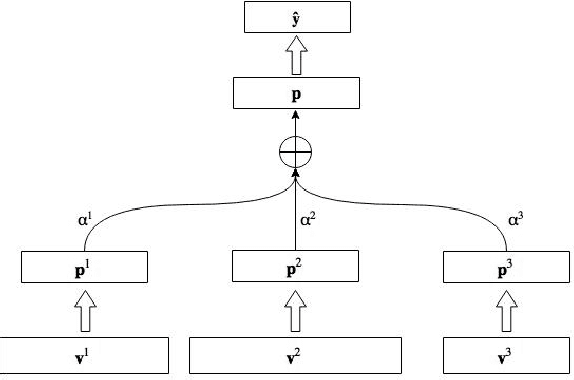
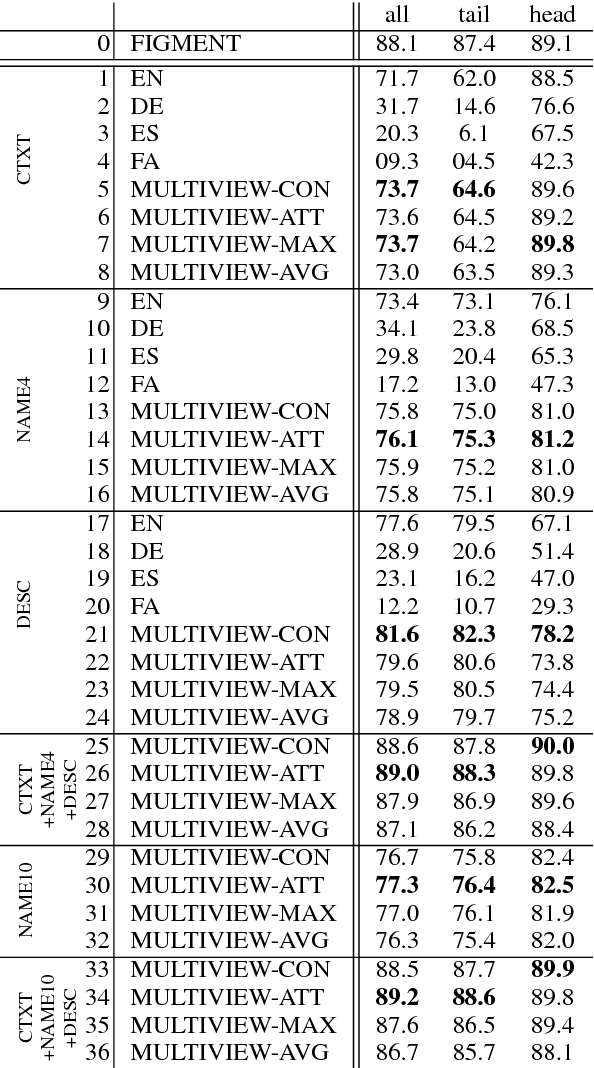
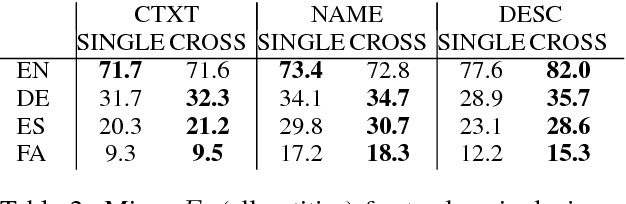
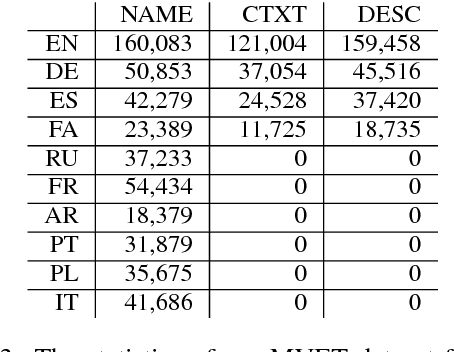
Knowledge bases (KBs) are paramount in NLP. We employ multiview learning for increasing accuracy and coverage of entity type information in KBs. We rely on two metaviews: language and representation. For language, we consider high-resource and low-resource languages from Wikipedia. For representation, we consider representations based on the context distribution of the entity (i.e., on its embedding), on the entity's name (i.e., on its surface form) and on its description in Wikipedia. The two metaviews language and representation can be freely combined: each pair of language and representation (e.g., German embedding, English description, Spanish name) is a distinct view. Our experiments on entity typing with fine-grained classes demonstrate the effectiveness of multiview learning. We release MVET, a large multiview - and, in particular, multilingual - entity typing dataset we created. Mono- and multilingual fine-grained entity typing systems can be evaluated on this dataset.