 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Domain Generalization Through Memorization: A Study of Nearest Neighbors in Neural Duplicate Question Detection
Nov 22, 2020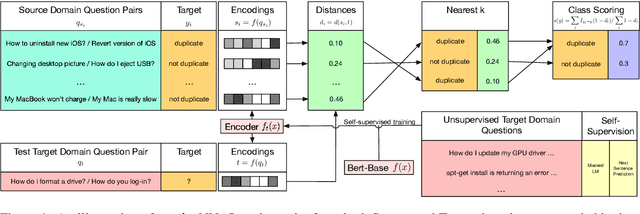
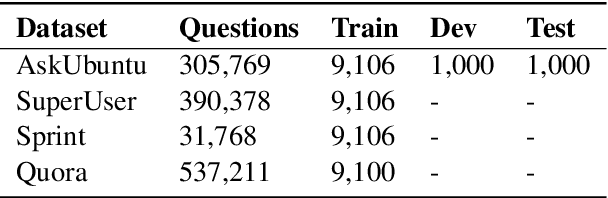
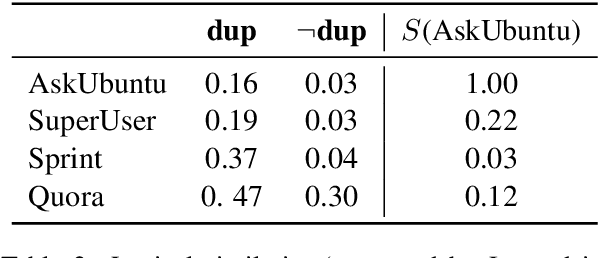
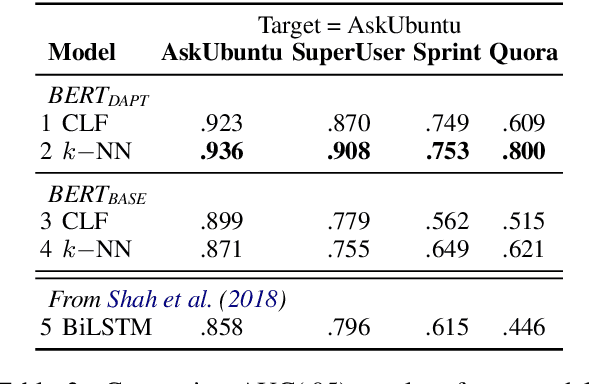
Duplicate question detection (DQD) is important to increase efficiency of community and automatic question answering systems. Unfortunately, gathering supervised data in a domain is time-consuming and expensive, and our ability to leverage annotations across domains is minimal. In this work, we leverage neural representations and study nearest neighbors for cross-domain generalization in DQD. We first encode question pairs of the source and target domain in a rich representation space and then using a k-nearest neighbour retrieval-based method, we aggregate the neighbors' labels and distances to rank pairs. We observe robust performance of this method in different cross-domain scenarios of StackExchange, Spring and Quora datasets, outperforming cross-entropy classification in multiple cases.
Towards Domain Adaptation from Limited Data for Question Answering Using Deep Neural Networks
Nov 06, 2019
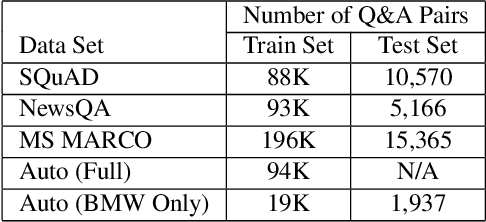
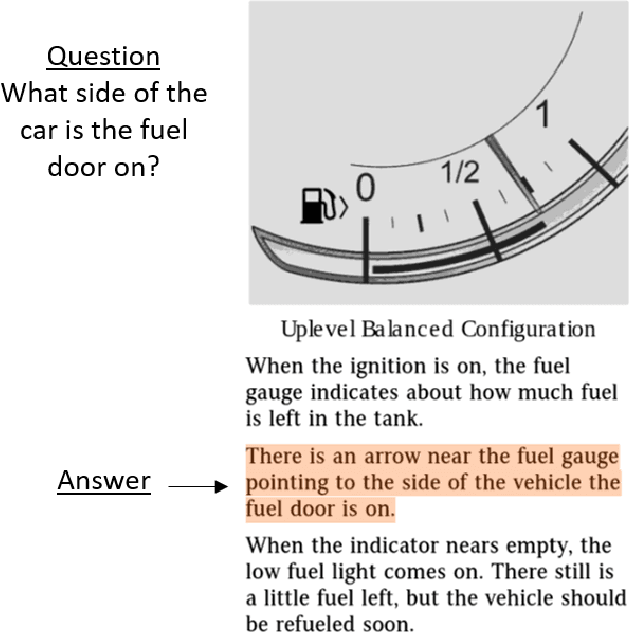
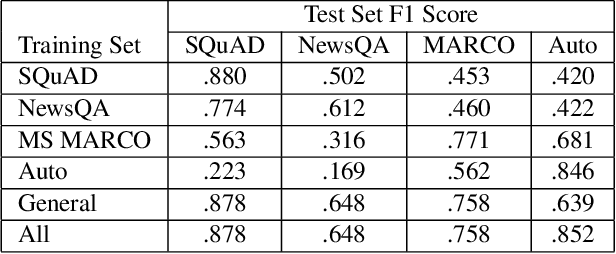
This paper explores domain adaptation for enabling question answering (QA) systems to answer questions posed against documents in new specialized domains. Current QA systems using deep neural network (DNN) technology have proven effective for answering general purpose factoid-style questions. However, current general purpose DNN models tend to be ineffective for use in new specialized domains. This paper explores the effectiveness of transfer learning techniques for this problem. In experiments on question answering in the automobile manual domain we demonstrate that standard DNN transfer learning techniques work surprisingly well in adapting DNN models to a new domain using limited amounts of annotated training data in the new domain.
Unsupervised Domain Adaptation of Contextual Embeddings for Low-Resource Duplicate Question Detection
Nov 06, 2019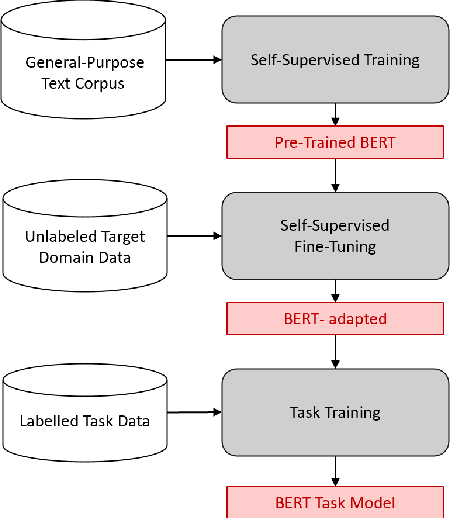
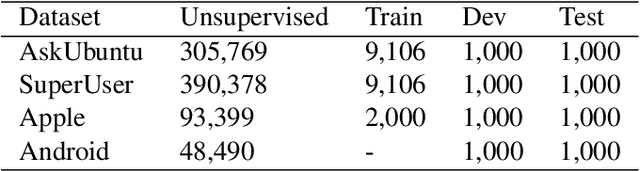
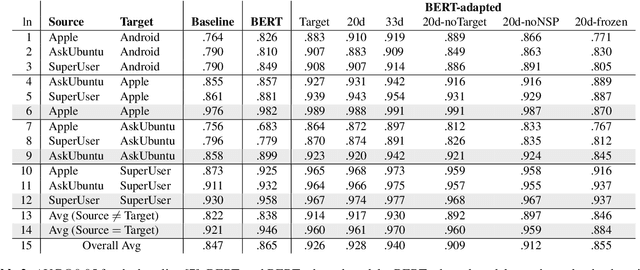
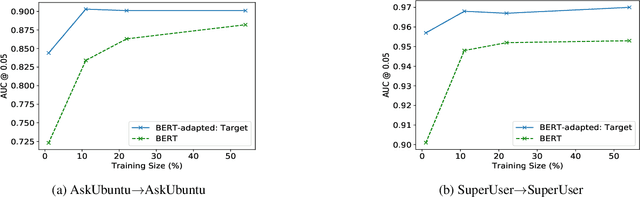
Answering questions is a primary goal of many conversational systems or search products. While most current systems have focused on answering questions against structured databases or curated knowledge graphs, on-line community forums or frequently asked questions (FAQ) lists offer an alternative source of information for question answering systems. Automatic duplicate question detection (DQD) is the key technology need for question answering systems to utilize existing online forums like StackExchange. Existing annotations of duplicate questions in such forums are community-driven, making them sparse or even completely missing for many domains. Therefore, it is important to transfer knowledge from related domains and tasks. Recently, contextual embedding models such as BERT have been outperforming many baselines by transferring self-supervised information to downstream tasks. In this paper, we apply BERT to DQD and advance it by unsupervised adaptation to StackExchange domains using self-supervised learning. We show the effectiveness of this adaptation for low-resource settings, where little or no training data is available from the target domain. Our analysis reveals that unsupervised BERT domain adaptation on even small amounts of data boosts the performance of BERT.
Probing for Semantic Classes: Diagnosing the Meaning Content of Word Embeddings
Jun 09, 2019

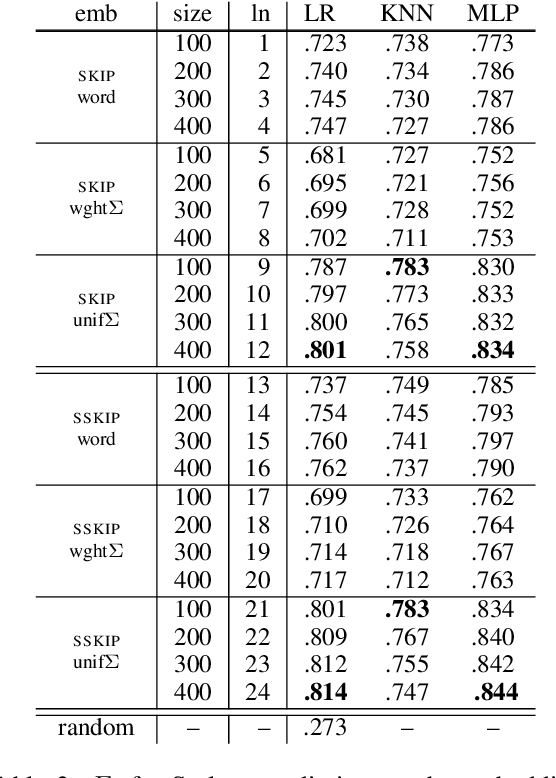
Word embeddings typically represent different meanings of a word in a single conflated vector. Empirical analysis of embeddings of ambiguous words is currently limited by the small size of manually annotated resources and by the fact that word senses are treated as unrelated individual concepts. We present a large dataset based on manual Wikipedia annotations and word senses, where word senses from different words are related by semantic classes. This is the basis for novel diagnostic tests for an embedding's content: we probe word embeddings for semantic classes and analyze the embedding space by classifying embeddings into semantic classes. Our main findings are: (i) Information about a sense is generally represented well in a single-vector embedding - if the sense is frequent. (ii) A classifier can accurately predict whether a word is single-sense or multi-sense, based only on its embedding. (iii) Although rare senses are not well represented in single-vector embeddings, this does not have negative impact on an NLP application whose performance depends on frequent senses.