 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBandit Theory and Thompson Sampling-Guided Directed Evolution for Sequence Optimization
Jun 05, 2022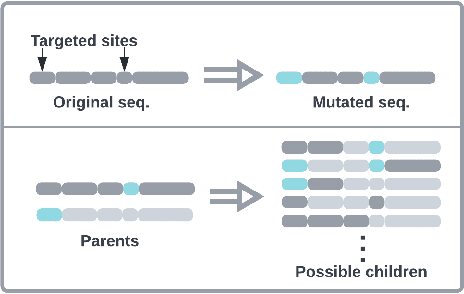
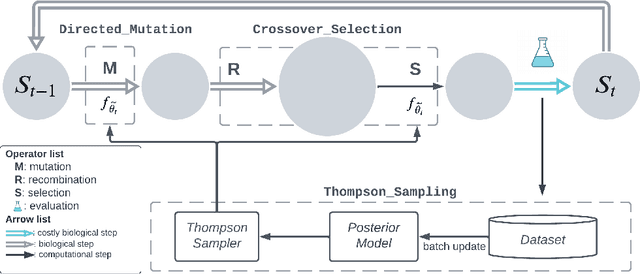
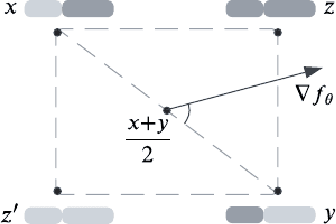
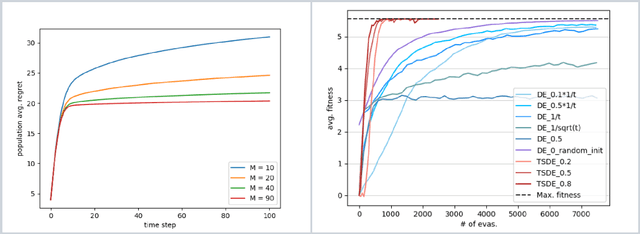
Directed Evolution (DE), a landmark wet-lab method originated in 1960s, enables discovery of novel protein designs via evolving a population of candidate sequences. Recent advances in biotechnology has made it possible to collect high-throughput data, allowing the use of machine learning to map out a protein's sequence-to-function relation. There is a growing interest in machine learning-assisted DE for accelerating protein optimization. Yet the theoretical understanding of DE, as well as the use of machine learning in DE, remains limited. In this paper, we connect DE with the bandit learning theory and make a first attempt to study regret minimization in DE. We propose a Thompson Sampling-guided Directed Evolution (TS-DE) framework for sequence optimization, where the sequence-to-function mapping is unknown and querying a single value is subject to costly and noisy measurements. TS-DE updates a posterior of the function based on collected measurements. It uses a posterior-sampled function estimate to guide the crossover recombination and mutation steps in DE. In the case of a linear model, we show that TS-DE enjoys a Bayesian regret of order $\tilde O(d^{2}\sqrt{MT})$, where $d$ is feature dimension, $M$ is population size and $T$ is number of rounds. This regret bound is nearly optimal, confirming that bandit learning can provably accelerate DE. It may have implications for more general sequence optimization and evolutionary algorithms.
Byzantine-Robust Online and Offline Distributed Reinforcement Learning
Jun 01, 2022We consider a distributed reinforcement learning setting where multiple agents separately explore the environment and communicate their experiences through a central server. However, $\alpha$-fraction of agents are adversarial and can report arbitrary fake information. Critically, these adversarial agents can collude and their fake data can be of any sizes. We desire to robustly identify a near-optimal policy for the underlying Markov decision process in the presence of these adversarial agents. Our main technical contribution is Weighted-Clique, a novel algorithm for the robust mean estimation from batches problem, that can handle arbitrary batch sizes. Building upon this new estimator, in the offline setting, we design a Byzantine-robust distributed pessimistic value iteration algorithm; in the online setting, we design a Byzantine-robust distributed optimistic value iteration algorithm. Both algorithms obtain near-optimal sample complexities and achieve superior robustness guarantee than prior works.
Provable Benefits of Representational Transfer in Reinforcement Learning
May 29, 2022

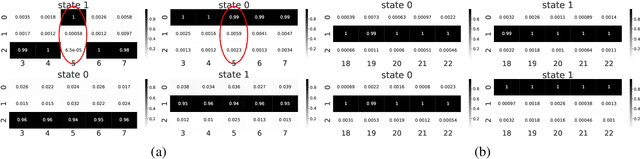
We study the problem of representational transfer in RL, where an agent first pretrains in a number of source tasks to discover a shared representation, which is subsequently used to learn a good policy in a target task. We propose a new notion of task relatedness between source and target tasks, and develop a novel approach for representational transfer under this assumption. Concretely, we show that given generative access to source tasks, we can discover a representation, using which subsequent linear RL techniques quickly converge to a near-optimal policy, with only online access to the target task. The sample complexity is close to knowing the ground truth features in the target task, and comparable to prior representation learning results in the source tasks. We complement our positive results with lower bounds without generative access, and validate our findings with empirical evaluation on rich observation MDPs that require deep exploration.
Off-Policy Fitted Q-Evaluation with Differentiable Function Approximators: Z-Estimation and Inference Theory
Feb 10, 2022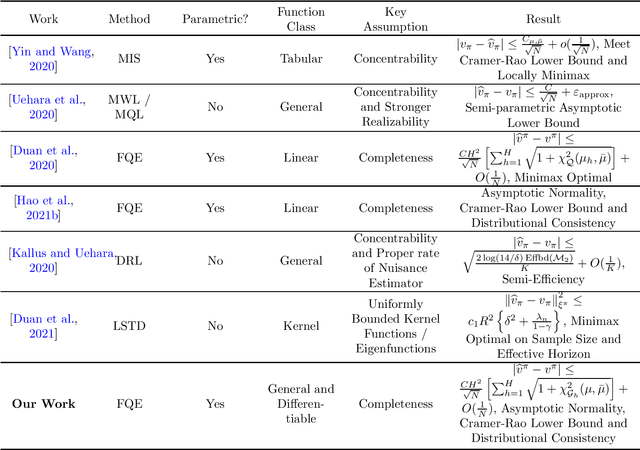
Off-Policy Evaluation (OPE) serves as one of the cornerstones in Reinforcement Learning (RL). Fitted Q Evaluation (FQE) with various function approximators, especially deep neural networks, has gained practical success. While statistical analysis has proved FQE to be minimax-optimal with tabular, linear and several nonparametric function families, its practical performance with more general function approximator is less theoretically understood. We focus on FQE with general differentiable function approximators, making our theory applicable to neural function approximations. We approach this problem using the Z-estimation theory and establish the following results: The FQE estimation error is asymptotically normal with explicit variance determined jointly by the tangent space of the function class at the ground truth, the reward structure, and the distribution shift due to off-policy learning; The finite-sample FQE error bound is dominated by the same variance term, and it can also be bounded by function class-dependent divergence, which measures how the off-policy distribution shift intertwines with the function approximator. In addition, we study bootstrapping FQE estimators for error distribution inference and estimating confidence intervals, accompanied by a Cramer-Rao lower bound that matches our upper bounds. The Z-estimation analysis provides a generalizable theoretical framework for studying off-policy estimation in RL and provides sharp statistical theory for FQE with differentiable function approximators.
Efficient Reinforcement Learning in Block MDPs: A Model-free Representation Learning Approach
Feb 02, 2022
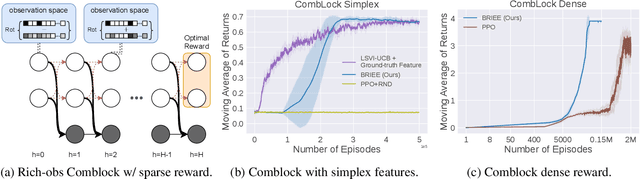
We present BRIEE (Block-structured Representation learning with Interleaved Explore Exploit), an algorithm for efficient reinforcement learning in Markov Decision Processes with block-structured dynamics (i.e., Block MDPs), where rich observations are generated from a set of unknown latent states. BRIEE interleaves latent states discovery, exploration, and exploitation together, and can provably learn a near-optimal policy with sample complexity scaling polynomially in the number of latent states, actions, and the time horizon, with no dependence on the size of the potentially infinite observation space. Empirically, we show that BRIEE is more sample efficient than the state-of-art Block MDP algorithm HOMER and other empirical RL baselines on challenging rich-observation combination lock problems that require deep exploration.
Optimal Estimation of Off-Policy Policy Gradient via Double Fitted Iteration
Jan 31, 2022
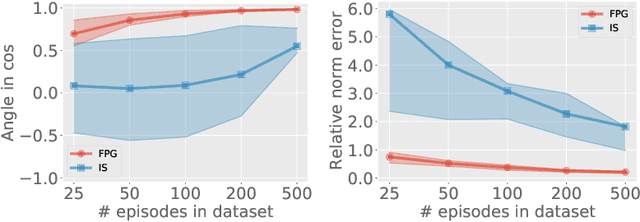
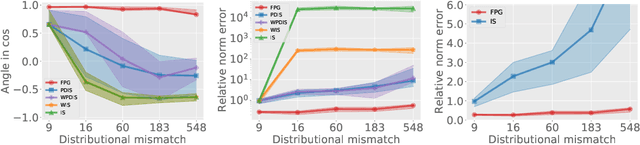
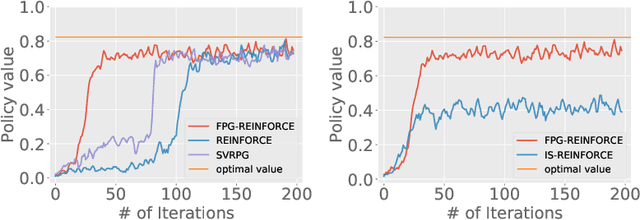
Policy gradient (PG) estimation becomes a challenge when we are not allowed to sample with the target policy but only have access to a dataset generated by some unknown behavior policy. Conventional methods for off-policy PG estimation often suffer from either significant bias or exponentially large variance. In this paper, we propose the double Fitted PG estimation (FPG) algorithm. FPG can work with an arbitrary policy parameterization, assuming access to a Bellman-complete value function class. In the case of linear value function approximation, we provide a tight finite-sample upper bound on policy gradient estimation error, that is governed by the amount of distribution mismatch measured in feature space. We also establish the asymptotic normality of FPG estimation error with a precise covariance characterization, which is further shown to be statistically optimal with a matching Cramer-Rao lower bound. Empirically, we evaluate the performance of FPG on both policy gradient estimation and policy optimization, using either softmax tabular or ReLU policy networks. Under various metrics, our results show that FPG significantly outperforms existing off-policy PG estimation methods based on importance sampling and variance reduction techniques.
Representation Learning for Online and Offline RL in Low-rank MDPs
Oct 09, 2021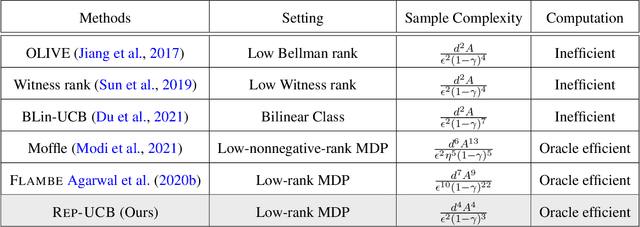
This work studies the question of Representation Learning in RL: how can we learn a compact low-dimensional representation such that on top of the representation we can perform RL procedures such as exploration and exploitation, in a sample efficient manner. We focus on the low-rank Markov Decision Processes (MDPs) where the transition dynamics correspond to a low-rank transition matrix. Unlike prior works that assume the representation is known (e.g., linear MDPs), here we need to learn the representation for the low-rank MDP. We study both the online RL and offline RL settings. For the online setting, operating with the same computational oracles used in FLAMBE (Agarwal et.al), the state-of-art algorithm for learning representations in low-rank MDPs, we propose an algorithm REP-UCB Upper Confidence Bound driven Representation learning for RL), which significantly improves the sample complexity from $\widetilde{O}( A^9 d^7 / (\epsilon^{10} (1-\gamma)^{22}))$ for FLAMBE to $\widetilde{O}( A^4 d^4 / (\epsilon^2 (1-\gamma)^{3}) )$ with $d$ being the rank of the transition matrix (or dimension of the ground truth representation), $A$ being the number of actions, and $\gamma$ being the discounted factor. Notably, REP-UCB is simpler than FLAMBE, as it directly balances the interplay between representation learning, exploration, and exploitation, while FLAMBE is an explore-then-commit style approach and has to perform reward-free exploration step-by-step forward in time. For the offline RL setting, we develop an algorithm that leverages pessimism to learn under a partial coverage condition: our algorithm is able to compete against any policy as long as it is covered by the offline distribution.
Corruption-Robust Offline Reinforcement Learning
Jun 11, 2021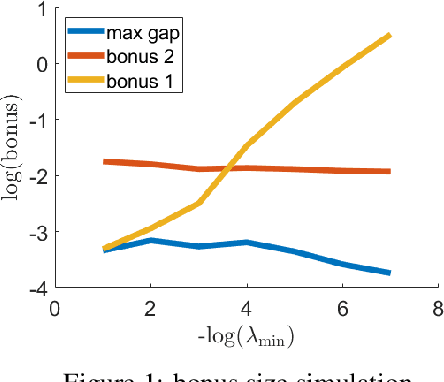
We study the adversarial robustness in offline reinforcement learning. Given a batch dataset consisting of tuples $(s, a, r, s')$, an adversary is allowed to arbitrarily modify $\epsilon$ fraction of the tuples. From the corrupted dataset the learner aims to robustly identify a near-optimal policy. We first show that a worst-case $\Omega(d\epsilon)$ optimality gap is unavoidable in linear MDP of dimension $d$, even if the adversary only corrupts the reward element in a tuple. This contrasts with dimension-free results in robust supervised learning and best-known lower-bound in the online RL setting with corruption. Next, we propose robust variants of the Least-Square Value Iteration (LSVI) algorithm utilizing robust supervised learning oracles, which achieve near-matching performances in cases both with and without full data coverage. The algorithm requires the knowledge of $\epsilon$ to design the pessimism bonus in the no-coverage case. Surprisingly, in this case, the knowledge of $\epsilon$ is necessary, as we show that being adaptive to unknown $\epsilon$ is impossible.This again contrasts with recent results on corruption-robust online RL and implies that robust offline RL is a strictly harder problem.
Controllable and Diverse Text Generation in E-commerce
Feb 23, 2021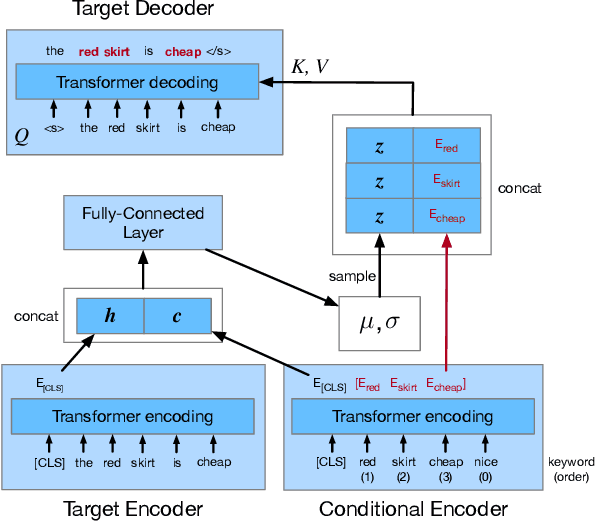
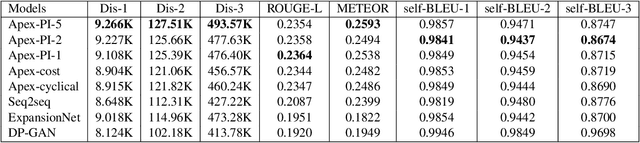
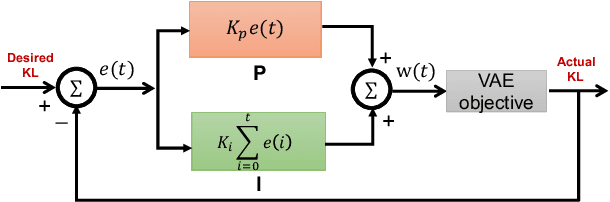
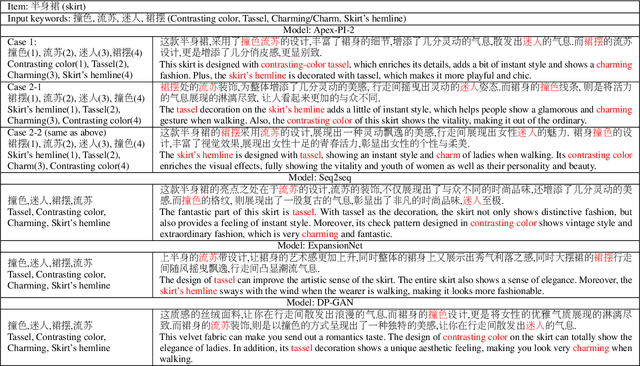
In E-commerce, a key challenge in text generation is to find a good trade-off between word diversity and accuracy (relevance) in order to make generated text appear more natural and human-like. In order to improve the relevance of generated results, conditional text generators were developed that use input keywords or attributes to produce the corresponding text. Prior work, however, do not finely control the diversity of automatically generated sentences. For example, it does not control the order of keywords to put more relevant ones first. Moreover, it does not explicitly control the balance between diversity and accuracy. To remedy these problems, we propose a fine-grained controllable generative model, called~\textit{Apex}, that uses an algorithm borrowed from automatic control (namely, a variant of the \textit{proportional, integral, and derivative (PID) controller}) to precisely manipulate the diversity/accuracy trade-off of generated text. The algorithm is injected into a Conditional Variational Autoencoder (CVAE), allowing \textit{Apex} to control both (i) the order of keywords in the generated sentences (conditioned on the input keywords and their order), and (ii) the trade-off between diversity and accuracy. Evaluation results on real-world datasets show that the proposed method outperforms existing generative models in terms of diversity and relevance. Apex is currently deployed to generate production descriptions and item recommendation reasons in Taobao owned by Alibaba, the largest E-commerce platform in China. The A/B production test results show that our method improves click-through rate (CTR) by 13.17\% compared to the existing method for production descriptions. For item recommendation reason, it is able to increase CTR by 6.89\% and 1.42\% compared to user reviews and top-K item recommendation without reviews, respectively.
Reward Poisoning in Reinforcement Learning: Attacks Against Unknown Learners in Unknown Environments
Feb 16, 2021We study black-box reward poisoning attacks against reinforcement learning (RL), in which an adversary aims to manipulate the rewards to mislead a sequence of RL agents with unknown algorithms to learn a nefarious policy in an environment unknown to the adversary a priori. That is, our attack makes minimum assumptions on the prior knowledge of the adversary: it has no initial knowledge of the environment or the learner, and neither does it observe the learner's internal mechanism except for its performed actions. We design a novel black-box attack, U2, that can provably achieve a near-matching performance to the state-of-the-art white-box attack, demonstrating the feasibility of reward poisoning even in the most challenging black-box setting.