 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Uniform Point Distribution in Feature-preserving Point Cloud Filtering
Jan 17, 2022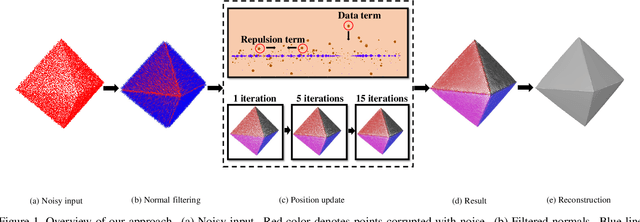
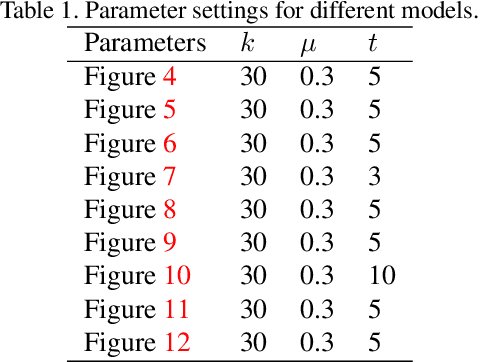
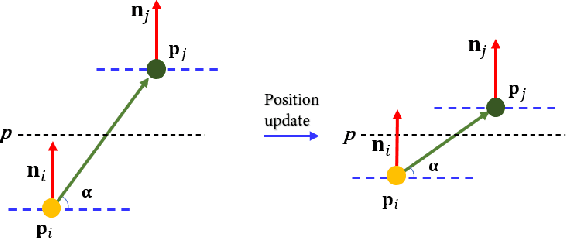
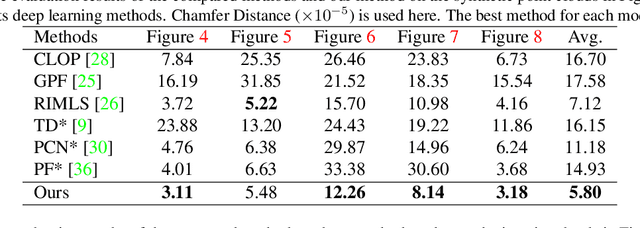
As a popular representation of 3D data, point cloud may contain noise and need to be filtered before use. Existing point cloud filtering methods either cannot preserve sharp features or result in uneven point distribution in the filtered output. To address this problem, this paper introduces a point cloud filtering method that considers both point distribution and feature preservation during filtering. The key idea is to incorporate a repulsion term with a data term in energy minimization. The repulsion term is responsible for the point distribution, while the data term is to approximate the noisy surfaces while preserving the geometric features. This method is capable of handling models with fine-scale features and sharp features. Extensive experiments show that our method yields better results with a more uniform point distribution ($5.8\times10^{-5}$ Chamfer Distance on average) in seconds.
3D Intracranial Aneurysm Classification and Segmentation via Unsupervised Dual-branch Learning
Jan 17, 2022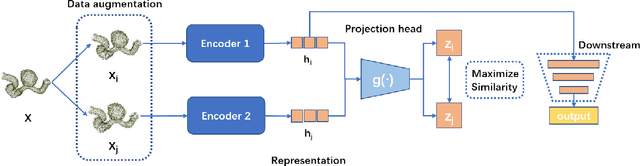
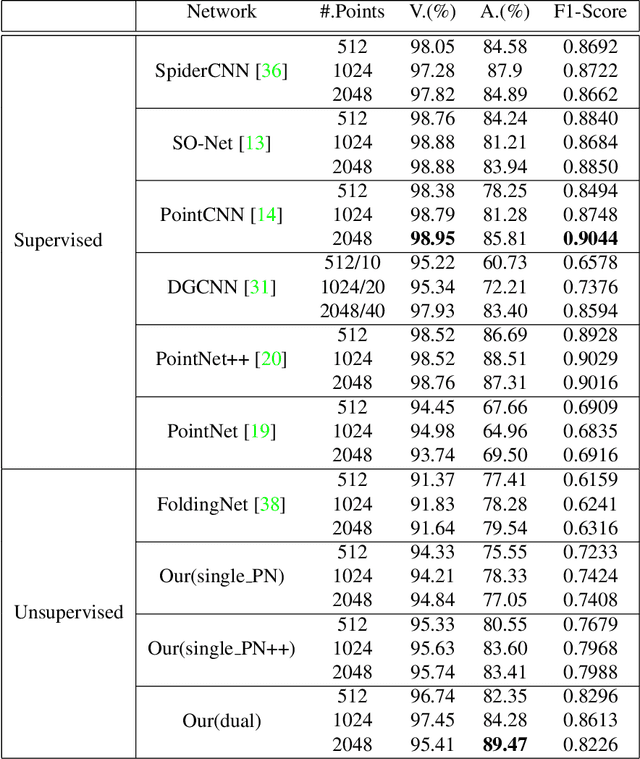
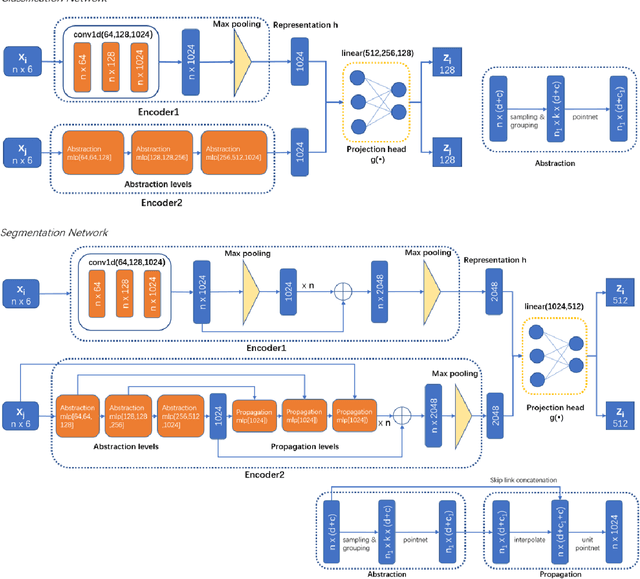
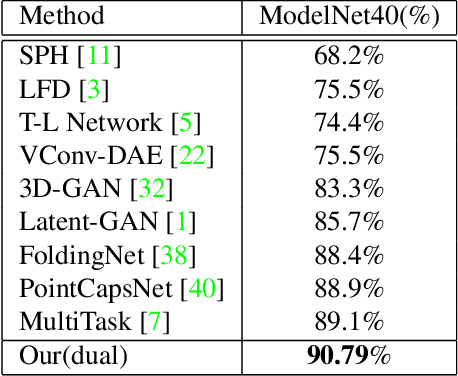
Intracranial aneurysms are common nowadays and how to detect them intelligently is of great significance in digital health. While most existing deep learning research focused on medical images in a supervised way, we introduce an unsupervised method for the detection of intracranial aneurysms based on 3D point cloud data. In particular, our method consists of two stages: unsupervised pre-training and downstream tasks. As for the former, the main idea is to pair each point cloud with its jittered counterpart and maximise their correspondence. Then we design a dual-branch contrastive network with an encoder for each branch and a subsequent common projection head. As for the latter, we design simple networks for supervised classification and segmentation training. Experiments on the public dataset (IntrA) show that our unsupervised method achieves comparable or even better performance than some state-of-the-art supervised techniques, and it is most prominent in the detection of aneurysmal vessels. Experiments on the ModelNet40 also show that our method achieves the accuracy of 90.79\% which outperforms existing state-of-the-art unsupervised models.
Deep Point Cloud Normal Estimation via Triplet Learning
Oct 20, 2021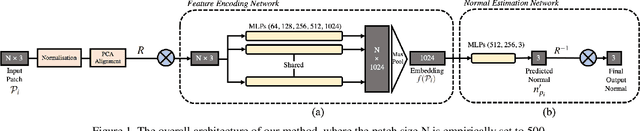

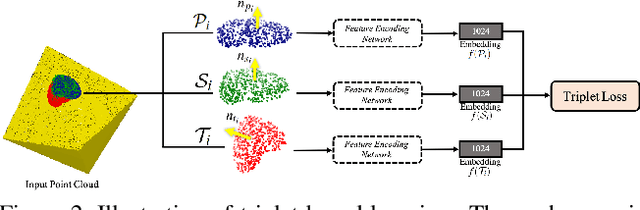

Normal estimation on 3D point clouds is a fundamental problem in 3D vision and graphics. Current methods often show limited accuracy in predicting normals at sharp features (e.g., edges and corners) and less robustness to noise. In this paper, we propose a novel normal estimation method for point clouds. It consists of two phases: (a) feature encoding which learns representations of local patches, and (b) normal estimation that takes the learned representation as input and regresses the normal vector. We are motivated that local patches on isotropic and anisotropic surfaces have similar or distinct normals, and that separable features or representations can be learned to facilitate normal estimation. To realise this, we first construct triplets of local patches on 3D point cloud data, and design a triplet network with a triplet loss for feature encoding. We then design a simple network with several MLPs and a loss function to regress the normal vector. Despite having a smaller network size compared to most other methods, experimental results show that our method preserves sharp features and achieves better normal estimation results on CAD-like shapes.
Rethinking Point Cloud Filtering: A Non-Local Position Based Approach
Oct 14, 2021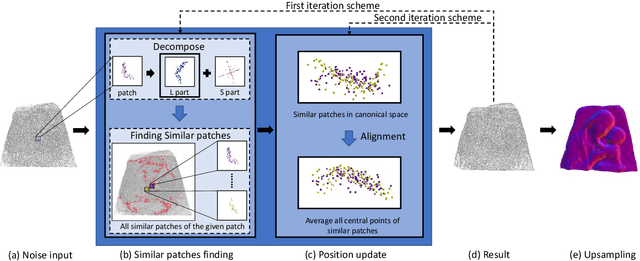
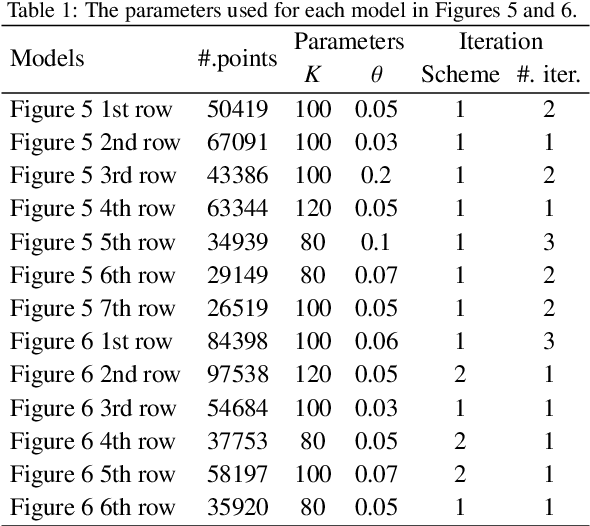
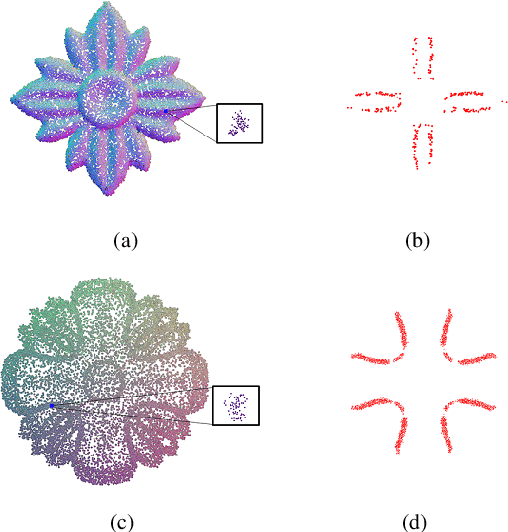
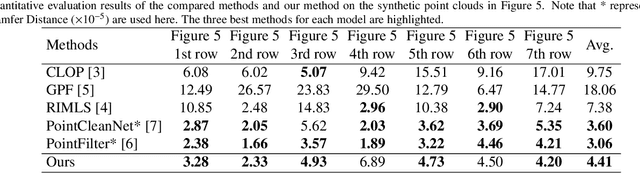
Existing position based point cloud filtering methods can hardly preserve sharp geometric features. In this paper, we rethink point cloud filtering from a non-learning non-local non-normal perspective, and propose a novel position based approach for feature-preserving point cloud filtering. Unlike normal based techniques, our method does not require the normal information. The core idea is to first design a similarity metric to search the non-local similar patches of a queried local patch. We then map the non-local similar patches into a canonical space and aggregate the non-local information. The aggregated outcome (i.e. coordinate) will be inversely mapped into the original space. Our method is simple yet effective. Extensive experiments validate our method, and show that it generally outperforms position based methods (deep learning and non-learning), and generates better or comparable outcomes to normal based techniques (deep learning and non-learning).
Unsupervised Representation Learning for 3D Point Cloud Data
Oct 13, 2021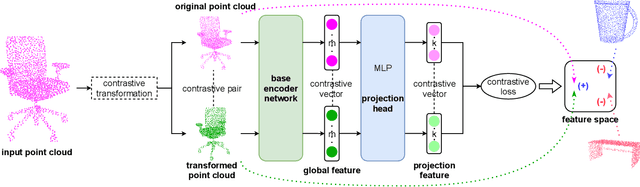


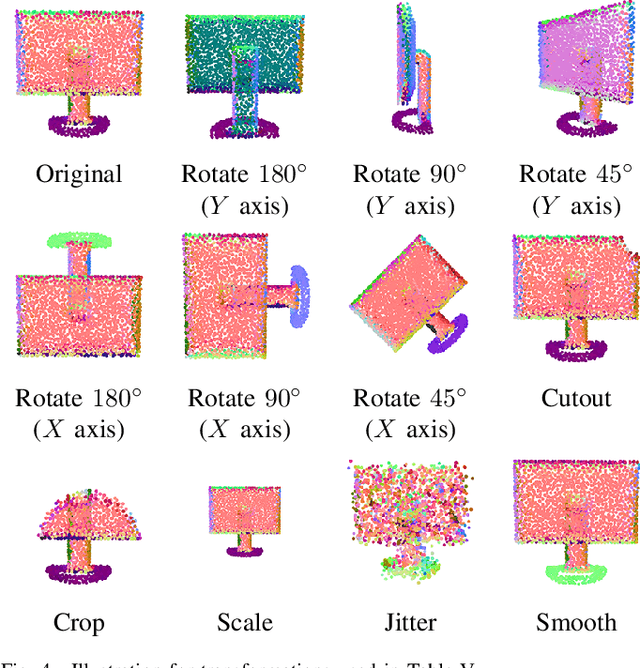
Though a number of point cloud learning methods have been proposed to handle unordered points, most of them are supervised and require labels for training. By contrast, unsupervised learning of point cloud data has received much less attention to date. In this paper, we propose a simple yet effective approach for unsupervised point cloud learning. In particular, we identify a very useful transformation which generates a good contrastive version of an original point cloud. They make up a pair. After going through a shared encoder and a shared head network, the consistency between the output representations are maximized with introducing two variants of contrastive losses to respectively facilitate downstream classification and segmentation. To demonstrate the efficacy of our method, we conduct experiments on three downstream tasks which are 3D object classification (on ModelNet40 and ModelNet10), shape part segmentation (on ShapeNet Part dataset) as well as scene segmentation (on S3DIS). Comprehensive results show that our unsupervised contrastive representation learning enables impressive outcomes in object classification and semantic segmentation. It generally outperforms current unsupervised methods, and even achieves comparable performance to supervised methods. Our source codes will be made publicly available.
Domain Adaptive Semantic Segmentation with Regional Contrastive Consistency Regularization
Oct 11, 2021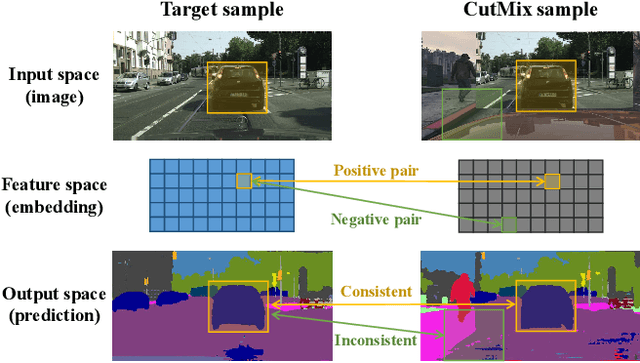
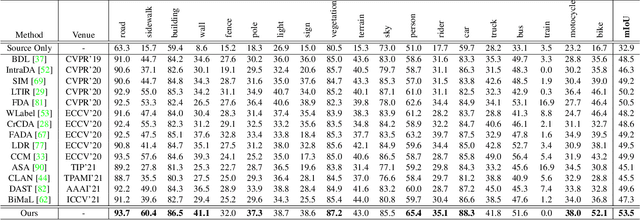
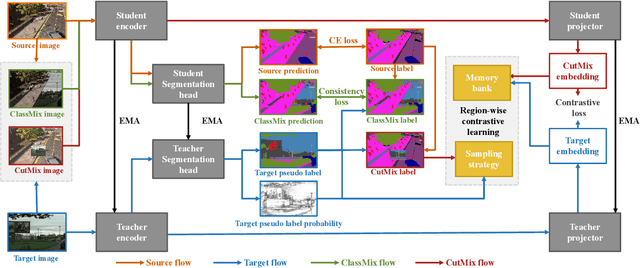
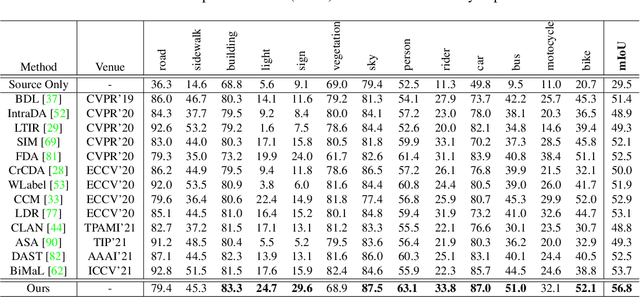
Unsupervised domain adaptation (UDA) aims to bridge the domain shift between the labeled source domain and the unlabeled target domain. However, most existing works perform the global-level feature alignment for semantic segmentation, while the local consistency between the regions has been largely neglected, and these methods are less robust to changing of outdoor environments. Motivated by the above facts, we propose a novel and fully end-to-end trainable approach, called regional contrastive consistency regularization (RCCR) for domain adaptive semantic segmentation. Our core idea is to pull the similar regional features extracted from the same location of different images to be closer, and meanwhile push the features from the different locations of the two images to be separated. We innovatively propose momentum projector heads, where the teacher projector is the exponential moving average of the student. Besides, we present a region-wise contrastive loss with two sampling strategies to realize effective regional consistency. Finally, a memory bank mechanism is designed to learn more robust and stable region-wise features under varying environments. Extensive experiments on two common UDA benchmarks, i.e., GTAV to Cityscapes and SYNTHIA to Cityscapes, demonstrate that our approach outperforms the state-of-the-art methods.
A Robust Scheme for 3D Point Cloud Copy Detection
Oct 03, 2021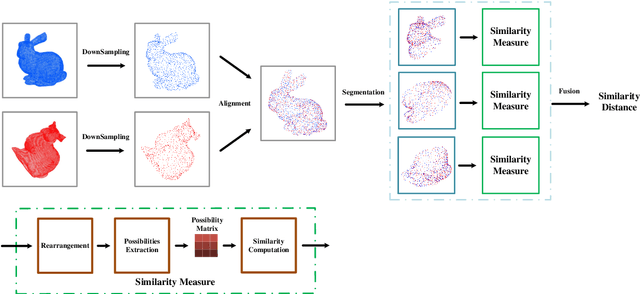
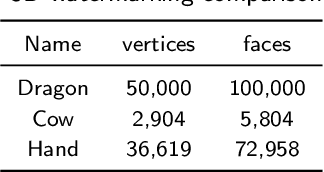
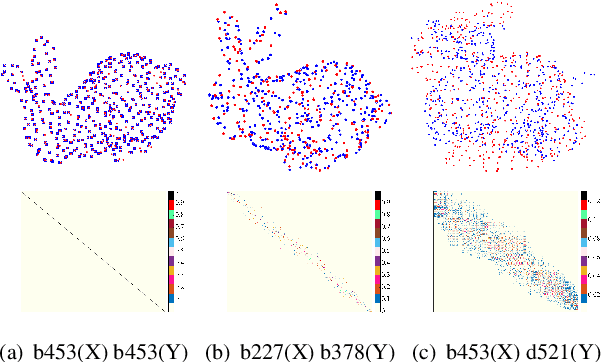
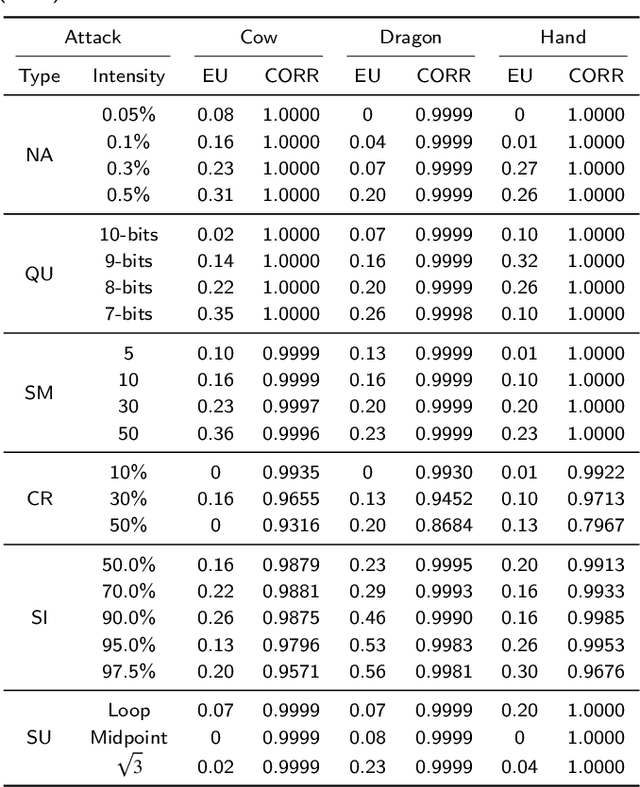
Most existing 3D geometry copy detection research focused on 3D watermarking, which first embeds ``watermarks'' and then detects the added watermarks. However, this kind of methods is non-straightforward and may be less robust to attacks such as cropping and noise. In this paper, we focus on a fundamental and practical research problem: judging whether a point cloud is plagiarized or copied to another point cloud in the presence of several manipulations (e.g., similarity transformation, smoothing). We propose a novel method to address this critical problem. Our key idea is first to align the two point clouds and then calculate their similarity distance. We design three different measures to compute the similarity. We also introduce two strategies to speed up our method. Comprehensive experiments and comparisons demonstrate the effectiveness and robustness of our method in estimating the similarity of two given 3D point clouds.
Anatomical Landmarks Localization for 3D Foot Point Clouds
Oct 03, 2021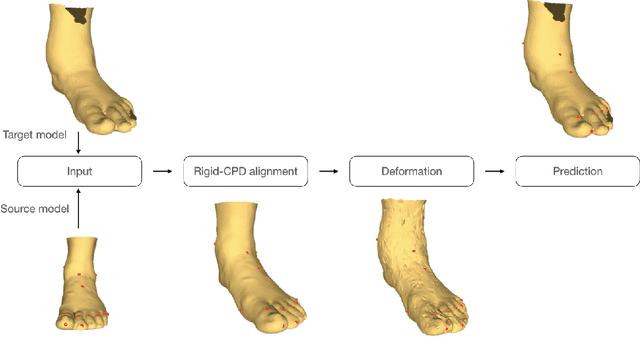
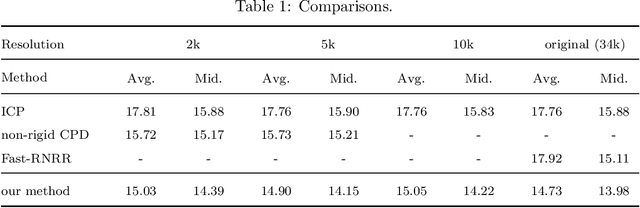
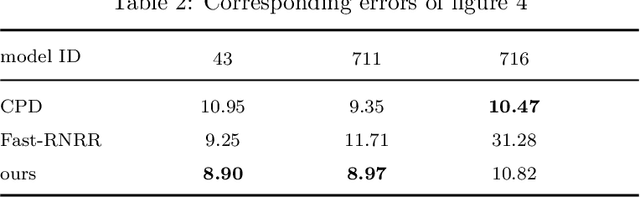
3D anatomical landmarks play an important role in health research. Their automated prediction/localization thus becomes a vital task. In this paper, we introduce a deformation method for 3D anatomical landmarks prediction. It utilizes a source model with anatomical landmarks which are annotated by clinicians, and deforms this model non-rigidly to match the target model. Two constraints are introduced in the optimization, which are responsible for alignment and smoothness, respectively. Experiments are performed on our dataset and the results demonstrate the robustness of our method, and show that it yields better performance than the state-of-the-art techniques in most cases.
Automated Security Assessment for the Internet of Things
Sep 09, 2021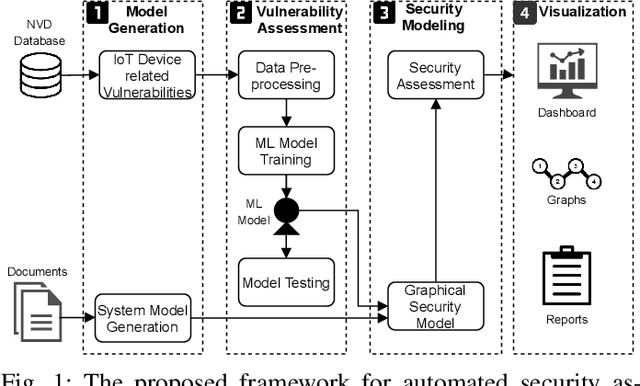
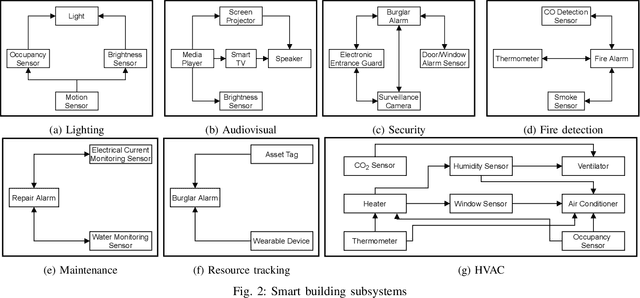
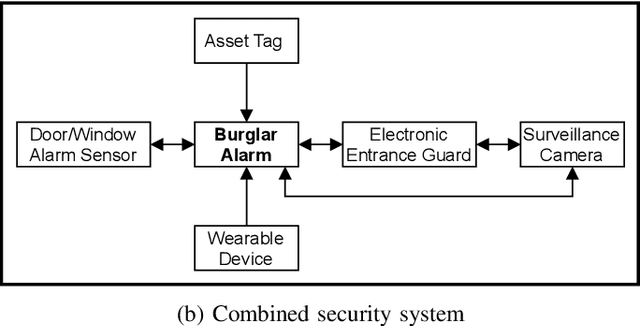
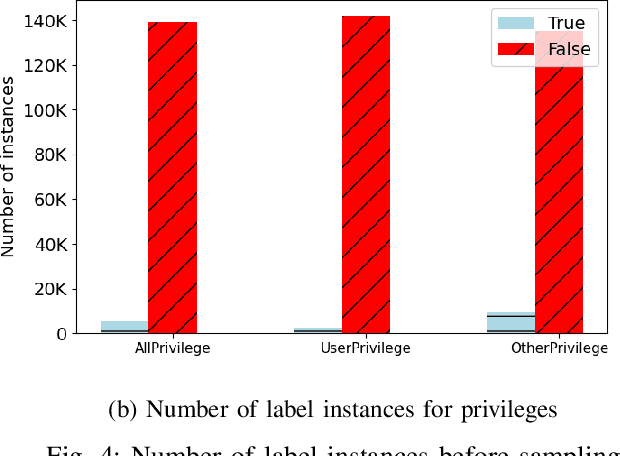
Internet of Things (IoT) based applications face an increasing number of potential security risks, which need to be systematically assessed and addressed. Expert-based manual assessment of IoT security is a predominant approach, which is usually inefficient. To address this problem, we propose an automated security assessment framework for IoT networks. Our framework first leverages machine learning and natural language processing to analyze vulnerability descriptions for predicting vulnerability metrics. The predicted metrics are then input into a two-layered graphical security model, which consists of an attack graph at the upper layer to present the network connectivity and an attack tree for each node in the network at the bottom layer to depict the vulnerability information. This security model automatically assesses the security of the IoT network by capturing potential attack paths. We evaluate the viability of our approach using a proof-of-concept smart building system model which contains a variety of real-world IoT devices and potential vulnerabilities. Our evaluation of the proposed framework demonstrates its effectiveness in terms of automatically predicting the vulnerability metrics of new vulnerabilities with more than 90% accuracy, on average, and identifying the most vulnerable attack paths within an IoT network. The produced assessment results can serve as a guideline for cybersecurity professionals to take further actions and mitigate risks in a timely manner.
3D Face Recognition: A Survey
Aug 25, 2021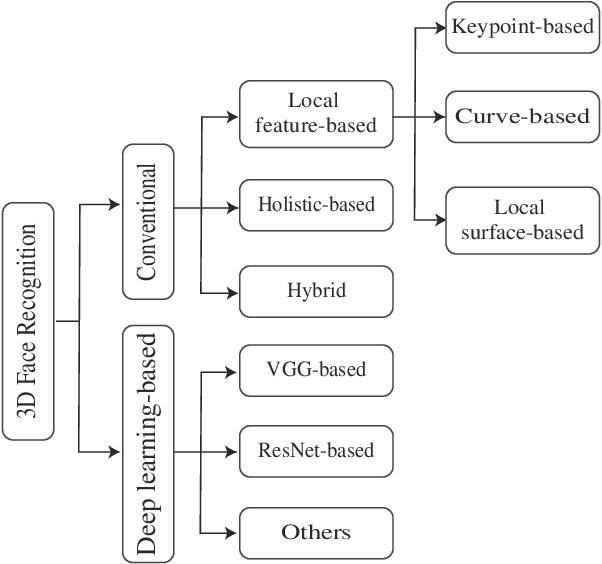
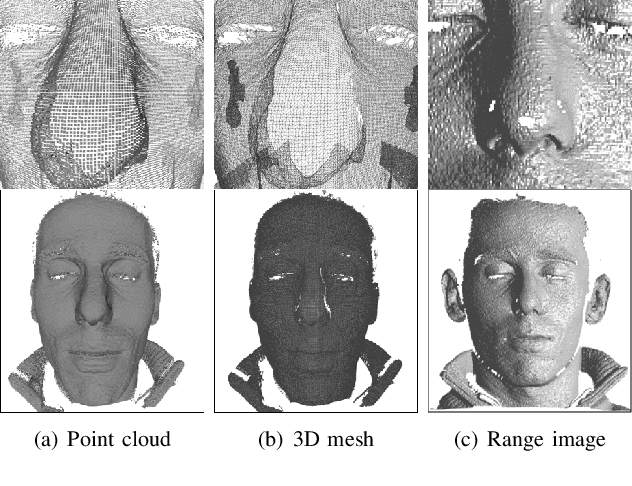
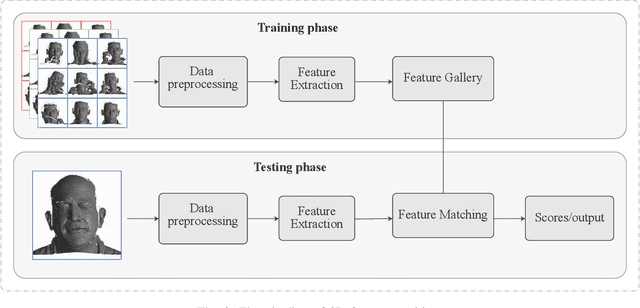
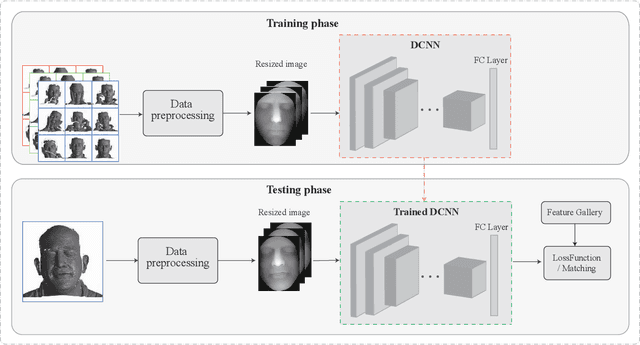
Face recognition is one of the most studied research topics in the community. In recent years, the research on face recognition has shifted to using 3D facial surfaces, as more discriminating features can be represented by the 3D geometric information. This survey focuses on reviewing the 3D face recognition techniques developed in the past ten years which are generally categorized into conventional methods and deep learning methods. The categorized techniques are evaluated using detailed descriptions of the representative works. The advantages and disadvantages of the techniques are summarized in terms of accuracy, complexity and robustness to face variation (expression, pose and occlusions, etc). The main contribution of this survey is that it comprehensively covers both conventional methods and deep learning methods on 3D face recognition. In addition, a review of available 3D face databases is provided, along with the discussion of future research challenges and directions.