 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning High-Quality Initial Noise for Single-View Synthesis with Diffusion Models
Dec 18, 2025Single-view novel view synthesis (NVS) models based on diffusion models have recently attracted increasing attention, as they can generate a series of novel view images from a single image prompt and camera pose information as conditions. It has been observed that in diffusion models, certain high-quality initial noise patterns lead to better generation results than others. However, there remains a lack of dedicated learning frameworks that enable NVS models to learn such high-quality noise. To obtain high-quality initial noise from random Gaussian noise, we make the following contributions. First, we design a discretized Euler inversion method to inject image semantic information into random noise, thereby constructing paired datasets of random and high-quality noise. Second, we propose a learning framework based on an encoder-decoder network (EDN) that directly transforms random noise into high-quality noise. Experiments demonstrate that the proposed EDN can be seamlessly plugged into various NVS models, such as SV3D and MV-Adapter, achieving significant performance improvements across multiple datasets. Code is available at: https://github.com/zhihao0512/EDN.
Variational Quantum Circuits for Quantum State Tomography
Dec 16, 2019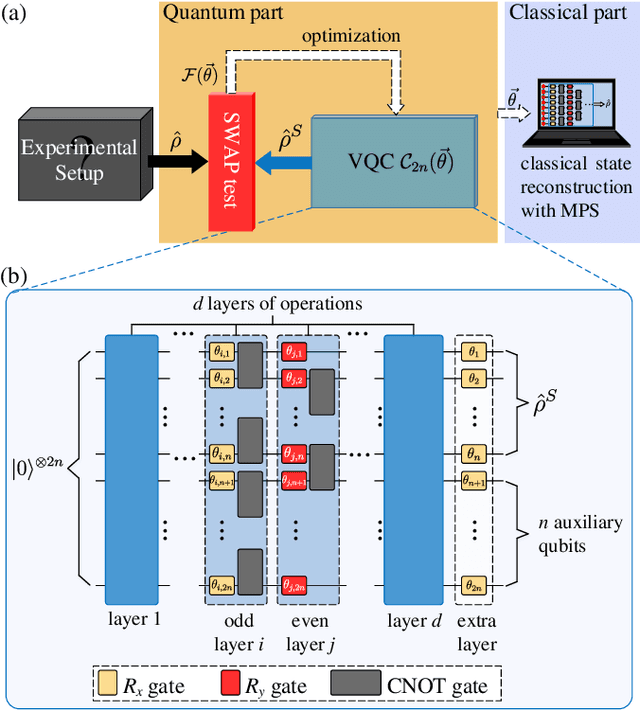
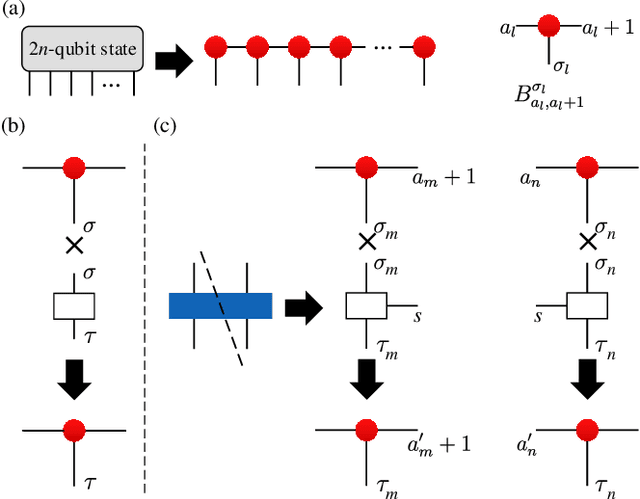
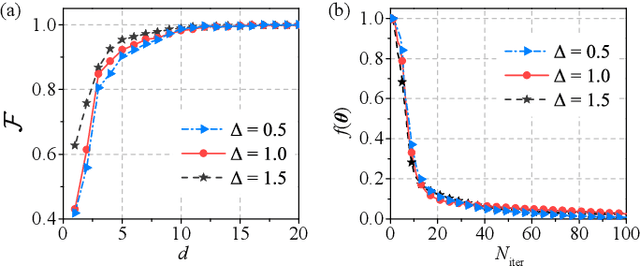
We propose a hybrid quantum-classical algorithm for quantum state tomography. Given an unknown quantum state, a quantum machine learning algorithm is used to maximize the fidelity between the output of a variational quantum circuit and this state. The number of parameters of the variational quantum circuit grows linearly with the number of qubits and the circuit depth. After that, a subsequent classical algorithm is used to reconstruct the unknown quantum state. We demonstrate our method by performing numerical simulations to reconstruct the ground state of a one-dimensional quantum spin chain, using a variational quantum circuit simulator. Our method is suitable for near-term quantum computing platforms, and could be used for relatively large-scale quantum state tomography for experimentally relevant quantum states.
CNN Feature boosted SeqSLAM for Real-Time Loop Closure Detection
Apr 17, 2017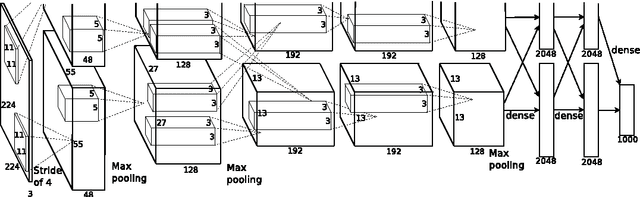

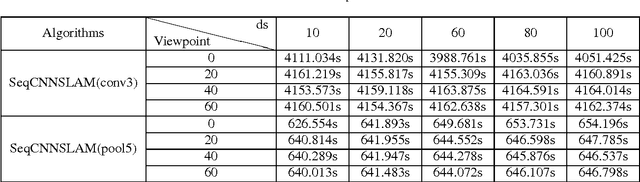
Loop closure detection (LCD) is an indispensable part of simultaneous localization and mapping systems (SLAM); it enables robots to produce a consistent map by recognizing previously visited places. When robots operate over extended periods, robustness to viewpoint and condition changes as well as satisfactory real-time performance become essential requirements for a practical LCD system. This paper presents an approach to directly utilize the outputs at the intermediate layer of a pre-trained convolutional neural network (CNN) as image descriptors. The matching location is determined by matching the image sequences through a method called SeqCNNSLAM. The utility of SeqCNNSLAM is comprehensively evaluated in terms of viewpoint and condition invariance. Experiments show that SeqCNNSLAM outperforms state-of-the-art LCD systems, such as SeqSLAM and Change Removal, in most cases. To allow for the real-time performance of SeqCNNSLAM, an acceleration method, A-SeqCNNSLAM, is established. This method exploits the location relationship between the matching images of adjacent images to reduce the matching range of the current image. Results demonstrate that acceleration of 4-6 is achieved with minimal accuracy degradation, and the method's runtime satisfies the real-time demand. To extend the applicability of A-SeqCNNSLAM to new environments, a method called O-SeqCNNSLAM is established for the online adjustment of the parameters of A-SeqCNNSLAM.
Joint Communication-Motion Planning in Wireless-Connected Robotic Networks: Overview and Design Guidelines
Nov 07, 2015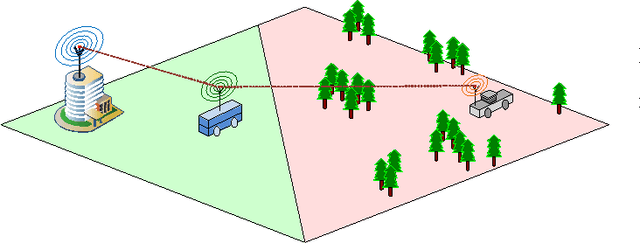
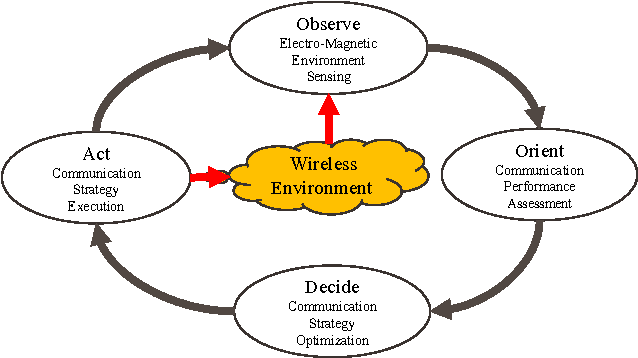
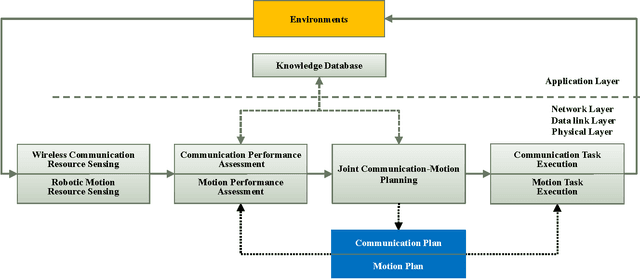
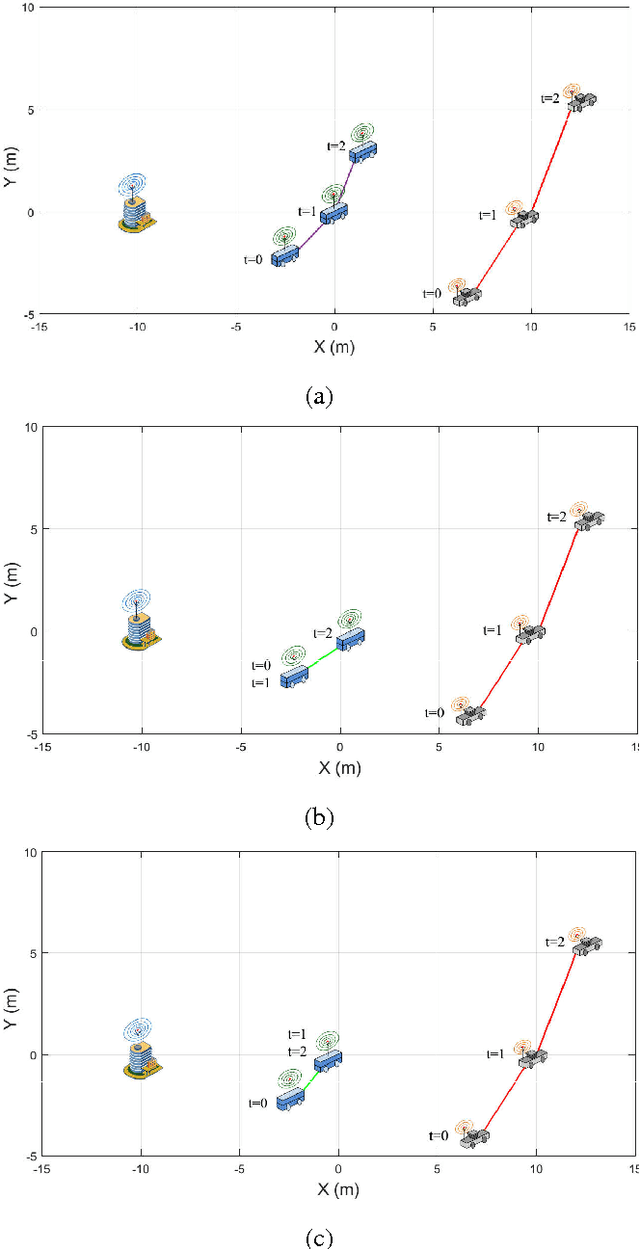
Recent years have witnessed the prosperity of robots and in order to support consensus and cooperation for multi-robot system, wireless communications and networking among robots and the infrastructure have become indispensable. In this technical note, we first provide an overview of the research contributions on communication-aware motion planning (CAMP) in designing wireless-connected robotic networks (WCRNs), where the degree-of-freedom (DoF) provided by motion and communication capabilities embraced by the robots have not been fully exploited. Therefore, we propose the framework of joint communication-motion planning (JCMP) as well as the architecture for incorporating JCMP in WCRNs. The proposed architecture is motivated by the observe-orient-decision-action (OODA) model commonly adopted in robotic motion control and cognitive radio. Then, we provide an overview of the orient module that quantify the connectivity assessment. Afterwards, we highlight the JCMP module and compare it with the conventional communication-planning, where the necessity of the JCMP is validated via both theoretical analysis and simulation results of an illustrative example. Finally, a series of open problems are discussed, which picture the gap between the state-of-the-art and a practical WCRN.