 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBarbieGait: An Identity-Consistent Synthetic Human Dataset with Versatile Cloth-Changing for Gait Recognition
Apr 14, 2026Gait recognition, as a reliable biometric technology, has seen rapid development in recent years while it faces significant challenges caused by diverse clothing styles in the real world. This paper introduces BarbieGait, a synthetic gait dataset where real-world subjects are uniquely mapped into a virtual engine to simulate extensive clothing changes while preserving their gait identity information. As a pioneering work, BarbieGait provides a controllable gait data generation method, enabling the production of large datasets to validate cross-clothing issues that are difficult to verify with real-world data. However, the diversity of clothing increases intra-class variance and makes one of the biggest challenges to learning cloth-invariant features under varying clothing conditions. Therefore, we propose GaitCLIF (Gait-oriented CLoth-Invariant Feature) as a robust baseline model for cross-clothing gait recognition. Through extensive experiments, we validate that our method significantly improves cross-clothing performance on BarbieGait and the existing popular gait benchmarks. We believe that BarbieGait, with its extensive cross-clothing gait data, will further advance the capabilities of gait recognition in cross-clothing scenarios and promote progress in related research.
Visually-Guided Policy Optimization for Multimodal Reasoning
Apr 10, 2026Reinforcement learning with verifiable rewards (RLVR) has significantly advanced the reasoning ability of vision-language models (VLMs). However, the inherent text-dominated nature of VLMs often leads to insufficient visual faithfulness, characterized by sparse attention activation to visual tokens. More importantly, our empirical analysis reveals that temporal visual forgetting along reasoning steps exacerbates this deficiency. To bridge this gap, we propose Visually-Guided Policy Optimization (VGPO), a novel framework to reinforce visual focus during policy optimization. Specifically, VGPO initially introduces a Visual Attention Compensation mechanism that leverages visual similarity to localize and amplify visual cues, while progressively elevating visual expectations in later steps to counteract visual forgetting. Building on this mechanism, we implement a dual-grained advantage re-weighting strategy: the intra-trajectory level highlights tokens exhibiting relatively high visual activation, while the inter-trajectory level prioritizes trajectories demonstrating superior visual accumulation. Extensive experiments demonstrate that VGPO achieves better visual activation and superior performance in mathematical multimodal reasoning and visual-dependent tasks.
AR-MAP: Are Autoregressive Large Language Models Implicit Teachers for Diffusion Large Language Models?
Feb 03, 2026Diffusion Large Language Models (DLLMs) have emerged as a powerful alternative to autoregressive models, enabling parallel token generation across multiple positions. However, preference alignment of DLLMs remains challenging due to high variance introduced by Evidence Lower Bound (ELBO)-based likelihood estimation. In this work, we propose AR-MAP, a novel transfer learning framework that leverages preference-aligned autoregressive LLMs (AR-LLMs) as implicit teachers for DLLM alignment. We reveal that DLLMs can effectively absorb alignment knowledge from AR-LLMs through simple weight scaling, exploiting the shared architectural structure between these divergent generation paradigms. Crucially, our approach circumvents the high variance and computational overhead of direct DLLM alignment and comprehensive experiments across diverse preference alignment tasks demonstrate that AR-MAP achieves competitive or superior performance compared to existing DLLM-specific alignment methods, achieving 69.08\% average score across all tasks and models. Our Code is available at https://github.com/AMAP-ML/AR-MAP.
Everything in Its Place: Benchmarking Spatial Intelligence of Text-to-Image Models
Jan 29, 2026Text-to-image (T2I) models have achieved remarkable success in generating high-fidelity images, but they often fail in handling complex spatial relationships, e.g., spatial perception, reasoning, or interaction. These critical aspects are largely overlooked by current benchmarks due to their short or information-sparse prompt design. In this paper, we introduce SpatialGenEval, a new benchmark designed to systematically evaluate the spatial intelligence of T2I models, covering two key aspects: (1) SpatialGenEval involves 1,230 long, information-dense prompts across 25 real-world scenes. Each prompt integrates 10 spatial sub-domains and corresponding 10 multi-choice question-answer pairs, ranging from object position and layout to occlusion and causality. Our extensive evaluation of 21 state-of-the-art models reveals that higher-order spatial reasoning remains a primary bottleneck. (2) To demonstrate that the utility of our information-dense design goes beyond simple evaluation, we also construct the SpatialT2I dataset. It contains 15,400 text-image pairs with rewritten prompts to ensure image consistency while preserving information density. Fine-tuned results on current foundation models (i.e., Stable Diffusion-XL, Uniworld-V1, OmniGen2) yield consistent performance gains (+4.2%, +5.7%, +4.4%) and more realistic effects in spatial relations, highlighting a data-centric paradigm to achieve spatial intelligence in T2I models.
FastDDHPose: Towards Unified, Efficient, and Disentangled 3D Human Pose Estimation
Dec 16, 2025



Recent approaches for monocular 3D human pose estimation (3D HPE) have achieved leading performance by directly regressing 3D poses from 2D keypoint sequences. Despite the rapid progress in 3D HPE, existing methods are typically trained and evaluated under disparate frameworks, lacking a unified framework for fair comparison. To address these limitations, we propose Fast3DHPE, a modular framework that facilitates rapid reproduction and flexible development of new methods. By standardizing training and evaluation protocols, Fast3DHPE enables fair comparison across 3D human pose estimation methods while significantly improving training efficiency. Within this framework, we introduce FastDDHPose, a Disentangled Diffusion-based 3D Human Pose Estimation method which leverages the strong latent distribution modeling capability of diffusion models to explicitly model the distributions of bone length and bone direction while avoiding further amplification of hierarchical error accumulation. Moreover, we design an efficient Kinematic-Hierarchical Spatial and Temporal Denoiser that encourages the model to focus on kinematic joint hierarchies while avoiding unnecessary modeling of overly complex joint topologies. Extensive experiments on Human3.6M and MPI-INF-3DHP show that the Fast3DHPE framework enables fair comparison of all methods while significantly improving training efficiency. Within this unified framework, FastDDHPose achieves state-of-the-art performance with strong generalization and robustness in in-the-wild scenarios. The framework and models will be released at: https://github.com/Andyen512/Fast3DHPE
POPDG: Popular 3D Dance Generation with PopDanceSet
May 06, 2024Generating dances that are both lifelike and well-aligned with music continues to be a challenging task in the cross-modal domain. This paper introduces PopDanceSet, the first dataset tailored to the preferences of young audiences, enabling the generation of aesthetically oriented dances. And it surpasses the AIST++ dataset in music genre diversity and the intricacy and depth of dance movements. Moreover, the proposed POPDG model within the iDDPM framework enhances dance diversity and, through the Space Augmentation Algorithm, strengthens spatial physical connections between human body joints, ensuring that increased diversity does not compromise generation quality. A streamlined Alignment Module is also designed to improve the temporal alignment between dance and music. Extensive experiments show that POPDG achieves SOTA results on two datasets. Furthermore, the paper also expands on current evaluation metrics. The dataset and code are available at https://github.com/Luke-Luo1/POPDG.
Disentangled Diffusion-Based 3D Human Pose Estimation with Hierarchical Spatial and Temporal Denoiser
Mar 07, 2024



Recently, diffusion-based methods for monocular 3D human pose estimation have achieved state-of-the-art (SOTA) performance by directly regressing the 3D joint coordinates from the 2D pose sequence. Although some methods decompose the task into bone length and bone direction prediction based on the human anatomical skeleton to explicitly incorporate more human body prior constraints, the performance of these methods is significantly lower than that of the SOTA diffusion-based methods. This can be attributed to the tree structure of the human skeleton. Direct application of the disentangled method could amplify the accumulation of hierarchical errors, propagating through each hierarchy. Meanwhile, the hierarchical information has not been fully explored by the previous methods. To address these problems, a Disentangled Diffusion-based 3D Human Pose Estimation method with Hierarchical Spatial and Temporal Denoiser is proposed, termed DDHPose. In our approach: (1) We disentangle the 3D pose and diffuse the bone length and bone direction during the forward process of the diffusion model to effectively model the human pose prior. A disentanglement loss is proposed to supervise diffusion model learning. (2) For the reverse process, we propose Hierarchical Spatial and Temporal Denoiser (HSTDenoiser) to improve the hierarchical modeling of each joint. Our HSTDenoiser comprises two components: the Hierarchical-Related Spatial Transformer (HRST) and the Hierarchical-Related Temporal Transformer (HRTT). HRST exploits joint spatial information and the influence of the parent joint on each joint for spatial modeling, while HRTT utilizes information from both the joint and its hierarchical adjacent joints to explore the hierarchical temporal correlations among joints.
Towards More Efficient Depression Risk Recognition via Gait
Oct 10, 2023



Depression, a highly prevalent mental illness, affects over 280 million individuals worldwide. Early detection and timely intervention are crucial for promoting remission, preventing relapse, and alleviating the emotional and financial burdens associated with depression. However, patients with depression often go undiagnosed in the primary care setting. Unlike many physiological illnesses, depression lacks objective indicators for recognizing depression risk, and existing methods for depression risk recognition are time-consuming and often encounter a shortage of trained medical professionals. The correlation between gait and depression risk has been empirically established. Gait can serve as a promising objective biomarker, offering the advantage of efficient and convenient data collection. However, current methods for recognizing depression risk based on gait have only been validated on small, private datasets, lacking large-scale publicly available datasets for research purposes. Additionally, these methods are primarily limited to hand-crafted approaches. Gait is a complex form of motion, and hand-crafted gait features often only capture a fraction of the intricate associations between gait and depression risk. Therefore, this study first constructs a large-scale gait database, encompassing over 1,200 individuals, 40,000 gait sequences, and covering six perspectives and three types of attire. Two commonly used psychological scales are provided as depression risk annotations. Subsequently, a deep learning-based depression risk recognition model is proposed, overcoming the limitations of hand-crafted approaches. Through experiments conducted on the constructed large-scale database, the effectiveness of the proposed method is validated, and numerous instructive insights are presented in the paper, highlighting the significant potential of gait-based depression risk recognition.
GPGait: Generalized Pose-based Gait Recognition
Mar 09, 2023



Recent works on pose-based gait recognition have demonstrated the potential of using such simple information to achieve results comparable to silhouette-based methods. However, the generalization ability of pose-based methods on different datasets is undesirably inferior to that of silhouette-based ones, which has received little attention but hinders the application of these methods in real-world scenarios. To improve the generalization ability of pose-based methods across datasets, we propose a Generalized Pose-based Gait recognition (GPGait) framework. First, a Human-Oriented Transformation (HOT) and a series of Human-Oriented Descriptors (HOD) are proposed to obtain a unified pose representation with discriminative multi-features. Then, given the slight variations in the unified representation after HOT and HOD, it becomes crucial for the network to extract local-global relationships between the keypoints. To this end, a Part-Aware Graph Convolutional Network (PAGCN) is proposed to enable efficient graph partition and local-global spatial feature extraction. Experiments on four public gait recognition datasets, CASIA-B, OUMVLP-Pose, Gait3D and GREW, show that our model demonstrates better and more stable cross-domain capabilities compared to existing skeleton-based methods, achieving comparable recognition results to silhouette-based ones. The code will be released.
Meta-SR: A Magnification-Arbitrary Network for Super-Resolution
Apr 03, 2019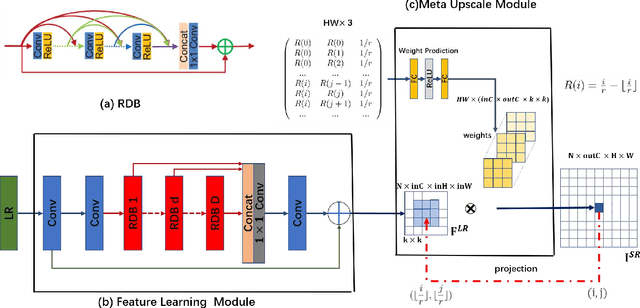
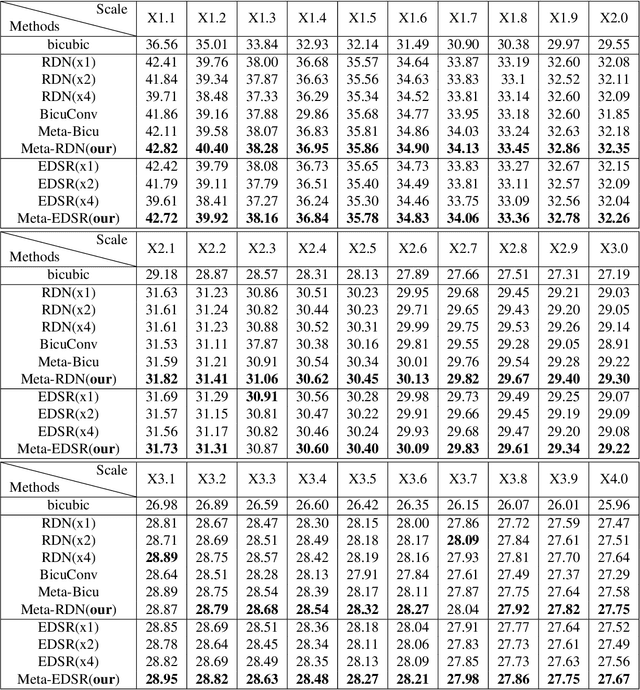
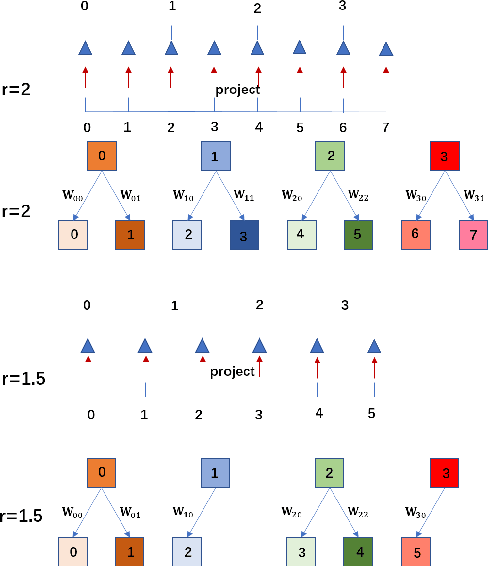
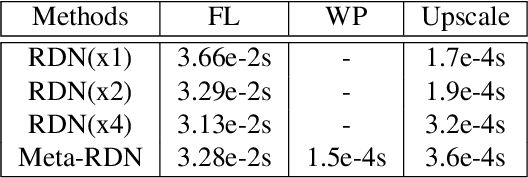
Recent research on super-resolution has achieved great success due to the development of deep convolutional neural networks (DCNNs). However, super-resolution of arbitrary scale factor has been ignored for a long time. Most previous researchers regard super-resolution of different scale factors as independent tasks. They train a specific model for each scale factor which is inefficient in computing, and prior work only take the super-resolution of several integer scale factors into consideration. In this work, we propose a novel method called Meta-SR to firstly solve super-resolution of arbitrary scale factor (including non-integer scale factors) with a single model. In our Meta-SR, the Meta-Upscale Module is proposed to replace the traditional upscale module. For arbitrary scale factor, the Meta-Upscale Module dynamically predicts the weights of the upscale filters by taking the scale factor as input and use these weights to generate the HR image of arbitrary size. For any low-resolution image, our Meta-SR can continuously zoom in it with arbitrary scale factor by only using a single model. We evaluated the proposed method through extensive experiments on widely used benchmark datasets on single image super-resolution. The experimental results show the superiority of our Meta-Upscale.