 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePHYBench: Holistic Evaluation of Physical Perception and Reasoning in Large Language Models
Apr 22, 2025



We introduce PHYBench, a novel, high-quality benchmark designed for evaluating reasoning capabilities of large language models (LLMs) in physical contexts. PHYBench consists of 500 meticulously curated physics problems based on real-world physical scenarios, designed to assess the ability of models to understand and reason about realistic physical processes. Covering mechanics, electromagnetism, thermodynamics, optics, modern physics, and advanced physics, the benchmark spans difficulty levels from high school exercises to undergraduate problems and Physics Olympiad challenges. Additionally, we propose the Expression Edit Distance (EED) Score, a novel evaluation metric based on the edit distance between mathematical expressions, which effectively captures differences in model reasoning processes and results beyond traditional binary scoring methods. We evaluate various LLMs on PHYBench and compare their performance with human experts. Our results reveal that even state-of-the-art reasoning models significantly lag behind human experts, highlighting their limitations and the need for improvement in complex physical reasoning scenarios. Our benchmark results and dataset are publicly available at https://phybench-official.github.io/phybench-demo/.
Variational Distillation for Multi-View Learning
Jun 20, 2022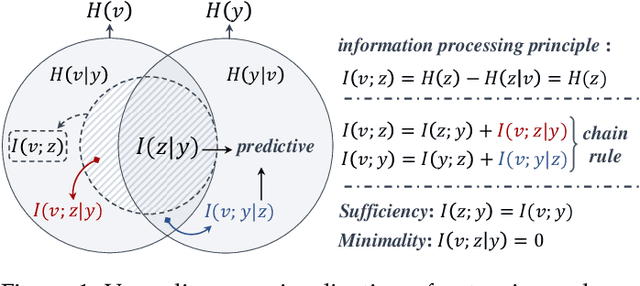
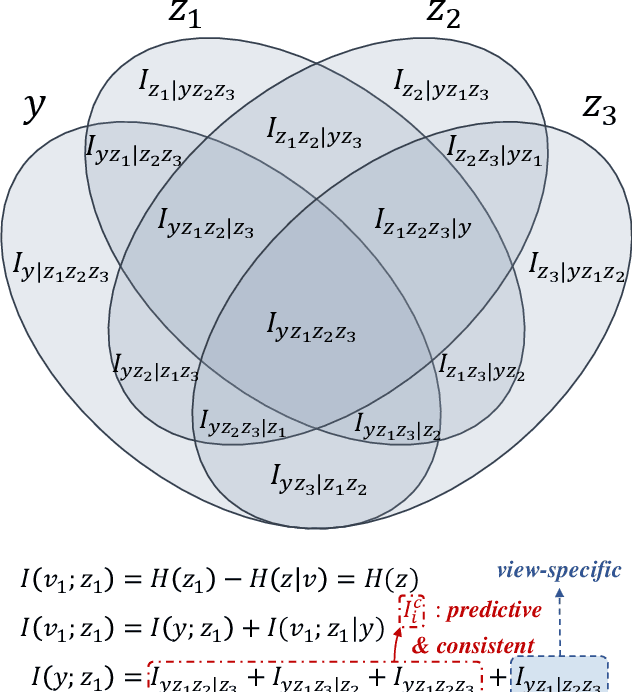
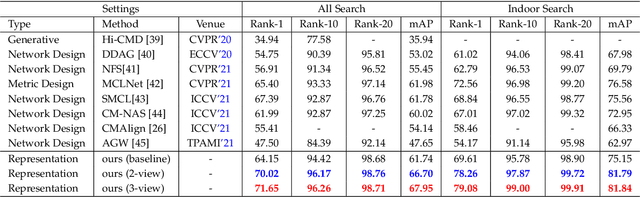
Information Bottleneck (IB) based multi-view learning provides an information theoretic principle for seeking shared information contained in heterogeneous data descriptions. However, its great success is generally attributed to estimate the multivariate mutual information which is intractable when the network becomes complicated. Moreover, the representation learning tradeoff, {\it i.e.}, prediction-compression and sufficiency-consistency tradeoff, makes the IB hard to satisfy both requirements simultaneously. In this paper, we design several variational information bottlenecks to exploit two key characteristics ({\it i.e.}, sufficiency and consistency) for multi-view representation learning. Specifically, we propose a Multi-View Variational Distillation (MV$^2$D) strategy to provide a scalable, flexible and analytical solution to fitting MI by giving arbitrary input of viewpoints but without explicitly estimating it. Under rigorously theoretical guarantee, our approach enables IB to grasp the intrinsic correlation between observations and semantic labels, producing predictive and compact representations naturally. Also, our information-theoretic constraint can effectively neutralize the sensitivity to heterogeneous data by eliminating both task-irrelevant and view-specific information, preventing both tradeoffs in multiple view cases. To verify our theoretically grounded strategies, we apply our approaches to various benchmarks under three different applications. Extensive experiments to quantitatively and qualitatively demonstrate the effectiveness of our approach against state-of-the-art methods.
Farewell to Mutual Information: Variational Distillation for Cross-Modal Person Re-Identification
Apr 07, 2021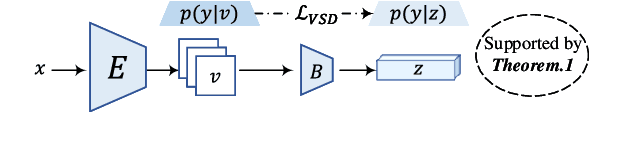
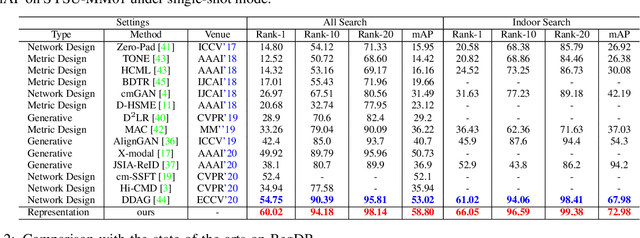
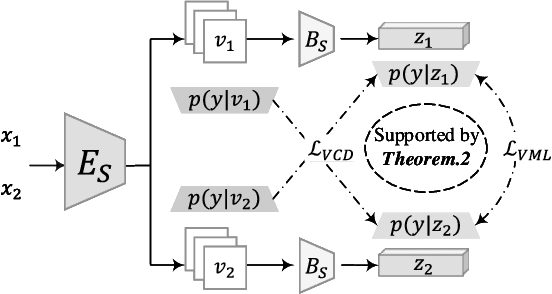
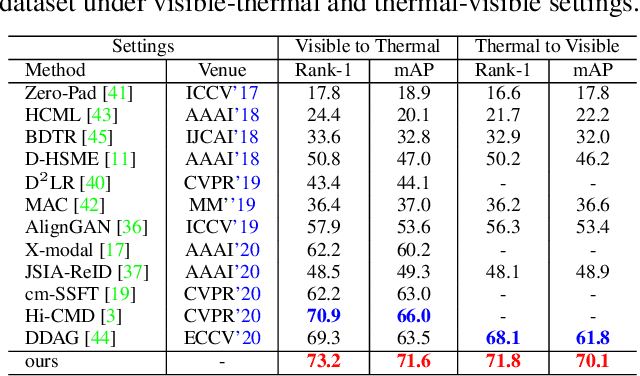
The Information Bottleneck (IB) provides an information theoretic principle for representation learning, by retaining all information relevant for predicting label while minimizing the redundancy. Though IB principle has been applied to a wide range of applications, its optimization remains a challenging problem which heavily relies on the accurate estimation of mutual information. In this paper, we present a new strategy, Variational Self-Distillation (VSD), which provides a scalable, flexible and analytic solution to essentially fitting the mutual information but without explicitly estimating it. Under rigorously theoretical guarantee, VSD enables the IB to grasp the intrinsic correlation between representation and label for supervised training. Furthermore, by extending VSD to multi-view learning, we introduce two other strategies, Variational Cross-Distillation (VCD) and Variational Mutual-Learning (VML), which significantly improve the robustness of representation to view-changes by eliminating view-specific and task-irrelevant information. To verify our theoretically grounded strategies, we apply our approaches to cross-modal person Re-ID, and conduct extensive experiments, where the superior performance against state-of-the-art methods are demonstrated. Our intriguing findings highlight the need to rethink the way to estimate mutual