 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChartNet: A Million-Scale, High-Quality Multimodal Dataset for Robust Chart Understanding
Mar 28, 2026Understanding charts requires models to jointly reason over geometric visual patterns, structured numerical data, and natural language -- a capability where current vision-language models (VLMs) remain limited. We introduce ChartNet, a high-quality, million-scale multimodal dataset designed to advance chart interpretation and reasoning. ChartNet leverages a novel code-guided synthesis pipeline to generate 1.5 million diverse chart samples spanning 24 chart types and 6 plotting libraries. Each sample consists of five aligned components: plotting code, rendered chart image, data table, natural language summary, and question-answering with reasoning, providing fine-grained cross-modal alignment. To capture the full spectrum of chart comprehension, ChartNet additionally includes specialized subsets encompassing human annotated data, real-world data, safety, and grounding. Moreover, a rigorous quality-filtering pipeline ensures visual fidelity, semantic accuracy, and diversity across chart representations. Fine-tuning on ChartNet consistently improves results across benchmarks, demonstrating its utility as large-scale supervision for multimodal models. As the largest open-source dataset of its kind, ChartNet aims to support the development of foundation models with robust and generalizable capabilities for data visualization understanding. The dataset is publicly available at https://huggingface.co/datasets/ibm-granite/ChartNet
Creation and Validation of a Chest X-Ray Dataset with Eye-tracking and Report Dictation for AI Development
Oct 08, 2020
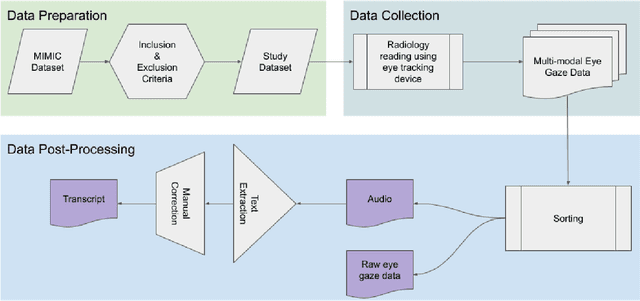
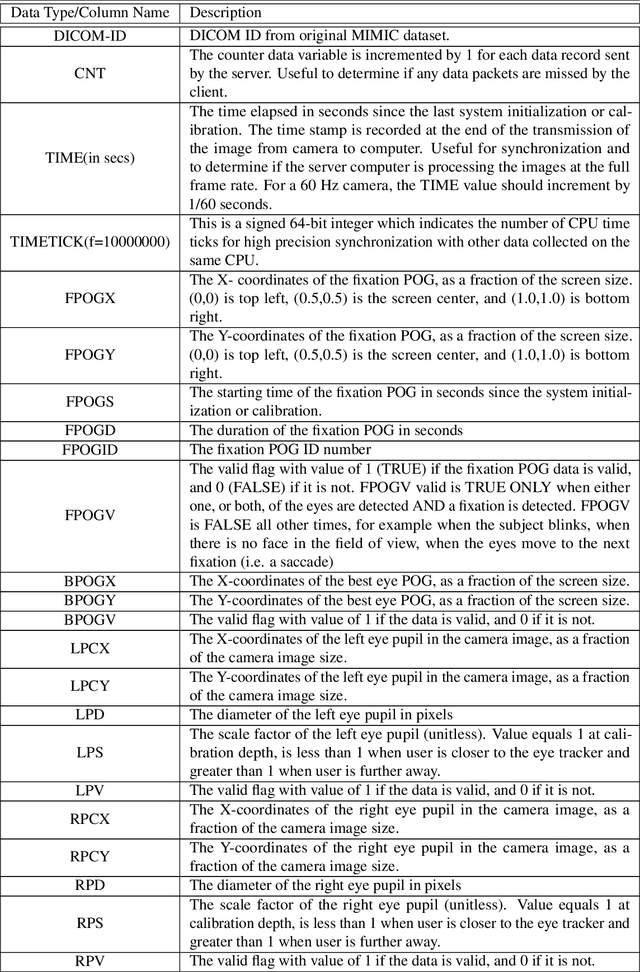
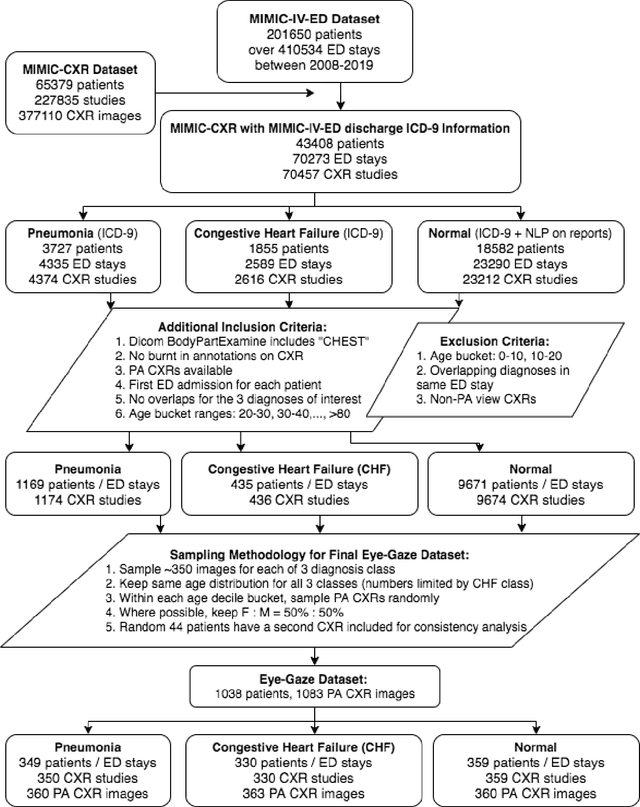
We developed a rich dataset of Chest X-Ray (CXR) images to assist investigators in artificial intelligence. The data were collected using an eye tracking system while a radiologist reviewed and reported on 1,083 CXR images. The dataset contains the following aligned data: CXR image, transcribed radiology report text, radiologist's dictation audio and eye gaze coordinates data. We hope this dataset can contribute to various areas of research particularly towards explainable and multimodal deep learning / machine learning methods. Furthermore, investigators in disease classification and localization, automated radiology report generation, and human-machine interaction can benefit from these data. We report deep learning experiments that utilize the attention maps produced by eye gaze dataset to show the potential utility of this data.
Automatic Diagnosis of Pulmonary Embolism Using an Attention-guided Framework: A Large-scale Study
May 29, 2020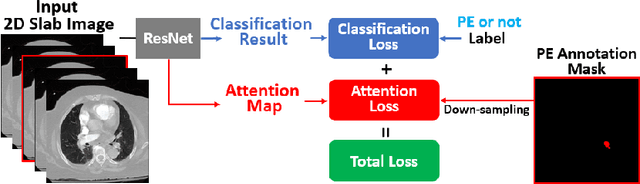
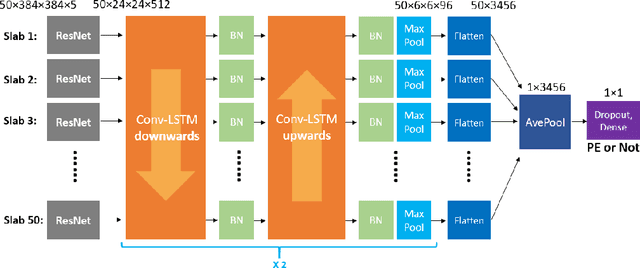
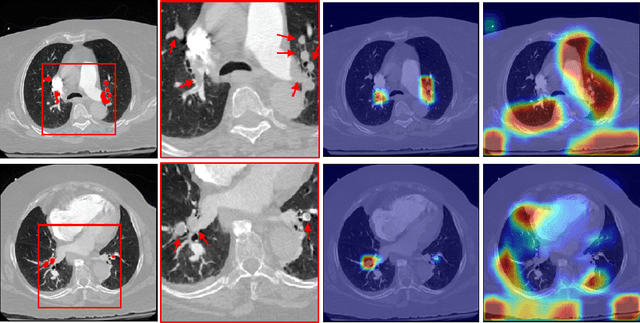
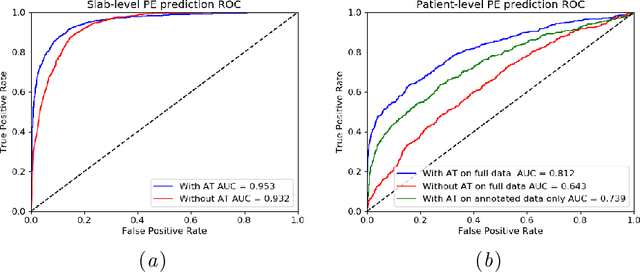
Pulmonary Embolism (PE) is a life-threatening disorder associated with high mortality and morbidity. Prompt diagnosis and immediate initiation of therapeutic action is important. We explored a deep learning model to detect PE on volumetric contrast-enhanced chest CT scans using a 2-stage training strategy. First, a residual convolutional neural network (ResNet) was trained using annotated 2D images. In addition to the classification loss, an attention loss was added during training to help the network focus attention on PE. Next, a recurrent network was used to scan sequentially through the features provided by the pre-trained ResNet to detect PE. This combination allows the network to be trained using both a limited and sparse set of pixel-level annotated images and a large number of easily obtainable patient-level image-label pairs. We used 1,670 sparsely annotated studies and more than 10,000 labeled studies in our training. On a test set with 2,160 patient studies, the proposed method achieved an area under the ROC curve (AUC) of 0.812. The proposed framework is also able to provide localized attention maps that indicate possible PE lesions, which could potentially help radiologists accelerate the diagnostic process.