 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChartNet: A Million-Scale, High-Quality Multimodal Dataset for Robust Chart Understanding
Mar 28, 2026Understanding charts requires models to jointly reason over geometric visual patterns, structured numerical data, and natural language -- a capability where current vision-language models (VLMs) remain limited. We introduce ChartNet, a high-quality, million-scale multimodal dataset designed to advance chart interpretation and reasoning. ChartNet leverages a novel code-guided synthesis pipeline to generate 1.5 million diverse chart samples spanning 24 chart types and 6 plotting libraries. Each sample consists of five aligned components: plotting code, rendered chart image, data table, natural language summary, and question-answering with reasoning, providing fine-grained cross-modal alignment. To capture the full spectrum of chart comprehension, ChartNet additionally includes specialized subsets encompassing human annotated data, real-world data, safety, and grounding. Moreover, a rigorous quality-filtering pipeline ensures visual fidelity, semantic accuracy, and diversity across chart representations. Fine-tuning on ChartNet consistently improves results across benchmarks, demonstrating its utility as large-scale supervision for multimodal models. As the largest open-source dataset of its kind, ChartNet aims to support the development of foundation models with robust and generalizable capabilities for data visualization understanding. The dataset is publicly available at https://huggingface.co/datasets/ibm-granite/ChartNet
The Power of Selecting Key Blocks with Local Pre-ranking for Long Document Information Retrieval
Nov 18, 2021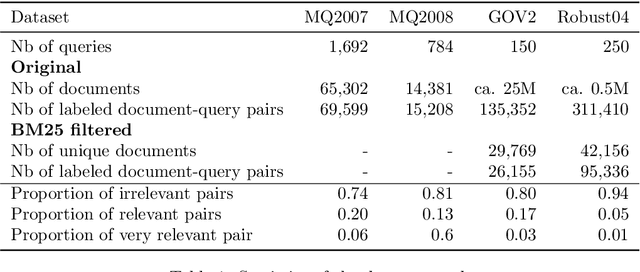
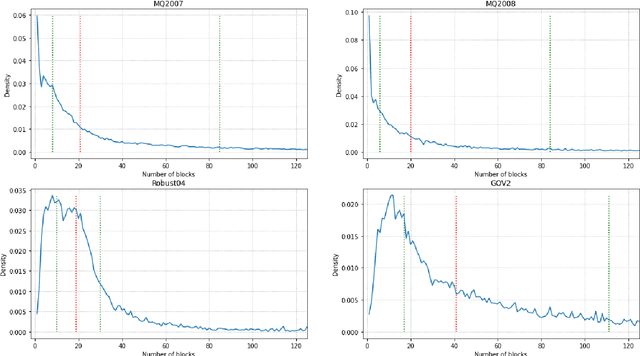
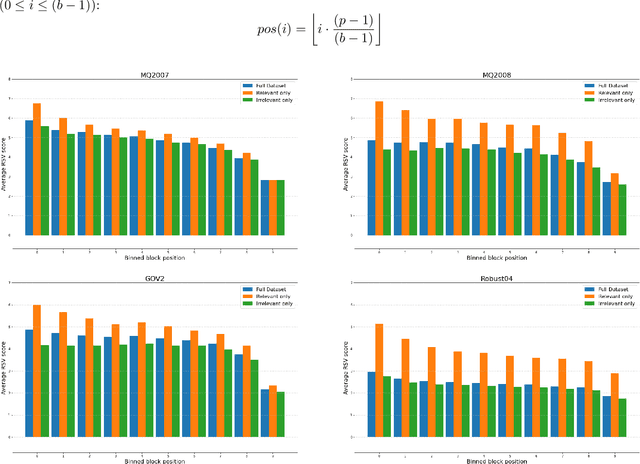
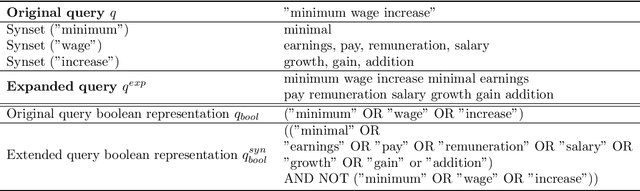
On a wide range of natural language processing and information retrieval tasks, transformer-based models, particularly pre-trained language models like BERT, have demonstrated tremendous effectiveness. Due to the quadratic complexity of the self-attention mechanism, however, such models have difficulties processing long documents. Recent works dealing with this issue include truncating long documents, segmenting them into passages that can be treated by a standard BERT model, or modifying the self-attention mechanism to make it sparser as in sparse-attention models. However, these approaches either lose information or have high computational complexity (and are both time, memory and energy consuming in this later case). We follow here a slightly different approach in which one first selects key blocks of a long document by local query-block pre-ranking, and then few blocks are aggregated to form a short document that can be processed by a model such as BERT. Experiments conducted on standard Information Retrieval datasets demonstrate the effectiveness of the proposed approach.
SmoothI: Smooth Rank Indicators for Differentiable IR Metrics
May 03, 2021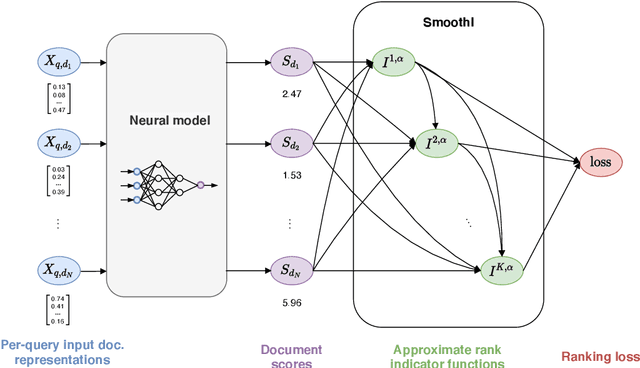
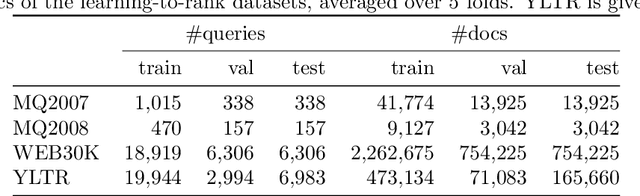
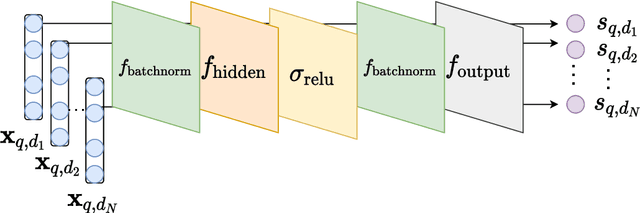
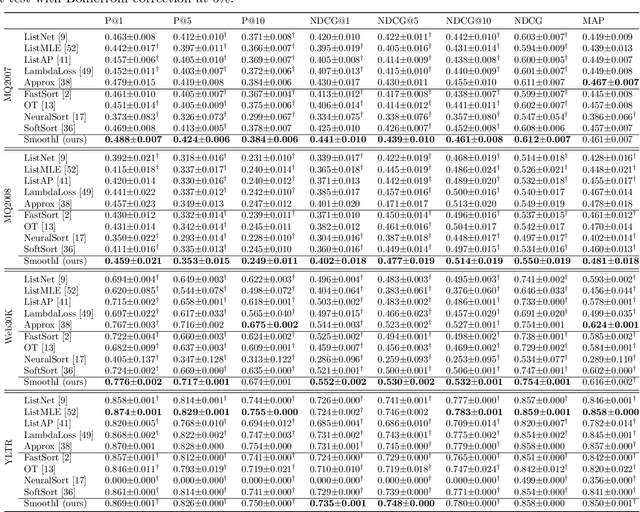
Information retrieval (IR) systems traditionally aim to maximize metrics built on rankings, such as precision or NDCG. However, the non-differentiability of the ranking operation prevents direct optimization of such metrics in state-of-the-art neural IR models, which rely entirely on the ability to compute meaningful gradients. To address this shortcoming, we propose SmoothI, a smooth approximation of rank indicators that serves as a basic building block to devise differentiable approximations of IR metrics. We further provide theoretical guarantees on SmoothI and derived approximations, showing in particular that the approximation errors decrease exponentially with an inverse temperature-like hyperparameter that controls the quality of the approximations. Extensive experiments conducted on four standard learning-to-rank datasets validate the efficacy of the listwise losses based on SmoothI, in comparison to previously proposed ones. Additional experiments with a vanilla BERT ranking model on a text-based IR task also confirm the benefits of our listwise approach.