 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Language Semantic Grounding for Multi-Domain Crop-Weed Segmentation
Feb 27, 2026Fine-grained crop-weed segmentation is essential for enabling targeted herbicide application in precision agriculture. However, existing deep learning models struggle to generalize across heterogeneous agricultural environments due to reliance on dataset-specific visual features. We propose Vision-Language Weed Segmentation (VL-WS), a novel framework that addresses this limitation by grounding pixel-level segmentation in semantically aligned, domain-invariant representations. Our architecture employs a dual-encoder design, where frozen Contrastive Language-Image Pretraining (CLIP) embeddings and task-specific spatial features are fused and modulated via Feature-wise Linear Modulation (FiLM) layers conditioned on natural language captions. This design enables image level textual descriptions to guide channel-wise feature refinement while preserving fine-grained spatial localization. Unlike prior works restricted to training and evaluation on single-source datasets, VL-WS is trained on a unified corpus that includes close-range ground imagery (robotic platforms) and high-altitude UAV imagery, covering diverse crop types, weed species, growth stages, and sensing conditions. Experimental results across four benchmark datasets demonstrate the effectiveness of our framework, with VL-WS achieving a mean Dice score of 91.64% and outperforming the CNN baseline by 4.98%. The largest gains occur on the most challenging weed class, where VL-WS attains 80.45% Dice score compared to 65.03% for the best baseline, representing a 15.42% improvement. VL-WS further maintains stable weed segmentation performance under limited target-domain supervision, indicating improved generalization and data efficiency. These findings highlight the potential of vision-language alignment to enable scalable, label-efficient segmentation models deployable across diverse real-world agricultural domains.
CaLa: Complementary Association Learning for Augmenting Composed Image Retrieval
May 29, 2024



Composed Image Retrieval (CIR) involves searching for target images based on an image-text pair query. While current methods treat this as a query-target matching problem, we argue that CIR triplets contain additional associations beyond this primary relation. In our paper, we identify two new relations within triplets, treating each triplet as a graph node. Firstly, we introduce the concept of text-bridged image alignment, where the query text serves as a bridge between the query image and the target image. We propose a hinge-based cross-attention mechanism to incorporate this relation into network learning. Secondly, we explore complementary text reasoning, considering CIR as a form of cross-modal retrieval where two images compose to reason about complementary text. To integrate these perspectives effectively, we design a twin attention-based compositor. By combining these complementary associations with the explicit query pair-target image relation, we establish a comprehensive set of constraints for CIR. Our framework, CaLa (Complementary Association Learning for Augmenting Composed Image Retrieval), leverages these insights. We evaluate CaLa on CIRR and FashionIQ benchmarks with multiple backbones, demonstrating its superiority in composed image retrieval.
Generative Plant Growth Simulation from Sequence-Informed Environmental Conditions
May 23, 2024A plant growth simulation can be characterized as a reconstructed visual representation of a plant or plant system. The phenotypic characteristics and plant structures are controlled by the scene environment and other contextual attributes. Considering the temporal dependencies and compounding effects of various factors on growth trajectories, we formulate a probabilistic approach to the simulation task by solving a frame synthesis and pattern recognition problem. We introduce a Sequence-Informed Plant Growth Simulation framework (SI-PGS) that employs a conditional generative model to implicitly learn a distribution of possible plant representations within a dynamic scene from a fusion of low dimensional temporal sensor and context data. Methods such as controlled latent sampling and recurrent output connections are used to improve coherence in plant structures between frames of predictions. In this work, we demonstrate that SI-PGS is able to capture temporal dependencies and continuously generate realistic frames of a plant scene.
Dual Relation Alignment for Composed Image Retrieval
Sep 05, 2023



Composed image retrieval, a task involving the search for a target image using a reference image and a complementary text as the query, has witnessed significant advancements owing to the progress made in cross-modal modeling. Unlike the general image-text retrieval problem with only one alignment relation, i.e., image-text, we argue for the existence of two types of relations in composed image retrieval. The explicit relation pertains to the reference image & complementary text-target image, which is commonly exploited by existing methods. Besides this intuitive relation, the observations during our practice have uncovered another implicit yet crucial relation, i.e., reference image & target image-complementary text, since we found that the complementary text can be inferred by studying the relation between the target image and the reference image. Regrettably, existing methods largely focus on leveraging the explicit relation to learn their networks, while overlooking the implicit relation. In response to this weakness, We propose a new framework for composed image retrieval, termed dual relation alignment, which integrates both explicit and implicit relations to fully exploit the correlations among the triplets. Specifically, we design a vision compositor to fuse reference image and target image at first, then the resulted representation will serve two roles: (1) counterpart for semantic alignment with the complementary text and (2) compensation for the complementary text to boost the explicit relation modeling, thereby implant the implicit relation into the alignment learning. Our method is evaluated on two popular datasets, CIRR and FashionIQ, through extensive experiments. The results confirm the effectiveness of our dual-relation learning in substantially enhancing composed image retrieval performance.
Eff-3DPSeg: 3D organ-level plant shoot segmentation using annotation-efficient point clouds
Dec 20, 2022



Reliable and automated 3D plant shoot segmentation is a core prerequisite for the extraction of plant phenotypic traits at the organ level. Combining deep learning and point clouds can provide effective ways to address the challenge. However, fully supervised deep learning methods require datasets to be point-wise annotated, which is extremely expensive and time-consuming. In our work, we proposed a novel weakly supervised framework, Eff-3DPSeg, for 3D plant shoot segmentation. First, high-resolution point clouds of soybean were reconstructed using a low-cost photogrammetry system, and the Meshlab-based Plant Annotator was developed for plant point cloud annotation. Second, a weakly-supervised deep learning method was proposed for plant organ segmentation. The method contained: (1) Pretraining a self-supervised network using Viewpoint Bottleneck loss to learn meaningful intrinsic structure representation from the raw point clouds; (2) Fine-tuning the pre-trained model with about only 0.5% points being annotated to implement plant organ segmentation. After, three phenotypic traits (stem diameter, leaf width, and leaf length) were extracted. To test the generality of the proposed method, the public dataset Pheno4D was included in this study. Experimental results showed that the weakly-supervised network obtained similar segmentation performance compared with the fully-supervised setting. Our method achieved 95.1%, 96.6%, 95.8% and 92.2% in the Precision, Recall, F1-score, and mIoU for stem leaf segmentation and 53%, 62.8% and 70.3% in the AP, AP@25, and AP@50 for leaf instance segmentation. This study provides an effective way for characterizing 3D plant architecture, which will become useful for plant breeders to enhance selection processes.
COMET: A Novel Memory-Efficient Deep Learning Training Framework by Using Error-Bounded Lossy Compression
Nov 18, 2021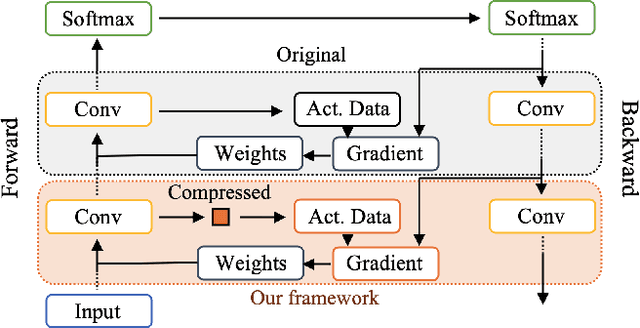
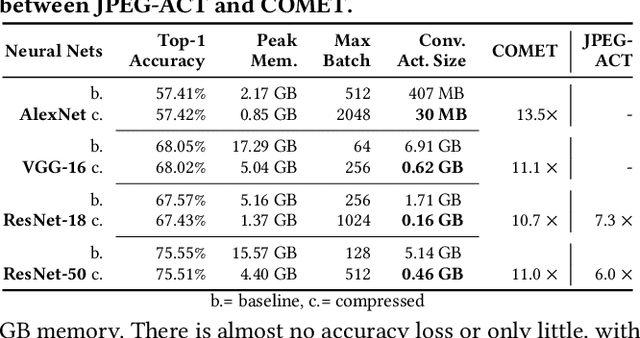
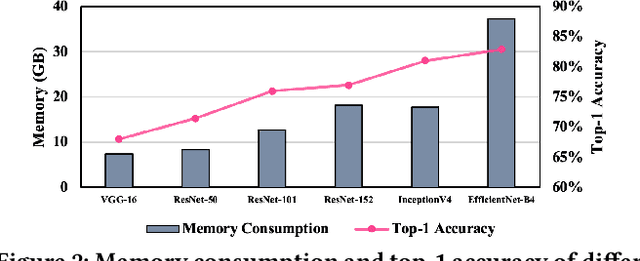
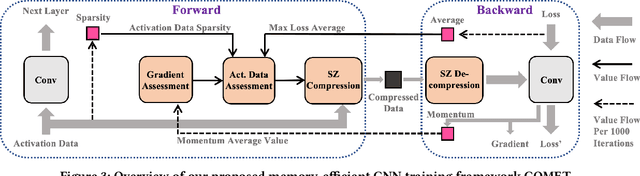
Training wide and deep neural networks (DNNs) require large amounts of storage resources such as memory because the intermediate activation data must be saved in the memory during forward propagation and then restored for backward propagation. However, state-of-the-art accelerators such as GPUs are only equipped with very limited memory capacities due to hardware design constraints, which significantly limits the maximum batch size and hence performance speedup when training large-scale DNNs. Traditional memory saving techniques either suffer from performance overhead or are constrained by limited interconnect bandwidth or specific interconnect technology. In this paper, we propose a novel memory-efficient CNN training framework (called COMET) that leverages error-bounded lossy compression to significantly reduce the memory requirement for training, to allow training larger models or to accelerate training. Different from the state-of-the-art solutions that adopt image-based lossy compressors (such as JPEG) to compress the activation data, our framework purposely adopts error-bounded lossy compression with a strict error-controlling mechanism. Specifically, we perform a theoretical analysis on the compression error propagation from the altered activation data to the gradients, and empirically investigate the impact of altered gradients over the training process. Based on these analyses, we optimize the error-bounded lossy compression and propose an adaptive error-bound control scheme for activation data compression. We evaluate our design against state-of-the-art solutions with five widely-adopted CNNs and ImageNet dataset. Experiments demonstrate that our proposed framework can significantly reduce the training memory consumption by up to 13.5X over the baseline training and 1.8X over another state-of-the-art compression-based framework, respectively, with little or no accuracy loss.