 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI based signage classification for linguistic landscape studies
Oct 27, 2025Linguistic Landscape (LL) research traditionally relies on manual photography and annotation of public signages to examine distribution of languages in urban space. While such methods yield valuable findings, the process is time-consuming and difficult for large study areas. This study explores the use of AI powered language detection method to automate LL analysis. Using Honolulu Chinatown as a case study, we constructed a georeferenced photo dataset of 1,449 images collected by researchers and applied AI for optical character recognition (OCR) and language classification. We also conducted manual validations for accuracy checking. This model achieved an overall accuracy of 79%. Five recurring types of mislabeling were identified, including distortion, reflection, degraded surface, graffiti, and hallucination. The analysis also reveals that the AI model treats all regions of an image equally, detecting peripheral or background texts that human interpreters typically ignore. Despite these limitations, the results demonstrate the potential of integrating AI-assisted workflows into LL research to reduce such time-consuming processes. However, due to all the limitations and mis-labels, we recognize that AI cannot be fully trusted during this process. This paper encourages a hybrid approach combining AI automation with human validation for a more reliable and efficient workflow.
Toward Medical Deepfake Detection: A Comprehensive Dataset and Novel Method
Sep 19, 2025The rapid advancement of generative AI in medical imaging has introduced both significant opportunities and serious challenges, especially the risk that fake medical images could undermine healthcare systems. These synthetic images pose serious risks, such as diagnostic deception, financial fraud, and misinformation. However, research on medical forensics to counter these threats remains limited, and there is a critical lack of comprehensive datasets specifically tailored for this field. Additionally, existing media forensic methods, which are primarily designed for natural or facial images, are inadequate for capturing the distinct characteristics and subtle artifacts of AI-generated medical images. To tackle these challenges, we introduce \textbf{MedForensics}, a large-scale medical forensics dataset encompassing six medical modalities and twelve state-of-the-art medical generative models. We also propose \textbf{DSKI}, a novel \textbf{D}ual-\textbf{S}tage \textbf{K}nowledge \textbf{I}nfusing detector that constructs a vision-language feature space tailored for the detection of AI-generated medical images. DSKI comprises two core components: 1) a cross-domain fine-trace adapter (CDFA) for extracting subtle forgery clues from both spatial and noise domains during training, and 2) a medical forensic retrieval module (MFRM) that boosts detection accuracy through few-shot retrieval during testing. Experimental results demonstrate that DSKI significantly outperforms both existing methods and human experts, achieving superior accuracy across multiple medical modalities.
M-learner:A Flexible And Powerful Framework To Study Heterogeneous Treatment Effect In Mediation Model
May 23, 2025We propose a novel method, termed the M-learner, for estimating heterogeneous indirect and total treatment effects and identifying relevant subgroups within a mediation framework. The procedure comprises four key steps. First, we compute individual-level conditional average indirect/total treatment effect Second, we construct a distance matrix based on pairwise differences. Third, we apply tSNE to project this matrix into a low-dimensional Euclidean space, followed by K-means clustering to identify subgroup structures. Finally, we calibrate and refine the clusters using a threshold-based procedure to determine the optimal configuration. To the best of our knowledge, this is the first approach specifically designed to capture treatment effect heterogeneity in the presence of mediation. Experimental results validate the robustness and effectiveness of the proposed framework. Application to the real-world Jobs II dataset highlights the broad adaptability and potential applicability of our method.Code is available at https: //anonymous.4open.science/r/M-learner-C4BB.
Verifying Robust Unlearning: Probing Residual Knowledge in Unlearned Models
Apr 21, 2025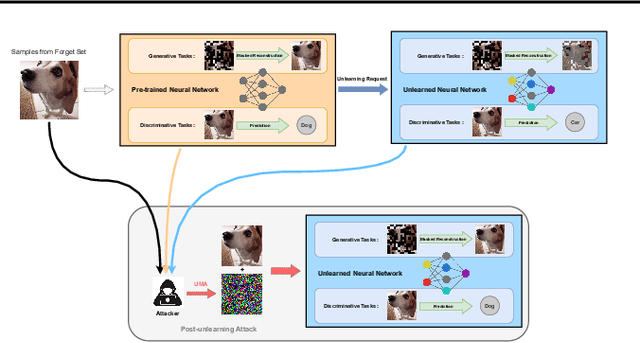
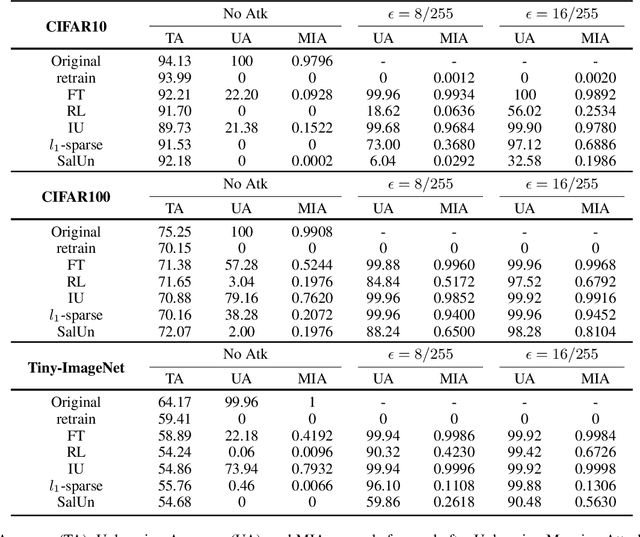
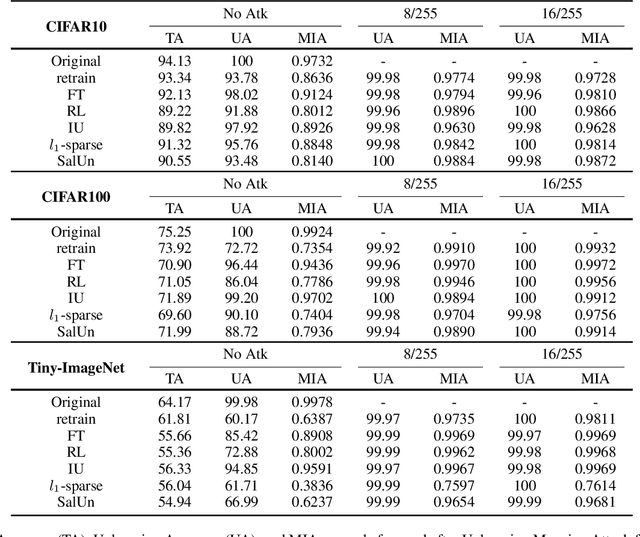

Machine Unlearning (MUL) is crucial for privacy protection and content regulation, yet recent studies reveal that traces of forgotten information persist in unlearned models, enabling adversaries to resurface removed knowledge. Existing verification methods only confirm whether unlearning was executed, failing to detect such residual information leaks. To address this, we introduce the concept of Robust Unlearning, ensuring models are indistinguishable from retraining and resistant to adversarial recovery. To empirically evaluate whether unlearning techniques meet this security standard, we propose the Unlearning Mapping Attack (UMA), a post-unlearning verification framework that actively probes models for forgotten traces using adversarial queries. Extensive experiments on discriminative and generative tasks show that existing unlearning techniques remain vulnerable, even when passing existing verification metrics. By establishing UMA as a practical verification tool, this study sets a new standard for assessing and enhancing machine unlearning security.
Multimodal Coreference Resolution for Chinese Social Media Dialogues: Dataset and Benchmark Approach
Apr 19, 2025Multimodal coreference resolution (MCR) aims to identify mentions referring to the same entity across different modalities, such as text and visuals, and is essential for understanding multimodal content. In the era of rapidly growing mutimodal content and social media, MCR is particularly crucial for interpreting user interactions and bridging text-visual references to improve communication and personalization. However, MCR research for real-world dialogues remains unexplored due to the lack of sufficient data resources.To address this gap, we introduce TikTalkCoref, the first Chinese multimodal coreference dataset for social media in real-world scenarios, derived from the popular Douyin short-video platform. This dataset pairs short videos with corresponding textual dialogues from user comments and includes manually annotated coreference clusters for both person mentions in the text and the coreferential person head regions in the corresponding video frames. We also present an effective benchmark approach for MCR, focusing on the celebrity domain, and conduct extensive experiments on our dataset, providing reliable benchmark results for this newly constructed dataset. We will release the TikTalkCoref dataset to facilitate future research on MCR for real-world social media dialogues.
From Dataset to Real-world: General 3D Object Detection via Generalized Cross-domain Few-shot Learning
Mar 08, 2025LiDAR-based 3D object detection datasets have been pivotal for autonomous driving, yet they cover a limited range of objects, restricting the model's generalization across diverse deployment environments. To address this, we introduce the first generalized cross-domain few-shot (GCFS) task in 3D object detection, which focuses on adapting a source-pretrained model for high performance on both common and novel classes in a target domain with few-shot samples. Our solution integrates multi-modal fusion and contrastive-enhanced prototype learning within one framework, holistically overcoming challenges related to data scarcity and domain adaptation in the GCFS setting. The multi-modal fusion module utilizes 2D vision-language models to extract rich, open-set semantic knowledge. To address biases in point distributions across varying structural complexities, we particularly introduce a physically-aware box searching strategy that leverages laser imaging principles to generate high-quality 3D box proposals from 2D insights, enhancing object recall. To effectively capture domain-specific representations for each class from limited target data, we further propose a contrastive-enhanced prototype learning, which strengthens the model's adaptability. We evaluate our approach with three GCFS benchmark settings, and extensive experiments demonstrate the effectiveness of our solution for GCFS tasks. The code will be publicly available.
Exploring the Impact of Temperature Scaling in Softmax for Classification and Adversarial Robustness
Feb 28, 2025The softmax function is a fundamental component in deep learning. This study delves into the often-overlooked parameter within the softmax function, known as "temperature," providing novel insights into the practical and theoretical aspects of temperature scaling for image classification. Our empirical studies, adopting convolutional neural networks and transformers on multiple benchmark datasets, reveal that moderate temperatures generally introduce better overall performance. Through extensive experiments and rigorous theoretical analysis, we explore the role of temperature scaling in model training and unveil that temperature not only influences learning step size but also shapes the model's optimization direction. Moreover, for the first time, we discover a surprising benefit of elevated temperatures: enhanced model robustness against common corruption, natural perturbation, and non-targeted adversarial attacks like Projected Gradient Descent. We extend our discoveries to adversarial training, demonstrating that, compared to the standard softmax function with the default temperature value, higher temperatures have the potential to enhance adversarial training. The insights of this work open new avenues for improving model performance and security in deep learning applications.
MDHP-Net: Detecting Injection Attacks on In-vehicle Network using Multi-Dimensional Hawkes Process and Temporal Model
Nov 15, 2024



The integration of intelligent and connected technologies in modern vehicles, while offering enhanced functionalities through Electronic Control Unit and interfaces like OBD-II and telematics, also exposes the vehicle's in-vehicle network (IVN) to potential cyberattacks. In this paper, we consider a specific type of cyberattack known as the injection attack. As demonstrated by empirical data from real-world cybersecurity adversarial competitions(available at https://mimic2024.xctf.org.cn/race/qwmimic2024 ), these injection attacks have excitation effect over time, gradually manipulating network traffic and disrupting the vehicle's normal functioning, ultimately compromising both its stability and safety. To profile the abnormal behavior of attackers, we propose a novel injection attack detector to extract long-term features of attack behavior. Specifically, we first provide a theoretical analysis of modeling the time-excitation effects of the attack using Multi-Dimensional Hawkes Process (MDHP). A gradient descent solver specifically tailored for MDHP, MDHP-GDS, is developed to accurately estimate optimal MDHP parameters. We then propose an injection attack detector, MDHP-Net, which integrates optimal MDHP parameters with MDHP-LSTM blocks to enhance temporal feature extraction. By introducing MDHP parameters, MDHP-Net captures complex temporal features that standard Long Short-Term Memory (LSTM) cannot, enriching temporal dependencies within our customized structure. Extensive evaluations demonstrate the effectiveness of our proposed detection approach.
ATLAS: Adapter-Based Multi-Modal Continual Learning with a Two-Stage Learning Strategy
Oct 14, 2024



While vision-and-language models significantly advance in many fields, the challenge of continual learning is unsolved. Parameter-efficient modules like adapters and prompts present a promising way to alleviate catastrophic forgetting. However, existing works usually learn individual adapters for each task, which may result in redundant knowledge among adapters. Moreover, they continue to use the original pre-trained model to initialize the downstream model, leading to negligible changes in the model's generalization compared to the original model. In addition, there is still a lack of research investigating the consequences of integrating a multi-modal model into the updating procedure for both uni-modal and multi-modal tasks and the subsequent impacts it has on downstream tasks. In this paper, we propose an adapter-based two-stage learning paradigm, a multi-modal continual learning scheme that consists of experience-based learning and novel knowledge expansion, which helps the model fully use experience knowledge and compensate for novel knowledge. Extensive experiments demonstrate that our method is proficient for continual learning. It expands the distribution of representation upstream while also minimizing the negative impact of forgetting previous tasks. Additionally, it enhances the generalization capability for downstream tasks. Furthermore, we incorporate both multi-modal and uni-modal tasks into upstream continual learning. We observe that learning from upstream tasks can help with downstream tasks. Our code will be available at: https://github.com/lihong2303/ATLAS.
InterMask: 3D Human Interaction Generation via Collaborative Masked Modelling
Oct 13, 2024Generating realistic 3D human-human interactions from textual descriptions remains a challenging task. Existing approaches, typically based on diffusion models, often generate unnatural and unrealistic results. In this work, we introduce InterMask, a novel framework for generating human interactions using collaborative masked modeling in discrete space. InterMask first employs a VQ-VAE to transform each motion sequence into a 2D discrete motion token map. Unlike traditional 1D VQ token maps, it better preserves fine-grained spatio-temporal details and promotes spatial awareness within each token. Building on this representation, InterMask utilizes a generative masked modeling framework to collaboratively model the tokens of two interacting individuals. This is achieved by employing a transformer architecture specifically designed to capture complex spatio-temporal interdependencies. During training, it randomly masks the motion tokens of both individuals and learns to predict them. In inference, starting from fully masked sequences, it progressively fills in the tokens for both individuals. With its enhanced motion representation, dedicated architecture, and effective learning strategy, InterMask achieves state-of-the-art results, producing high-fidelity and diverse human interactions. It outperforms previous methods, achieving an FID of $5.154$ (vs $5.535$ for in2IN) on the InterHuman dataset and $0.399$ (vs $5.207$ for InterGen) on the InterX dataset. Additionally, InterMask seamlessly supports reaction generation without the need for model redesign or fine-tuning.