 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning an Interpretable End-to-End Network for Real-Time Acoustic Beamforming
Jun 19, 2023Recently, many forms of audio industrial applications, such as sound monitoring and source localization, have begun exploiting smart multi-modal devices equipped with a microphone array. Regrettably, model-based methods are often difficult to employ for such devices due to their high computational complexity, as well as the difficulty of appropriately selecting the user-determined parameters. As an alternative, one may use deep network-based methods, but these are often difficult to generalize, nor can they generate the desired beamforming map directly. In this paper, a computationally efficient acoustic beamforming algorithm is proposed, which may be unrolled to form a model-based deep learning network for real-time imaging, here termed the DAMAS-FISTA-Net. By exploiting the natural structure of an acoustic beamformer, the proposed network inherits the physical knowledge of the acoustic system, and thus learns the underlying physical properties of the propagation. As a result, all the network parameters may be learned end-to-end, guided by a model-based prior using back-propagation. Notably, the proposed network enables an excellent interpretability and the ability of being able to process the raw data directly. Extensive numerical experiments using both simulated and real-world data illustrate the preferable performance of the DAMAS-FISTA-Net as compared to alternative approaches.
Hint-dynamic Knowledge Distillation
Nov 30, 2022



Knowledge Distillation (KD) transfers the knowledge from a high-capacity teacher model to promote a smaller student model. Existing efforts guide the distillation by matching their prediction logits, feature embedding, etc., while leaving how to efficiently utilize them in junction less explored. In this paper, we propose Hint-dynamic Knowledge Distillation, dubbed HKD, which excavates the knowledge from the teacher' s hints in a dynamic scheme. The guidance effect from the knowledge hints usually varies in different instances and learning stages, which motivates us to customize a specific hint-learning manner for each instance adaptively. Specifically, a meta-weight network is introduced to generate the instance-wise weight coefficients about knowledge hints in the perception of the dynamical learning progress of the student model. We further present a weight ensembling strategy to eliminate the potential bias of coefficient estimation by exploiting the historical statics. Experiments on standard benchmarks of CIFAR-100 and Tiny-ImageNet manifest that the proposed HKD well boost the effect of knowledge distillation tasks.
Uncertainty Inspired Underwater Image Enhancement
Jul 20, 2022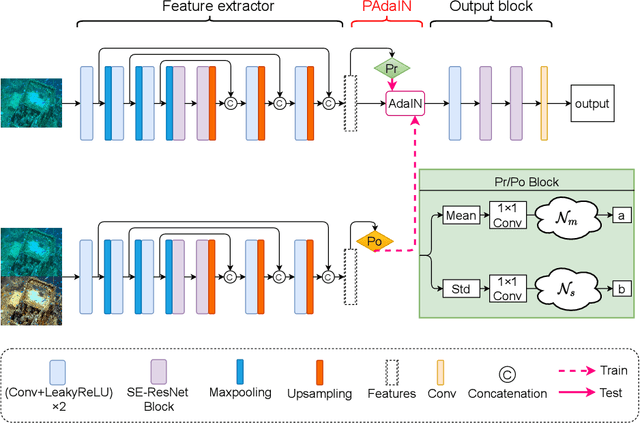
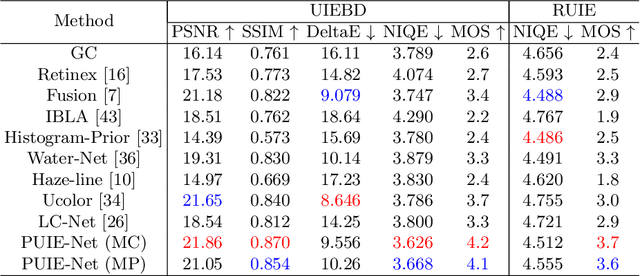


A main challenge faced in the deep learning-based Underwater Image Enhancement (UIE) is that the ground truth high-quality image is unavailable. Most of the existing methods first generate approximate reference maps and then train an enhancement network with certainty. This kind of method fails to handle the ambiguity of the reference map. In this paper, we resolve UIE into distribution estimation and consensus process. We present a novel probabilistic network to learn the enhancement distribution of degraded underwater images. Specifically, we combine conditional variational autoencoder with adaptive instance normalization to construct the enhancement distribution. After that, we adopt a consensus process to predict a deterministic result based on a set of samples from the distribution. By learning the enhancement distribution, our method can cope with the bias introduced in the reference map labeling to some extent. Additionally, the consensus process is useful to capture a robust and stable result. We examined the proposed method on two widely used real-world underwater image enhancement datasets. Experimental results demonstrate that our approach enables sampling possible enhancement predictions. Meanwhile, the consensus estimate yields competitive performance compared with state-of-the-art UIE methods. Code available at https://github.com/zhenqifu/PUIE-Net.
Knowledge Condensation Distillation
Jul 12, 2022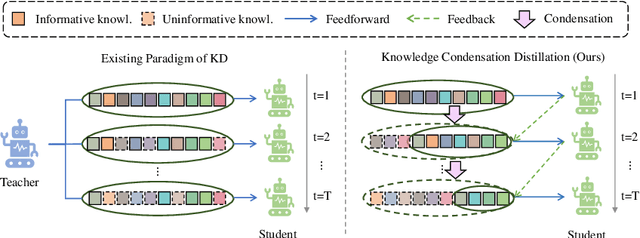
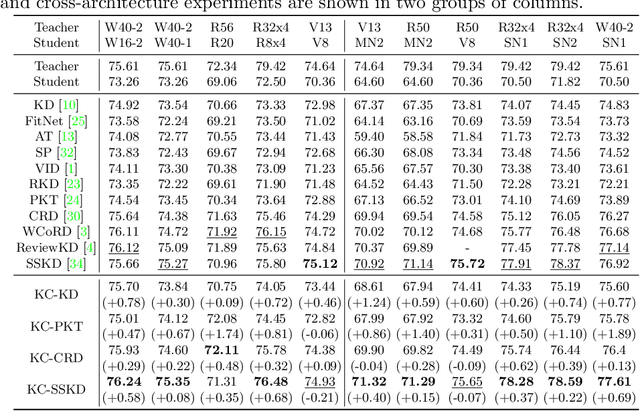
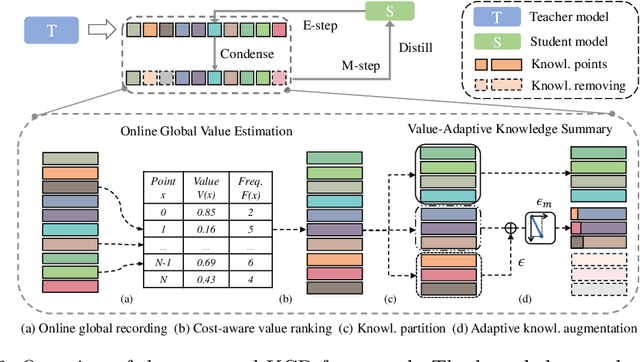

Knowledge Distillation (KD) transfers the knowledge from a high-capacity teacher network to strengthen a smaller student. Existing methods focus on excavating the knowledge hints and transferring the whole knowledge to the student. However, the knowledge redundancy arises since the knowledge shows different values to the student at different learning stages. In this paper, we propose Knowledge Condensation Distillation (KCD). Specifically, the knowledge value on each sample is dynamically estimated, based on which an Expectation-Maximization (EM) framework is forged to iteratively condense a compact knowledge set from the teacher to guide the student learning. Our approach is easy to build on top of the off-the-shelf KD methods, with no extra training parameters and negligible computation overhead. Thus, it presents one new perspective for KD, in which the student that actively identifies teacher's knowledge in line with its aptitude can learn to learn more effectively and efficiently. Experiments on standard benchmarks manifest that the proposed KCD can well boost the performance of student model with even higher distillation efficiency. Code is available at https://github.com/dzy3/KCD.
Relation Matters: Foreground-aware Graph-based Relational Reasoning for Domain Adaptive Object Detection
Jun 06, 2022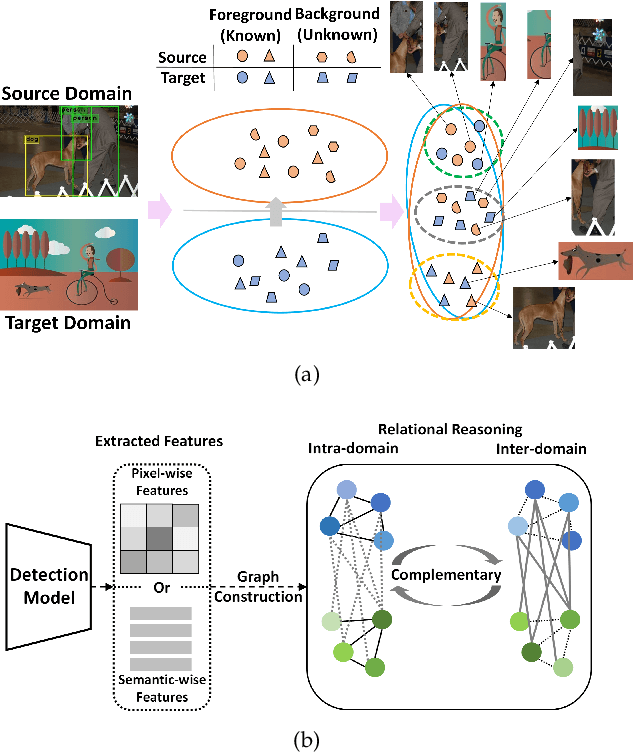
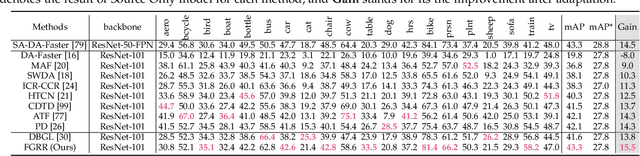
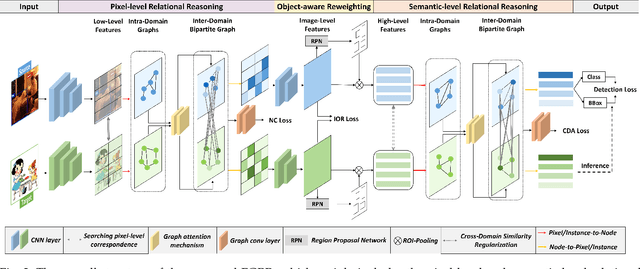
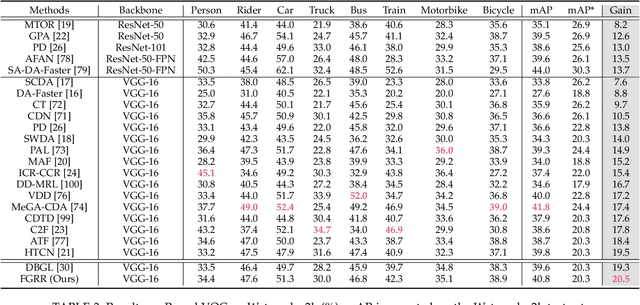
Domain Adaptive Object Detection (DAOD) focuses on improving the generalization ability of object detectors via knowledge transfer. Recent advances in DAOD strive to change the emphasis of the adaptation process from global to local in virtue of fine-grained feature alignment methods. However, both the global and local alignment approaches fail to capture the topological relations among different foreground objects as the explicit dependencies and interactions between and within domains are neglected. In this case, only seeking one-vs-one alignment does not necessarily ensure the precise knowledge transfer. Moreover, conventional alignment-based approaches may be vulnerable to catastrophic overfitting regarding those less transferable regions (e.g. backgrounds) due to the accumulation of inaccurate localization results in the target domain. To remedy these issues, we first formulate DAOD as an open-set domain adaptation problem, in which the foregrounds and backgrounds are seen as the ``known classes'' and ``unknown class'' respectively. Accordingly, we propose a new and general framework for DAOD, named Foreground-aware Graph-based Relational Reasoning (FGRR), which incorporates graph structures into the detection pipeline to explicitly model the intra- and inter-domain foreground object relations on both pixel and semantic spaces, thereby endowing the DAOD model with the capability of relational reasoning beyond the popular alignment-based paradigm. The inter-domain visual and semantic correlations are hierarchically modeled via bipartite graph structures, and the intra-domain relations are encoded via graph attention mechanisms. Empirical results demonstrate that the proposed FGRR exceeds the state-of-the-art performance on four DAOD benchmarks.
A Closer Look at Personalization in Federated Image Classification
Apr 22, 2022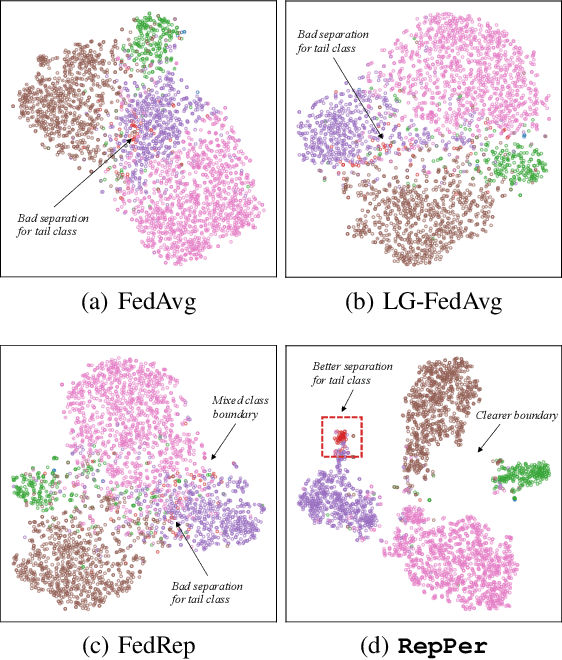
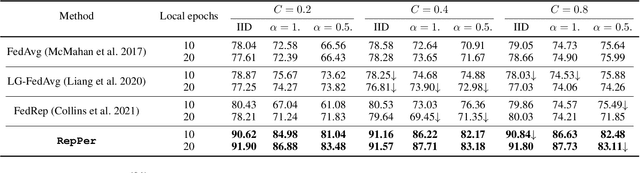
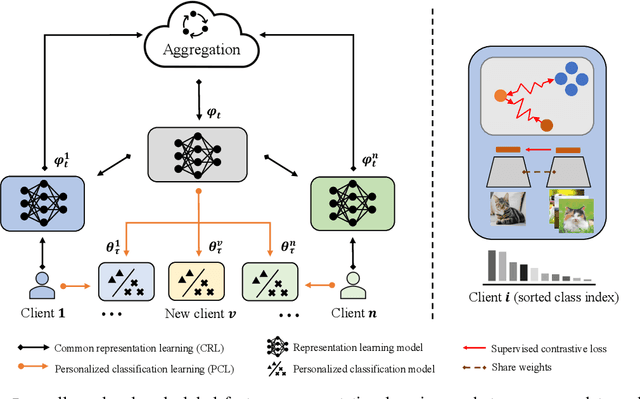
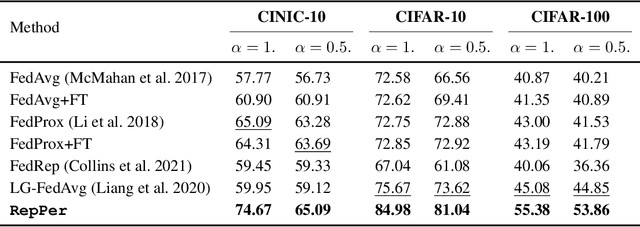
Federated Learning (FL) is developed to learn a single global model across the decentralized data, while is susceptible when realizing client-specific personalization in the presence of statistical heterogeneity. However, studies focus on learning a robust global model or personalized classifiers, which yield divergence due to inconsistent objectives. This paper shows that it is possible to achieve flexible personalization after the convergence of the global model by introducing representation learning. In this paper, we first analyze and determine that non-IID data harms representation learning of the global model. Existing FL methods adhere to the scheme of jointly learning representations and classifiers, where the global model is an average of classification-based local models that are consistently subject to heterogeneity from non-IID data. As a solution, we separate representation learning from classification learning in FL and propose RepPer, an independent two-stage personalized FL framework.We first learn the client-side feature representation models that are robust to non-IID data and aggregate them into a global common representation model. After that, we achieve personalization by learning a classifier head for each client, based on the common representation obtained at the former stage. Notably, the proposed two-stage learning scheme of RepPer can be potentially used for lightweight edge computing that involves devices with constrained computation power.Experiments on various datasets (CIFAR-10/100, CINIC-10) and heterogeneous data setup show that RepPer outperforms alternatives in flexibility and personalization on non-IID data.
AFSC: Adaptive Fourier Space Compression for Anomaly Detection
Apr 17, 2022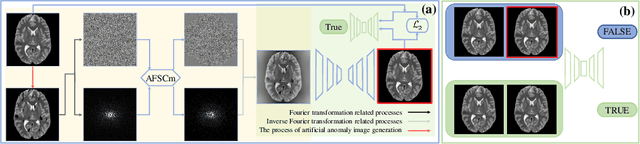
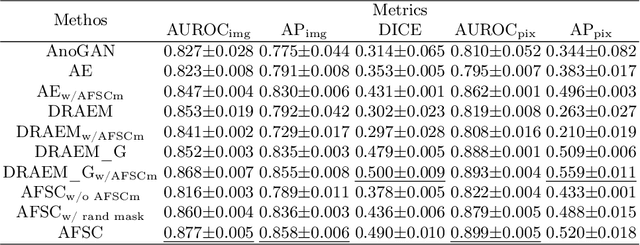
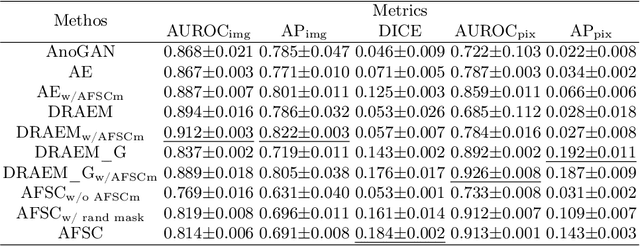
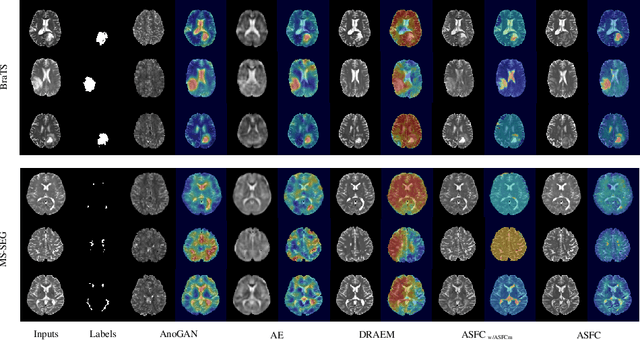
Anomaly Detection (AD) on medical images enables a model to recognize any type of anomaly pattern without lesion-specific supervised learning. Data augmentation based methods construct pseudo-healthy images by "pasting" fake lesions on real healthy ones, and a network is trained to predict healthy images in a supervised manner. The lesion can be found by difference between the unhealthy input and pseudo-healthy output. However, using only manually designed fake lesions fail to approximate to irregular real lesions, hence limiting the model generalization. We assume by exploring the intrinsic data property within images, we can distinguish previously unseen lesions from healthy regions in an unhealthy image. In this study, we propose an Adaptive Fourier Space Compression (AFSC) module to distill healthy feature for AD. The compression of both magnitude and phase in frequency domain addresses the hyper intensity and diverse position of lesions. Experimental results on the BraTS and MS-SEG datasets demonstrate an AFSC baseline is able to produce promising detection results, and an AFSC module can be effectively embedded into existing AD methods.
Acoustic-Net: A Novel Neural Network for Sound Localization and Quantification
Mar 31, 2022
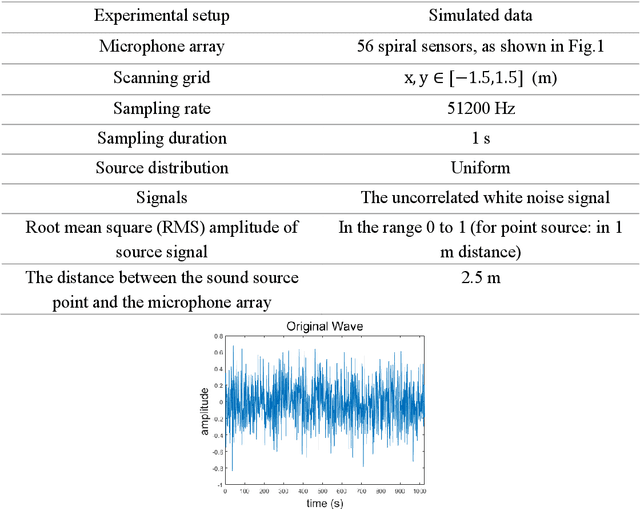
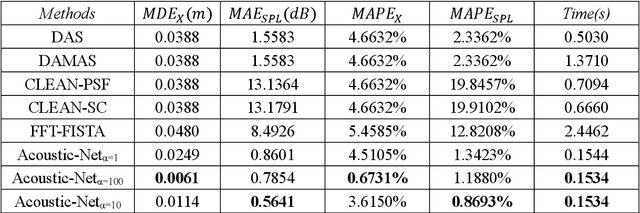
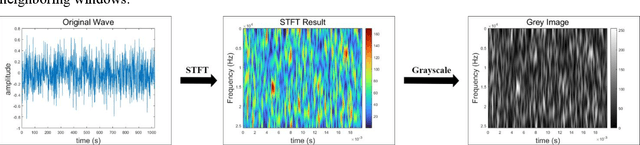
Acoustic source localization has been applied in different fields, such as aeronautics and ocean science, generally using multiple microphones array data to reconstruct the source location. However, the model-based beamforming methods fail to achieve the high-resolution of conventional beamforming maps. Deep neural networks are also appropriate to locate the sound source, but in general, these methods with complex network structures are hard to be recognized by hardware. In this paper, a novel neural network, termed the Acoustic-Net, is proposed to locate and quantify the sound source simply using the original signals. The experiments demonstrate that the proposed method significantly improves the accuracy of sound source prediction and the computing speed, which may generalize well to real data. The code and trained models are available at https://github.com/JoaquinChou/Acoustic-Net.
Harmonizing Pathological and Normal Pixels for Pseudo-healthy Synthesis
Mar 29, 2022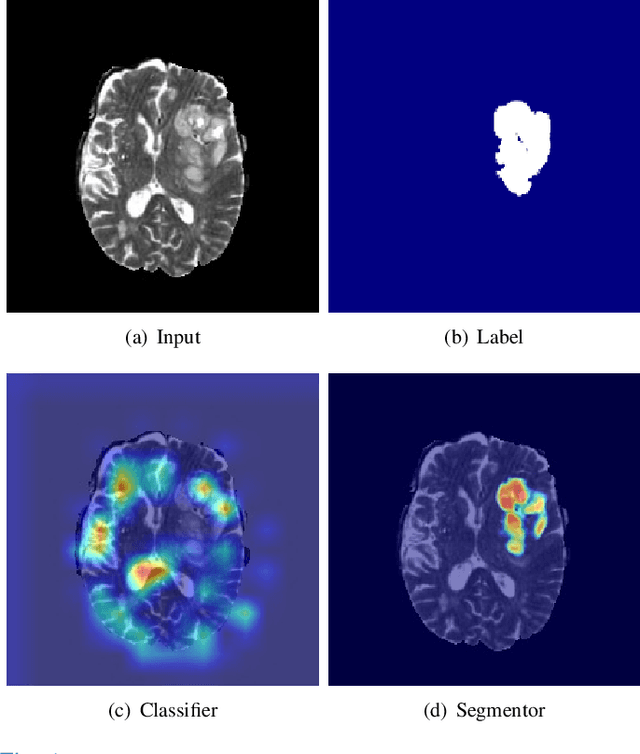
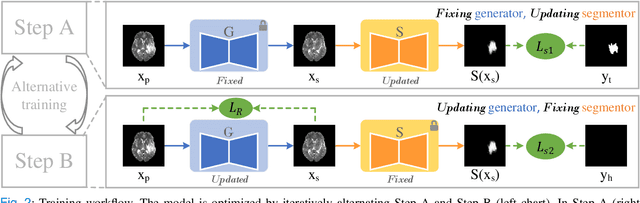
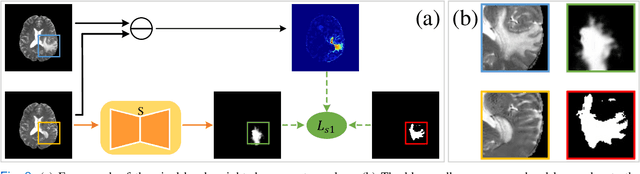

Synthesizing a subject-specific pathology-free image from a pathological image is valuable for algorithm development and clinical practice. In recent years, several approaches based on the Generative Adversarial Network (GAN) have achieved promising results in pseudo-healthy synthesis. However, the discriminator (i.e., a classifier) in the GAN cannot accurately identify lesions and further hampers from generating admirable pseudo-healthy images. To address this problem, we present a new type of discriminator, the segmentor, to accurately locate the lesions and improve the visual quality of pseudo-healthy images. Then, we apply the generated images into medical image enhancement and utilize the enhanced results to cope with the low contrast problem existing in medical image segmentation. Furthermore, a reliable metric is proposed by utilizing two attributes of label noise to measure the health of synthetic images. Comprehensive experiments on the T2 modality of BraTS demonstrate that the proposed method substantially outperforms the state-of-the-art methods. The method achieves better performance than the existing methods with only 30\% of the training data. The effectiveness of the proposed method is also demonstrated on the LiTS and the T1 modality of BraTS. The code and the pre-trained model of this study are publicly available at https://github.com/Au3C2/Generator-Versus-Segmentor.
Self-Verification in Image Denoising
Nov 01, 2021
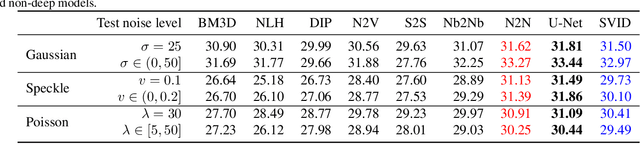
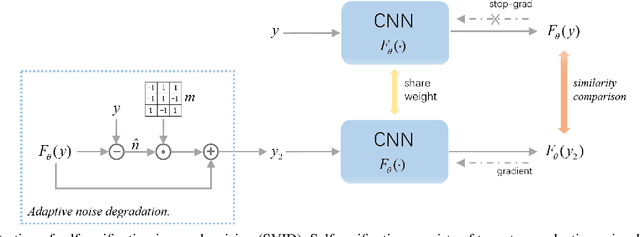
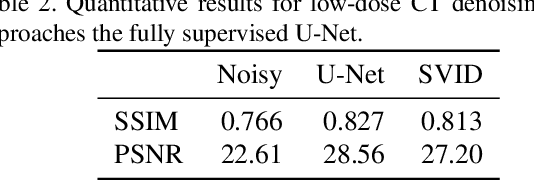
We devise a new regularization, called self-verification, for image denoising. This regularization is formulated using a deep image prior learned by the network, rather than a traditional predefined prior. Specifically, we treat the output of the network as a ``prior'' that we denoise again after ``re-noising''. The comparison between the again denoised image and its prior can be interpreted as a self-verification of the network's denoising ability. We demonstrate that self-verification encourages the network to capture low-level image statistics needed to restore the image. Based on this self-verification regularization, we further show that the network can learn to denoise even if it has not seen any clean images. This learning strategy is self-supervised, and we refer to it as Self-Verification Image Denoising (SVID). SVID can be seen as a mixture of learning-based methods and traditional model-based denoising methods, in which regularization is adaptively formulated using the output of the network. We show the application of SVID to various denoising tasks using only observed corrupted data. It can achieve the denoising performance close to supervised CNNs.