 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Dynamic Knowledge Graphs from Text-based Games
Oct 22, 2019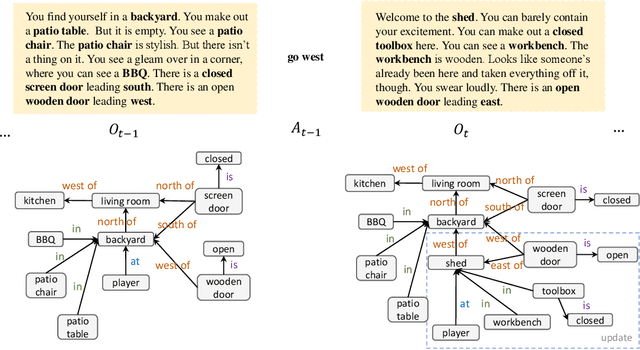

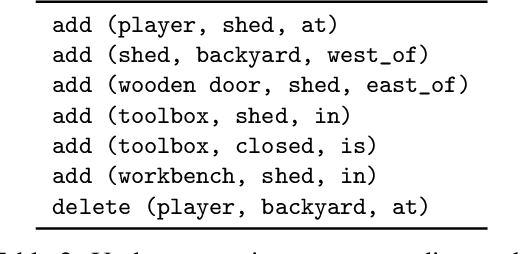
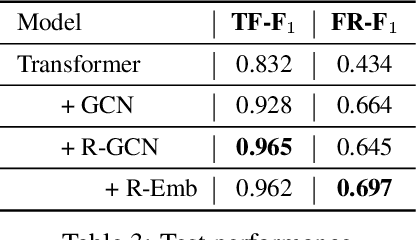
We are interested in learning how to update Knowledge Graphs (KG) from text. In this preliminary work, we propose a novel Sequence-to-Sequence (Seq2Seq) architecture to generate elementary KG operations. Furthermore, we introduce a new dataset for KG extraction built upon text-based game transitions (over 300k data points). We conduct experiments and discuss the results.
Does Order Matter? An Empirical Study on Generating Multiple Keyphrases as a Sequence
Oct 20, 2019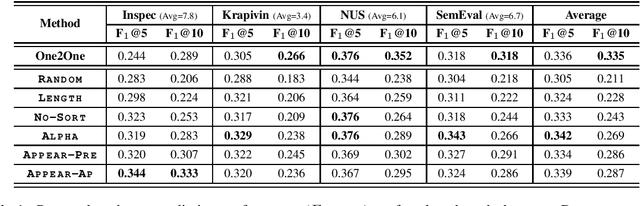
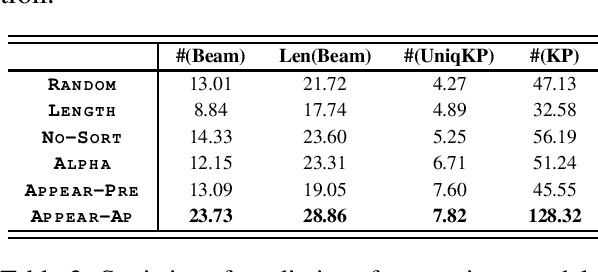
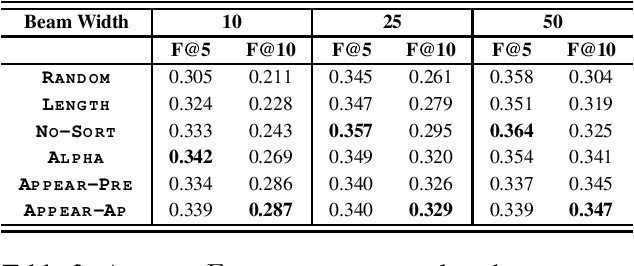
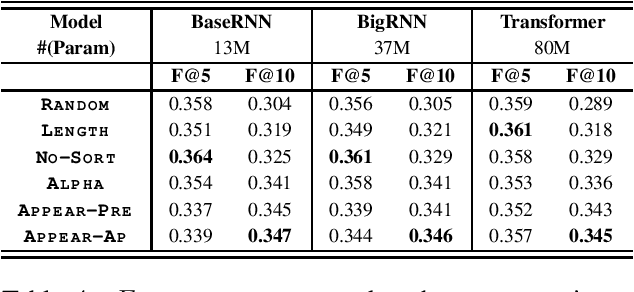
Recently, concatenating multiple keyphrases as a target sequence has been proposed as a new learning paradigm for keyphrase generation. Existing studies concatenate target keyphrases in different orders but no study has examined the effects of ordering on models' behavior. In this paper, we propose several orderings for concatenation and inspect the important factors for training a successful keyphrase generation model. By running comprehensive comparisons, we observe one preferable ordering and summarize a number of empirical findings and challenges, which can shed light on future research on this line of work.
Interactive Fiction Games: A Colossal Adventure
Sep 11, 2019
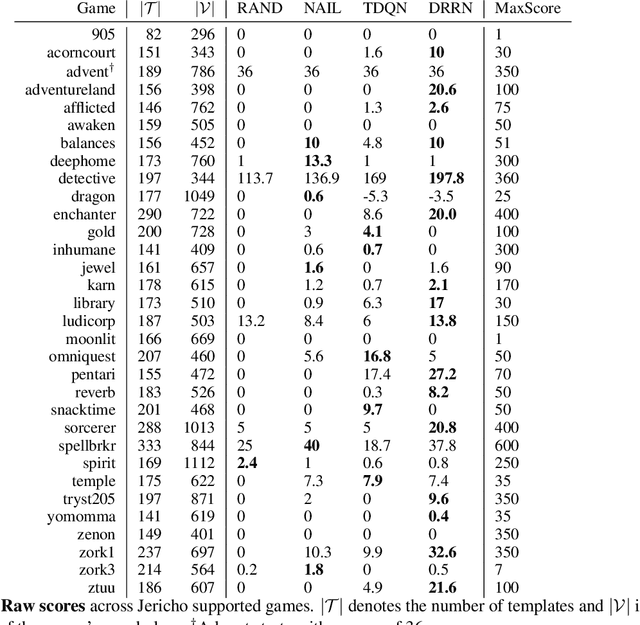
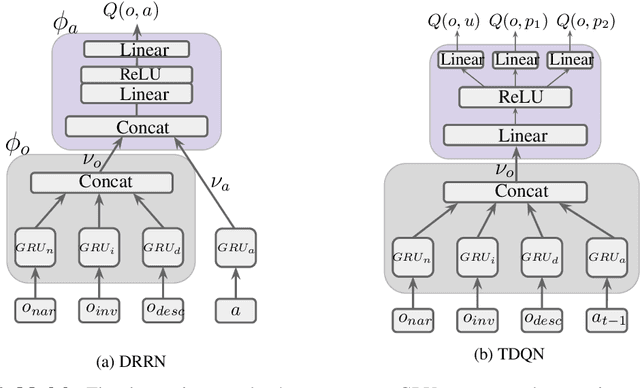

A hallmark of human intelligence is the ability to understand and communicate with language. Interactive Fiction games are fully text-based simulation environments where a player issues text commands to effect change in the environment and progress through the story. We argue that IF games are an excellent testbed for studying language-based autonomous agents. In particular, IF games combine challenges of combinatorial action spaces, language understanding, and commonsense reasoning. To facilitate rapid development of language-based agents, we introduce Jericho, a learning environment for man-made IF games and conduct a comprehensive study of text-agents across a rich set of games, highlighting directions in which agents can improve.
Interactive Machine Comprehension with Information Seeking Agents
Sep 04, 2019
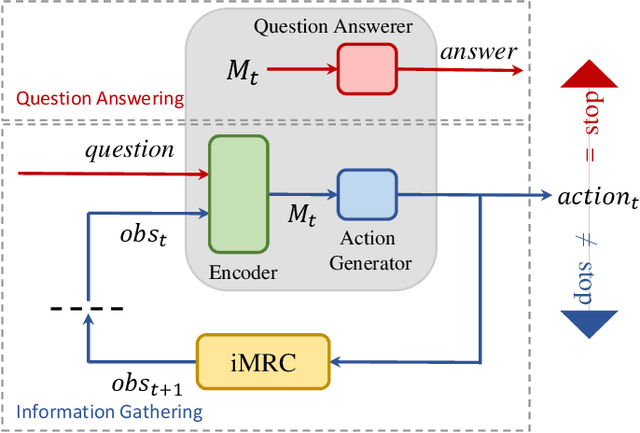
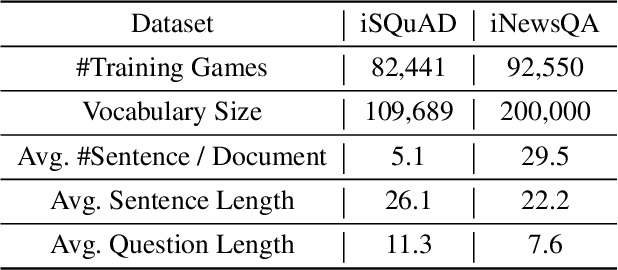
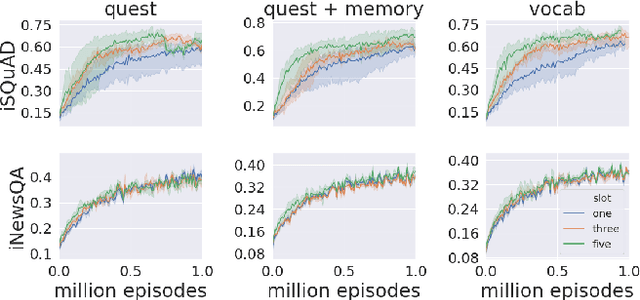
Existing machine reading comprehension (MRC) models do not scale effectively to real-world applications like web-level information retrieval and question answering (QA). We argue that this stems from the nature of MRC datasets: most of these are static environments wherein the supporting documents and all necessary information are fully observed. In this paper, we propose a simple method that reframes existing MRC datasets as interactive, partially observable environments. Specifically, we "occlude" the majority of a document's text and add context-sensitive commands that reveal "glimpses" of the hidden text to a model. We repurpose SQuAD and NewsQA as an initial case study, and then show how the interactive corpora can be used to train a model that seeks relevant information through sequential decision making. We believe that this setting can contribute in scaling models to web-level QA scenarios.
Interactive Language Learning by Question Answering
Aug 28, 2019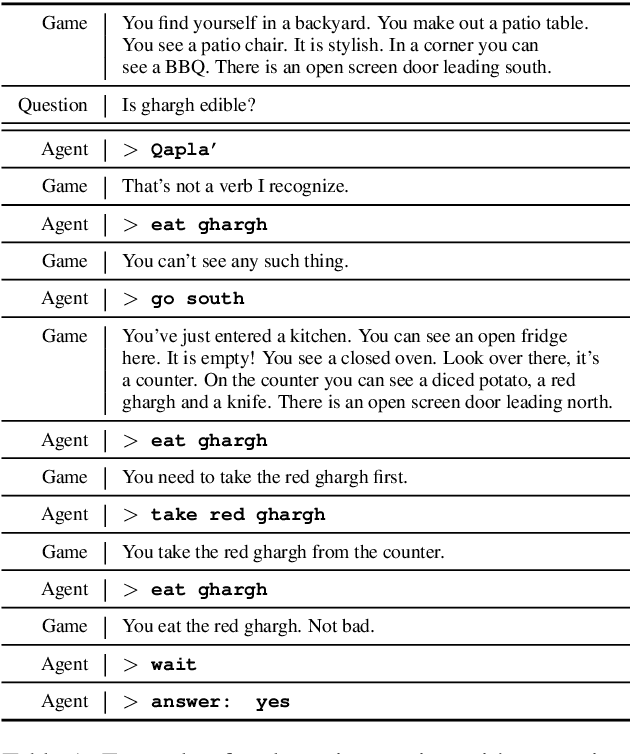
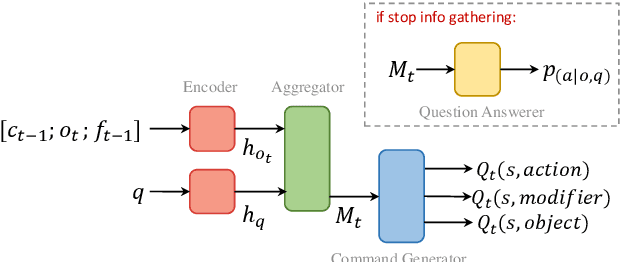
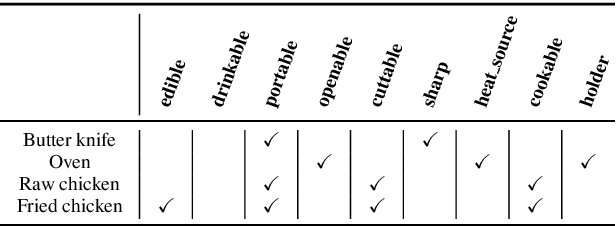
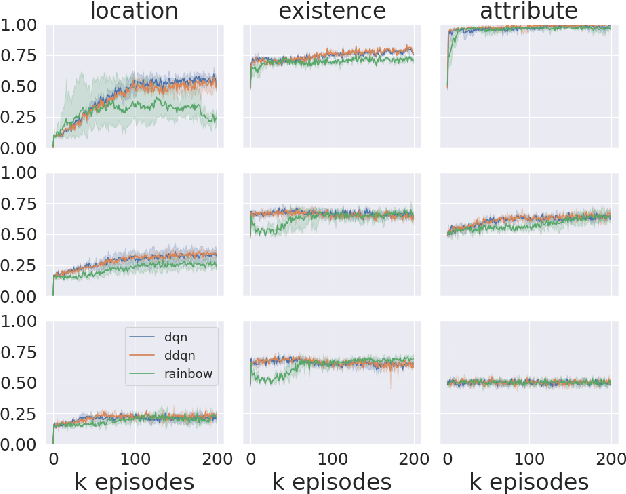
Humans observe and interact with the world to acquire knowledge. However, most existing machine reading comprehension (MRC) tasks miss the interactive, information-seeking component of comprehension. Such tasks present models with static documents that contain all necessary information, usually concentrated in a single short substring. Thus, models can achieve strong performance through simple word- and phrase-based pattern matching. We address this problem by formulating a novel text-based question answering task: Question Answering with Interactive Text (QAit). In QAit, an agent must interact with a partially observable text-based environment to gather information required to answer questions. QAit poses questions about the existence, location, and attributes of objects found in the environment. The data is built using a text-based game generator that defines the underlying dynamics of interaction with the environment. We propose and evaluate a set of baseline models for the QAit task that includes deep reinforcement learning agents. Experiments show that the task presents a major challenge for machine reading systems, while humans solve it with relative ease.
Simple and Effective Curriculum Pointer-Generator Networks for Reading Comprehension over Long Narratives
May 26, 2019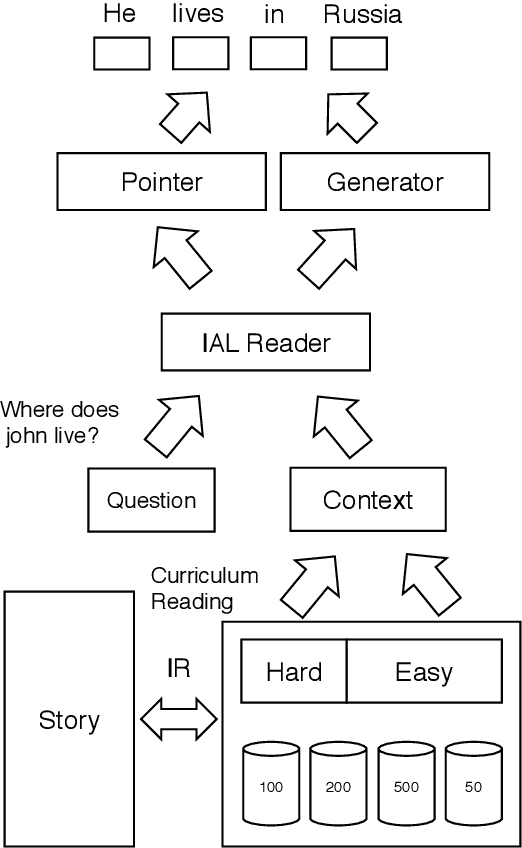
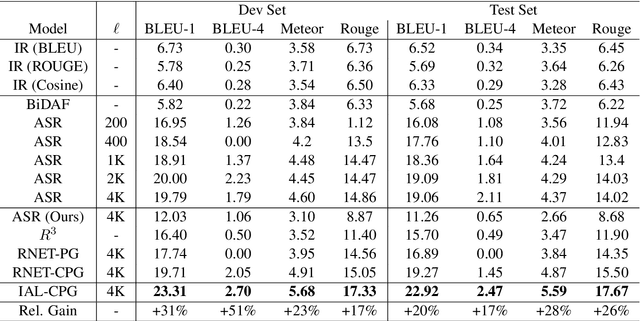
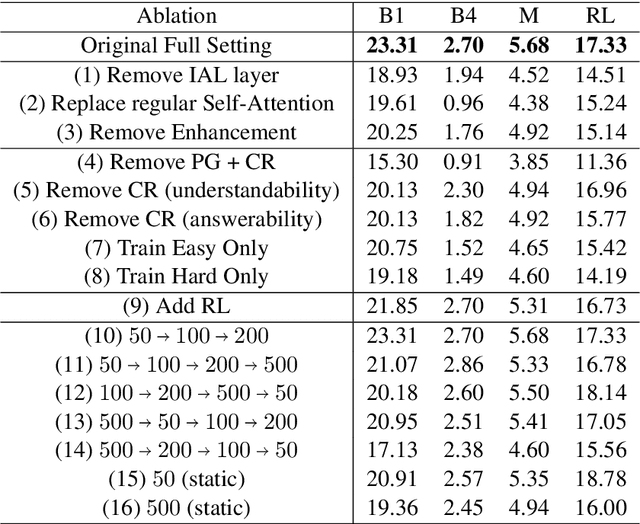

This paper tackles the problem of reading comprehension over long narratives where documents easily span over thousands of tokens. We propose a curriculum learning (CL) based Pointer-Generator framework for reading/sampling over large documents, enabling diverse training of the neural model based on the notion of alternating contextual difficulty. This can be interpreted as a form of domain randomization and/or generative pretraining during training. To this end, the usage of the Pointer-Generator softens the requirement of having the answer within the context, enabling us to construct diverse training samples for learning. Additionally, we propose a new Introspective Alignment Layer (IAL), which reasons over decomposed alignments using block-based self-attention. We evaluate our proposed method on the NarrativeQA reading comprehension benchmark, achieving state-of-the-art performance, improving existing baselines by $51\%$ relative improvement on BLEU-4 and $17\%$ relative improvement on Rouge-L. Extensive ablations confirm the effectiveness of our proposed IAL and CL components.
Towards Solving Text-based Games by Producing Adaptive Action Spaces
Dec 03, 2018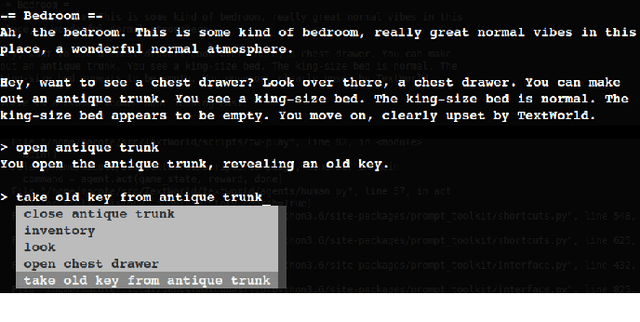

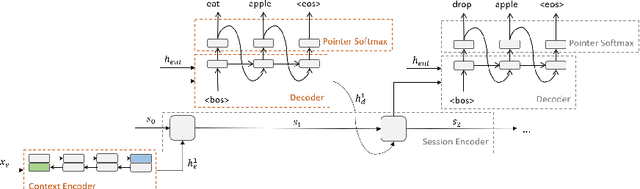
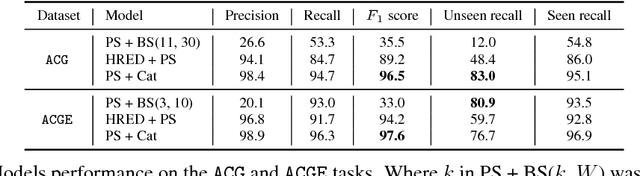
To solve a text-based game, an agent needs to formulate valid text commands for a given context and find the ones that lead to success. Recent attempts at solving text-based games with deep reinforcement learning have focused on the latter, i.e., learning to act optimally when valid actions are known in advance. In this work, we propose to tackle the first task and train a model that generates the set of all valid commands for a given context. We try three generative models on a dataset generated with Textworld. The best model can generate valid commands which were unseen at training and achieve high $F_1$ score on the test set.
Building Dynamic Knowledge Graphs from Text using Machine Reading Comprehension
Oct 12, 2018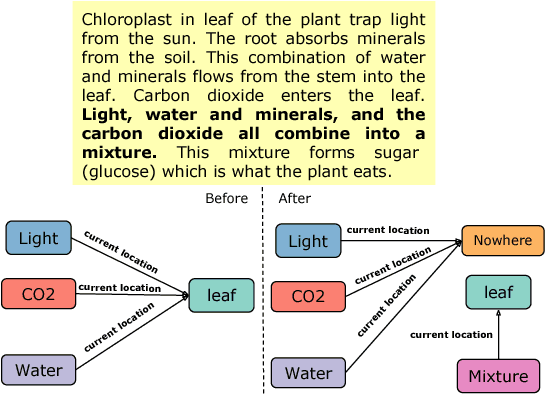

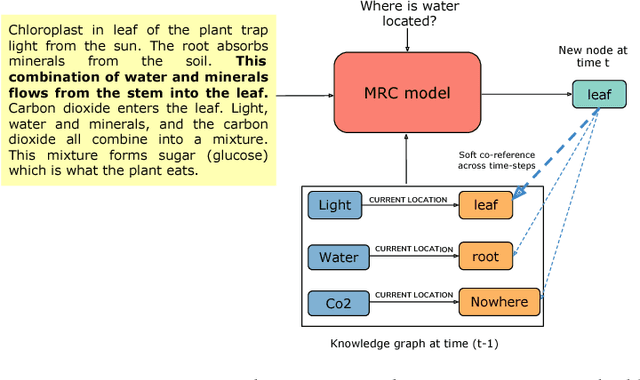
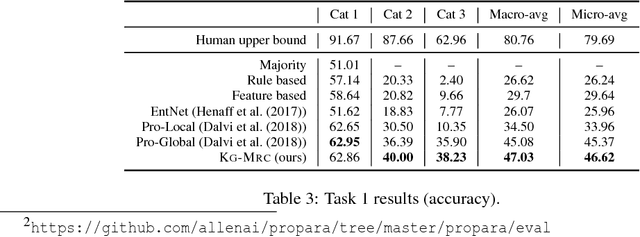
We propose a neural machine-reading model that constructs dynamic knowledge graphs from procedural text. It builds these graphs recurrently for each step of the described procedure, and uses them to track the evolving states of participant entities. We harness and extend a recently proposed machine reading comprehension (MRC) model to query for entity states, since these states are generally communicated in spans of text and MRC models perform well in extracting entity-centric spans. The explicit, structured, and evolving knowledge graph representations that our model constructs can be used in downstream question answering tasks to improve machine comprehension of text, as we demonstrate empirically. On two comprehension tasks from the recently proposed PROPARA dataset (Dalvi et al., 2018), our model achieves state-of-the-art results. We further show that our model is competitive on the RECIPES dataset (Kiddon et al., 2015), suggesting it may be generally applicable. We present some evidence that the model's knowledge graphs help it to impose commonsense constraints on its predictions.
Generating Diverse Numbers of Diverse Keyphrases
Oct 11, 2018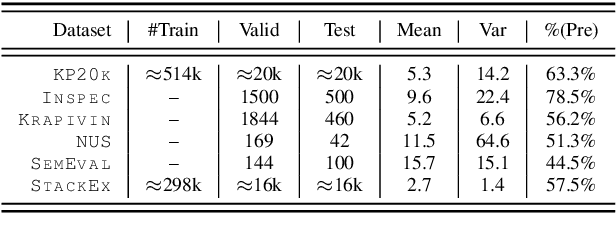
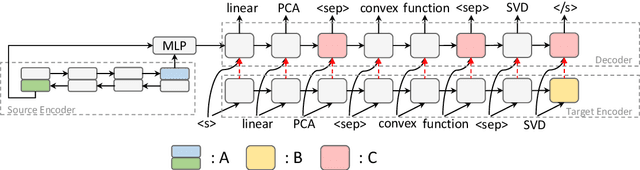
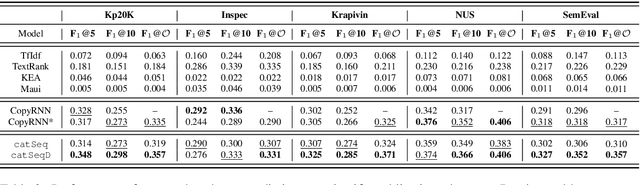
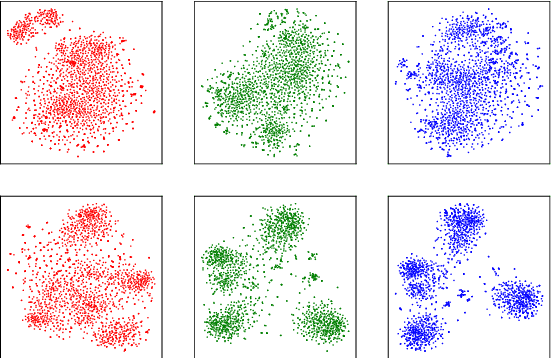
Existing keyphrase generation studies suffer from the problems of generating duplicate phrases and deficient evaluation based on a fixed number of predicted phrases. We propose a recurrent generative model that generates multiple keyphrases sequentially from a text, with specific modules that promote generation diversity. We further propose two new metrics that consider a variable number of phrases. With both existing and proposed evaluation setups, our model demonstrates superior performance to baselines on three types of keyphrase generation datasets, including two newly introduced in this work: StackExchange and TextWorld ACG. In contrast to previous keyphrase generation approaches, our model generates sets of diverse keyphrases of a variable number.
Rapid Adaptation with Conditionally Shifted Neurons
Jul 03, 2018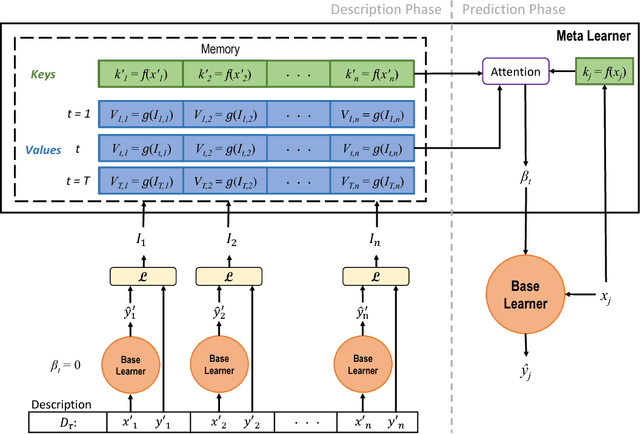
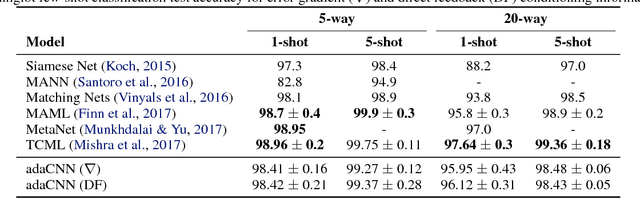
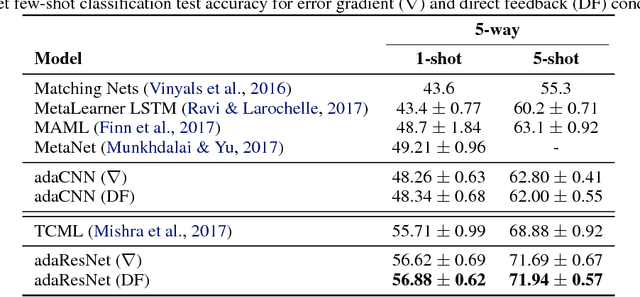
We describe a mechanism by which artificial neural networks can learn rapid adaptation - the ability to adapt on the fly, with little data, to new tasks - that we call conditionally shifted neurons. We apply this mechanism in the framework of metalearning, where the aim is to replicate some of the flexibility of human learning in machines. Conditionally shifted neurons modify their activation values with task-specific shifts retrieved from a memory module, which is populated rapidly based on limited task experience. On metalearning benchmarks from the vision and language domains, models augmented with conditionally shifted neurons achieve state-of-the-art results.