 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHistDiT: A Structure-Aware Latent Conditional Diffusion Model for High-Fidelity Virtual Staining in Histopathology
Apr 09, 2026Immunohistochemistry (IHC) is essential for assessing specific immune biomarkers like Human Epidermal growth-factor Receptor 2 (HER2) in breast cancer. However, the traditional protocols of obtaining IHC stains are resource-intensive, time-consuming, and prone to structural damages. Virtual staining has emerged as a scalable alternative, but it faces significant challenges in preserving fine-grained cellular structures while accurately translating biochemical expressions. Current state-of-the-art methods still rely on Generative Adversarial Networks (GANs) or standard convolutional U-Net diffusion models that often struggle with "structure and staining trade-offs". The generated samples are either structurally relevant but blurry, or texturally realistic but have artifacts that compromise their diagnostic use. In this paper, we introduce HistDiT, a novel latent conditional Diffusion Transformer (DiT) architecture that establishes a new benchmark for visual fidelity in virtual histological staining. The novelty introduced in this work is, a) the Dual-Stream Conditioning strategy that explicitly maintains a balance between spatial constraints via VAE-encoded latents and semantic phenotype guidance via UNI embeddings; b) the multi-objective loss function that contributes to sharper images with clear morphological structure; and c) the use of the Structural Correlation Metric (SCM) to focus on the core morphological structure for precise assessment of sample quality. Consequently, our model outperforms existing baselines, as demonstrated through rigorous quantitative and qualitative evaluations.
IFViT: Interpretable Fixed-Length Representation for Fingerprint Matching via Vision Transformer
Apr 12, 2024



Determining dense feature points on fingerprints used in constructing deep fixed-length representations for accurate matching, particularly at the pixel level, is of significant interest. To explore the interpretability of fingerprint matching, we propose a multi-stage interpretable fingerprint matching network, namely Interpretable Fixed-length Representation for Fingerprint Matching via Vision Transformer (IFViT), which consists of two primary modules. The first module, an interpretable dense registration module, establishes a Vision Transformer (ViT)-based Siamese Network to capture long-range dependencies and the global context in fingerprint pairs. It provides interpretable dense pixel-wise correspondences of feature points for fingerprint alignment and enhances the interpretability in the subsequent matching stage. The second module takes into account both local and global representations of the aligned fingerprint pair to achieve an interpretable fixed-length representation extraction and matching. It employs the ViTs trained in the first module with the additional fully connected layer and retrains them to simultaneously produce the discriminative fixed-length representation and interpretable dense pixel-wise correspondences of feature points. Extensive experimental results on diverse publicly available fingerprint databases demonstrate that the proposed framework not only exhibits superior performance on dense registration and matching but also significantly promotes the interpretability in deep fixed-length representations-based fingerprint matching.
Balancing Accuracy and Latency in Multipath Neural Networks
Apr 25, 2021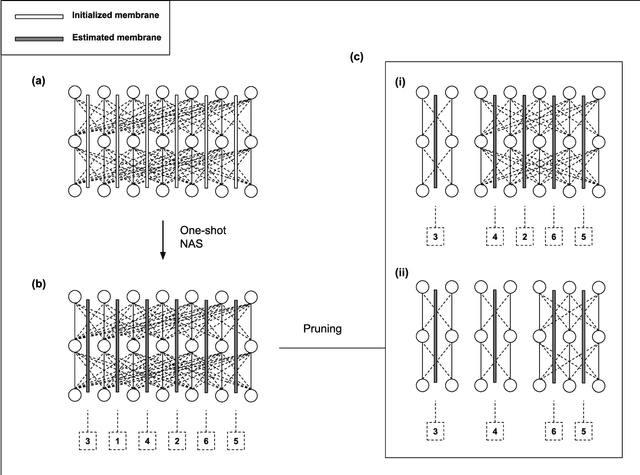
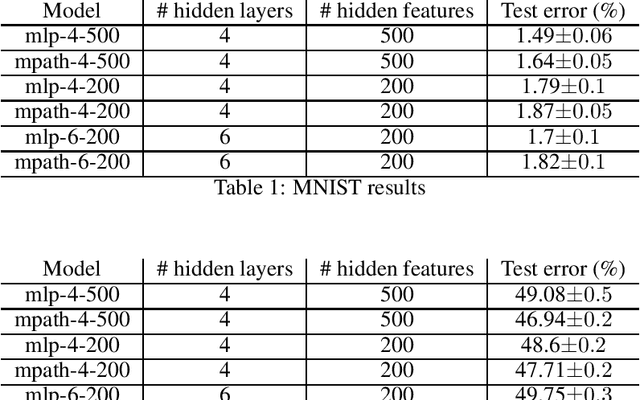
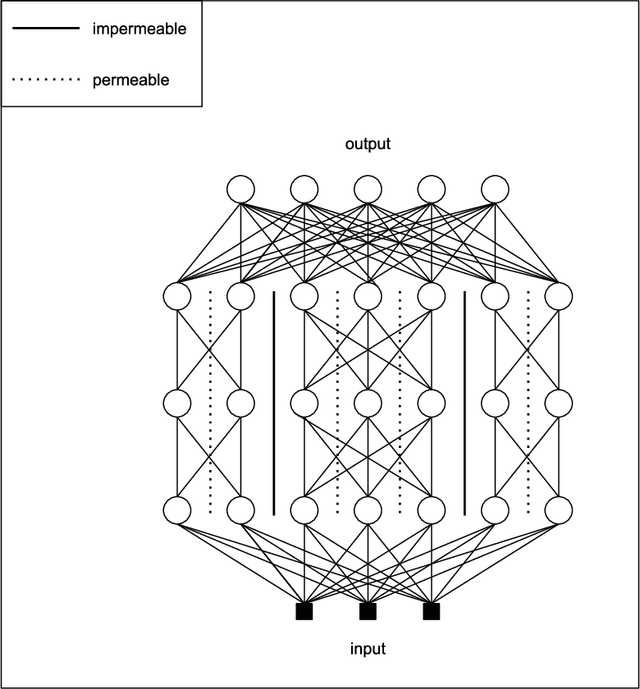
The growing capacity of neural networks has strongly contributed to their success at complex machine learning tasks and the computational demand of such large models has, in turn, stimulated a significant improvement in the hardware necessary to accelerate their computations. However, models with high latency aren't suitable for limited-resource environments such as hand-held and IoT devices. Hence, many deep learning techniques aim to address this problem by developing models with reasonable accuracy without violating the limited-resource constraint. In this work, we use a one-shot neural architecture search model to implicitly evaluate the performance of an intractable number of multipath neural networks. Combining this architecture search with a pruning technique and architecture sample evaluation, we can model the relation between the accuracy and the latency of a spectrum of models with graded complexity. We show that our method can accurately model the relative performance between models with different latencies and predict the performance of unseen models with good precision across different datasets.