 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Understanding Feature Learning in Parameter Transfer
Sep 26, 2025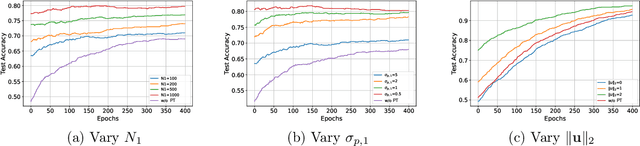
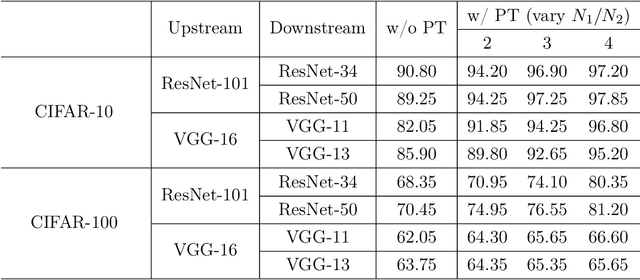
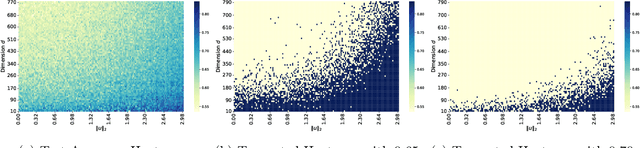
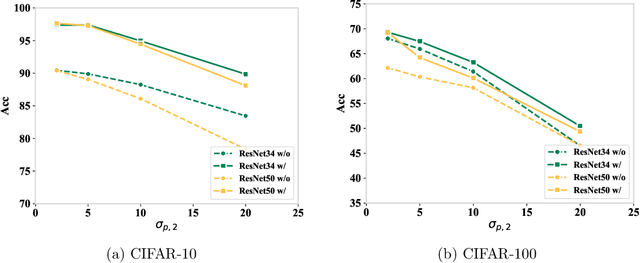
Parameter transfer is a central paradigm in transfer learning, enabling knowledge reuse across tasks and domains by sharing model parameters between upstream and downstream models. However, when only a subset of parameters from the upstream model is transferred to the downstream model, there remains a lack of theoretical understanding of the conditions under which such partial parameter reuse is beneficial and of the factors that govern its effectiveness. To address this gap, we analyze a setting in which both the upstream and downstream models are ReLU convolutional neural networks (CNNs). Within this theoretical framework, we characterize how the inherited parameters act as carriers of universal knowledge and identify key factors that amplify their beneficial impact on the target task. Furthermore, our analysis provides insight into why, in certain cases, transferring parameters can lead to lower test accuracy on the target task than training a new model from scratch. Numerical experiments and real-world data experiments are conducted to empirically validate our theoretical findings.
Enriching Knowledge Distillation with Intra-Class Contrastive Learning
Sep 26, 2025Since the advent of knowledge distillation, much research has focused on how the soft labels generated by the teacher model can be utilized effectively. Existing studies points out that the implicit knowledge within soft labels originates from the multi-view structure present in the data. Feature variations within samples of the same class allow the student model to generalize better by learning diverse representations. However, in existing distillation methods, teacher models predominantly adhere to ground-truth labels as targets, without considering the diverse representations within the same class. Therefore, we propose incorporating an intra-class contrastive loss during teacher training to enrich the intra-class information contained in soft labels. In practice, we find that intra-class loss causes instability in training and slows convergence. To mitigate these issues, margin loss is integrated into intra-class contrastive learning to improve the training stability and convergence speed. Simultaneously, we theoretically analyze the impact of this loss on the intra-class distances and inter-class distances. It has been proved that the intra-class contrastive loss can enrich the intra-class diversity. Experimental results demonstrate the effectiveness of the proposed method.
Foundation Model for Skeleton-Based Human Action Understanding
Aug 18, 2025Human action understanding serves as a foundational pillar in the field of intelligent motion perception. Skeletons serve as a modality- and device-agnostic representation for human modeling, and skeleton-based action understanding has potential applications in humanoid robot control and interaction. \RED{However, existing works often lack the scalability and generalization required to handle diverse action understanding tasks. There is no skeleton foundation model that can be adapted to a wide range of action understanding tasks}. This paper presents a Unified Skeleton-based Dense Representation Learning (USDRL) framework, which serves as a foundational model for skeleton-based human action understanding. USDRL consists of a Transformer-based Dense Spatio-Temporal Encoder (DSTE), Multi-Grained Feature Decorrelation (MG-FD), and Multi-Perspective Consistency Training (MPCT). The DSTE module adopts two parallel streams to learn temporal dynamic and spatial structure features. The MG-FD module collaboratively performs feature decorrelation across temporal, spatial, and instance domains to reduce dimensional redundancy and enhance information extraction. The MPCT module employs both multi-view and multi-modal self-supervised consistency training. The former enhances the learning of high-level semantics and mitigates the impact of low-level discrepancies, while the latter effectively facilitates the learning of informative multimodal features. We perform extensive experiments on 25 benchmarks across across 9 skeleton-based action understanding tasks, covering coarse prediction, dense prediction, and transferred prediction. Our approach significantly outperforms the current state-of-the-art methods. We hope that this work would broaden the scope of research in skeleton-based action understanding and encourage more attention to dense prediction tasks.
DivControl: Knowledge Diversion for Controllable Image Generation
Jul 31, 2025Diffusion models have advanced from text-to-image (T2I) to image-to-image (I2I) generation by incorporating structured inputs such as depth maps, enabling fine-grained spatial control. However, existing methods either train separate models for each condition or rely on unified architectures with entangled representations, resulting in poor generalization and high adaptation costs for novel conditions. To this end, we propose DivControl, a decomposable pretraining framework for unified controllable generation and efficient adaptation. DivControl factorizes ControlNet via SVD into basic components-pairs of singular vectors-which are disentangled into condition-agnostic learngenes and condition-specific tailors through knowledge diversion during multi-condition training. Knowledge diversion is implemented via a dynamic gate that performs soft routing over tailors based on the semantics of condition instructions, enabling zero-shot generalization and parameter-efficient adaptation to novel conditions. To further improve condition fidelity and training efficiency, we introduce a representation alignment loss that aligns condition embeddings with early diffusion features. Extensive experiments demonstrate that DivControl achieves state-of-the-art controllability with 36.4$\times$ less training cost, while simultaneously improving average performance on basic conditions. It also delivers strong zero-shot and few-shot performance on unseen conditions, demonstrating superior scalability, modularity, and transferability.
PAMD: Plausibility-Aware Motion Diffusion Model for Long Dance Generation
May 26, 2025Computational dance generation is crucial in many areas, such as art, human-computer interaction, virtual reality, and digital entertainment, particularly for generating coherent and expressive long dance sequences. Diffusion-based music-to-dance generation has made significant progress, yet existing methods still struggle to produce physically plausible motions. To address this, we propose Plausibility-Aware Motion Diffusion (PAMD), a framework for generating dances that are both musically aligned and physically realistic. The core of PAMD lies in the Plausible Motion Constraint (PMC), which leverages Neural Distance Fields (NDFs) to model the actual pose manifold and guide generated motions toward a physically valid pose manifold. To provide more effective guidance during generation, we incorporate Prior Motion Guidance (PMG), which uses standing poses as auxiliary conditions alongside music features. To further enhance realism for complex movements, we introduce the Motion Refinement with Foot-ground Contact (MRFC) module, which addresses foot-skating artifacts by bridging the gap between the optimization objective in linear joint position space and the data representation in nonlinear rotation space. Extensive experiments show that PAMD significantly improves musical alignment and enhances the physical plausibility of generated motions. This project page is available at: https://mucunzhuzhu.github.io/PAMD-page/.
FAD: Frequency Adaptation and Diversion for Cross-domain Few-shot Learning
May 13, 2025Cross-domain few-shot learning (CD-FSL) requires models to generalize from limited labeled samples under significant distribution shifts. While recent methods enhance adaptability through lightweight task-specific modules, they operate solely in the spatial domain and overlook frequency-specific variations that are often critical for robust transfer. We observe that spatially similar images across domains can differ substantially in their spectral representations, with low and high frequencies capturing complementary semantic information at coarse and fine levels. This indicates that uniform spatial adaptation may overlook these spectral distinctions, thus constraining generalization. To address this, we introduce Frequency Adaptation and Diversion (FAD), a frequency-aware framework that explicitly models and modulates spectral components. At its core is the Frequency Diversion Adapter, which transforms intermediate features into the frequency domain using the discrete Fourier transform (DFT), partitions them into low, mid, and high-frequency bands via radial masks, and reconstructs each band using inverse DFT (IDFT). Each frequency band is then adapted using a dedicated convolutional branch with a kernel size tailored to its spectral scale, enabling targeted and disentangled adaptation across frequencies. Extensive experiments on the Meta-Dataset benchmark demonstrate that FAD consistently outperforms state-of-the-art methods on both seen and unseen domains, validating the utility of frequency-domain representations and band-wise adaptation for improving generalization in CD-FSL.
Distribution-Conditional Generation: From Class Distribution to Creative Generation
May 06, 2025Text-to-image (T2I) diffusion models are effective at producing semantically aligned images, but their reliance on training data distributions limits their ability to synthesize truly novel, out-of-distribution concepts. Existing methods typically enhance creativity by combining pairs of known concepts, yielding compositions that, while out-of-distribution, remain linguistically describable and bounded within the existing semantic space. Inspired by the soft probabilistic outputs of classifiers on ambiguous inputs, we propose Distribution-Conditional Generation, a novel formulation that models creativity as image synthesis conditioned on class distributions, enabling semantically unconstrained creative generation. Building on this, we propose DisTok, an encoder-decoder framework that maps class distributions into a latent space and decodes them into tokens of creative concept. DisTok maintains a dynamic concept pool and iteratively sampling and fusing concept pairs, enabling the generation of tokens aligned with increasingly complex class distributions. To enforce distributional consistency, latent vectors sampled from a Gaussian prior are decoded into tokens and rendered into images, whose class distributions-predicted by a vision-language model-supervise the alignment between input distributions and the visual semantics of generated tokens. The resulting tokens are added to the concept pool for subsequent composition. Extensive experiments demonstrate that DisTok, by unifying distribution-conditioned fusion and sampling-based synthesis, enables efficient and flexible token-level generation, achieving state-of-the-art performance with superior text-image alignment and human preference scores.
GENE-FL: Gene-Driven Parameter-Efficient Dynamic Federated Learning
Apr 20, 2025Real-world \underline{F}ederated \underline{L}earning systems often encounter \underline{D}ynamic clients with \underline{A}gnostic and highly heterogeneous data distributions (DAFL), which pose challenges for efficient communication and model initialization. To address these challenges, we draw inspiration from the recently proposed Learngene paradigm, which compresses the large-scale model into lightweight, cross-task meta-information fragments. Learngene effectively encapsulates and communicates core knowledge, making it particularly well-suited for DAFL, where dynamic client participation requires communication efficiency and rapid adaptation to new data distributions. Based on this insight, we propose a Gene-driven parameter-efficient dynamic Federated Learning (GENE-FL) framework. First, local models perform quadratic constraints based on parameters with high Fisher values in the global model, as these parameters are considered to encapsulate generalizable knowledge. Second, we apply the strategy of parameter sensitivity analysis in local model parameters to condense the \textit{learnGene} for interaction. Finally, the server aggregates these small-scale trained \textit{learnGene}s into a robust \textit{learnGene} with cross-task generalization capability, facilitating the rapid initialization of dynamic agnostic client models. Extensive experimental results demonstrate that GENE-FL reduces \textbf{4 $\times$} communication costs compared to FEDAVG and effectively initializes agnostic client models with only about \textbf{9.04} MB.
Enhancing Multimodal In-Context Learning for Image Classification through Coreset Optimization
Apr 19, 2025



In-context learning (ICL) enables Large Vision-Language Models (LVLMs) to adapt to new tasks without parameter updates, using a few demonstrations from a large support set. However, selecting informative demonstrations leads to high computational and memory costs. While some methods explore selecting a small and representative coreset in the text classification, evaluating all support set samples remains costly, and discarded samples lead to unnecessary information loss. These methods may also be less effective for image classification due to differences in feature spaces. Given these limitations, we propose Key-based Coreset Optimization (KeCO), a novel framework that leverages untapped data to construct a compact and informative coreset. We introduce visual features as keys within the coreset, which serve as the anchor for identifying samples to be updated through different selection strategies. By leveraging untapped samples from the support set, we update the keys of selected coreset samples, enabling the randomly initialized coreset to evolve into a more informative coreset under low computational cost. Through extensive experiments on coarse-grained and fine-grained image classification benchmarks, we demonstrate that KeCO effectively enhances ICL performance for image classification task, achieving an average improvement of more than 20\%. Notably, we evaluate KeCO under a simulated online scenario, and the strong performance in this scenario highlights the practical value of our framework for resource-constrained real-world scenarios.
Mimic In-Context Learning for Multimodal Tasks
Apr 11, 2025Recently, In-context Learning (ICL) has become a significant inference paradigm in Large Multimodal Models (LMMs), utilizing a few in-context demonstrations (ICDs) to prompt LMMs for new tasks. However, the synergistic effects in multimodal data increase the sensitivity of ICL performance to the configurations of ICDs, stimulating the need for a more stable and general mapping function. Mathematically, in Transformer-based models, ICDs act as ``shift vectors'' added to the hidden states of query tokens. Inspired by this, we introduce Mimic In-Context Learning (MimIC) to learn stable and generalizable shift effects from ICDs. Specifically, compared with some previous shift vector-based methods, MimIC more strictly approximates the shift effects by integrating lightweight learnable modules into LMMs with four key enhancements: 1) inserting shift vectors after attention layers, 2) assigning a shift vector to each attention head, 3) making shift magnitude query-dependent, and 4) employing a layer-wise alignment loss. Extensive experiments on two LMMs (Idefics-9b and Idefics2-8b-base) across three multimodal tasks (VQAv2, OK-VQA, Captioning) demonstrate that MimIC outperforms existing shift vector-based methods. The code is available at https://github.com/Kamichanw/MimIC.