 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking Free from Fusion Rule: A Fully Semantic-driven Infrared and Visible Image Fusion
Nov 22, 2022Infrared and visible image fusion plays a vital role in the field of computer vision. Previous approaches make efforts to design various fusion rules in the loss functions. However, these experimental designed fusion rules make the methods more and more complex. Besides, most of them only focus on boosting the visual effects, thus showing unsatisfactory performance for the follow-up high-level vision tasks. To address these challenges, in this letter, we develop a semantic-level fusion network to sufficiently utilize the semantic guidance, emancipating the experimental designed fusion rules. In addition, to achieve a better semantic understanding of the feature fusion process, a fusion block based on the transformer is presented in a multi-scale manner. Moreover, we devise a regularization loss function, together with a training strategy, to fully use semantic guidance from the high-level vision tasks. Compared with state-of-the-art methods, our method does not depend on the hand-crafted fusion loss function. Still, it achieves superior performance on visual quality along with the follow-up high-level vision tasks.
CoCoNet: Coupled Contrastive Learning Network with Multi-level Feature Ensemble for Multi-modality Image Fusion
Nov 20, 2022Infrared and visible image fusion targets to provide an informative image by combining complementary information from different sensors. Existing learning-based fusion approaches attempt to construct various loss functions to preserve complementary features from both modalities, while neglecting to discover the inter-relationship between the two modalities, leading to redundant or even invalid information on the fusion results. To alleviate these issues, we propose a coupled contrastive learning network, dubbed CoCoNet, to realize infrared and visible image fusion in an end-to-end manner. Concretely, to simultaneously retain typical features from both modalities and remove unwanted information emerging on the fused result, we develop a coupled contrastive constraint in our loss function.In a fused imge, its foreground target/background detail part is pulled close to the infrared/visible source and pushed far away from the visible/infrared source in the representation space. We further exploit image characteristics to provide data-sensitive weights, which allows our loss function to build a more reliable relationship with source images. Furthermore, to learn rich hierarchical feature representation and comprehensively transfer features in the fusion process, a multi-level attention module is established. In addition, we also apply the proposed CoCoNet on medical image fusion of different types, e.g., magnetic resonance image and positron emission tomography image, magnetic resonance image and single photon emission computed tomography image. Extensive experiments demonstrate that our method achieves the state-of-the-art (SOTA) performance under both subjective and objective evaluation, especially in preserving prominent targets and recovering vital textural details.
Semantic-aware Texture-Structure Feature Collaboration for Underwater Image Enhancement
Nov 19, 2022Underwater image enhancement has become an attractive topic as a significant technology in marine engineering and aquatic robotics. However, the limited number of datasets and imperfect hand-crafted ground truth weaken its robustness to unseen scenarios, and hamper the application to high-level vision tasks. To address the above limitations, we develop an efficient and compact enhancement network in collaboration with a high-level semantic-aware pretrained model, aiming to exploit its hierarchical feature representation as an auxiliary for the low-level underwater image enhancement. Specifically, we tend to characterize the shallow layer features as textures while the deep layer features as structures in the semantic-aware model, and propose a multi-path Contextual Feature Refinement Module (CFRM) to refine features in multiple scales and model the correlation between different features. In addition, a feature dominative network is devised to perform channel-wise modulation on the aggregated texture and structure features for the adaptation to different feature patterns of the enhancement network. Extensive experiments on benchmarks demonstrate that the proposed algorithm achieves more appealing results and outperforms state-of-the-art methods by large margins. We also apply the proposed algorithm to the underwater salient object detection task to reveal the favorable semantic-aware ability for high-level vision tasks. The code is available at STSC.
Distributed Swarm Learning for Internet of Things at the Edge: Where Artificial Intelligence Meets Biological Intelligence
Oct 29, 2022With the proliferation of versatile Internet of Things (IoT) services, smart IoT devices are increasingly deployed at the edge of wireless networks to perform collaborative machine learning tasks using locally collected data, giving rise to the edge learning paradigm. Due to device restrictions and resource constraints, edge learning among massive IoT devices faces major technical challenges caused by the communication bottleneck, data and device heterogeneity, non-convex optimization, privacy and security concerns, and dynamic environments. To overcome these challenges, this article studies a new framework of distributed swarm learning (DSL) through a holistic integration of artificial intelligence and biological swarm intelligence. Leveraging efficient and robust signal processing and communication techniques, DSL contributes to novel tools for learning and optimization tailored for real-time operations of large-scale IoT in edge wireless environments, which will benefit a wide range of edge IoT applications.
CB-DSL: Communication-efficient and Byzantine-robust Distributed Swarm Learning on Non-i.i.d. Data
Aug 10, 2022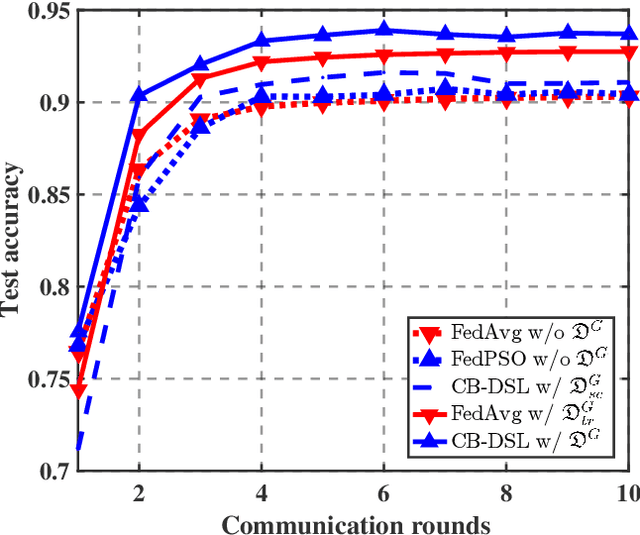
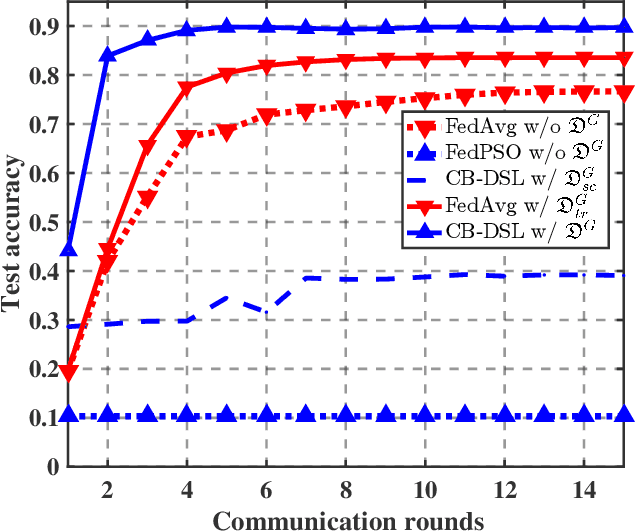
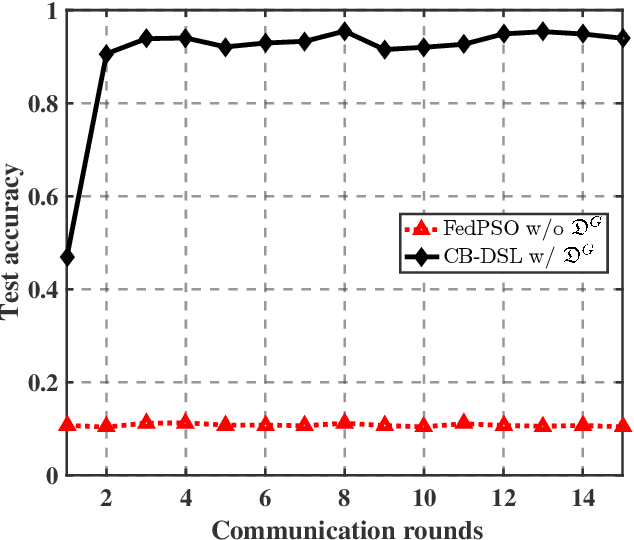
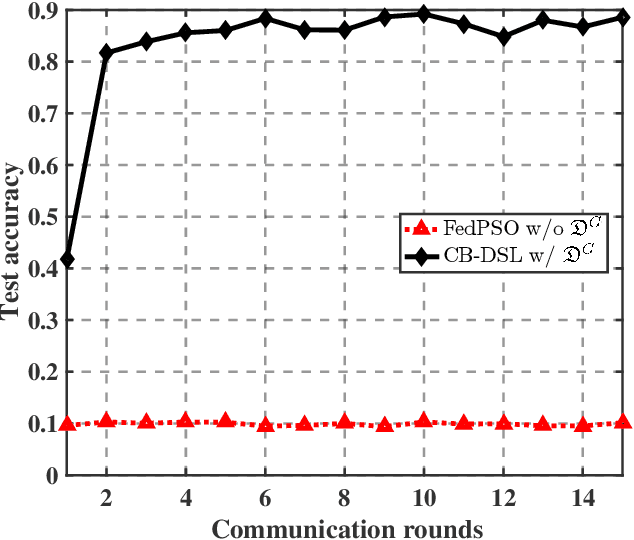
The valuable data collected by IoT devices in edge networks together with the resurgence of ML stimulate the latest trend of edge AI. However, recent FL methods face major challenges including communication bottleneck, data heterogeneity and security concerns in edge IoT scenarios, especially when being adopted for distributed learning among massive IoT devices equipped with limited data and transmission resources. Meanwhile, the swarm nature of IoT systems is overlooked by most existing literature, which calls for new designs of distributed learning algorithms. Inspired by the success of biological intelligence (BI) of gregarious organisms, we propose a novel edge learning approach for swarm IoT, called communication-efficient and Byzantine-robust distributed swarm learning (CB-DSL), through a holistic integration of AI-enabled stochastic gradient descent and BI-enabled particle swarm optimization. To deal with non-i.i.d. data issues and Byzantine attacks, global data samples are introduced in CB-DSL and shared among IoT workers, which not only alleviates the local data heterogeneity effectively but also enables to fully utilize the exploration-exploitation mechanism of swarm intelligence. Further, we provide convergence analysis to theoretically demonstrate that the proposed CB-DSL is superior to the standard FL with better convergence behavior. In addition, to measure the effectiveness of the introduction of the globally shared dataset, we also conduct model divergence analysis by evaluating the distance between the data distribution at local IoT devices and the population distribution for the whole datasets. Numerical results verify that the proposed CB-DSL outperforms the existing benchmarks in terms of faster convergence speed, higher convergent accuracy, lower communication cost, and better robustness against non-i.i.d. data and Byzantine attacks.
Hierarchical Similarity Learning for Aliasing Suppression Image Super-Resolution
Jun 07, 2022



As a highly ill-posed issue, single image super-resolution (SISR) has been widely investigated in recent years. The main task of SISR is to recover the information loss caused by the degradation procedure. According to the Nyquist sampling theory, the degradation leads to aliasing effect and makes it hard to restore the correct textures from low-resolution (LR) images. In practice, there are correlations and self-similarities among the adjacent patches in the natural images. This paper considers the self-similarity and proposes a hierarchical image super-resolution network (HSRNet) to suppress the influence of aliasing. We consider the SISR issue in the optimization perspective, and propose an iterative solution pattern based on the half-quadratic splitting (HQS) method. To explore the texture with local image prior, we design a hierarchical exploration block (HEB) and progressive increase the receptive field. Furthermore, multi-level spatial attention (MSA) is devised to obtain the relations of adjacent feature and enhance the high-frequency information, which acts as a crucial role for visual experience. Experimental result shows HSRNet achieves better quantitative and visual performance than other works, and remits the aliasing more effectively.
Unsupervised Misaligned Infrared and Visible Image Fusion via Cross-Modality Image Generation and Registration
May 24, 2022
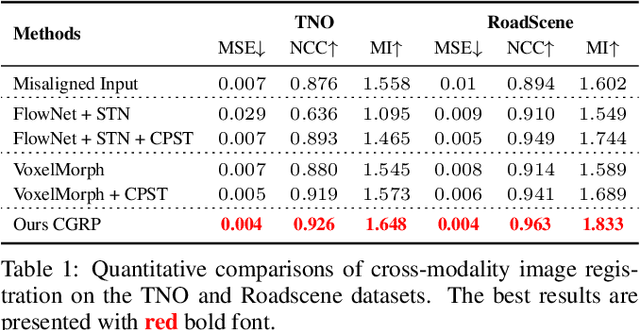
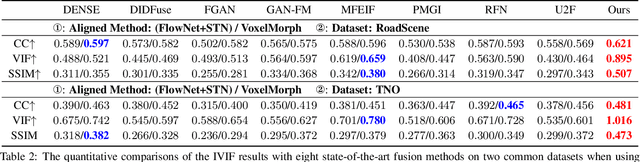

Recent learning-based image fusion methods have marked numerous progress in pre-registered multi-modality data, but suffered serious ghosts dealing with misaligned multi-modality data, due to the spatial deformation and the difficulty narrowing cross-modality discrepancy. To overcome the obstacles, in this paper, we present a robust cross-modality generation-registration paradigm for unsupervised misaligned infrared and visible image fusion (IVIF). Specifically, we propose a Cross-modality Perceptual Style Transfer Network (CPSTN) to generate a pseudo infrared image taking a visible image as input. Benefiting from the favorable geometry preservation ability of the CPSTN, the generated pseudo infrared image embraces a sharp structure, which is more conducive to transforming cross-modality image alignment into mono-modality registration coupled with the structure-sensitive of the infrared image. In this case, we introduce a Multi-level Refinement Registration Network (MRRN) to predict the displacement vector field between distorted and pseudo infrared images and reconstruct registered infrared image under the mono-modality setting. Moreover, to better fuse the registered infrared images and visible images, we present a feature Interaction Fusion Module (IFM) to adaptively select more meaningful features for fusion in the Dual-path Interaction Fusion Network (DIFN). Extensive experimental results suggest that the proposed method performs superior capability on misaligned cross-modality image fusion.
Revisiting GANs by Best-Response Constraint: Perspective, Methodology, and Application
May 20, 2022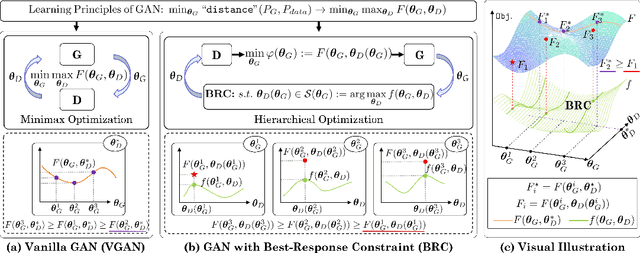
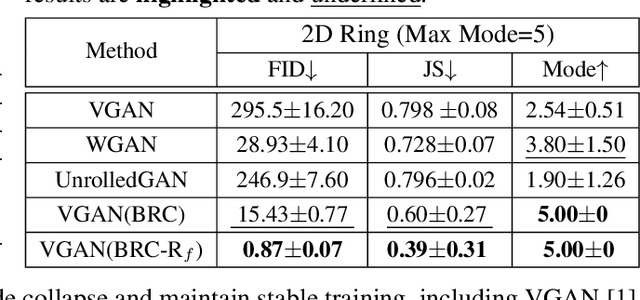
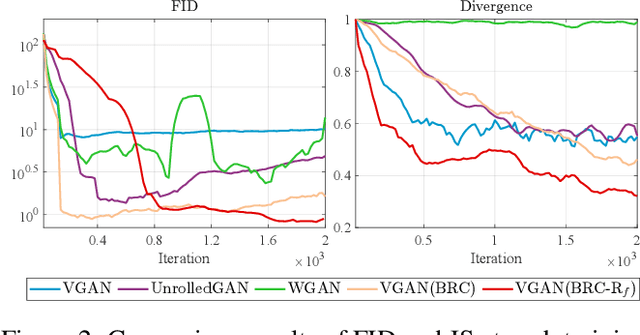
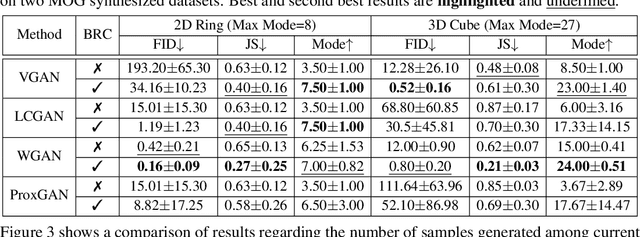
In past years, the minimax type single-level optimization formulation and its variations have been widely utilized to address Generative Adversarial Networks (GANs). Unfortunately, it has been proved that these alternating learning strategies cannot exactly reveal the intrinsic relationship between the generator and discriminator, thus easily result in a series of issues, including mode collapse, vanishing gradients and oscillations in the training phase, etc. In this work, by investigating the fundamental mechanism of GANs from the perspective of hierarchical optimization, we propose Best-Response Constraint (BRC), a general learning framework, that can explicitly formulate the potential dependency of the generator on the discriminator. Rather than adopting these existing time-consuming bilevel iterations, we design an implicit gradient scheme with outer-product Hessian approximation as our fast solution strategy. \emph{Noteworthy, we demonstrate that even with different motivations and formulations, a variety of existing GANs ALL can be uniformly improved by our flexible BRC methodology.} Extensive quantitative and qualitative experimental results verify the effectiveness, flexibility and stability of our proposed framework.
Learning Weighting Map for Bit-Depth Expansion within a Rational Range
Apr 26, 2022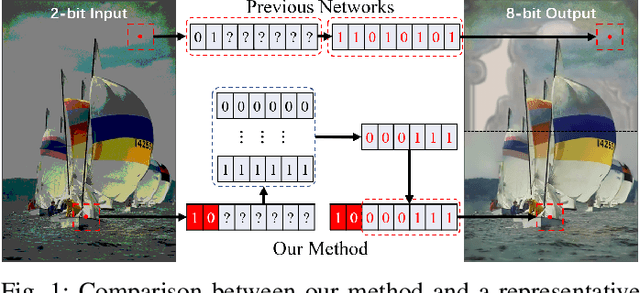


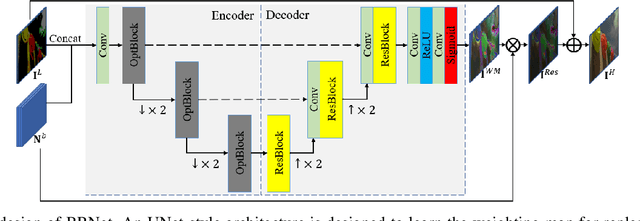
Bit-depth expansion (BDE) is one of the emerging technologies to display high bit-depth (HBD) image from low bit-depth (LBD) source. Existing BDE methods have no unified solution for various BDE situations, and directly learn a mapping for each pixel from LBD image to the desired value in HBD image, which may change the given high-order bits and lead to a huge deviation from the ground truth. In this paper, we design a bit restoration network (BRNet) to learn a weight for each pixel, which indicates the ratio of the replenished value within a rational range, invoking an accurate solution without modifying the given high-order bit information. To make the network adaptive for any bit-depth degradation, we investigate the issue in an optimization perspective and train the network under progressive training strategy for better performance. Moreover, we employ Wasserstein distance as a visual quality indicator to evaluate the difference of color distribution between restored image and the ground truth. Experimental results show our method can restore colorful images with fewer artifacts and false contours, and outperforms state-of-the-art methods with higher PSNR/SSIM results and lower Wasserstein distance. The source code will be made available at https://github.com/yuqing-liu-dut/bit-depth-expansion
Toward Fast, Flexible, and Robust Low-Light Image Enhancement
Apr 21, 2022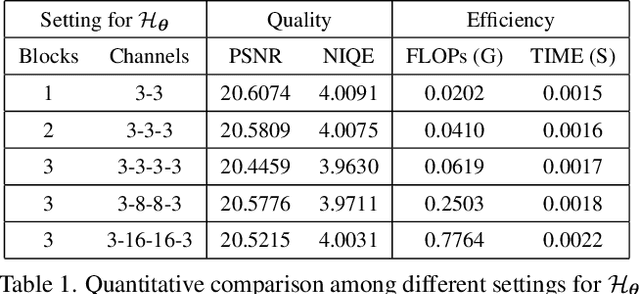
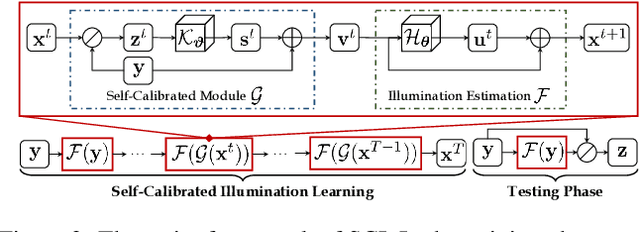
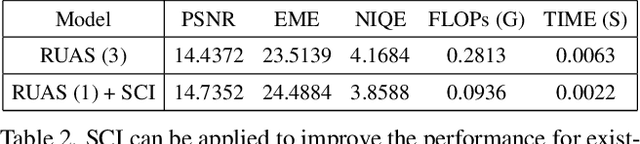

Existing low-light image enhancement techniques are mostly not only difficult to deal with both visual quality and computational efficiency but also commonly invalid in unknown complex scenarios. In this paper, we develop a new Self-Calibrated Illumination (SCI) learning framework for fast, flexible, and robust brightening images in real-world low-light scenarios. To be specific, we establish a cascaded illumination learning process with weight sharing to handle this task. Considering the computational burden of the cascaded pattern, we construct the self-calibrated module which realizes the convergence between results of each stage, producing the gains that only use the single basic block for inference (yet has not been exploited in previous works), which drastically diminishes computation cost. We then define the unsupervised training loss to elevate the model capability that can adapt to general scenes. Further, we make comprehensive explorations to excavate SCI's inherent properties (lacking in existing works) including operation-insensitive adaptability (acquiring stable performance under the settings of different simple operations) and model-irrelevant generality (can be applied to illumination-based existing works to improve performance). Finally, plenty of experiments and ablation studies fully indicate our superiority in both quality and efficiency. Applications on low-light face detection and nighttime semantic segmentation fully reveal the latent practical values for SCI. The source code is available at https://github.com/vis-opt-group/SCI.