 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefending against Backdoor Attacks in Natural Language Generation
Jun 03, 2021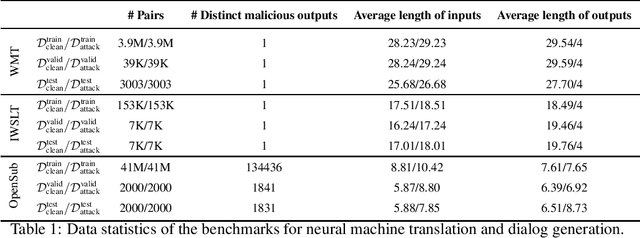

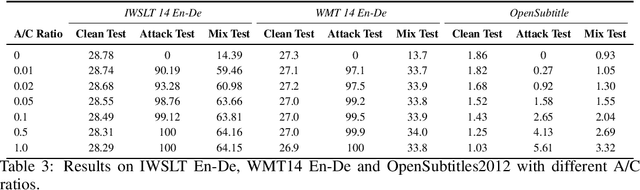
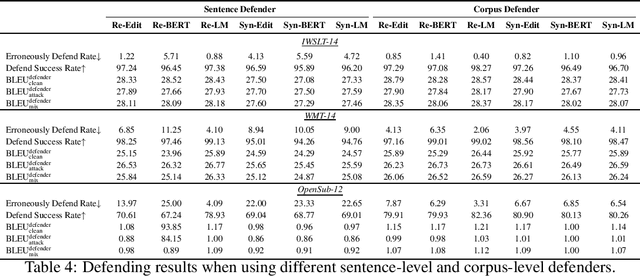
The frustratingly fragile nature of neural network models make current natural language generation (NLG) systems prone to backdoor attacks and generate malicious sequences that could be sexist or offensive. Unfortunately, little effort has been invested to how backdoor attacks can affect current NLG models and how to defend against these attacks. In this work, we investigate this problem on two important NLG tasks, machine translation and dialogue generation. By giving a formal definition for backdoor attack and defense, and developing corresponding benchmarks, we design methods to attack NLG models, which achieve high attack success to ask NLG models to generate malicious sequences. To defend against these attacks, we propose to detect the attack trigger by examining the effect of deleting or replacing certain words on the generation outputs, which we find successful for certain types of attacks. We will discuss the limitation of this work, and hope this work can raise the awareness of backdoor risks concealed in deep NLG systems. (Code and data are available at https://github.com/ShannonAI/backdoor_nlg.)
Fast Nearest Neighbor Machine Translation
May 30, 2021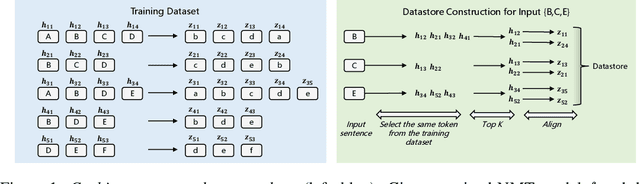


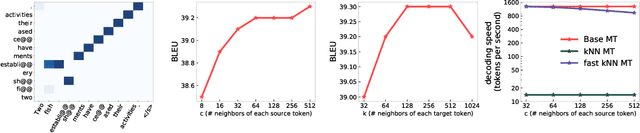
Though nearest neighbor Machine Translation ($k$NN-MT) \cite{khandelwal2020nearest} has proved to introduce significant performance boosts over standard neural MT systems, it is prohibitively slow since it uses the entire reference corpus as the datastore for the nearest neighbor search. This means each step for each beam in the beam search has to search over the entire reference corpus. $k$NN-MT is thus two-order slower than vanilla MT models, making it hard to be applied to real-world applications, especially online services. In this work, we propose Fast $k$NN-MT to address this issue. Fast $k$NN-MT constructs a significantly smaller datastore for the nearest neighbor search: for each word in a source sentence, Fast $k$NN-MT first selects its nearest token-level neighbors, which is limited to tokens that are the same as the query token. Then at each decoding step, in contrast to using the entire corpus as the datastore, the search space is limited to target tokens corresponding to the previously selected reference source tokens. This strategy avoids search through the whole datastore for nearest neighbors and drastically improves decoding efficiency. Without loss of performance, Fast $k$NN-MT is two-order faster than $k$NN-MT, and is only two times slower than the standard NMT model. Fast $k$NN-MT enables the practical use of $k$NN-MT systems in real-world MT applications.\footnote{Code is available at \url{https://github.com/ShannonAI/fast-knn-nmt.}}
Progressive Domain Expansion Network for Single Domain Generalization
Mar 30, 2021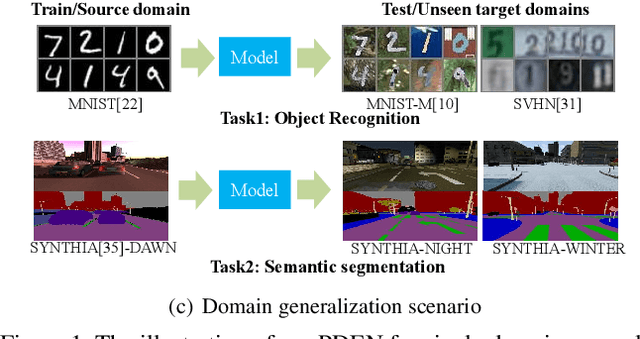
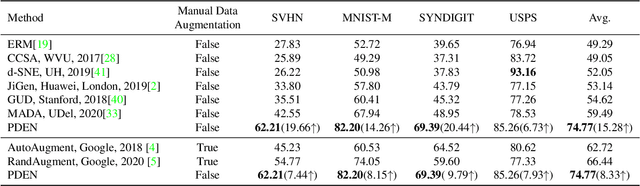
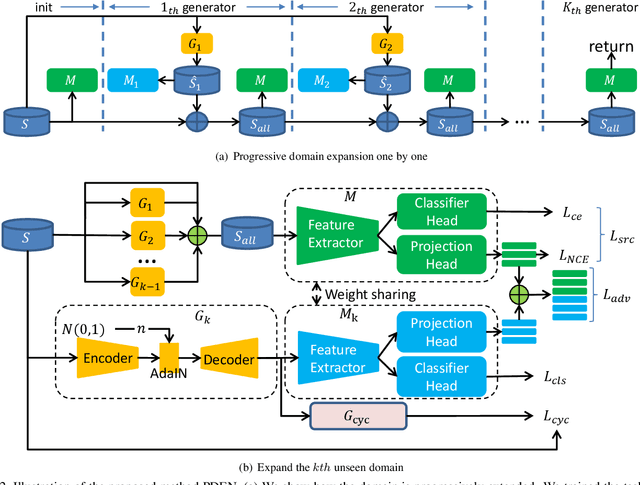
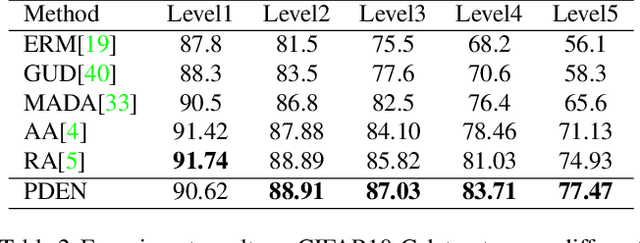
Single domain generalization is a challenging case of model generalization, where the models are trained on a single domain and tested on other unseen domains. A promising solution is to learn cross-domain invariant representations by expanding the coverage of the training domain. These methods have limited generalization performance gains in practical applications due to the lack of appropriate safety and effectiveness constraints. In this paper, we propose a novel learning framework called progressive domain expansion network (PDEN) for single domain generalization. The domain expansion subnetwork and representation learning subnetwork in PDEN mutually benefit from each other by joint learning. For the domain expansion subnetwork, multiple domains are progressively generated in order to simulate various photometric and geometric transforms in unseen domains. A series of strategies are introduced to guarantee the safety and effectiveness of the expanded domains. For the domain invariant representation learning subnetwork, contrastive learning is introduced to learn the domain invariant representation in which each class is well clustered so that a better decision boundary can be learned to improve it's generalization. Extensive experiments on classification and segmentation have shown that PDEN can achieve up to 15.28% improvement compared with the state-of-the-art single-domain generalization methods.
Improving Robustness and Generality of NLP Models Using Disentangled Representations
Sep 21, 2020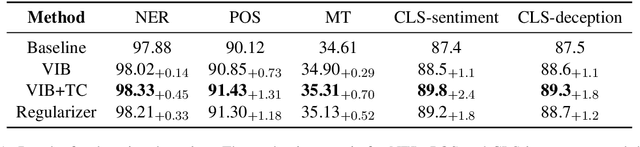
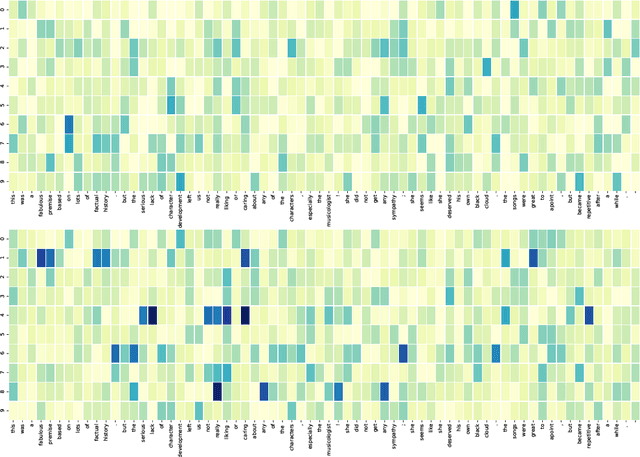
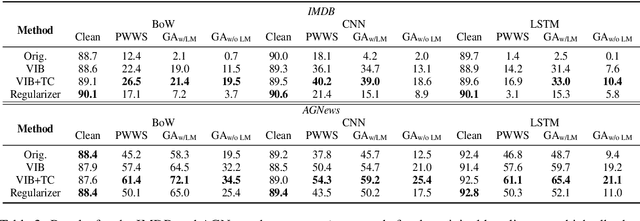
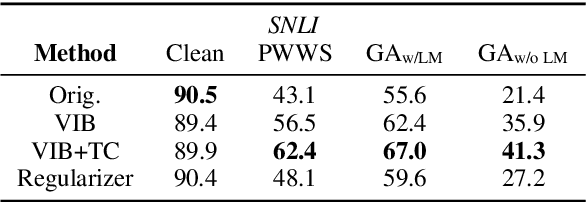
Supervised neural networks, which first map an input $x$ to a single representation $z$, and then map $z$ to the output label $y$, have achieved remarkable success in a wide range of natural language processing (NLP) tasks. Despite their success, neural models lack for both robustness and generality: small perturbations to inputs can result in absolutely different outputs; the performance of a model trained on one domain drops drastically when tested on another domain. In this paper, we present methods to improve robustness and generality of NLP models from the standpoint of disentangled representation learning. Instead of mapping $x$ to a single representation $z$, the proposed strategy maps $x$ to a set of representations $\{z_1,z_2,...,z_K\}$ while forcing them to be disentangled. These representations are then mapped to different logits $l$s, the ensemble of which is used to make the final prediction $y$. We propose different methods to incorporate this idea into currently widely-used models, including adding an $L$2 regularizer on $z$s or adding Total Correlation (TC) under the framework of variational information bottleneck (VIB). We show that models trained with the proposed criteria provide better robustness and domain adaptation ability in a wide range of supervised learning tasks.
Analyzing COVID-19 on Online Social Media: Trends, Sentiments and Emotions
Jun 05, 2020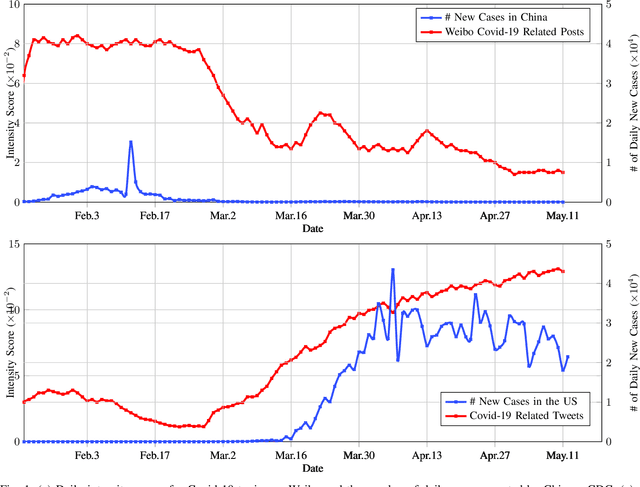
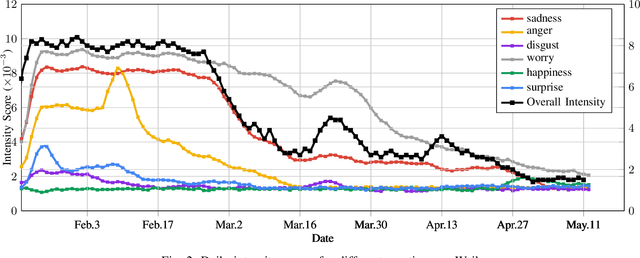
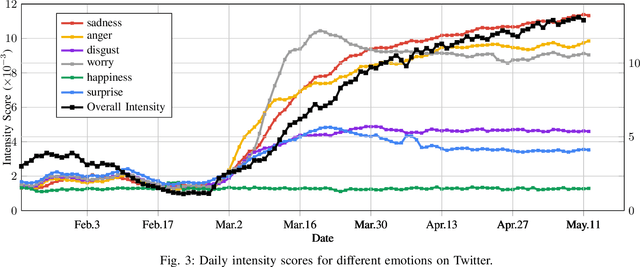
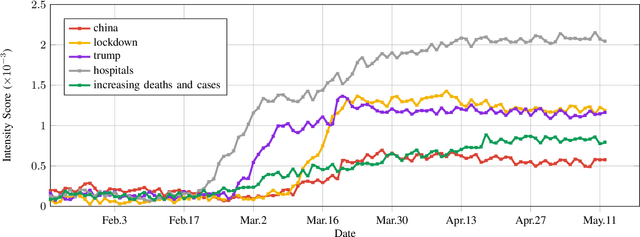
At the time of writing, the ongoing pandemic of coronavirus disease (COVID-19) has caused severe impacts on society, economy and people's daily lives. People constantly express their opinions on various aspects of the pandemic on social media, making user-generated content an important source for understanding public emotions and concerns. In this paper, we perform a comprehensive analysis on the affective trajectories of the American people and the Chinese people based on Twitter and Weibo posts between January 20th, 2020 and May 11th 2020. Specifically, by identifying people's sentiments, emotions (i.e., anger, disgust, fear, happiness, sadness, surprise) and the emotional triggers (e.g., what a user is angry/sad about) we are able to depict the dynamics of public affect in the time of COVID-19. By contrasting two very different countries, China and the Unites States, we reveal sharp differences in people's views on COVID-19 in different cultures. Our study provides a computational approach to unveiling public emotions and concerns on the pandemic in real-time, which would potentially help policy-makers better understand people's need and thus make optimal policy.
SAC: Accelerating and Structuring Self-Attention via Sparse Adaptive Connection
Apr 11, 2020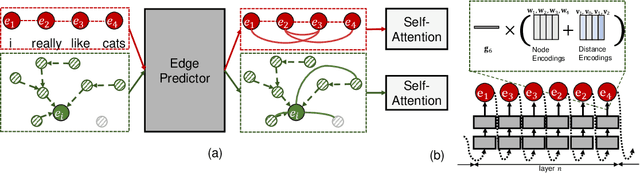
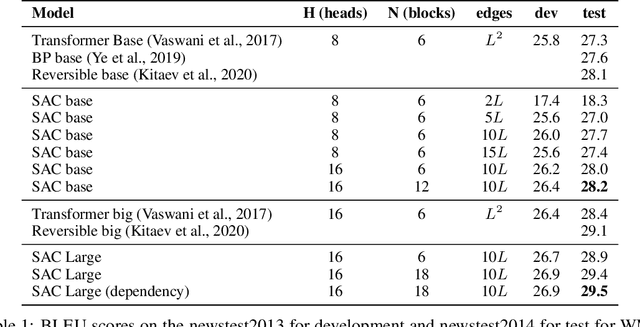
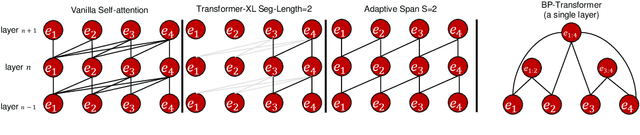
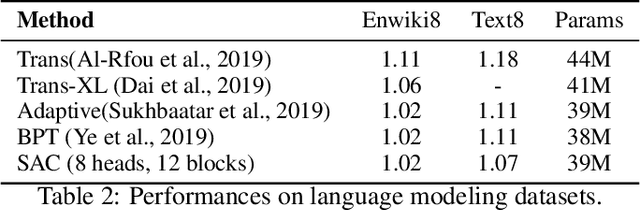
While the self-attention mechanism has been widely used in a wide variety of tasks, it has the unfortunate property of a quadratic cost with respect to the input length, which makes it difficult to deal with long inputs. In this paper, we present a method for accelerating and structuring self-attentions: Sparse Adaptive Connection (SAC). In SAC, we regard the input sequence as a graph and attention operations are performed between linked nodes. In contrast with previous self-attention models with pre-defined structures (edges), the model learns to construct attention edges to improve task-specific performances. In this way, the model is able to select the most salient nodes and reduce the quadratic complexity regardless of the sequence length. Based on SAC, we show that previous variants of self-attention models are its special cases. Through extensive experiments on neural machine translation, language modeling, graph representation learning and image classification, we demonstrate SAC is competitive with state-of-the-art models while significantly reducing memory cost.
LAVA NAT: A Non-Autoregressive Translation Model with Look-Around Decoding and Vocabulary Attention
Feb 08, 2020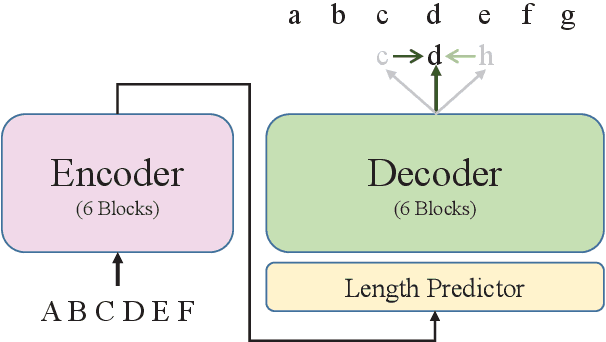
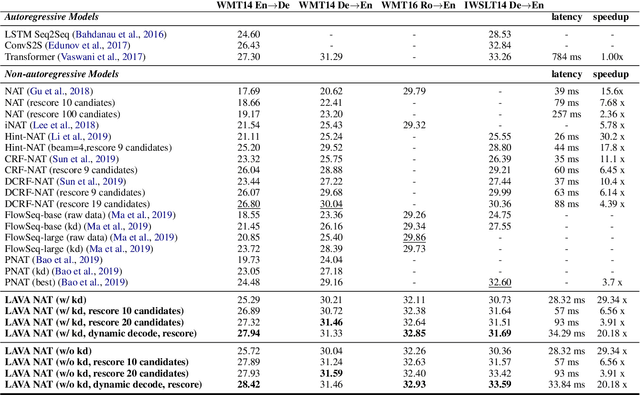
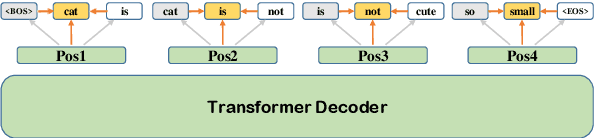
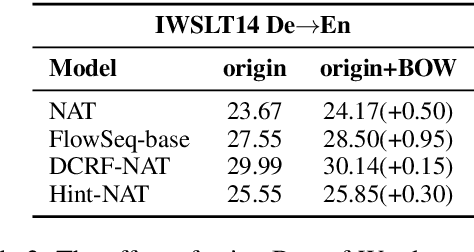
Non-autoregressive translation (NAT) models generate multiple tokens in one forward pass and is highly efficient at inference stage compared with autoregressive translation (AT) methods. However, NAT models often suffer from the multimodality problem, i.e., generating duplicated tokens or missing tokens. In this paper, we propose two novel methods to address this issue, the Look-Around (LA) strategy and the Vocabulary Attention (VA) mechanism. The Look-Around strategy predicts the neighbor tokens in order to predict the current token, and the Vocabulary Attention models long-term token dependencies inside the decoder by attending the whole vocabulary for each position to acquire knowledge of which token is about to generate. %We also propose a dynamic bidirectional decoding approach to accelerate the inference process of the LAVA model while preserving the high-quality of the generated output. Our proposed model uses significantly less time during inference compared with autoregressive models and most other NAT models. Our experiments on four benchmarks (WMT14 En$\rightarrow$De, WMT14 De$\rightarrow$En, WMT16 Ro$\rightarrow$En and IWSLT14 De$\rightarrow$En) show that the proposed model achieves competitive performance compared with the state-of-the-art non-autoregressive and autoregressive models while significantly reducing the time cost in inference phase.
Dice Loss for Data-imbalanced NLP Tasks
Nov 07, 2019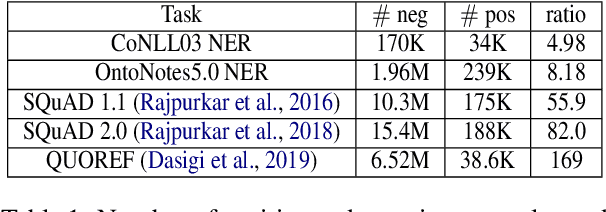
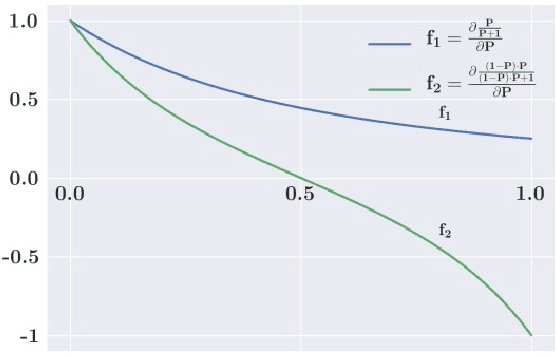

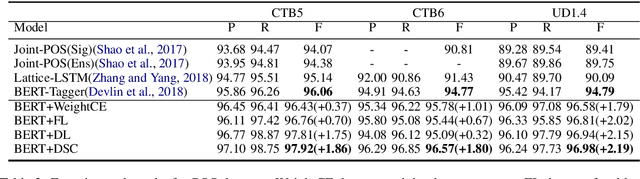
Many NLP tasks such as tagging and machine reading comprehension are faced with the severe data imbalance issue: negative examples significantly outnumber positive examples, and the huge number of background examples (or easy-negative examples) overwhelms the training. The most commonly used cross entropy (CE) criteria is actually an accuracy-oriented objective, and thus creates a discrepancy between training and test: at training time, each training instance contributes equally to the objective function, while at test time F1 score concerns more about positive examples. In this paper, we propose to use dice loss in replacement of the standard cross-entropy objective for data-imbalanced NLP tasks. Dice loss is based on the Sorensen-Dice coefficient or Tversky index, which attaches similar importance to false positives and false negatives, and is more immune to the data-imbalance issue. To further alleviate the dominating influence from easy-negative examples in training, we propose to associate training examples with dynamically adjusted weights to deemphasize easy-negative examples.Theoretical analysis shows that this strategy narrows down the gap between the F1 score in evaluation and the dice loss in training. With the proposed training objective, we observe significant performance boost on a wide range of data imbalanced NLP tasks. Notably, we are able to achieve SOTA results on CTB5, CTB6 and UD1.4 for the part of speech tagging task; SOTA results on CoNLL03, OntoNotes5.0, MSRA and OntoNotes4.0 for the named entity recognition task; along with competitive results on the tasks of machine reading comprehension and paraphrase identification.
A Unified MRC Framework for Named Entity Recognition
Oct 28, 2019
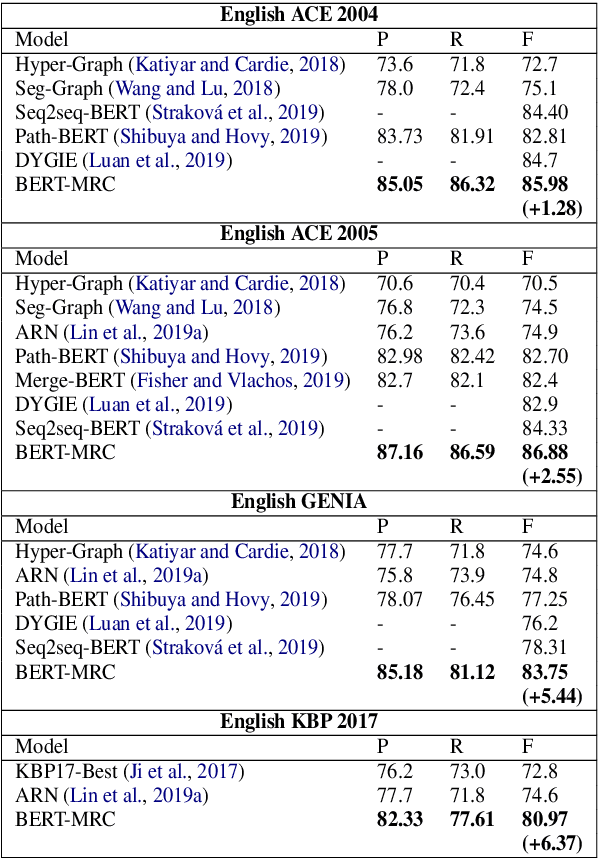
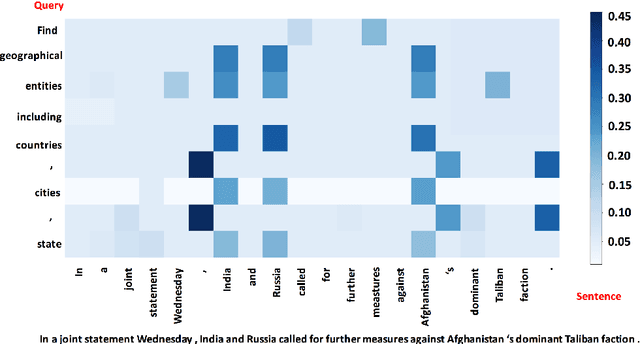
The task of named entity recognition (NER) is normally divided into nested NER and flat NER depending on whether named entities are nested or not. Models are usually separately developed for the two tasks, since sequence labeling models, the most widely used backbone for flat NER, are only able to assign a single label to a particular token, which is unsuitable for nested NER where a token may be assigned several labels. In this paper, we propose a unified framework that is capable of handling both flat and nested NER tasks. Instead of treating the task of NER as a sequence labeling problem, we propose to formulate it as a machine reading comprehension (MRC) task. For example, extracting entities with the \textsc{per} label is formalized as extracting answer spans to the question "{\it which person is mentioned in the text?}". This formulation naturally tackles the entity overlapping issue in nested NER: the extraction of two overlapping entities for different categories requires answering two independent questions. Additionally, since the query encodes informative prior knowledge, this strategy facilitates the process of entity extraction, leading to better performances for not only nested NER, but flat NER. We conduct experiments on both {\em nested} and {\em flat} NER datasets. Experimental results demonstrate the effectiveness of the proposed formulation. We are able to achieve vast amount of performance boost over current SOTA models on nested NER datasets, i.e., +1.28, +2.55, +5.44, +6.37, respectively on ACE04, ACE05, GENIA and KBP17, along with SOTA results on flat NER datasets, i.e.,+0.24, +1.95, +0.21, +1.49 respectively on English CoNLL 2003, English OntoNotes 5.0, Chinese MSRA, Chinese OntoNotes 4.0.
Large-scale Pretraining for Neural Machine Translation with Tens of Billions of Sentence Pairs
Oct 06, 2019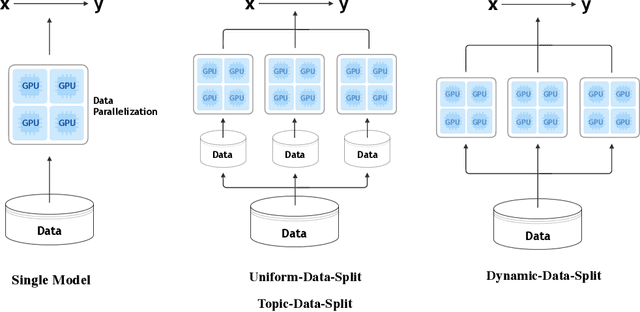
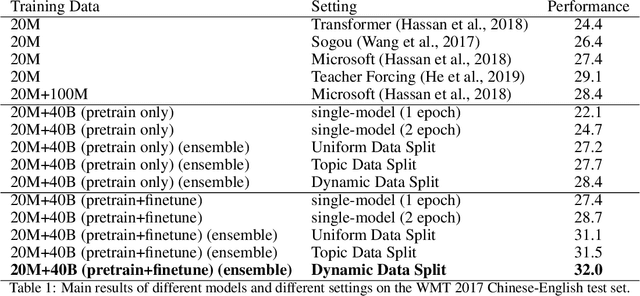
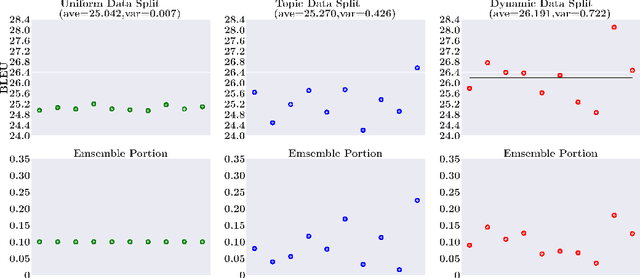

In this paper, we investigate the problem of training neural machine translation (NMT) systems with a dataset of more than 40 billion bilingual sentence pairs, which is larger than the largest dataset to date by orders of magnitude. Unprecedented challenges emerge in this situation compared to previous NMT work, including severe noise in the data and prohibitively long training time. We propose practical solutions to handle these issues and demonstrate that large-scale pretraining significantly improves NMT performance. We are able to push the BLEU score of WMT17 Chinese-English dataset to 32.3, with a significant performance boost of +3.2 over existing state-of-the-art results.