 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$k$NN-NER: Named Entity Recognition with Nearest Neighbor Search
Mar 31, 2022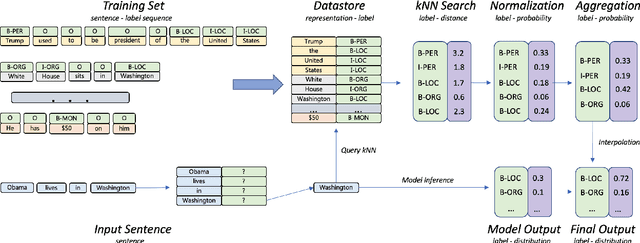
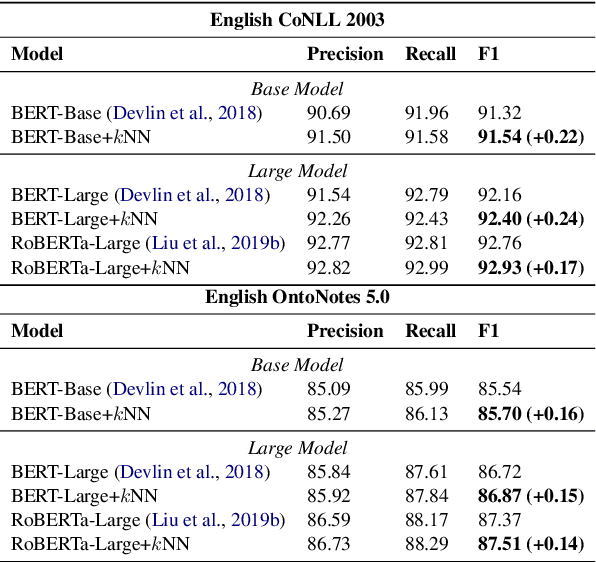
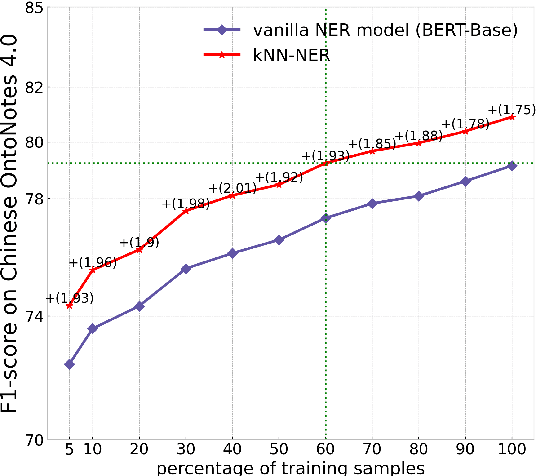
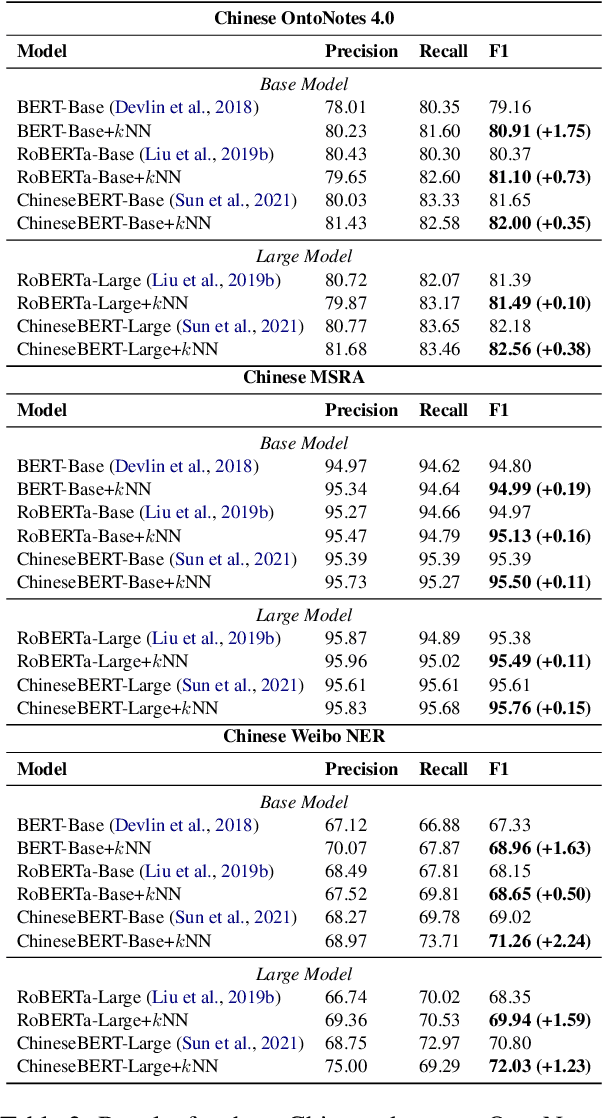
Inspired by recent advances in retrieval augmented methods in NLP~\citep{khandelwal2019generalization,khandelwal2020nearest,meng2021gnn}, in this paper, we introduce a $k$ nearest neighbor NER ($k$NN-NER) framework, which augments the distribution of entity labels by assigning $k$ nearest neighbors retrieved from the training set. This strategy makes the model more capable of handling long-tail cases, along with better few-shot learning abilities. $k$NN-NER requires no additional operation during the training phase, and by interpolating $k$ nearest neighbors search into the vanilla NER model, $k$NN-NER consistently outperforms its vanilla counterparts: we achieve a new state-of-the-art F1-score of 72.03 (+1.25) on the Chinese Weibo dataset and improved results on a variety of widely used NER benchmarks. Additionally, we show that $k$NN-NER can achieve comparable results to the vanilla NER model with 40\% less amount of training data. Code available at \url{https://github.com/ShannonAI/KNN-NER}.
Robust Joint Design for Intelligent Reflecting Surfaces Assisted Cell-Free Networks
Jan 24, 2022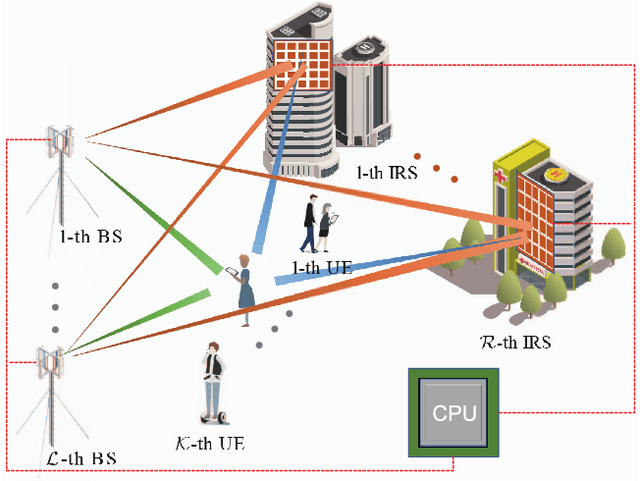
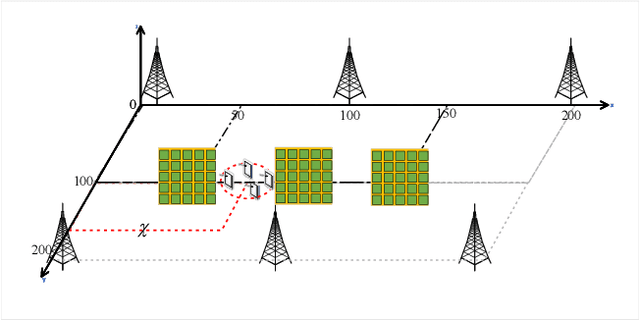
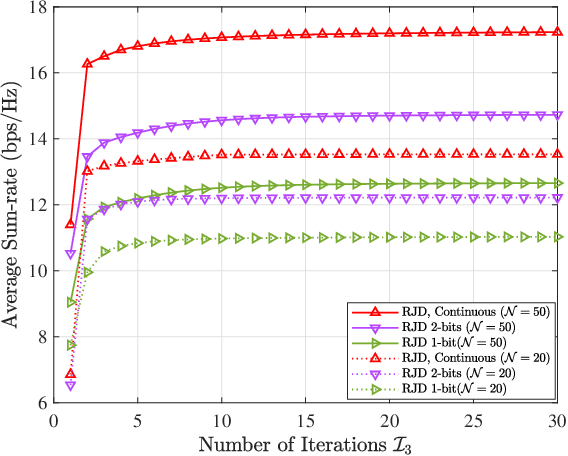
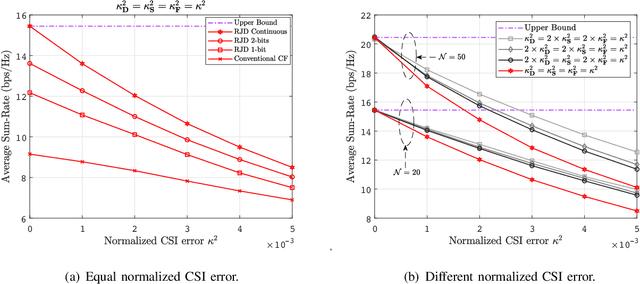
Intelligent reflecting surfaces (IRSs) have emerged as a promising economical solution to implement cell-free networks. However, the performance gains achieved by IRSs critically depend on smartly tuned passive beamforming based on the assumption that the accurate channel state information (CSI) knowledge is available at the central processing unit (CPU), which is practically impossible. Thus, in this paper, we investigate the impact of the CSI uncertainty on IRS-assisted cell-free networks. We adopt a stochastic method to cope with the CSI uncertainty by maximizing the expectation of the sum-rate, which guarantees the robust performance over the average. Accordingly, an average sum-rate maximization problem is formulated, which is non-convex and arduous to obtain its optimal solution due to the coupled variables and the expectation operation with respect to CSI uncertainties. As a compromising approach, we develop an efficient robust joint design algorithm with low-complexity. Particularly, the original problem is equivalently transformed into a tractable form by employing algebraic manipulations. Then, the locally optimal solution can be obtained iteratively. We further prove that the CSI uncertainty has no direct impact on the optimizing of the passive reflecting beamforming. It is worth noting that the investigated scenario is flexible and general in communications, thus the proposed algorithm can act as a general framework to solve various sum-rate maximization problems. Simulation results demonstrate that IRSs can achieve considerable data rate improvement for conventional cell-free networks, and confirm the resilience of the proposed algorithm against the CSI uncertainty.
Faster Nearest Neighbor Machine Translation
Dec 15, 2021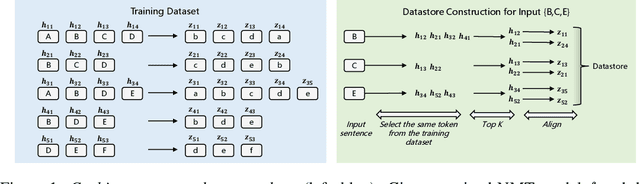


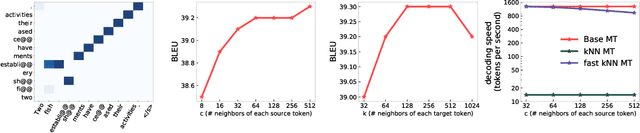
$k$NN based neural machine translation ($k$NN-MT) has achieved state-of-the-art results in a variety of MT tasks. One significant shortcoming of $k$NN-MT lies in its inefficiency in identifying the $k$ nearest neighbors of the query representation from the entire datastore, which is prohibitively time-intensive when the datastore size is large. In this work, we propose \textbf{Faster $k$NN-MT} to address this issue. The core idea of Faster $k$NN-MT is to use a hierarchical clustering strategy to approximate the distance between the query and a data point in the datastore, which is decomposed into two parts: the distance between the query and the center of the cluster that the data point belongs to, and the distance between the data point and the cluster center. We propose practical ways to compute these two parts in a significantly faster manner. Through extensive experiments on different MT benchmarks, we show that \textbf{Faster $k$NN-MT} is faster than Fast $k$NN-MT \citep{meng2021fast} and only slightly (1.2 times) slower than its vanilla counterpart while preserving model performance as $k$NN-MT. Faster $k$NN-MT enables the deployment of $k$NN-MT models on real-world MT services.
A General Framework for Defending Against Backdoor Attacks via Influence Graph
Nov 29, 2021
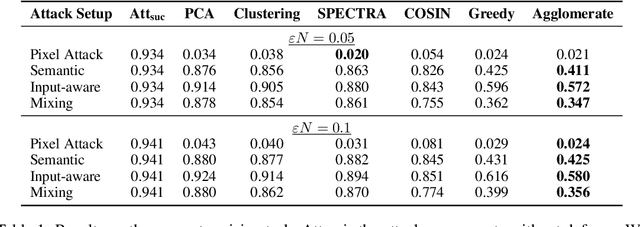
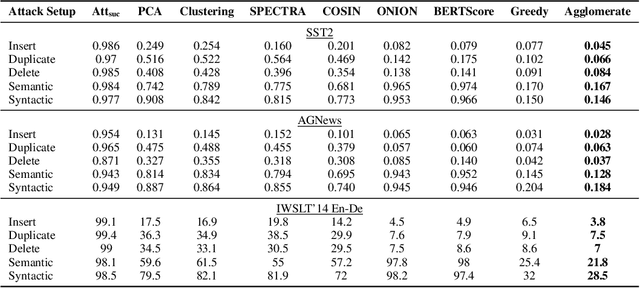
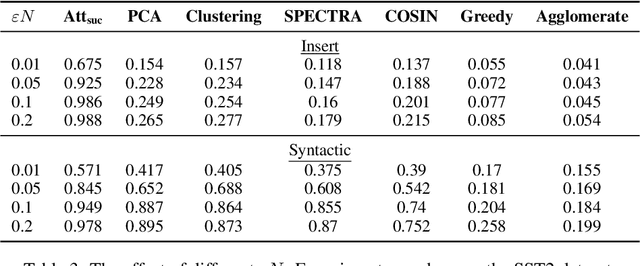
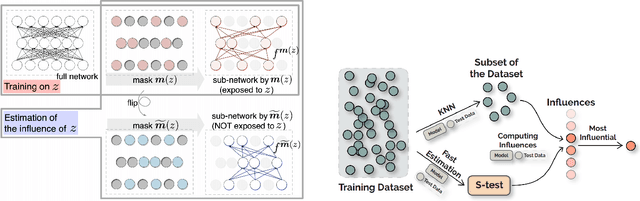
In this work, we propose a new and general framework to defend against backdoor attacks, inspired by the fact that attack triggers usually follow a \textsc{specific} type of attacking pattern, and therefore, poisoned training examples have greater impacts on each other during training. We introduce the notion of the {\it influence graph}, which consists of nodes and edges respectively representative of individual training points and associated pair-wise influences. The influence between a pair of training points represents the impact of removing one training point on the prediction of another, approximated by the influence function \citep{koh2017understanding}. Malicious training points are extracted by finding the maximum average sub-graph subject to a particular size. Extensive experiments on computer vision and natural language processing tasks demonstrate the effectiveness and generality of the proposed framework.
Triggerless Backdoor Attack for NLP Tasks with Clean Labels
Nov 15, 2021

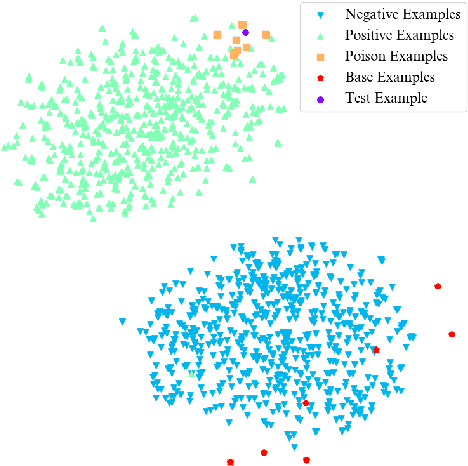
Backdoor attacks pose a new threat to NLP models. A standard strategy to construct poisoned data in backdoor attacks is to insert triggers (e.g., rare words) into selected sentences and alter the original label to a target label. This strategy comes with a severe flaw of being easily detected from both the trigger and the label perspectives: the trigger injected, which is usually a rare word, leads to an abnormal natural language expression, and thus can be easily detected by a defense model; the changed target label leads the example to be mistakenly labeled and thus can be easily detected by manual inspections. To deal with this issue, in this paper, we propose a new strategy to perform textual backdoor attacks which do not require an external trigger, and the poisoned samples are correctly labeled. The core idea of the proposed strategy is to construct clean-labeled examples, whose labels are correct but can lead to test label changes when fused with the training set. To generate poisoned clean-labeled examples, we propose a sentence generation model based on the genetic algorithm to cater to the non-differentiable characteristic of text data. Extensive experiments demonstrate that the proposed attacking strategy is not only effective, but more importantly, hard to defend due to its triggerless and clean-labeled nature. Our work marks the first step towards developing triggerless attacking strategies in NLP.
Interpreting Deep Learning Models in Natural Language Processing: A Review
Oct 25, 2021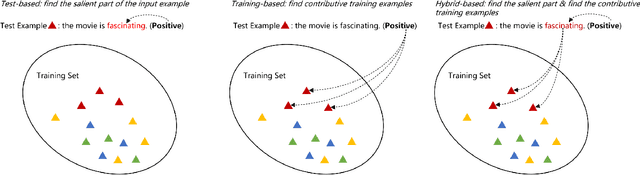
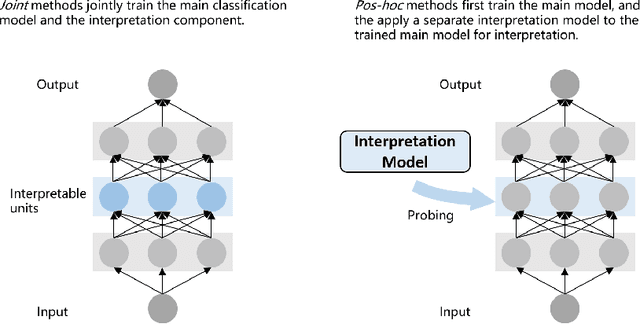
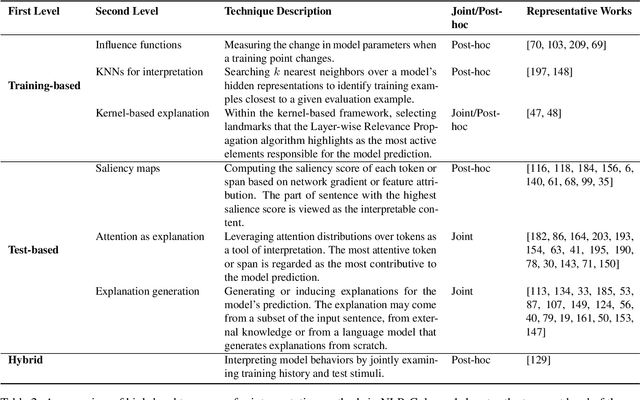
Neural network models have achieved state-of-the-art performances in a wide range of natural language processing (NLP) tasks. However, a long-standing criticism against neural network models is the lack of interpretability, which not only reduces the reliability of neural NLP systems but also limits the scope of their applications in areas where interpretability is essential (e.g., health care applications). In response, the increasing interest in interpreting neural NLP models has spurred a diverse array of interpretation methods over recent years. In this survey, we provide a comprehensive review of various interpretation methods for neural models in NLP. We first stretch out a high-level taxonomy for interpretation methods in NLP, i.e., training-based approaches, test-based approaches, and hybrid approaches. Next, we describe sub-categories in each category in detail, e.g., influence-function based methods, KNN-based methods, attention-based models, saliency-based methods, perturbation-based methods, etc. We point out deficiencies of current methods and suggest some avenues for future research.
GNN-LM: Language Modeling based on Global Contexts via GNN
Oct 17, 2021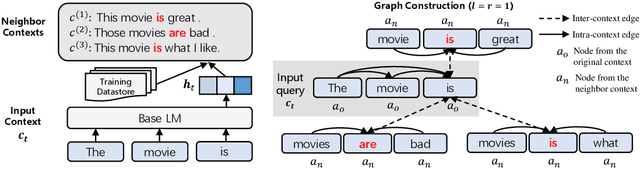
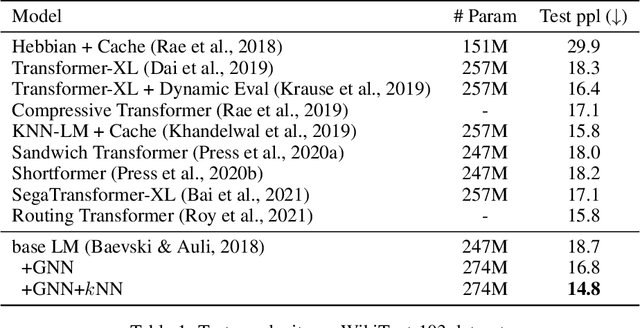
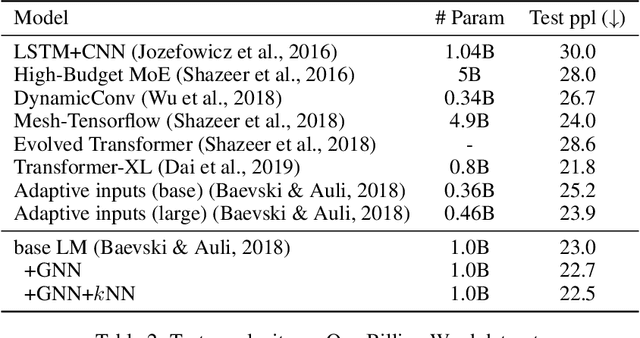
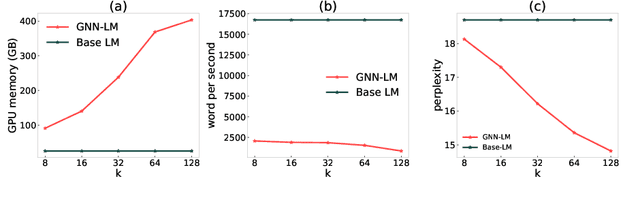
Inspired by the notion that ``{\it to copy is easier than to memorize}``, in this work, we introduce GNN-LM, which extends the vanilla neural language model (LM) by allowing to reference similar contexts in the entire training corpus. We build a directed heterogeneous graph between an input context and its semantically related neighbors selected from the training corpus, where nodes are tokens in the input context and retrieved neighbor contexts, and edges represent connections between nodes. Graph neural networks (GNNs) are constructed upon the graph to aggregate information from similar contexts to decode the token. This learning paradigm provides direct access to the reference contexts and helps improve a model's generalization ability. We conduct comprehensive experiments to validate the effectiveness of the GNN-LM: GNN-LM achieves a new state-of-the-art perplexity of 14.8 on WikiText-103 (a 4.5 point improvement over its counterpart of the vanilla LM model) and shows substantial improvement on One Billion Word and Enwiki8 datasets against strong baselines. In-depth ablation studies are performed to understand the mechanics of GNN-LM.
OpenViDial 2.0: A Larger-Scale, Open-Domain Dialogue Generation Dataset with Visual Contexts
Sep 28, 2021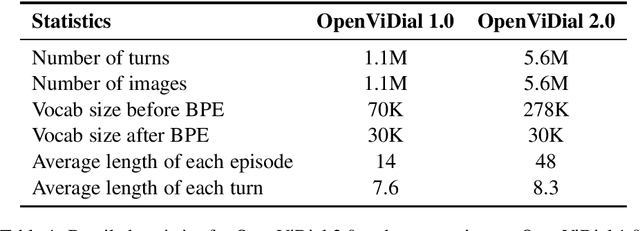


In order to better simulate the real human conversation process, models need to generate dialogue utterances based on not only preceding textual contexts but also visual contexts. However, with the development of multi-modal dialogue learning, the dataset scale gradually becomes a bottleneck. In this report, we release OpenViDial 2.0, a larger-scale open-domain multi-modal dialogue dataset compared to the previous version OpenViDial 1.0. OpenViDial 2.0 contains a total number of 5.6 million dialogue turns extracted from either movies or TV series from different resources, and each dialogue turn is paired with its corresponding visual context. We hope this large-scale dataset can help facilitate future researches on open-domain multi-modal dialog generation, e.g., multi-modal pretraining for dialogue generation.
$k$Folden: $k$-Fold Ensemble for Out-Of-Distribution Detection
Aug 29, 2021
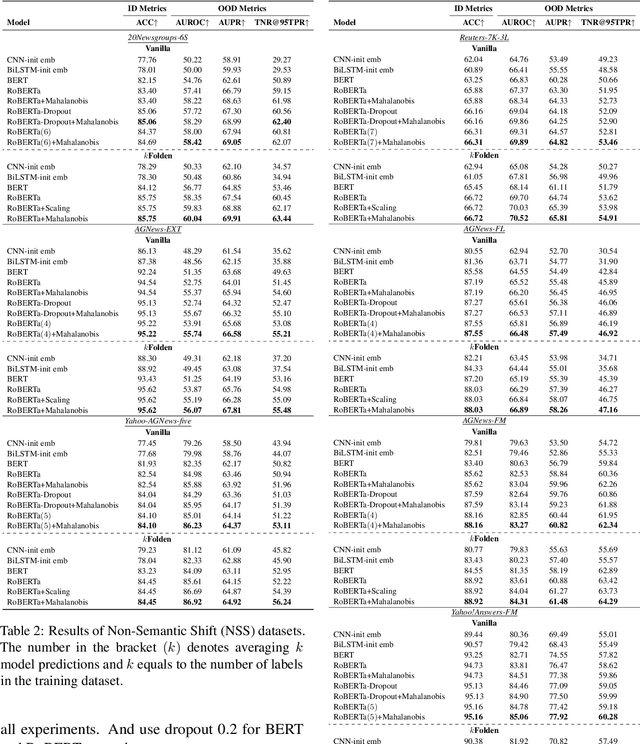

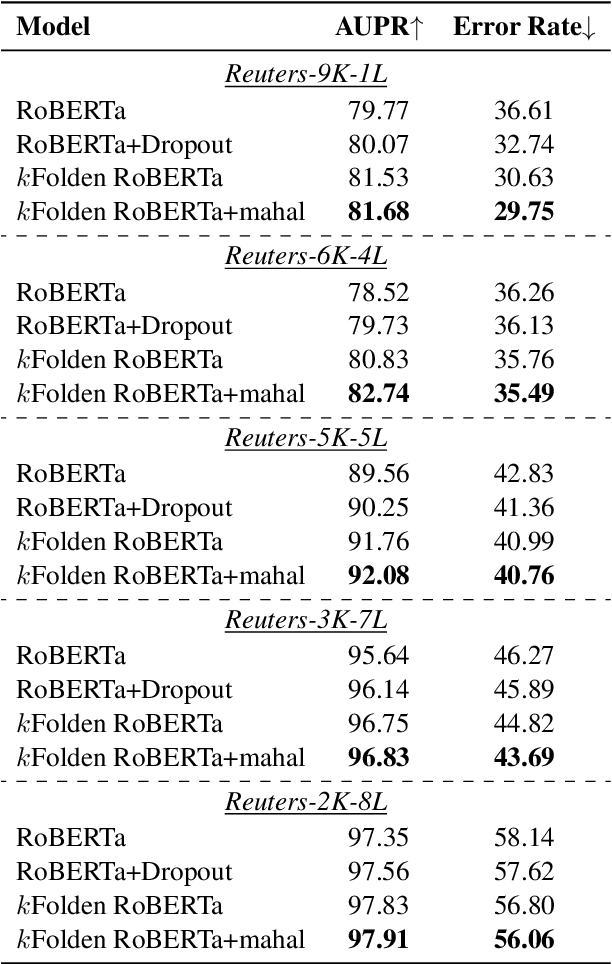
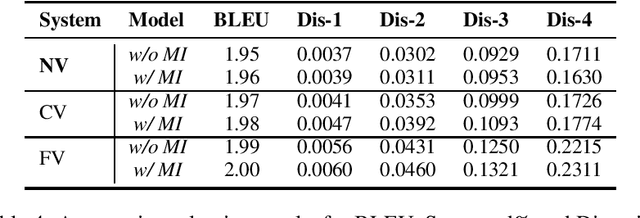
Out-of-Distribution (OOD) detection is an important problem in natural language processing (NLP). In this work, we propose a simple yet effective framework $k$Folden, which mimics the behaviors of OOD detection during training without the use of any external data. For a task with $k$ training labels, $k$Folden induces $k$ sub-models, each of which is trained on a subset with $k-1$ categories with the left category masked unknown to the sub-model. Exposing an unknown label to the sub-model during training, the model is encouraged to learn to equally attribute the probability to the seen $k-1$ labels for the unknown label, enabling this framework to simultaneously resolve in- and out-distribution examples in a natural way via OOD simulations. Taking text classification as an archetype, we develop benchmarks for OOD detection using existing text classification datasets. By conducting comprehensive comparisons and analyses on the developed benchmarks, we demonstrate the superiority of $k$Folden against current methods in terms of improving OOD detection performances while maintaining improved in-domain classification accuracy.
ChineseBERT: Chinese Pretraining Enhanced by Glyph and Pinyin Information
Jun 30, 2021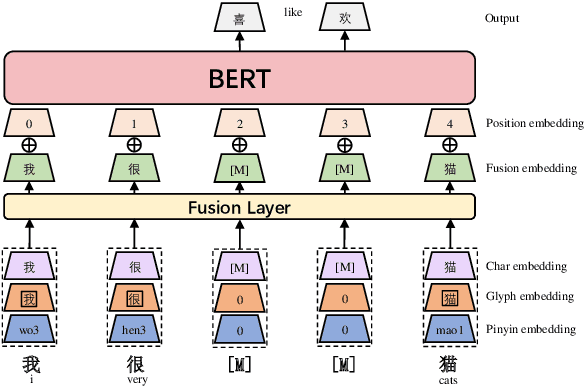

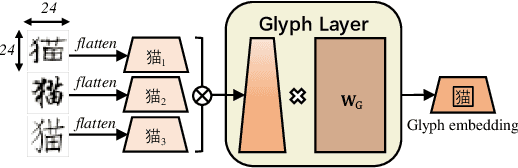
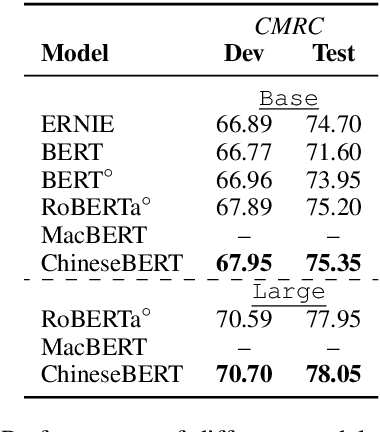
Recent pretraining models in Chinese neglect two important aspects specific to the Chinese language: glyph and pinyin, which carry significant syntax and semantic information for language understanding. In this work, we propose ChineseBERT, which incorporates both the {\it glyph} and {\it pinyin} information of Chinese characters into language model pretraining. The glyph embedding is obtained based on different fonts of a Chinese character, being able to capture character semantics from the visual features, and the pinyin embedding characterizes the pronunciation of Chinese characters, which handles the highly prevalent heteronym phenomenon in Chinese (the same character has different pronunciations with different meanings). Pretrained on large-scale unlabeled Chinese corpus, the proposed ChineseBERT model yields significant performance boost over baseline models with fewer training steps. The porpsoed model achieves new SOTA performances on a wide range of Chinese NLP tasks, including machine reading comprehension, natural language inference, text classification, sentence pair matching, and competitive performances in named entity recognition. Code and pretrained models are publicly available at https://github.com/ShannonAI/ChineseBert.