 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuery-Mixed Interest Extraction and Heterogeneous Interaction: A Scalable CTR Model for Industrial Recommender Systems
Feb 12, 2026Learning effective feature interactions is central to modern recommender systems, yet remains challenging in industrial settings due to sparse multi-field inputs and ultra-long user behavior sequences. While recent scaling efforts have improved model capacity, they often fail to construct both context-aware and context-independent user intent from the long-term and real-time behavior sequence. Meanwhile, recent work also suffers from inefficient and homogeneous interaction mechanisms, leading to suboptimal prediction performance. To address these limitations, we propose HeMix, a scalable ranking model that unifies adaptive sequence tokenization and heterogeneous interaction structure. Specifically, HeMix introduces a Query-Mixed Interest Extraction module that jointly models context-aware and context-independent user interests via dynamic and fixed queries over global and real-time behavior sequences. For interaction, we replace self-attention with the HeteroMixer block, enabling efficient, multi-granularity cross-feature interactions that adopt the multi-head token fusion, heterogeneous interaction and group-aligned reconstruction pipelines. HeMix demonstrates favorable scaling behavior, driven by the HeteroMixer block, where increasing model scale via parameter expansion leads to steady improvements in recommendation accuracy. Experiments on industrial-scale datasets show that HeMix scales effectively and consistently outperforms strong baselines. Most importantly, HeMix has been deployed on the AMAP platform, delivering significant online gains over DLRM: +3.61\% GMV, +2.78\% PV\_CTR, and +2.12\% UV\_CVR.
GeoGR: A Generative Retrieval Framework for Spatio-Temporal Aware POI Recommendation
Feb 11, 2026Next Point-of-Interest (POI) prediction is a fundamental task in location-based services, especially critical for large-scale navigation platforms like AMAP that serve billions of users across diverse lifestyle scenarios. While recent POI recommendation approaches based on SIDs have achieved promising, they struggle in complex, sparse real-world environments due to two key limitations: (1) inadequate modeling of high-quality SIDs that capture cross-category spatio-temporal collaborative relationships, and (2) poor alignment between large language models (LLMs) and the POI recommendation task. To this end, we propose GeoGR, a geographic generative recommendation framework tailored for navigation-based LBS like AMAP, which perceives users' contextual state changes and enables intent-aware POI recommendation. GeoGR features a two-stage design: (i) a geo-aware SID tokenization pipeline that explicitly learns spatio-temporal collaborative semantic representations via geographically constrained co-visited POI pairs, contrastive learning, and iterative refinement; and (ii) a multi-stage LLM training strategy that aligns non-native SID tokens through multiple template-based continued pre-training(CPT) and enables autoregressive POI generation via supervised fine-tuning(SFT). Extensive experiments on multiple real-world datasets demonstrate GeoGR's superiority over state-of-the-art baselines. Moreover, deployment on the AMAP platform, serving millions of users with multiple online metrics boosting, confirms its practical effectiveness and scalability in production.
Towards Deeper, Lighter and Interpretable Cross Network for CTR Prediction
Nov 08, 2023



Click Through Rate (CTR) prediction plays an essential role in recommender systems and online advertising. It is crucial to effectively model feature interactions to improve the prediction performance of CTR models. However, existing methods face three significant challenges. First, while most methods can automatically capture high-order feature interactions, their performance tends to diminish as the order of feature interactions increases. Second, existing methods lack the ability to provide convincing interpretations of the prediction results, especially for high-order feature interactions, which limits the trustworthiness of their predictions. Third, many methods suffer from the presence of redundant parameters, particularly in the embedding layer. This paper proposes a novel method called Gated Deep Cross Network (GDCN) and a Field-level Dimension Optimization (FDO) approach to address these challenges. As the core structure of GDCN, Gated Cross Network (GCN) captures explicit high-order feature interactions and dynamically filters important interactions with an information gate in each order. Additionally, we use the FDO approach to learn condensed dimensions for each field based on their importance. Comprehensive experiments on five datasets demonstrate the effectiveness, superiority and interpretability of GDCN. Moreover, we verify the effectiveness of FDO in learning various dimensions and reducing model parameters. The code is available on \url{https://github.com/anonctr/GDCN}.
A Comprehensive Summarization and Evaluation of Feature Refinement Modules for CTR Prediction
Nov 08, 2023



Click-through rate (CTR) prediction is widely used in academia and industry. Most CTR tasks fall into a feature embedding \& feature interaction paradigm, where the accuracy of CTR prediction is mainly improved by designing practical feature interaction structures. However, recent studies have argued that the fixed feature embedding learned only through the embedding layer limits the performance of existing CTR models. Some works apply extra modules on top of the embedding layer to dynamically refine feature representations in different instances, making it effective and easy to integrate with existing CTR methods. Despite the promising results, there is a lack of a systematic review and summarization of this new promising direction on the CTR task. To fill this gap, we comprehensively summarize and define a new module, namely \textbf{feature refinement} (FR) module, that can be applied between feature embedding and interaction layers. We extract 14 FR modules from previous works, including instances where the FR module was proposed but not clearly defined or explained. We fully assess the effectiveness and compatibility of existing FR modules through comprehensive and extensive experiments with over 200 augmented models and over 4,000 runs for more than 15,000 GPU hours. The results offer insightful guidelines for researchers, and all benchmarking code and experimental results are open-sourced. In addition, we present a new architecture of assigning independent FR modules to separate sub-networks for parallel CTR models, as opposed to the conventional method of inserting a shared FR module on top of the embedding layer. Our approach is also supported by comprehensive experiments demonstrating its effectiveness.
CL4CTR: A Contrastive Learning Framework for CTR Prediction
Dec 01, 2022Many Click-Through Rate (CTR) prediction works focused on designing advanced architectures to model complex feature interactions but neglected the importance of feature representation learning, e.g., adopting a plain embedding layer for each feature, which results in sub-optimal feature representations and thus inferior CTR prediction performance. For instance, low frequency features, which account for the majority of features in many CTR tasks, are less considered in standard supervised learning settings, leading to sub-optimal feature representations. In this paper, we introduce self-supervised learning to produce high-quality feature representations directly and propose a model-agnostic Contrastive Learning for CTR (CL4CTR) framework consisting of three self-supervised learning signals to regularize the feature representation learning: contrastive loss, feature alignment, and field uniformity. The contrastive module first constructs positive feature pairs by data augmentation and then minimizes the distance between the representations of each positive feature pair by the contrastive loss. The feature alignment constraint forces the representations of features from the same field to be close, and the field uniformity constraint forces the representations of features from different fields to be distant. Extensive experiments verify that CL4CTR achieves the best performance on four datasets and has excellent effectiveness and compatibility with various representative baselines.
Enhancing CTR Prediction with Context-Aware Feature Representation Learning
Apr 19, 2022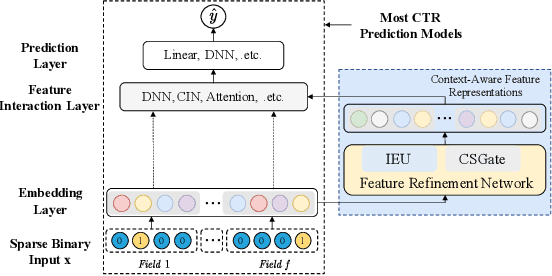
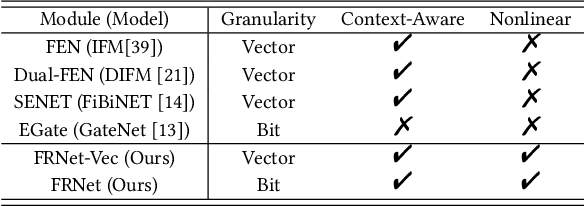
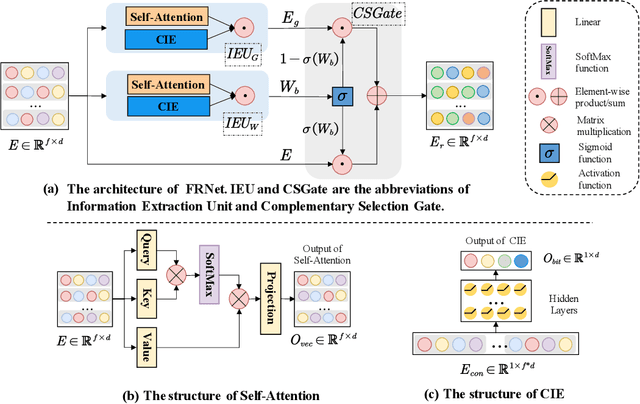

CTR prediction has been widely used in the real world. Many methods model feature interaction to improve their performance. However, most methods only learn a fixed representation for each feature without considering the varying importance of each feature under different contexts, resulting in inferior performance. Recently, several methods tried to learn vector-level weights for feature representations to address the fixed representation issue. However, they only produce linear transformations to refine the fixed feature representations, which are still not flexible enough to capture the varying importance of each feature under different contexts. In this paper, we propose a novel module named Feature Refinement Network (FRNet), which learns context-aware feature representations at bit-level for each feature in different contexts. FRNet consists of two key components: 1) Information Extraction Unit (IEU), which captures contextual information and cross-feature relationships to guide context-aware feature refinement; and 2) Complementary Selection Gate (CSGate), which adaptively integrates the original and complementary feature representations learned in IEU with bit-level weights. Notably, FRNet is orthogonal to existing CTR methods and thus can be applied in many existing methods to boost their performance. Comprehensive experiments are conducted to verify the effectiveness, efficiency, and compatibility of FRNet.