 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Pillar Motion Learning for Autonomous Driving
Apr 18, 2021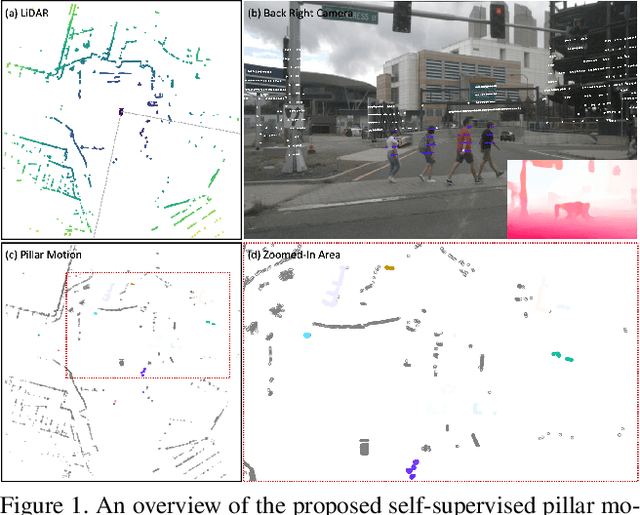

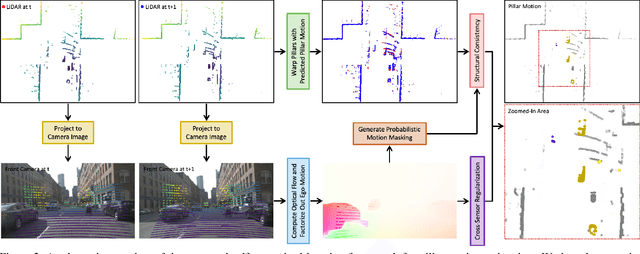

Autonomous driving can benefit from motion behavior comprehension when interacting with diverse traffic participants in highly dynamic environments. Recently, there has been a growing interest in estimating class-agnostic motion directly from point clouds. Current motion estimation methods usually require vast amount of annotated training data from self-driving scenes. However, manually labeling point clouds is notoriously difficult, error-prone and time-consuming. In this paper, we seek to answer the research question of whether the abundant unlabeled data collections can be utilized for accurate and efficient motion learning. To this end, we propose a learning framework that leverages free supervisory signals from point clouds and paired camera images to estimate motion purely via self-supervision. Our model involves a point cloud based structural consistency augmented with probabilistic motion masking as well as a cross-sensor motion regularization to realize the desired self-supervision. Experiments reveal that our approach performs competitively to supervised methods, and achieves the state-of-the-art result when combining our self-supervised model with supervised fine-tuning.
UFO$^2$: A Unified Framework towards Omni-supervised Object Detection
Oct 21, 2020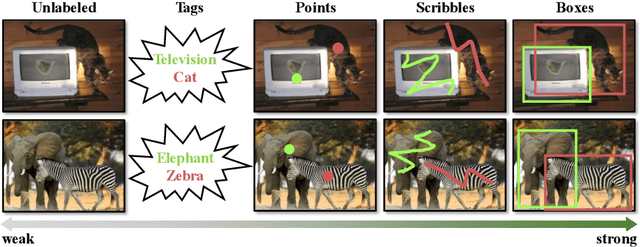


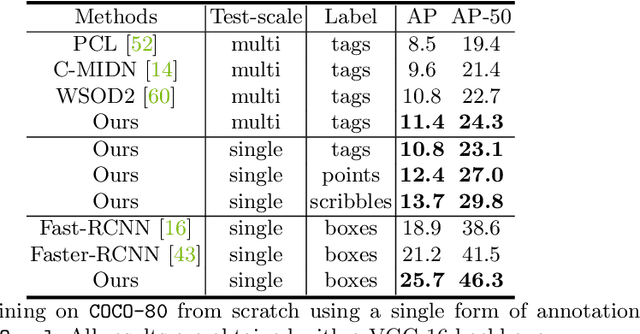
Existing work on object detection often relies on a single form of annotation: the model is trained using either accurate yet costly bounding boxes or cheaper but less expressive image-level tags. However, real-world annotations are often diverse in form, which challenges these existing works. In this paper, we present UFO$^2$, a unified object detection framework that can handle different forms of supervision simultaneously. Specifically, UFO$^2$ incorporates strong supervision (e.g., boxes), various forms of partial supervision (e.g., class tags, points, and scribbles), and unlabeled data. Through rigorous evaluations, we demonstrate that each form of label can be utilized to either train a model from scratch or to further improve a pre-trained model. We also use UFO$^2$ to investigate budget-aware omni-supervised learning, i.e., various annotation policies are studied under a fixed annotation budget: we show that competitive performance needs no strong labels for all data. Finally, we demonstrate the generalization of UFO$^2$, detecting more than 1,000 different objects without bounding box annotations.
Hierarchical Contrastive Motion Learning for Video Action Recognition
Jul 20, 2020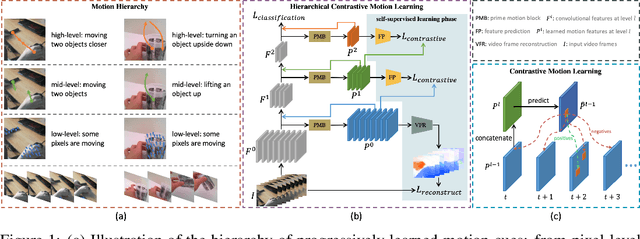
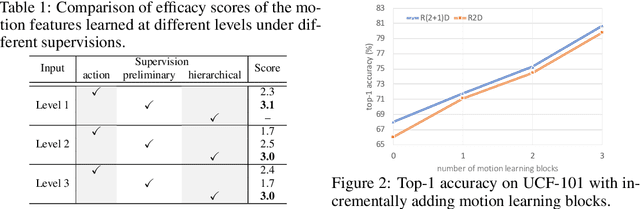
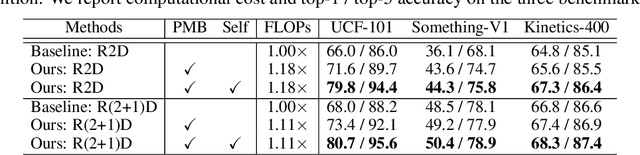

One central question for video action recognition is how to model motion. In this paper, we present hierarchical contrastive motion learning, a new self-supervised learning framework to extract effective motion representations from raw video frames. Our approach progressively learns a hierarchy of motion features that correspond to different abstraction levels in a network. This hierarchical design bridges the semantic gap between low-level motion cues and high-level recognition tasks, and promotes the fusion of appearance and motion information at multiple levels. At each level, an explicit motion self-supervision is provided via contrastive learning to enforce the motion features at the current level to predict the future ones at the previous level. Thus, the motion features at higher levels are trained to gradually capture semantic dynamics and evolve more discriminative for action recognition. Our motion learning module is lightweight and flexible to be embedded into various backbone networks. Extensive experiments on four benchmarks show that the proposed approach consistently achieves superior results.
Joint Disentangling and Adaptation for Cross-Domain Person Re-Identification
Jul 20, 2020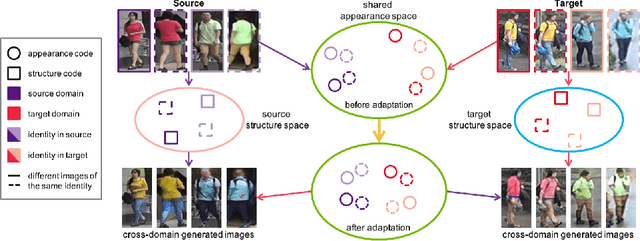
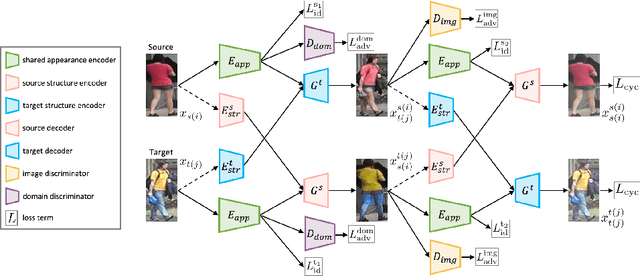
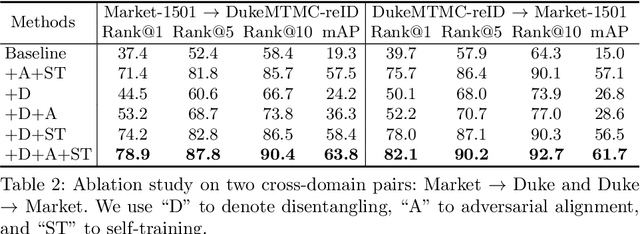
Although a significant progress has been witnessed in supervised person re-identification (re-id), it remains challenging to generalize re-id models to new domains due to the huge domain gaps. Recently, there has been a growing interest in using unsupervised domain adaptation to address this scalability issue. Existing methods typically conduct adaptation on the representation space that contains both id-related and id-unrelated factors, thus inevitably undermining the adaptation efficacy of id-related features. In this paper, we seek to improve adaptation by purifying the representation space to be adapted. To this end, we propose a joint learning framework that disentangles id-related/unrelated features and enforces adaptation to work on the id-related feature space exclusively. Our model involves a disentangling module that encodes cross-domain images into a shared appearance space and two separate structure spaces, and an adaptation module that performs adversarial alignment and self-training on the shared appearance space. The two modules are co-designed to be mutually beneficial. Extensive experiments demonstrate that the proposed joint learning framework outperforms the state-of-the-art methods by clear margins.
Contrastive Learning for Weakly Supervised Phrase Grounding
Jun 17, 2020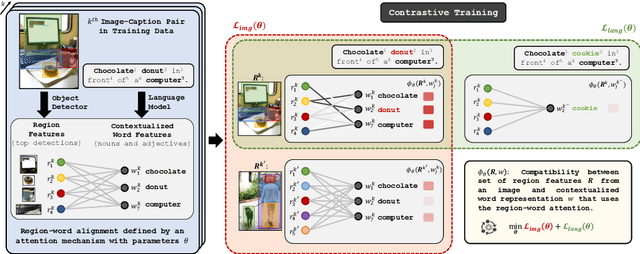
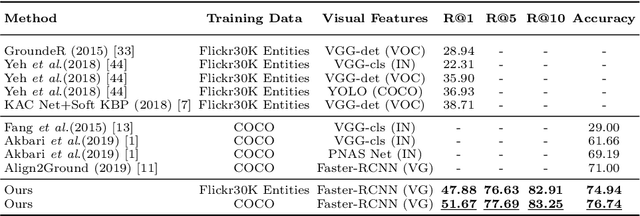
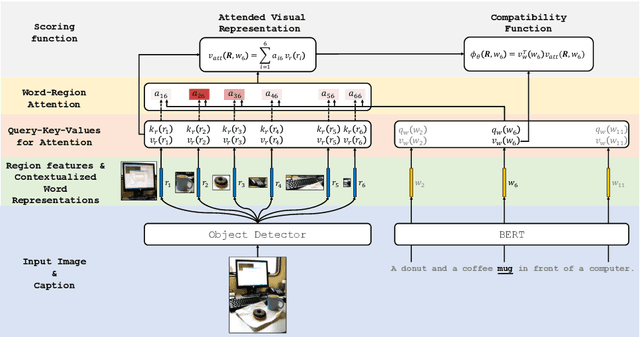

Phrase grounding, the problem of associating image regions to caption words, is a crucial component of vision-language tasks. We show that phrase grounding can be learned by optimizing word-region attention to maximize a lower bound on mutual information between images and caption words. Given pairs of images and captions, we maximize compatibility of the attention-weighted regions and the words in the corresponding caption, compared to non-corresponding pairs of images and captions. A key idea is to construct effective negative captions for learning through language model guided word substitutions. Training with our negatives yields a $\sim10\%$ absolute gain in accuracy over randomly-sampled negatives from the training data. Our weakly supervised phrase grounding model trained on COCO-Captions shows a healthy gain of $5.7\%$ to achieve $76.7\%$ accuracy on Flickr30K Entities benchmark.
PAMTRI: Pose-Aware Multi-Task Learning for Vehicle Re-Identification Using Highly Randomized Synthetic Data
May 02, 2020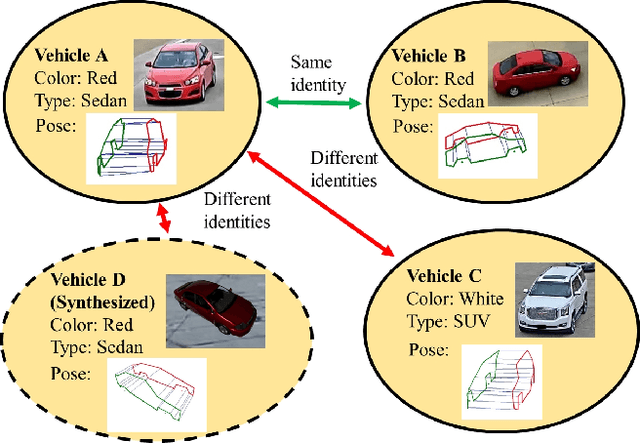
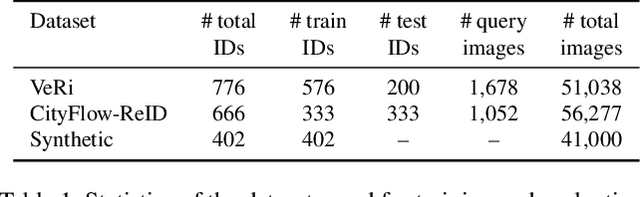
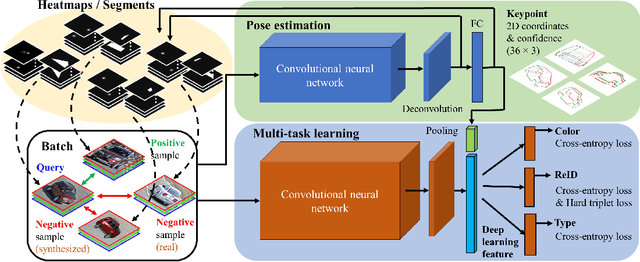
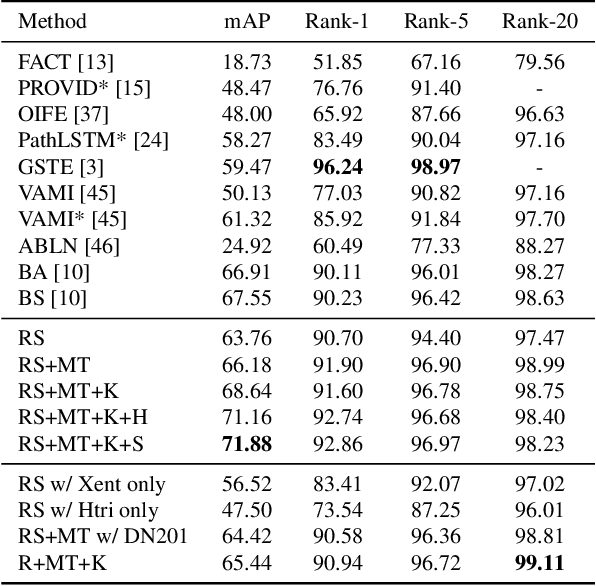
In comparison with person re-identification (ReID), which has been widely studied in the research community, vehicle ReID has received less attention. Vehicle ReID is challenging due to 1) high intra-class variability (caused by the dependency of shape and appearance on viewpoint), and 2) small inter-class variability (caused by the similarity in shape and appearance between vehicles produced by different manufacturers). To address these challenges, we propose a Pose-Aware Multi-Task Re-Identification (PAMTRI) framework. This approach includes two innovations compared with previous methods. First, it overcomes viewpoint-dependency by explicitly reasoning about vehicle pose and shape via keypoints, heatmaps and segments from pose estimation. Second, it jointly classifies semantic vehicle attributes (colors and types) while performing ReID, through multi-task learning with the embedded pose representations. Since manually labeling images with detailed pose and attribute information is prohibitive, we create a large-scale highly randomized synthetic dataset with automatically annotated vehicle attributes for training. Extensive experiments validate the effectiveness of each proposed component, showing that PAMTRI achieves significant improvement over state-of-the-art on two mainstream vehicle ReID benchmarks: VeRi and CityFlow-ReID. Code and models are available at https://github.com/NVlabs/PAMTRI.
The 4th AI City Challenge
Apr 30, 2020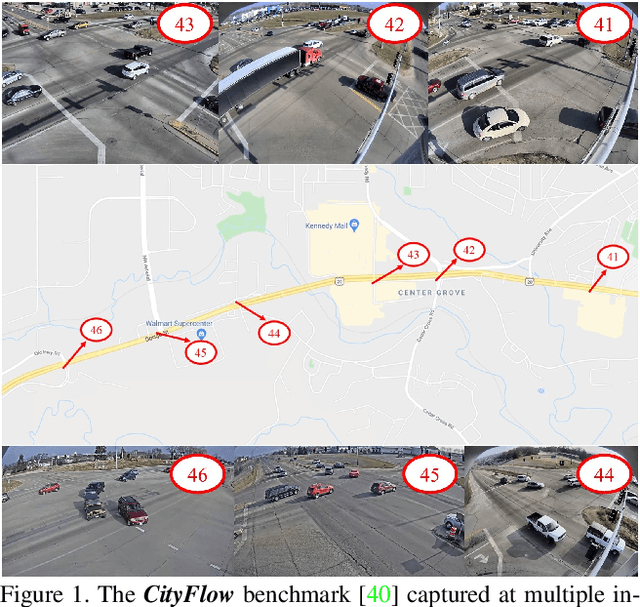
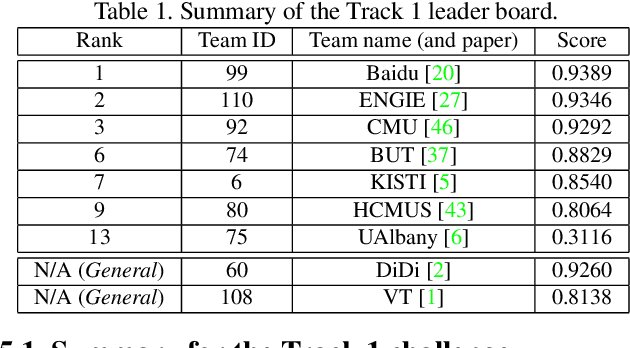
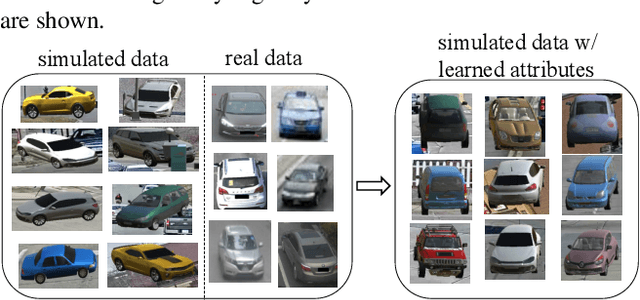
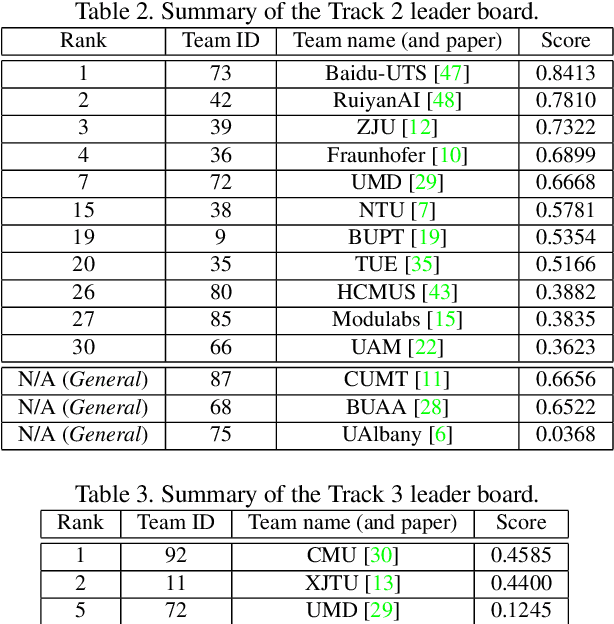
The AI City Challenge was created to accelerate intelligent video analysis that helps make cities smarter and safer. Transportation is one of the largest segments that can benefit from actionable insights derived from data captured by sensors, where computer vision and deep learning have shown promise in achieving large-scale practical deployment. The 4th annual edition of the AI City Challenge has attracted 315 participating teams across 37 countries, who leveraged city-scale real traffic data and high-quality synthetic data to compete in four challenge tracks. Track 1 addressed video-based automatic vehicle counting, where the evaluation is conducted on both algorithmic effectiveness and computational efficiency. Track 2 addressed city-scale vehicle re-identification with augmented synthetic data to substantially increase the training set for the task. Track 3 addressed city-scale multi-target multi-camera vehicle tracking. Track 4 addressed traffic anomaly detection. The evaluation system shows two leader boards, in which a general leader board shows all submitted results, and a public leader board shows results limited to our contest participation rules, that teams are not allowed to use external data in their work. The public leader board shows results more close to real-world situations where annotated data are limited. Our results show promise that AI technology can enable smarter and safer transportation systems.
NNV: The Neural Network Verification Tool for Deep Neural Networks and Learning-Enabled Cyber-Physical Systems
Apr 12, 2020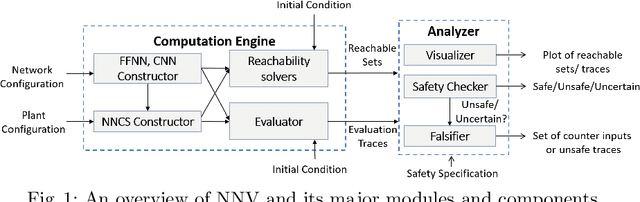
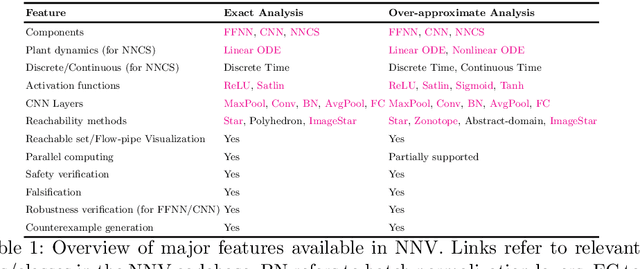
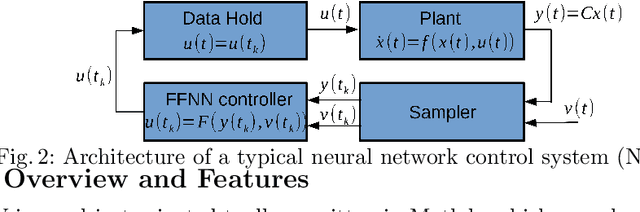
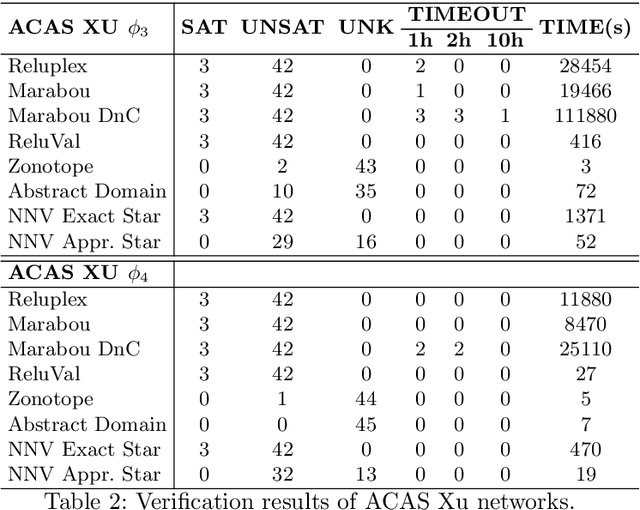
This paper presents the Neural Network Verification (NNV) software tool, a set-based verification framework for deep neural networks (DNNs) and learning-enabled cyber-physical systems (CPS). The crux of NNV is a collection of reachability algorithms that make use of a variety of set representations, such as polyhedra, star sets, zonotopes, and abstract-domain representations. NNV supports both exact (sound and complete) and over-approximate (sound) reachability algorithms for verifying safety and robustness properties of feed-forward neural networks (FFNNs) with various activation functions. For learning-enabled CPS, such as closed-loop control systems incorporating neural networks, NNV provides exact and over-approximate reachability analysis schemes for linear plant models and FFNN controllers with piecewise-linear activation functions, such as ReLUs. For similar neural network control systems (NNCS) that instead have nonlinear plant models, NNV supports over-approximate analysis by combining the star set analysis used for FFNN controllers with zonotope-based analysis for nonlinear plant dynamics building on CORA. We evaluate NNV using two real-world case studies: the first is safety verification of ACAS Xu networks and the second deals with the safety verification of a deep learning-based adaptive cruise control system.
Instance-aware, Context-focused, and Memory-efficient Weakly Supervised Object Detection
Apr 09, 2020
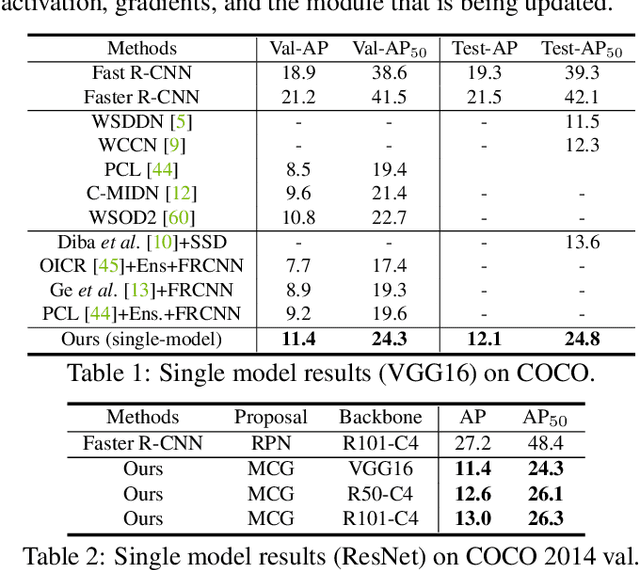
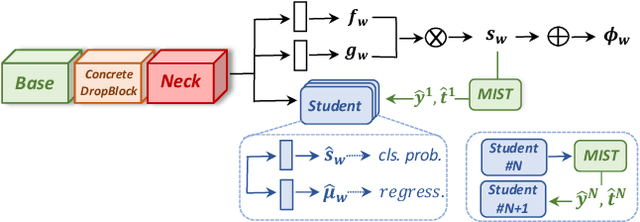
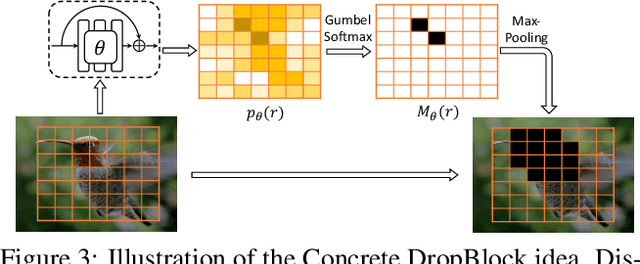
Weakly supervised learning has emerged as a compelling tool for object detection by reducing the need for strong supervision during training. However, major challenges remain: (1) differentiation of object instances can be ambiguous; (2) detectors tend to focus on discriminative parts rather than entire objects; (3) without ground truth, object proposals have to be redundant for high recalls, causing significant memory consumption. Addressing these challenges is difficult, as it often requires to eliminate uncertainties and trivial solutions. To target these issues we develop an instance-aware and context-focused unified framework. It employs an instance-aware self-training algorithm and a learnable Concrete DropBlock while devising a memory-efficient sequential batch back-propagation. Our proposed method achieves state-of-the-art results on COCO ($12.1\% ~AP$, $24.8\% ~AP_{50}$), VOC 2007 ($54.9\% ~AP$), and VOC 2012 ($52.1\% ~AP$), improving baselines by great margins. In addition, the proposed method is the first to benchmark ResNet based models and weakly supervised video object detection. Refer to our project page for code, models, and more details: https://github.com/NVlabs/wetectron.
Reachability Analysis for Feed-Forward Neural Networks using Face Lattices
Mar 02, 2020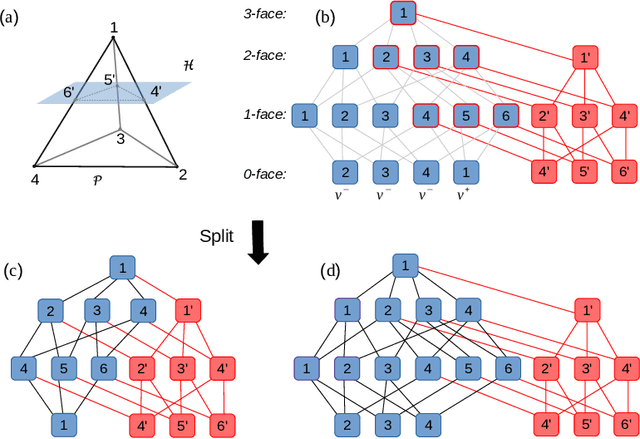
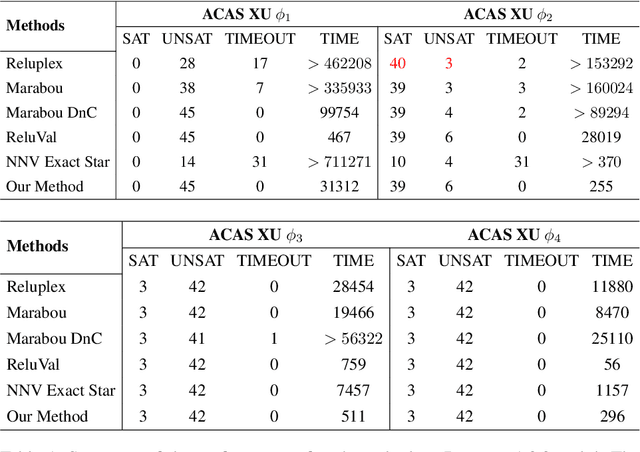

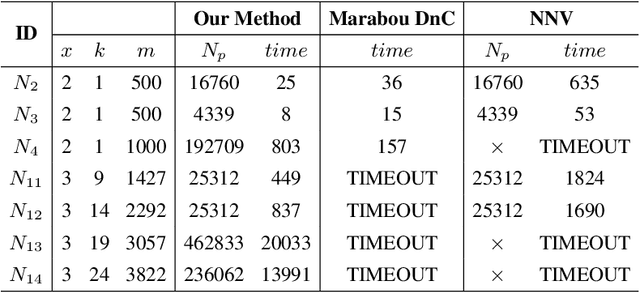
Deep neural networks have been widely applied as an effective approach to handle complex and practical problems. However, one of the most fundamental open problems is the lack of formal methods to analyze the safety of their behaviors. To address this challenge, we propose a parallelizable technique to compute exact reachable sets of a neural network to an input set. Our method currently focuses on feed-forward neural networks with ReLU activation functions. One of the primary challenges for polytope-based approaches is identifying the intersection between intermediate polytopes and hyperplanes from neurons. In this regard, we present a new approach to construct the polytopes with the face lattice, a complete combinatorial structure. The correctness and performance of our methodology are evaluated by verifying the safety of ACAS Xu networks and other benchmarks. Compared to state-of-the-art methods such as Reluplex, Marabou, and NNV, our approach exhibits a significantly higher efficiency. Additionally, our approach is capable of constructing the complete input set given an output set, so that any input that leads to safety violation can be tracked.