 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTEP: Spatio-Temporal Progressive Learning for Video Action Detection
Paper and Code
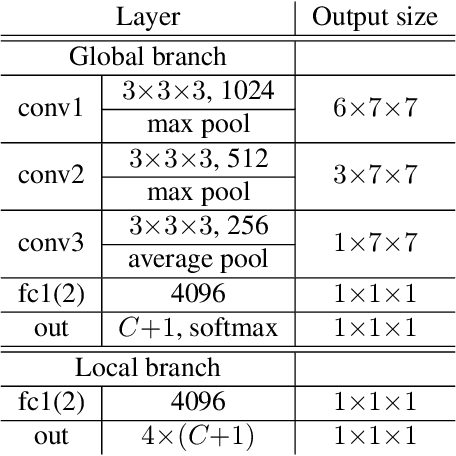

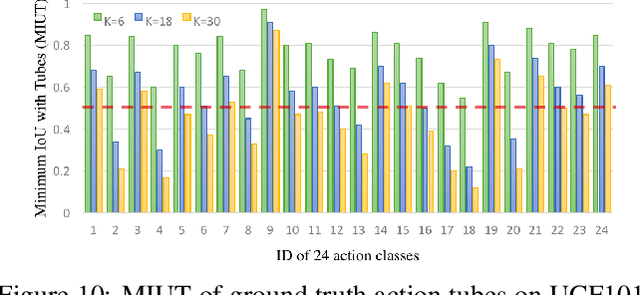
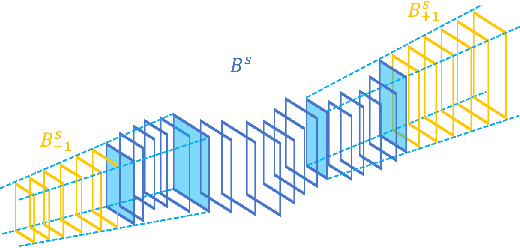
In this paper, we propose Spatio-TEmporal Progressive (STEP) action detector---a progressive learning framework for spatio-temporal action detection in videos. Starting from a handful of coarse-scale proposal cuboids, our approach progressively refines the proposals towards actions over a few steps. In this way, high-quality proposals (i.e., adhere to action movements) can be gradually obtained at later steps by leveraging the regression outputs from previous steps. At each step, we adaptively extend the proposals in time to incorporate more related temporal context. Compared to the prior work that performs action detection in one run, our progressive learning framework is able to naturally handle the spatial displacement within action tubes and therefore provides a more effective way for spatio-temporal modeling. We extensively evaluate our approach on UCF101 and AVA, and demonstrate superior detection results. Remarkably, we achieve mAP of 75.0% and 18.6% on the two datasets with 3 progressive steps and using respectively only 11 and 34 initial proposals.