 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYAYI 2: Multilingual Open-Source Large Language Models
Dec 22, 2023As the latest advancements in natural language processing, large language models (LLMs) have achieved human-level language understanding and generation abilities in many real-world tasks, and even have been regarded as a potential path to the artificial general intelligence. To better facilitate research on LLMs, many open-source LLMs, such as Llama 2 and Falcon, have recently been proposed and gained comparable performances to proprietary models. However, these models are primarily designed for English scenarios and exhibit poor performances in Chinese contexts. In this technical report, we propose YAYI 2, including both base and chat models, with 30 billion parameters. YAYI 2 is pre-trained from scratch on a multilingual corpus which contains 2.65 trillion tokens filtered by our pre-training data processing pipeline. The base model is aligned with human values through supervised fine-tuning with millions of instructions and reinforcement learning from human feedback. Extensive experiments on multiple benchmarks, such as MMLU and CMMLU, consistently demonstrate that the proposed YAYI 2 outperforms other similar sized open-source models.
BNS-Net: A Dual-channel Sarcasm Detection Method Considering Behavior-level and Sentence-level Conflicts
Sep 07, 2023



Sarcasm detection is a binary classification task that aims to determine whether a given utterance is sarcastic. Over the past decade, sarcasm detection has evolved from classical pattern recognition to deep learning approaches, where features such as user profile, punctuation and sentiment words have been commonly employed for sarcasm detection. In real-life sarcastic expressions, behaviors without explicit sentimental cues often serve as carriers of implicit sentimental meanings. Motivated by this observation, we proposed a dual-channel sarcasm detection model named BNS-Net. The model considers behavior and sentence conflicts in two channels. Channel 1: Behavior-level Conflict Channel reconstructs the text based on core verbs while leveraging the modified attention mechanism to highlight conflict information. Channel 2: Sentence-level Conflict Channel introduces external sentiment knowledge to segment the text into explicit and implicit sentences, capturing conflicts between them. To validate the effectiveness of BNS-Net, several comparative and ablation experiments are conducted on three public sarcasm datasets. The analysis and evaluation of experimental results demonstrate that the BNS-Net effectively identifies sarcasm in text and achieves the state-of-the-art performance.
ORES: Open-vocabulary Responsible Visual Synthesis
Aug 26, 2023



Avoiding synthesizing specific visual concepts is an essential challenge in responsible visual synthesis. However, the visual concept that needs to be avoided for responsible visual synthesis tends to be diverse, depending on the region, context, and usage scenarios. In this work, we formalize a new task, Open-vocabulary Responsible Visual Synthesis (ORES), where the synthesis model is able to avoid forbidden visual concepts while allowing users to input any desired content. To address this problem, we present a Two-stage Intervention (TIN) framework. By introducing 1) rewriting with learnable instruction through a large-scale language model (LLM) and 2) synthesizing with prompt intervention on a diffusion synthesis model, it can effectively synthesize images avoiding any concepts but following the user's query as much as possible. To evaluate on ORES, we provide a publicly available dataset, baseline models, and benchmark. Experimental results demonstrate the effectiveness of our method in reducing risks of image generation. Our work highlights the potential of LLMs in responsible visual synthesis. Our code and dataset is public available.
NUWA-XL: Diffusion over Diffusion for eXtremely Long Video Generation
Mar 22, 2023



In this paper, we propose NUWA-XL, a novel Diffusion over Diffusion architecture for eXtremely Long video generation. Most current work generates long videos segment by segment sequentially, which normally leads to the gap between training on short videos and inferring long videos, and the sequential generation is inefficient. Instead, our approach adopts a ``coarse-to-fine'' process, in which the video can be generated in parallel at the same granularity. A global diffusion model is applied to generate the keyframes across the entire time range, and then local diffusion models recursively fill in the content between nearby frames. This simple yet effective strategy allows us to directly train on long videos (3376 frames) to reduce the training-inference gap, and makes it possible to generate all segments in parallel. To evaluate our model, we build FlintstonesHD dataset, a new benchmark for long video generation. Experiments show that our model not only generates high-quality long videos with both global and local coherence, but also decreases the average inference time from 7.55min to 26s (by 94.26\%) at the same hardware setting when generating 1024 frames. The homepage link is \url{https://msra-nuwa.azurewebsites.net/}
Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
Mar 08, 2023



ChatGPT is attracting a cross-field interest as it provides a language interface with remarkable conversational competency and reasoning capabilities across many domains. However, since ChatGPT is trained with languages, it is currently not capable of processing or generating images from the visual world. At the same time, Visual Foundation Models, such as Visual Transformers or Stable Diffusion, although showing great visual understanding and generation capabilities, they are only experts on specific tasks with one-round fixed inputs and outputs. To this end, We build a system called \textbf{Visual ChatGPT}, incorporating different Visual Foundation Models, to enable the user to interact with ChatGPT by 1) sending and receiving not only languages but also images 2) providing complex visual questions or visual editing instructions that require the collaboration of multiple AI models with multi-steps. 3) providing feedback and asking for corrected results. We design a series of prompts to inject the visual model information into ChatGPT, considering models of multiple inputs/outputs and models that require visual feedback. Experiments show that Visual ChatGPT opens the door to investigating the visual roles of ChatGPT with the help of Visual Foundation Models. Our system is publicly available at \url{https://github.com/microsoft/visual-chatgpt}.
Learning 3D Photography Videos via Self-supervised Diffusion on Single Images
Feb 21, 2023



3D photography renders a static image into a video with appealing 3D visual effects. Existing approaches typically first conduct monocular depth estimation, then render the input frame to subsequent frames with various viewpoints, and finally use an inpainting model to fill those missing/occluded regions. The inpainting model plays a crucial role in rendering quality, but it is normally trained on out-of-domain data. To reduce the training and inference gap, we propose a novel self-supervised diffusion model as the inpainting module. Given a single input image, we automatically construct a training pair of the masked occluded image and the ground-truth image with random cycle-rendering. The constructed training samples are closely aligned to the testing instances, without the need of data annotation. To make full use of the masked images, we design a Masked Enhanced Block (MEB), which can be easily plugged into the UNet and enhance the semantic conditions. Towards real-world animation, we present a novel task: out-animation, which extends the space and time of input objects. Extensive experiments on real datasets show that our method achieves competitive results with existing SOTA methods.
Progressive Meta-Pooling Learning for Lightweight Image Classification Model
Jan 24, 2023



Practical networks for edge devices adopt shallow depth and small convolutional kernels to save memory and computational cost, which leads to a restricted receptive field. Conventional efficient learning methods focus on lightweight convolution designs, ignoring the role of the receptive field in neural network design. In this paper, we propose the Meta-Pooling framework to make the receptive field learnable for a lightweight network, which consists of parameterized pooling-based operations. Specifically, we introduce a parameterized spatial enhancer, which is composed of pooling operations to provide versatile receptive fields for each layer of a lightweight model. Then, we present a Progressive Meta-Pooling Learning (PMPL) strategy for the parameterized spatial enhancer to acquire a suitable receptive field size. The results on the ImageNet dataset demonstrate that MobileNetV2 using Meta-Pooling achieves top1 accuracy of 74.6\%, which outperforms MobileNetV2 by 2.3\%.
RD-NAS: Enhancing One-shot Supernet Ranking Ability via Ranking Distillation from Zero-cost Proxies
Jan 24, 2023



Neural architecture search (NAS) has made tremendous progress in the automatic design of effective neural network structures but suffers from a heavy computational burden. One-shot NAS significantly alleviates the burden through weight sharing and improves computational efficiency. Zero-shot NAS further reduces the cost by predicting the performance of the network from its initial state, which conducts no training. Both methods aim to distinguish between "good" and "bad" architectures, i.e., ranking consistency of predicted and true performance. In this paper, we propose Ranking Distillation one-shot NAS (RD-NAS) to enhance ranking consistency, which utilizes zero-cost proxies as the cheap teacher and adopts the margin ranking loss to distill the ranking knowledge. Specifically, we propose a margin subnet sampler to distill the ranking knowledge from zero-shot NAS to one-shot NAS by introducing Group distance as margin. Our evaluation of the NAS-Bench-201 and ResNet-based search space demonstrates that RD-NAS achieve 10.7\% and 9.65\% improvements in ranking ability, respectively. Our codes are available at https://github.com/pprp/CVPR2022-NAS-competition-Track1-3th-solution
Unsupervised Knowledge Graph Construction and Event-centric Knowledge Infusion for Scientific NLI
Oct 28, 2022



With the advance of natural language inference (NLI), a rising demand for NLI is to handle scientific texts. Existing methods depend on pre-trained models (PTM) which lack domain-specific knowledge. To tackle this drawback, we introduce a scientific knowledge graph to generalize PTM to scientific domain. However, existing knowledge graph construction approaches suffer from some drawbacks, i.e., expensive labeled data, failure to apply in other domains, long inference time and difficulty extending to large corpora. Therefore, we propose an unsupervised knowledge graph construction method to build a scientific knowledge graph (SKG) without any labeled data. Moreover, to alleviate noise effect from SKG and complement knowledge in sentences better, we propose an event-centric knowledge infusion method to integrate external knowledge into each event that is a fine-grained semantic unit in sentences. Experimental results show that our method achieves state-of-the-art performance and the effectiveness and reliability of SKG.
Radar-enabled ambient backscatter communication
Aug 15, 2022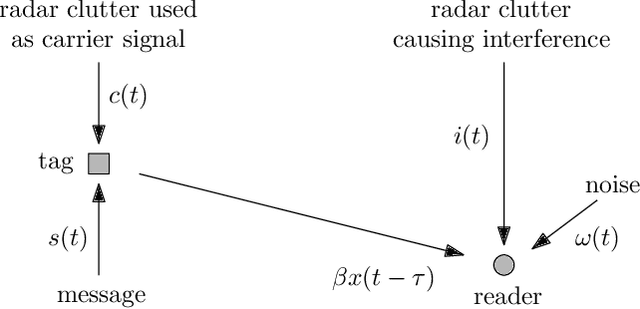
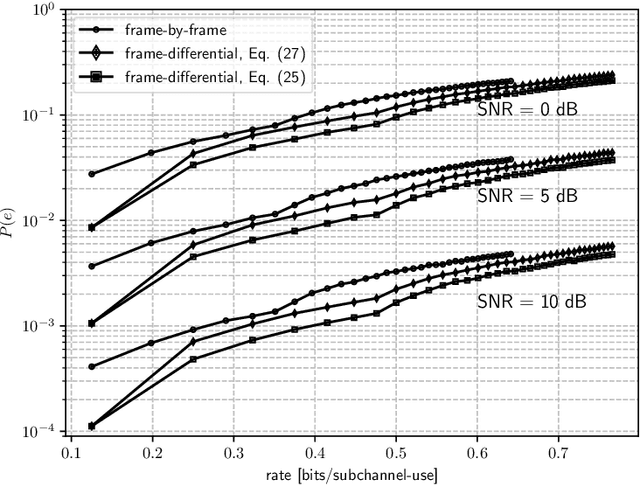
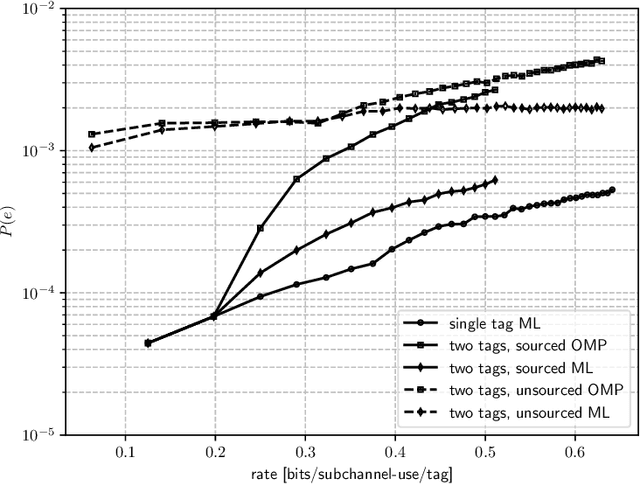
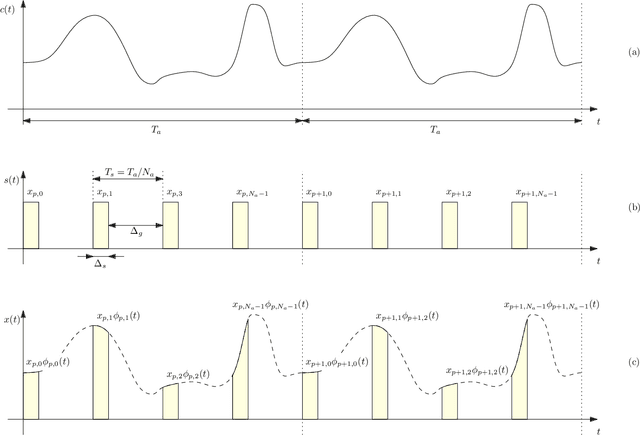
In this work, we exploit the radar clutter (i.e., the ensemble of echoes generated by the terrain and/or the surrounding objects in response to the signal emitted by a radar transmitter) as a carrier signal to enable an ambient basckscatter communication from a source (tag) to a destination (reader). Upon deriving a convenient signal model, we exploit the fact that the radar clutter is periodic over time scales shorter than the coherence time of the environment, because so is the radar excitation, to distinguish the message sent by the tag from the superimposed ambient interference. In particular, we propose two encoding/decoding schemes that do not require any coordination with the radar transmitter or knowledge of the radar waveform. Different tradeoffs in terms of transmission rate and error probability can be obtained upon changing the control signal driving the tag switch or the adopted encoding rule; also, multiple tags can be accommodated with either a sourced or an unsourced multiple access strategy.