 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuiding Perception-Reasoning Closer to Human in Blind Image Quality Assessment
Dec 18, 2025Humans assess image quality through a perception-reasoning cascade, integrating sensory cues with implicit reasoning to form self-consistent judgments. In this work, we investigate how a model can acquire both human-like and self-consistent reasoning capability for blind image quality assessment (BIQA). We first collect human evaluation data that capture several aspects of human perception-reasoning pipeline. Then, we adopt reinforcement learning, using human annotations as reward signals to guide the model toward human-like perception and reasoning. To enable the model to internalize self-consistent reasoning capability, we design a reward that drives the model to infer the image quality purely from self-generated descriptions. Empirically, our approach achieves score prediction performance comparable to state-of-the-art BIQA systems under general metrics, including Pearson and Spearman correlation coefficients. In addition to the rating score, we assess human-model alignment using ROUGE-1 to measure the similarity between model-generated and human perception-reasoning chains. On over 1,000 human-annotated samples, our model reaches a ROUGE-1 score of 0.512 (cf. 0.443 for baseline), indicating substantial coverage of human explanations and marking a step toward human-like interpretable reasoning in BIQA.
Language Model-Driven Unsupervised Neural Machine Translation
Nov 10, 2019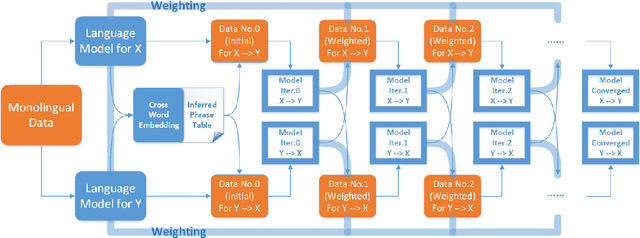
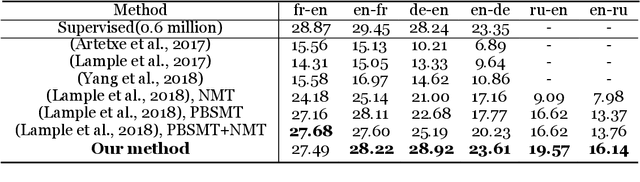
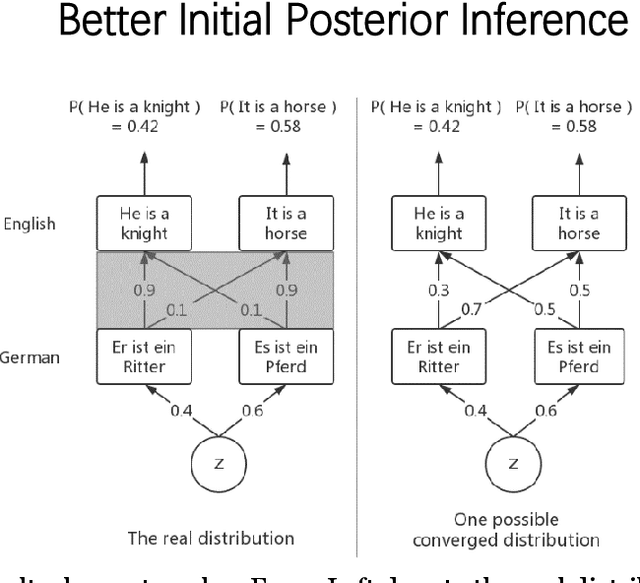
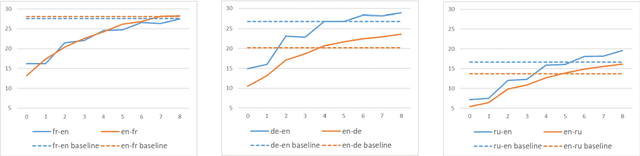
Unsupervised neural machine translation(NMT) is associated with noise and errors in synthetic data when executing vanilla back-translations. Here, we explicitly exploits language model(LM) to drive construction of an unsupervised NMT system. This features two steps. First, we initialize NMT models using synthetic data generated via temporary statistical machine translation(SMT). Second, unlike vanilla back-translation, we formulate a weight function, that scores synthetic data at each step of subsequent iterative training; this allows unsupervised training to an improved outcome. We present the detailed mathematical construction of our method. Experimental WMT2014 English-French, and WMT2016 English-German and English-Russian translation tasks revealed that our method outperforms the best prior systems by more than 3 BLEU points.