 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmortized Filtering and Smoothing with Conditional Normalizing Flows
Apr 08, 2026Bayesian filtering and smoothing for high-dimensional nonlinear dynamical systems are fundamental yet challenging problems in many areas of science and engineering. In this work, we propose AFSF, a unified amortized framework for filtering and smoothing with conditional normalizing flows. The core idea is to encode each observation history into a fixed-dimensional summary statistic and use this shared representation to learn both a forward flow for the filtering distribution and a backward flow for the backward transition kernel. Specifically, a recurrent encoder maps each observation history to a fixed-dimensional summary statistic whose dimension does not depend on the length of the time series. Conditioned on this shared summary statistic, the forward flow approximates the filtering distribution, while the backward flow approximates the backward transition kernel. The smoothing distribution over an entire trajectory is then recovered by combining the terminal filtering distribution with the learned backward flow through the standard backward recursion. By learning the underlying temporal evolution structure, AFSF also supports extrapolation beyond the training horizon. Moreover, by coupling the two flows through shared summary statistics, AFSF induces an implicit regularization across latent state trajectories and improves trajectory-level smoothing. In addition, we develop a flow-based particle filtering variant that provides an alternative filtering procedure and enables ESS-based diagnostics when explicit model factors are available. Numerical experiments demonstrate that AFSF provides accurate approximations of both filtering distributions and smoothing paths.
LVM-GP: Uncertainty-Aware PDE Solver via coupling latent variable model and Gaussian process
Jul 30, 2025We propose a novel probabilistic framework, termed LVM-GP, for uncertainty quantification in solving forward and inverse partial differential equations (PDEs) with noisy data. The core idea is to construct a stochastic mapping from the input to a high-dimensional latent representation, enabling uncertainty-aware prediction of the solution. Specifically, the architecture consists of a confidence-aware encoder and a probabilistic decoder. The encoder implements a high-dimensional latent variable model based on a Gaussian process (LVM-GP), where the latent representation is constructed by interpolating between a learnable deterministic feature and a Gaussian process prior, with the interpolation strength adaptively controlled by a confidence function learned from data. The decoder defines a conditional Gaussian distribution over the solution field, where the mean is predicted by a neural operator applied to the latent representation, allowing the model to learn flexible function-to-function mapping. Moreover, physical laws are enforced as soft constraints in the loss function to ensure consistency with the underlying PDE structure. Compared to existing approaches such as Bayesian physics-informed neural networks (B-PINNs) and deep ensembles, the proposed framework can efficiently capture functional dependencies via merging a latent Gaussian process and neural operator, resulting in competitive predictive accuracy and robust uncertainty quantification. Numerical experiments demonstrate the effectiveness and reliability of the method.
Integral regularization PINNs for evolution equations
Mar 31, 2025Evolution equations, including both ordinary differential equations (ODEs) and partial differential equations (PDEs), play a pivotal role in modeling dynamic systems. However, achieving accurate long-time integration for these equations remains a significant challenge. While physics-informed neural networks (PINNs) provide a mesh-free framework for solving PDEs, they often suffer from temporal error accumulation, which limits their effectiveness in capturing long-time behaviors. To alleviate this issue, we propose integral regularization PINNs (IR-PINNs), a novel approach that enhances temporal accuracy by incorporating an integral-based residual term into the loss function. This method divides the entire time interval into smaller sub-intervals and enforces constraints over these sub-intervals, thereby improving the resolution and correlation of temporal dynamics. Furthermore, IR-PINNs leverage adaptive sampling to dynamically refine the distribution of collocation points based on the evolving solution, ensuring higher accuracy in regions with sharp gradients or rapid variations. Numerical experiments on benchmark problems demonstrate that IR-PINNs outperform original PINNs and other state-of-the-art methods in capturing long-time behaviors, offering a robust and accurate solution for evolution equations.
Wearable intelligent throat enables natural speech in stroke patients with dysarthria
Nov 28, 2024



Wearable silent speech systems hold significant potential for restoring communication in patients with speech impairments. However, seamless, coherent speech remains elusive, and clinical efficacy is still unproven. Here, we present an AI-driven intelligent throat (IT) system that integrates throat muscle vibrations and carotid pulse signal sensors with large language model (LLM) processing to enable fluent, emotionally expressive communication. The system utilizes ultrasensitive textile strain sensors to capture high-quality signals from the neck area and supports token-level processing for real-time, continuous speech decoding, enabling seamless, delay-free communication. In tests with five stroke patients with dysarthria, IT's LLM agents intelligently corrected token errors and enriched sentence-level emotional and logical coherence, achieving low error rates (4.2% word error rate, 2.9% sentence error rate) and a 55% increase in user satisfaction. This work establishes a portable, intuitive communication platform for patients with dysarthria with the potential to be applied broadly across different neurological conditions and in multi-language support systems.
A hybrid FEM-PINN method for time-dependent partial differential equations
Sep 04, 2024



In this work, we present a hybrid numerical method for solving evolution partial differential equations (PDEs) by merging the time finite element method with deep neural networks. In contrast to the conventional deep learning-based formulation where the neural network is defined on a spatiotemporal domain, our methodology utilizes finite element basis functions in the time direction where the space-dependent coefficients are defined as the output of a neural network. We then apply the Galerkin or collocation projection in the time direction to obtain a system of PDEs for the space-dependent coefficients which is approximated in the framework of PINN. The advantages of such a hybrid formulation are twofold: statistical errors are avoided for the integral in the time direction, and the neural network's output can be regarded as a set of reduced spatial basis functions. To further alleviate the difficulties from high dimensionality and low regularity, we have developed an adaptive sampling strategy that refines the training set. More specifically, we use an explicit density model to approximate the distribution induced by the PDE residual and then augment the training set with new time-dependent random samples given by the learned density model. The effectiveness and efficiency of our proposed method have been demonstrated through a series of numerical experiments.
MC-Nonlocal-PINNs: handling nonlocal operators in PINNs via Monte Carlo sampling
Dec 26, 2022We propose, Monte Carlo Nonlocal physics-informed neural networks (MC-Nonlocal-PINNs), which is a generalization of MC-fPINNs in \cite{guo2022monte}, for solving general nonlocal models such as integral equations and nonlocal PDEs. Similar as in MC-fPINNs, our MC-Nonlocal-PINNs handle the nonlocal operators in a Monte Carlo way, resulting in a very stable approach for high dimensional problems. We present a variety of test problems, including high dimensional Volterra type integral equations, hypersingular integral equations and nonlocal PDEs, to demonstrate the effectiveness of our approach.
Gradient-enhanced deep neural network approximations
Nov 08, 2022We propose in this work the gradient-enhanced deep neural networks (DNNs) approach for function approximations and uncertainty quantification. More precisely, the proposed approach adopts both the function evaluations and the associated gradient information to yield enhanced approximation accuracy. In particular, the gradient information is included as a regularization term in the gradient-enhanced DNNs approach, for which we present similar posterior estimates (by the two-layer neural networks) as those in the path-norm regularized DNNs approximations. We also discuss the application of this approach to gradient-enhanced uncertainty quantification, and present several numerical experiments to show that the proposed approach can outperform the traditional DNNs approach in many cases of interests.
Solving time dependent Fokker-Planck equations via temporal normalizing flow
Dec 28, 2021
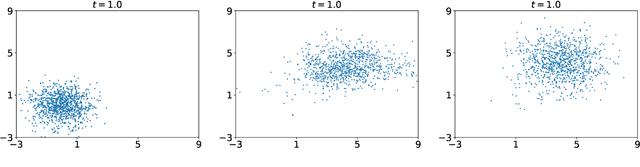
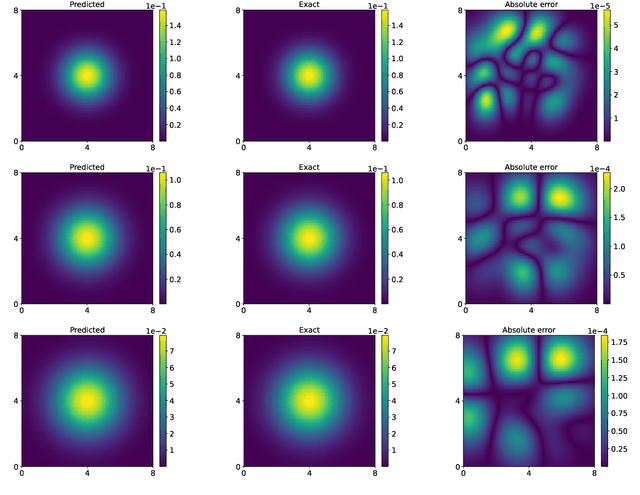
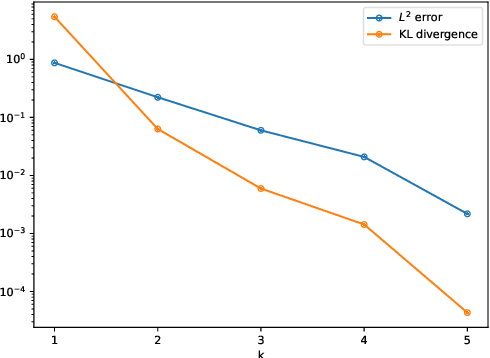
In this work, we propose an adaptive learning approach based on temporal normalizing flows for solving time-dependent Fokker-Planck (TFP) equations. It is well known that solutions of such equations are probability density functions, and thus our approach relies on modelling the target solutions with the temporal normalizing flows. The temporal normalizing flow is then trained based on the TFP loss function, without requiring any labeled data. Being a machine learning scheme, the proposed approach is mesh-free and can be easily applied to high dimensional problems. We present a variety of test problems to show the effectiveness of the learning approach.
Robust Sparse Coding via Self-Paced Learning
Sep 10, 2017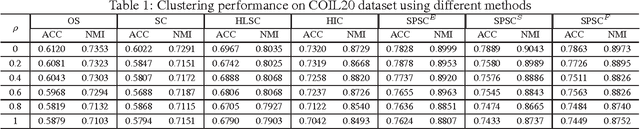

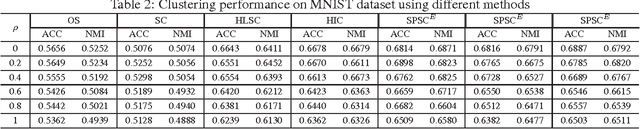
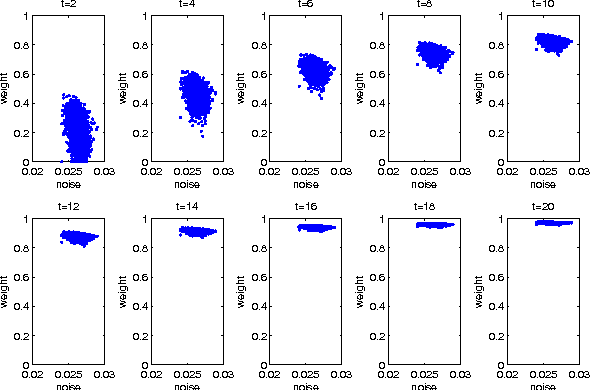
Sparse coding (SC) is attracting more and more attention due to its comprehensive theoretical studies and its excellent performance in many signal processing applications. However, most existing sparse coding algorithms are nonconvex and are thus prone to becoming stuck into bad local minima, especially when there are outliers and noisy data. To enhance the learning robustness, in this paper, we propose a unified framework named Self-Paced Sparse Coding (SPSC), which gradually include matrix elements into SC learning from easy to complex. We also generalize the self-paced learning schema into different levels of dynamic selection on samples, features and elements respectively. Experimental results on real-world data demonstrate the efficacy of the proposed algorithms.