 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViHOI: Human-Object Interaction Synthesis with Visual Priors
Mar 25, 2026Generating realistic and physically plausible 3D Human-Object Interactions (HOI) remains a key challenge in motion generation. One primary reason is that describing these physical constraints with words alone is difficult. To address this limitation, we propose a new paradigm: extracting rich interaction priors from easily accessible 2D images. Specifically, we introduce ViHOI, a novel framework that enables diffusion-based generative models to leverage rich, task-specific priors from 2D images to enhance generation quality. We utilize a large Vision-Language Model (VLM) as a powerful prior-extraction engine and adopt a layer-decoupled strategy to obtain visual and textual priors. Concurrently, we design a Q-Former-based adapter that compresses the VLM's high-dimensional features into compact prior tokens, which significantly facilitates the conditional training of our diffusion model. Our framework is trained on motion-rendered images from the dataset to ensure strict semantic alignment between visual inputs and motion sequences. During inference, it leverages reference images synthesized by a text-to-image generation model to improve generalization to unseen objects and interaction categories. Experimental results demonstrate that ViHOI achieves state-of-the-art performance, outperforming existing methods across multiple benchmarks and demonstrating superior generalization.
Reconstruction-Anchored Diffusion Model for Text-to-Motion Generation
Jan 21, 2026Diffusion models have seen widespread adoption for text-driven human motion generation and related tasks due to their impressive generative capabilities and flexibility. However, current motion diffusion models face two major limitations: a representational gap caused by pre-trained text encoders that lack motion-specific information, and error propagation during the iterative denoising process. This paper introduces Reconstruction-Anchored Diffusion Model (RAM) to address these challenges. First, RAM leverages a motion latent space as intermediate supervision for text-to-motion generation. To this end, RAM co-trains a motion reconstruction branch with two key objective functions: self-regularization to enhance the discrimination of the motion space and motion-centric latent alignment to enable accurate mapping from text to the motion latent space. Second, we propose Reconstructive Error Guidance (REG), a testing-stage guidance mechanism that exploits the diffusion model's inherent self-correction ability to mitigate error propagation. At each denoising step, REG uses the motion reconstruction branch to reconstruct the previous estimate, reproducing the prior error patterns. By amplifying the residual between the current prediction and the reconstructed estimate, REG highlights the improvements in the current prediction. Extensive experiments demonstrate that RAM achieves significant improvements and state-of-the-art performance. Our code will be released.
LVM-GP: Uncertainty-Aware PDE Solver via coupling latent variable model and Gaussian process
Jul 30, 2025We propose a novel probabilistic framework, termed LVM-GP, for uncertainty quantification in solving forward and inverse partial differential equations (PDEs) with noisy data. The core idea is to construct a stochastic mapping from the input to a high-dimensional latent representation, enabling uncertainty-aware prediction of the solution. Specifically, the architecture consists of a confidence-aware encoder and a probabilistic decoder. The encoder implements a high-dimensional latent variable model based on a Gaussian process (LVM-GP), where the latent representation is constructed by interpolating between a learnable deterministic feature and a Gaussian process prior, with the interpolation strength adaptively controlled by a confidence function learned from data. The decoder defines a conditional Gaussian distribution over the solution field, where the mean is predicted by a neural operator applied to the latent representation, allowing the model to learn flexible function-to-function mapping. Moreover, physical laws are enforced as soft constraints in the loss function to ensure consistency with the underlying PDE structure. Compared to existing approaches such as Bayesian physics-informed neural networks (B-PINNs) and deep ensembles, the proposed framework can efficiently capture functional dependencies via merging a latent Gaussian process and neural operator, resulting in competitive predictive accuracy and robust uncertainty quantification. Numerical experiments demonstrate the effectiveness and reliability of the method.
Guiding Human-Object Interactions with Rich Geometry and Relations
Mar 26, 2025Human-object interaction (HOI) synthesis is crucial for creating immersive and realistic experiences for applications such as virtual reality. Existing methods often rely on simplified object representations, such as the object's centroid or the nearest point to a human, to achieve physically plausible motions. However, these approaches may overlook geometric complexity, resulting in suboptimal interaction fidelity. To address this limitation, we introduce ROG, a novel diffusion-based framework that models the spatiotemporal relationships inherent in HOIs with rich geometric detail. For efficient object representation, we select boundary-focused and fine-detail key points from the object mesh, ensuring a comprehensive depiction of the object's geometry. This representation is used to construct an interactive distance field (IDF), capturing the robust HOI dynamics. Furthermore, we develop a diffusion-based relation model that integrates spatial and temporal attention mechanisms, enabling a better understanding of intricate HOI relationships. This relation model refines the generated motion's IDF, guiding the motion generation process to produce relation-aware and semantically aligned movements. Experimental evaluations demonstrate that ROG significantly outperforms state-of-the-art methods in the realism and semantic accuracy of synthesized HOIs.
Flow-based linear embedding for Bayesian filtering of nonlinear stochastic dynamical systems
Feb 22, 2025



Bayesian filtering for high-dimensional nonlinear stochastic dynamical systems is a fundamental yet challenging problem in many fields of science and engineering. Existing methods face significant obstacles: Gaussian-based filters struggle with non-Gaussian distributions, sequential Monte Carlo methods are computationally intensive and prone to particle degeneracy in high dimensions, and deep learning approaches often fail to balance accuracy and efficiency in complex filtering tasks. To address these challenges, we propose a flow-based Bayesian filter (FBF) that integrates normalizing flows to construct a latent linear state-space model with Gaussian filtering distributions. This framework enables efficient density estimation and sampling through invertible transformations provided by normalizing flows, which can be learned directly from data, thereby eliminating the need for prior knowledge of system dynamics or observation models. Numerical experiments demonstrate the advantages of FBF in terms of both accuracy and efficiency.
Energy based diffusion generator for efficient sampling of Boltzmann distributions
Jan 04, 2024We introduce a novel sampler called the energy based diffusion generator for generating samples from arbitrary target distributions. The sampling model employs a structure similar to a variational autoencoder, utilizing a decoder to transform latent variables from a simple distribution into random variables approximating the target distribution, and we design an encoder based on the diffusion model. Leveraging the powerful modeling capacity of the diffusion model for complex distributions, we can obtain an accurate variational estimate of the Kullback-Leibler divergence between the distributions of the generated samples and the target. Moreover, we propose a decoder based on generalized Hamiltonian dynamics to further enhance sampling performance. Through empirical evaluation, we demonstrate the effectiveness of our method across various complex distribution functions, showcasing its superiority compared to existing methods.
IB-UQ: Information bottleneck based uncertainty quantification for neural function regression and neural operator learning
Feb 07, 2023In this paper, a novel framework is established for uncertainty quantification via information bottleneck (IB-UQ) for scientific machine learning tasks, including deep neural network (DNN) regression and neural operator learning (DeepONet). Specifically, we first employ the General Incompressible-Flow Networks (GIN) model to learn a "wide" distribution fromnoisy observation data. Then, following the information bottleneck objective, we learn a stochastic map from input to some latent representation that can be used to predict the output. A tractable variational bound on the IB objective is constructed with a normalizing flow reparameterization. Hence, we can optimize the objective using the stochastic gradient descent method. IB-UQ can provide both mean and variance in the label prediction by explicitly modeling the representation variables. Compared to most DNN regression methods and the deterministic DeepONet, the proposed model can be trained on noisy data and provide accurate predictions with reliable uncertainty estimates on unseen noisy data. We demonstrate the capability of the proposed IB-UQ framework via several representative examples, including discontinuous function regression, real-world dataset regression and learning nonlinear operators for diffusion-reaction partial differential equation.
Monte Carlo PINNs: deep learning approach for forward and inverse problems involving high dimensional fractional partial differential equations
Mar 16, 2022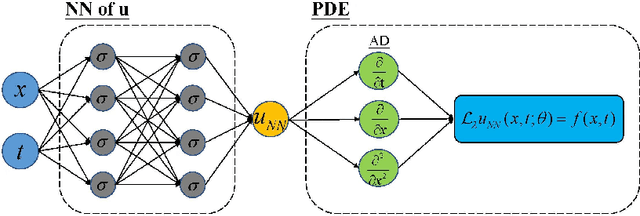

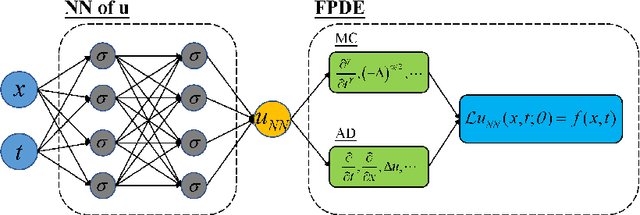
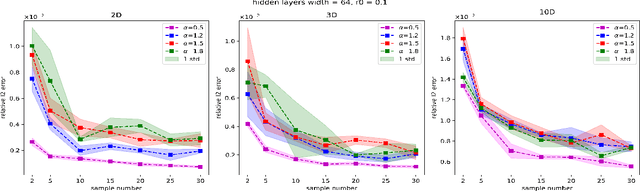
We introduce a sampling based machine learning approach, Monte Carlo physics informed neural networks (MC-PINNs), for solving forward and inverse fractional partial differential equations (FPDEs). As a generalization of physics informed neural networks (PINNs), our method relies on deep neural network surrogates in addition to a stochastic approximation strategy for computing the fractional derivatives of the DNN outputs. A key ingredient in our MC-PINNs is to construct an unbiased estimation of the physical soft constraints in the loss function. Our directly sampling approach can yield less overall computational cost compared to fPINNs proposed in \cite{pang2019fpinns} and thus provide an opportunity for solving high dimensional fractional PDEs. We validate the performance of MC-PINNs method via several examples that include high dimensional integral fractional Laplacian equations, parametric identification of time-space fractional PDEs, and fractional diffusion equation with random inputs. The results show that MC-PINNs is flexible and promising to tackle high-dimensional FPDEs.
Uncertainty Quantification in Scientific Machine Learning: Methods, Metrics, and Comparisons
Jan 19, 2022



Neural networks (NNs) are currently changing the computational paradigm on how to combine data with mathematical laws in physics and engineering in a profound way, tackling challenging inverse and ill-posed problems not solvable with traditional methods. However, quantifying errors and uncertainties in NN-based inference is more complicated than in traditional methods. This is because in addition to aleatoric uncertainty associated with noisy data, there is also uncertainty due to limited data, but also due to NN hyperparameters, overparametrization, optimization and sampling errors as well as model misspecification. Although there are some recent works on uncertainty quantification (UQ) in NNs, there is no systematic investigation of suitable methods towards quantifying the total uncertainty effectively and efficiently even for function approximation, and there is even less work on solving partial differential equations and learning operator mappings between infinite-dimensional function spaces using NNs. In this work, we present a comprehensive framework that includes uncertainty modeling, new and existing solution methods, as well as evaluation metrics and post-hoc improvement approaches. To demonstrate the applicability and reliability of our framework, we present an extensive comparative study in which various methods are tested on prototype problems, including problems with mixed input-output data, and stochastic problems in high dimensions. In the Appendix, we include a comprehensive description of all the UQ methods employed, which we will make available as open-source library of all codes included in this framework.
Normalizing field flows: Solving forward and inverse stochastic differential equations using physics-informed flow models
Sep 07, 2021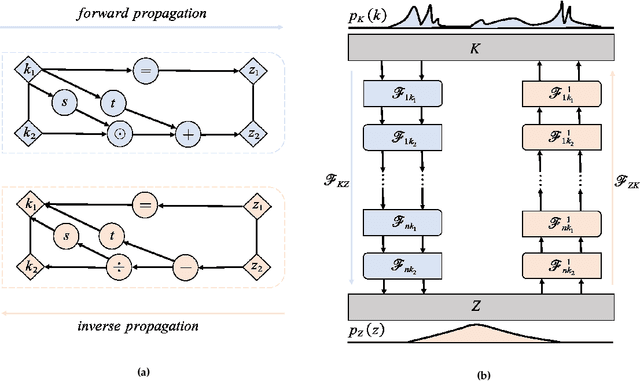
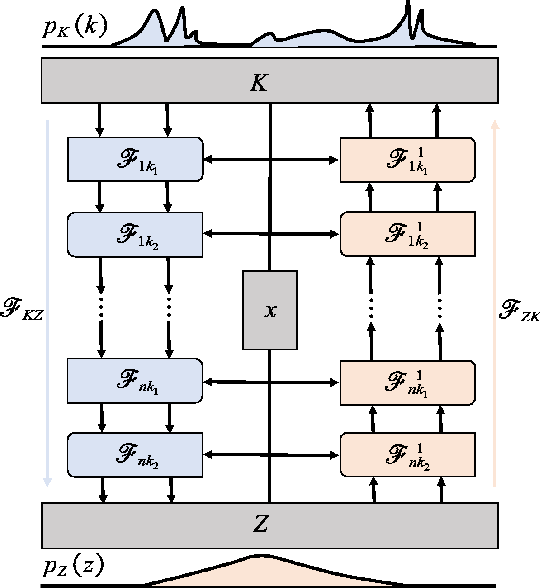
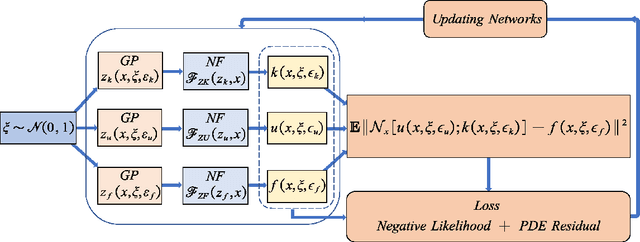
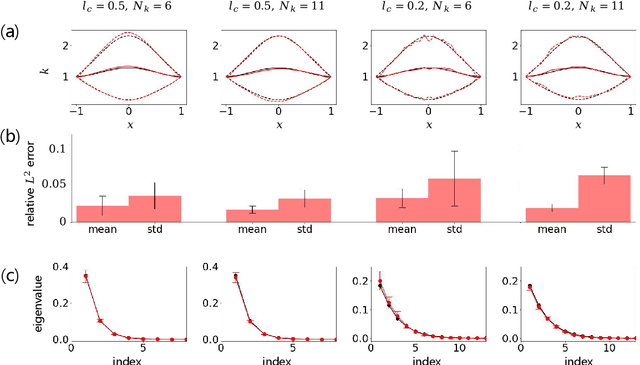
We introduce in this work the normalizing field flows (NFF) for learning random fields from scattered measurements. More precisely, we construct a bijective transformation (a normalizing flow characterizing by neural networks) between a Gaussian random field with the Karhunen-Lo\`eve (KL) expansion structure and the target stochastic field, where the KL expansion coefficients and the invertible networks are trained by maximizing the sum of the log-likelihood on scattered measurements. This NFF model can be used to solve data-driven forward, inverse, and mixed forward/inverse stochastic partial differential equations in a unified framework. We demonstrate the capability of the proposed NFF model for learning Non Gaussian processes and different types of stochastic partial differential equations.