 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple and Efficient Heterogeneous Graph Neural Network
Jul 06, 2022
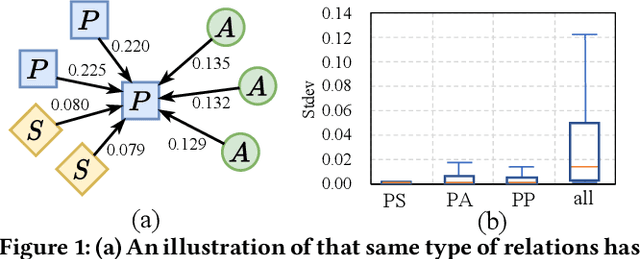
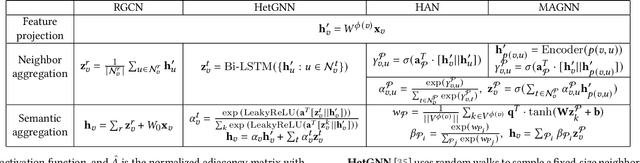
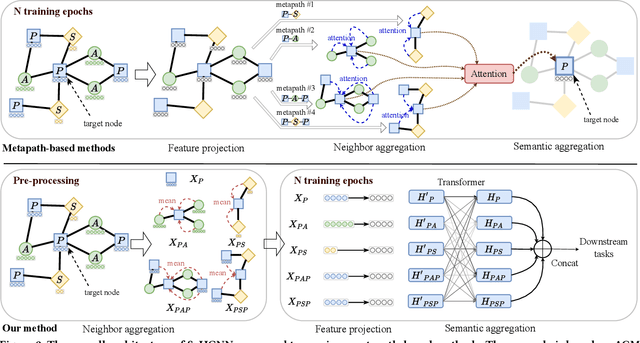
Heterogeneous graph neural networks (HGNNs) deliver the powerful capability to embed rich structural and semantic information of a heterogeneous graph into low-dimensional node representations. Existing HGNNs usually learn to embed information using hierarchy attention mechanism and repeated neighbor aggregation, suffering from unnecessary complexity and redundant computation. This paper proposes Simple and Efficient Heterogeneous Graph Neural Network (SeHGNN) which reduces this excess complexity through avoiding overused node-level attention within the same relation and pre-computing the neighbor aggregation in the pre-processing stage. Unlike previous work, SeHGNN utilizes a light-weight parameter-free neighbor aggregator to learn structural information for each metapath, and a transformer-based semantic aggregator to combine semantic information across metapaths for the final embedding of each node. As a result, SeHGNN offers the simple network structure, high prediction accuracy, and fast training speed. Extensive experiments on five real-world heterogeneous graphs demonstrate the superiority of SeHGNN over the state-of-the-arts on both the accuracy and training speed. Codes are available at https://github.com/ICT-GIMLab/SeHGNN.
Characterizing and Understanding Distributed GNN Training on GPUs
Apr 18, 2022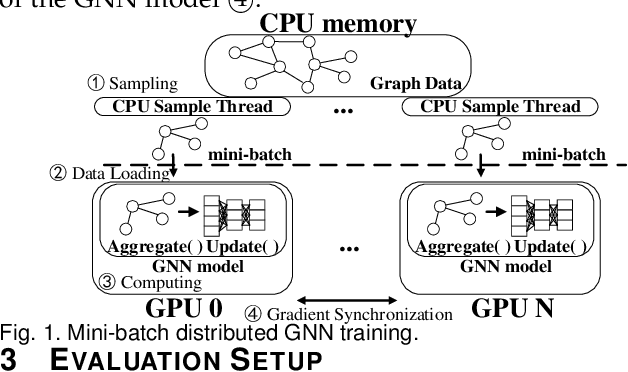
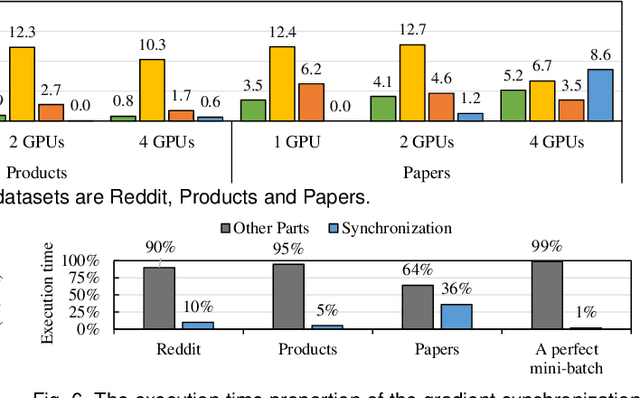
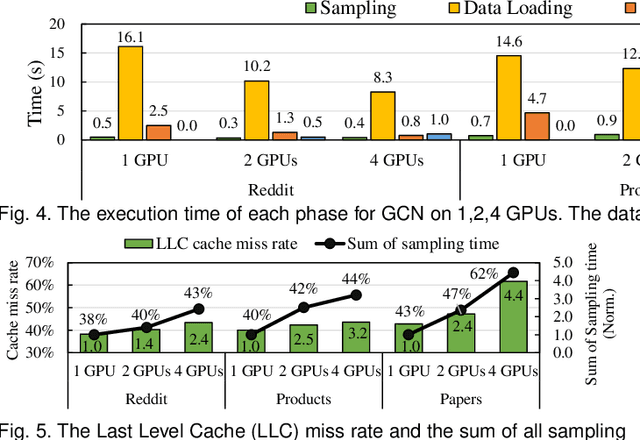
Graph neural network (GNN) has been demonstrated to be a powerful model in many domains for its effectiveness in learning over graphs. To scale GNN training for large graphs, a widely adopted approach is distributed training which accelerates training using multiple computing nodes. Maximizing the performance is essential, but the execution of distributed GNN training remains preliminarily understood. In this work, we provide an in-depth analysis of distributed GNN training on GPUs, revealing several significant observations and providing useful guidelines for both software optimization and hardware optimization.
Survey on Graph Neural Network Acceleration: An Algorithmic Perspective
Feb 10, 2022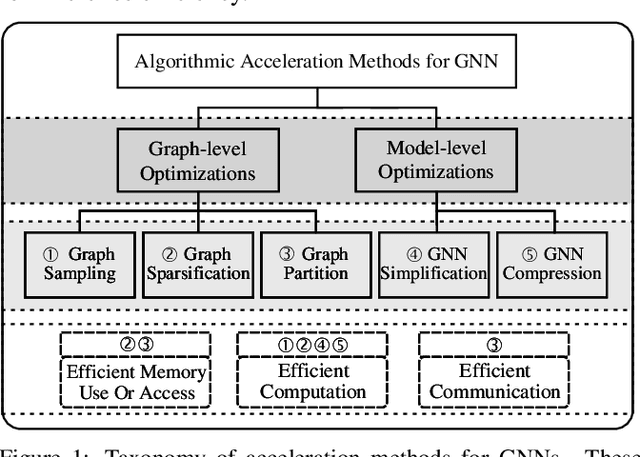
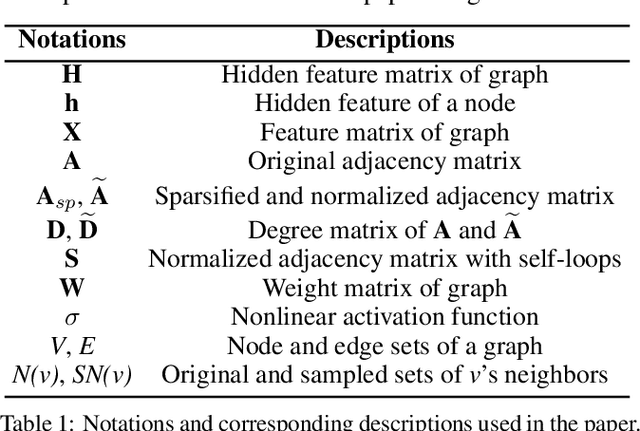
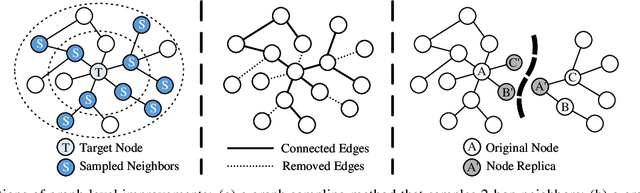

Graph neural networks (GNNs) have been a hot spot of recent research and are widely utilized in diverse applications. However, with the use of huger data and deeper models, an urgent demand is unsurprisingly made to accelerate GNNs for more efficient execution. In this paper, we provide a comprehensive survey on acceleration methods for GNNs from an algorithmic perspective. We first present a new taxonomy to classify existing acceleration methods into five categories. Based on the classification, we systematically discuss these methods and highlight their correlations. Next, we provide comparisons from aspects of the efficiency and characteristics of these methods. Finally, we suggest some promising prospects for future research.
GNNSampler: Bridging the Gap between Sampling Algorithms of GNN and Hardware
Aug 26, 2021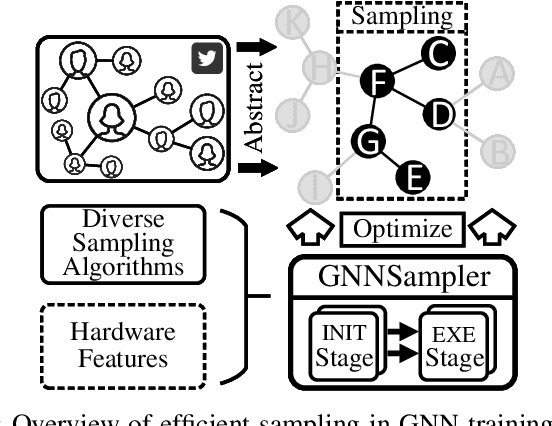
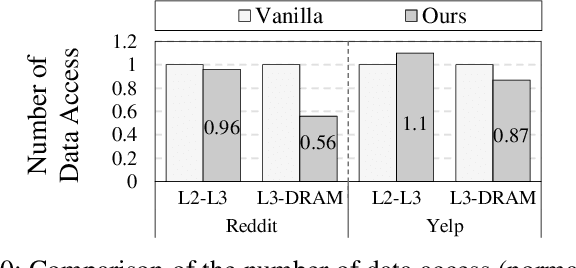
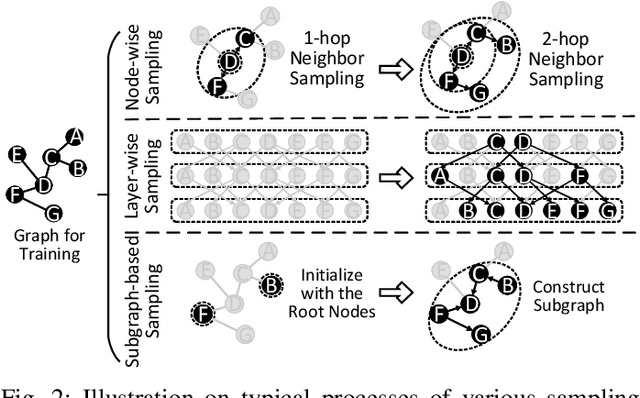

Sampling is a critical operation in the training of Graph Neural Network (GNN) that helps reduce the cost. Previous works have explored improving sampling algorithms through mathematical and statistical methods. However, there is a gap between sampling algorithms and hardware. Without consideration of hardware, algorithm designers merely optimize sampling at the algorithm level, missing the great potential of promoting the efficiency of existing sampling algorithms by leveraging hardware features. In this paper, we first propose a unified programming model for mainstream sampling algorithms, termed GNNSampler, covering the key processes for sampling algorithms in various categories. Second, we explore the data locality among nodes and their neighbors (i.e., the hardware feature) in real-world datasets for alleviating the irregular memory access in sampling. Third, we implement locality-aware optimizations in GNNSampler for diverse sampling algorithms to optimize the general sampling process in the training of GNN. Finally, we emphatically conduct experiments on large graph datasets to analyze the relevance between the training time, model accuracy, and hardware-level metrics, which helps achieve a good trade-off between time and accuracy in GNN training. Extensive experimental results show that our method is universal to mainstream sampling algorithms and reduces the training time of GNN (range from 4.83% with layer-wise sampling to 44.92% with subgraph-based sampling) with comparable accuracy.
Tackling Variabilities in Autonomous Driving
Apr 21, 2021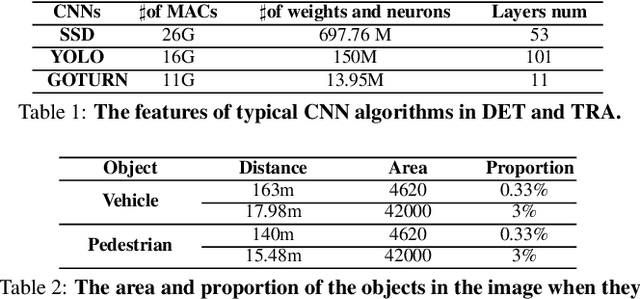
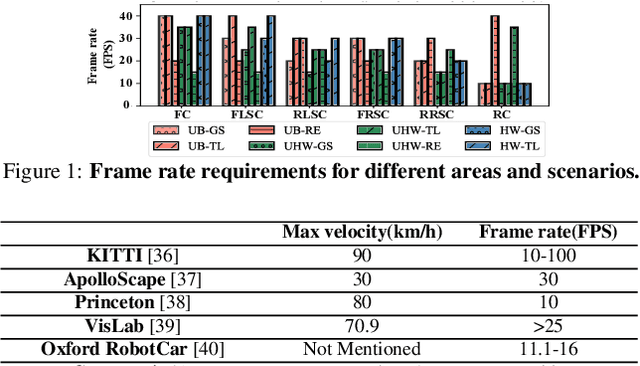
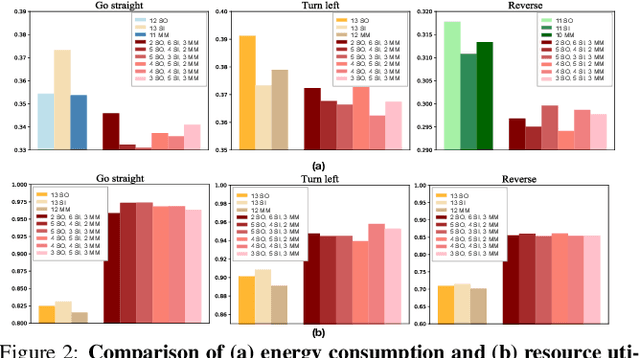
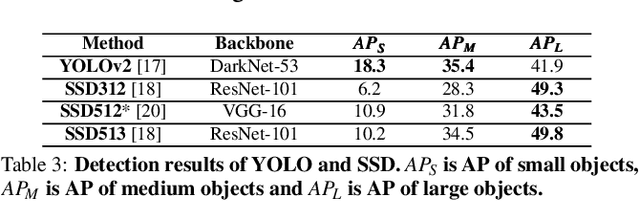
The state-of-the-art driving automation system demands extreme computational resources to meet rigorous accuracy and latency requirements. Though emerging driving automation computing platforms are based on ASIC to provide better performance and power guarantee, building such an accelerator-based computing platform for driving automation still present challenges. First, the workloads mix and performance requirements exposed to driving automation system present significant variability. Second, with more cameras/sensors integrated in a future fully autonomous driving vehicle, a heterogeneous multi-accelerator architecture substrate is needed that requires a design space exploration for a new form of parallelism. In this work, we aim to extensively explore the above system design challenges and these challenges motivate us to propose a comprehensive framework that synergistically handles the heterogeneous hardware accelerator design principles, system design criteria, and task scheduling mechanism. Specifically, we propose a novel heterogeneous multi-core AI accelerator (HMAI) to provide the hardware substrate for the driving automation tasks with variability. We also define system design criteria to better utilize hardware resources and achieve increased throughput while satisfying the performance and energy restrictions. Finally, we propose a deep reinforcement learning (RL)-based task scheduling mechanism FlexAI, to resolve task mapping issue. Experimental results show that with FlexAI scheduling, basically 100% tasks in each driving route can be processed by HMAI within their required period to ensure safety, and FlexAI can also maximally reduce the breaking distance up to 96% as compared to typical heuristics and guided random-search-based algorithms.
Sampling methods for efficient training of graph convolutional networks: A survey
Mar 10, 2021
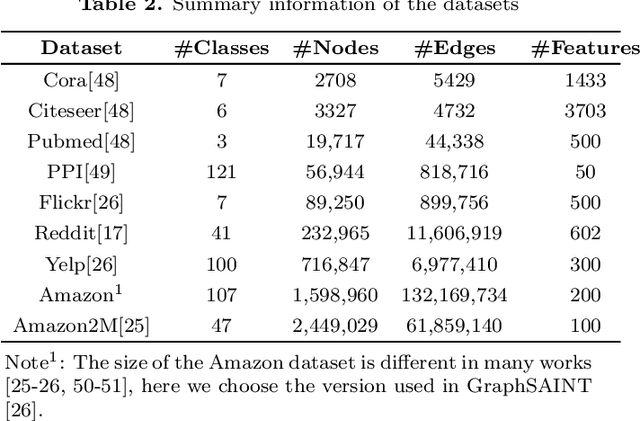


Graph Convolutional Networks (GCNs) have received significant attention from various research fields due to the excellent performance in learning graph representations. Although GCN performs well compared with other methods, it still faces challenges. Training a GCN model for large-scale graphs in a conventional way requires high computation and memory costs. Therefore, motivated by an urgent need in terms of efficiency and scalability in training GCN, sampling methods are proposed and achieve a significant effect. In this paper, we categorize sampling methods based on the sampling mechanisms and provide a comprehensive survey of sampling methods for efficient training of GCN. To highlight the characteristics and differences of sampling methods, we present a detailed comparison within each category and further give an overall comparative analysis for the sampling methods in all categories. Finally, we discuss some challenges and future research directions of the sampling methods.
Video Face Recognition System: RetinaFace-mnet-faster and Secondary Search
Sep 29, 2020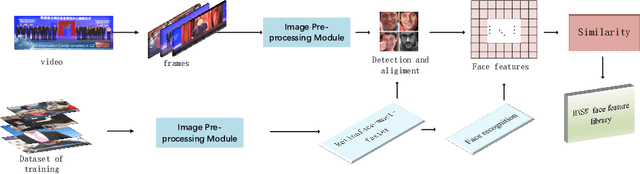

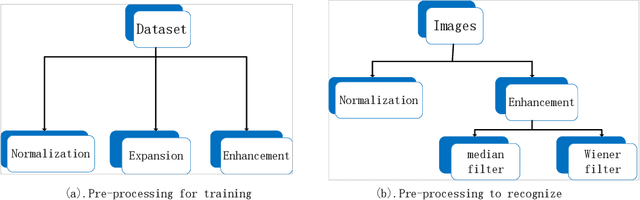

Face recognition is widely used in the scene. However, different visual environments require different methods, and face recognition has a difficulty in complex environments. Therefore, this paper mainly experiments complex faces in the video. First, we design an image pre-processing module for fuzzy scene or under-exposed faces to enhance images. Our experimental results demonstrate that effective images pre-processing improves the accuracy of 0.11%, 0.2% and 1.4% on LFW, WIDER FACE and our datasets, respectively. Second, we propose RetinacFace-mnet-faster for detection and a confidence threshold specification for face recognition, reducing the lost rate. Our experimental results show that our RetinaFace-mnet-faster for 640*480 resolution on the Tesla P40 and single-thread improve speed of 16.7% and 70.2%, respectively. Finally, we design secondary search mechanism with HNSW to improve performance. Ours is suitable for large-scale datasets, and experimental results show that our method is 82% faster than the violent retrieval for the single-frame detection.
Top-Related Meta-Learning Method for Few-Shot Detection
Jul 27, 2020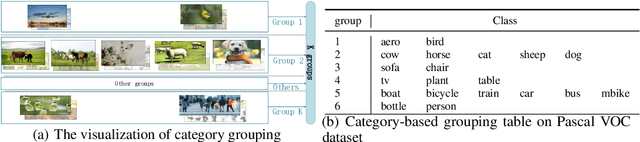
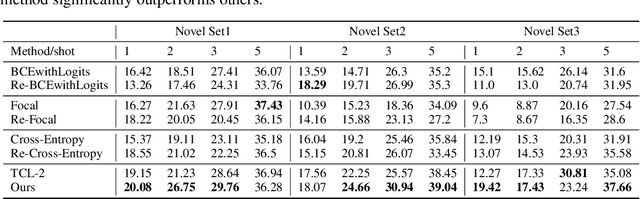
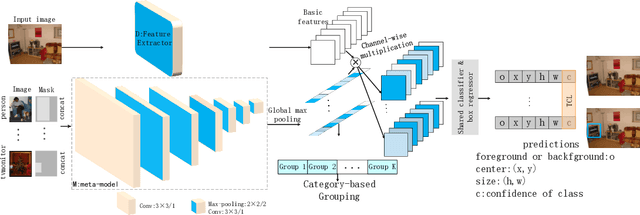

Many meta-learning methods are proposed for few-shot detection. However, previous most methods have two main problems, strong bias between all classes, and poor classification for few-shot classes. Previous works mainly depend on additional datasets and sub-module to alleviate these issues. However, they require more cost. In this paper, we find that the main challenge lies on imbalance between the examples, and poor shared distribution of class-based meta-features. Therefore, we propose a TCL for classification task and a category-based grouping mechanism. The TCL exploits the classification score of true-label class and the classification score of the most similar class to improve detection performance on few-shot classes. According to appearance and environment, the category-based grouping mechanism groups categories into different groupings to promote different similar semantic features more compact, alleviating the strong bias problem and further improving few-shot detection APs. The whole training consists of the base model and the fine-tuning phase. During training detection model, the category-related meta-features are regarded as the weights of the detection layer, exploiting the meta-features with a shared distribution between categories within a group to improve the detection performance. According to grouping mechanism, we group the meta-features vectors, so that the distribution difference between groups is obvious, and the one within each group is less. Experimental results on Pascal VOC dataset demonstrate that ours which combines the TCL with category-based grouping significantly outperforms previous state-of-the-art methods for 1, 2-shot detection, and obtains detection APs of almost 30% for 3-shot detection.
Pixel-Semantic Revise of Position Learning A One-Stage Object Detector with A Shared Encoder-Decoder
Jan 04, 2020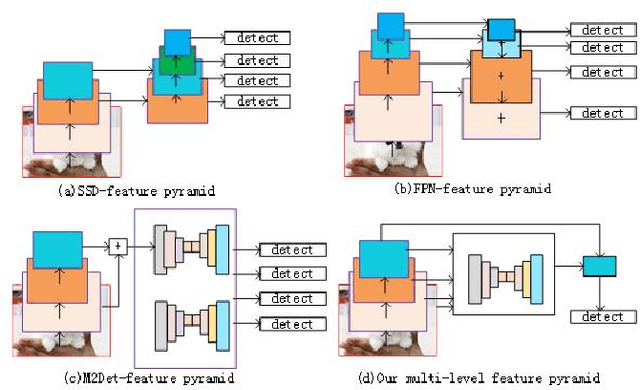
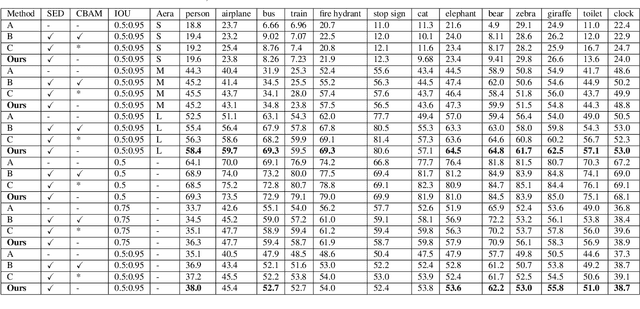
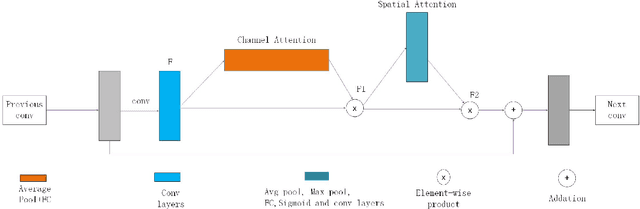
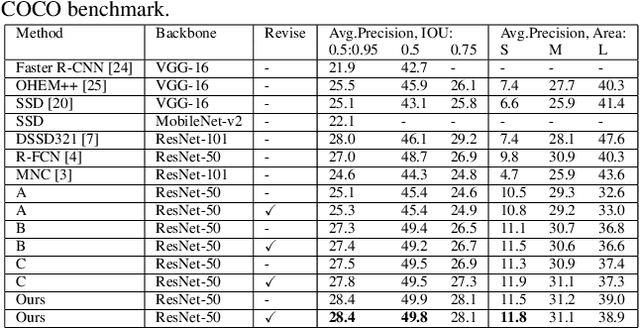
We analyze that different methods based channel or position attention mechanism give rise to different performance on scale, and some of state-of-the-art detectors applying feature pyramid are integrated with various variants convolutions with many mechanisms to enhance information, resulting in increasing runtime. This work addresses the problem by constructing an anchor-free detector with shared module consisting of encoder and decoder with attention mechanism. First, we consider different level features from backbone (e.g., ResNet-50) as the base features. Second, we feed the feature into a simple block, rather than various complex operations.Then, location and classification tasks are obtained by the detector head and classifier, respectively. At the same time, we use the semantic information to revise geometry locations. Additionally, we show that the detector is a pixel-semantic revise of position, universal, effective and simple to detect, especially, large-scale objects. More importantly, this work compares different feature processing (e.g.,mean, maximum or minimum) performance across channel. Finally,we present that our method improves detection accuracy by 3.8 AP compared to state-of-the-art MNC based ResNet-101 on the standard MSCOCO baseline.
Utilizing the Instability in Weakly Supervised Object Detection
Jun 14, 2019
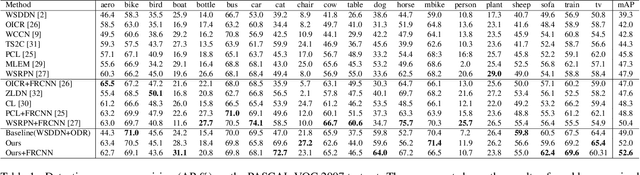
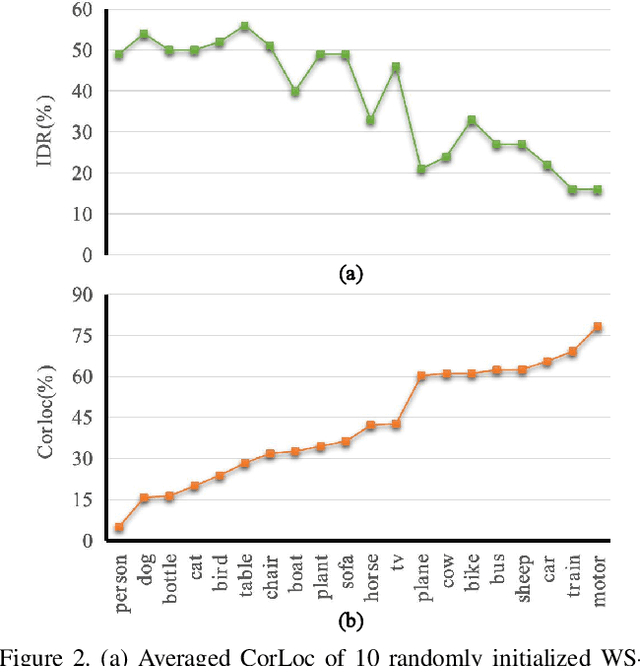
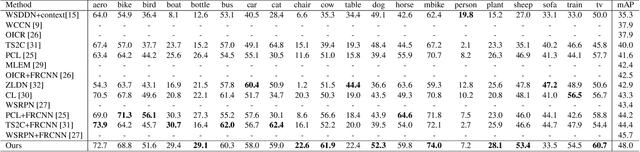
Weakly supervised object detection (WSOD) focuses on training object detector with only image-level annotations, and is challenging due to the gap between the supervision and the objective. Most of existing approaches model WSOD as a multiple instance learning (MIL) problem. However, we observe that the result of MIL based detector is unstable, i.e., the most confident bounding boxes change significantly when using different initializations. We quantitatively demonstrate the instability by introducing a metric to measure it, and empirically analyze the reason of instability. Although the instability seems harmful for detection task, we argue that it can be utilized to improve the performance by fusing the results of differently initialized detectors. To implement this idea, we propose an end-to-end framework with multiple detection branches, and introduce a simple fusion strategy. We further propose an orthogonal initialization method to increase the difference between detection branches. By utilizing the instability, we achieve 52.6% and 48.0% mAP on the challenging PASCAL VOC 2007 and 2012 datasets, which are both the new state-of-the-arts.