 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction-Effect Memory Pretraining for Robot Manipulation
Jun 10, 2026We present AEM, an Action-Effect Memory pretraining framework for robot manipulation that learns compact temporal representations from vision-action history. Unlike prior robot representation pretraining methods that mainly focus on single-frame visual encoding, AEM targets the temporal nature of manipulation, where the current observation alone is often insufficient under partial observability. AEM models manipulation as an action-driven interaction process by interleaving visual and action features and applying masked modeling to recover missing content from incomplete histories, thereby learning action-conditioned state evolution. The Mamba-encoded output of the final vision token is used as a compact history representation, serving as the global context for decoding and downstream control. This design preserves a single-vector temporal bottleneck while keeping inference efficient. We evaluate AEM with Diffusion Policy and Flow Policy. AEM consistently improves manipulation performance in both simulation and real-world settings, outperforming baselines across clean scenes, cluttered and random scenes, and non-Markovian tasks. Ablation studies further show that history-aware pretraining surpasses single-frame pretraining and direct frame stacking, while reducing inference latency and computational cost.
Drift-Aware Online Dynamic Learning for Nonstationary Multivariate Time Series: Application to Sintering Quality Prediction
Apr 10, 2026Accurate prediction of nonstationary multivariate time series remains a critical challenge in complex industrial systems such as iron ore sintering. In practice, pronounced concept drift compounded by significant label verification latency rapidly degrades the performance of offline-trained models. Existing methods based on static architectures or passive update strategies struggle to simultaneously extract multi-scale spatiotemporal features and overcome the stability-plasticity dilemma without immediate supervision. To address these limitations, a Drift-Aware Multi-Scale Dynamic Learning (DA-MSDL) framework is proposed to maintain robust multi-output predictive performance via online adaptive mechanisms on nonstationary data streams. The framework employs a multi-scale bi-branch convolutional network as its backbone to disentangle local fluctuations from long-term trends, thereby enhancing representational capacity for complex dynamic patterns. To circumvent the label latency bottleneck, DA-MSDL leverages Maximum Mean Discrepancy (MMD) for unsupervised drift detection. By quantifying online statistical deviations in feature distributions, DA-MSDL proactively triggers model adaptation prior to inference. Furthermore, a drift-severity-guided hierarchical fine-tuning strategy is developed. Supported by prioritized experience replay from a dynamic memory queue, this approach achieves rapid distribution alignment while effectively mitigating catastrophic forgetting. Long-horizon experiments on real-world industrial sintering data and a public benchmark dataset demonstrate that DA-MSDL consistently outperforms representative baselines under severe concept drift. Exhibiting strong cross-domain generalization and predictive stability, the proposed framework provides an effective online dynamic learning paradigm for quality monitoring in nonstationary environments.
Auto-Configured Networks for Multi-Scale Multi-Output Time-Series Forecasting
Apr 08, 2026Industrial forecasting often involves multi-source asynchronous signals and multi-output targets, while deployment requires explicit trade-offs between prediction error and model complexity. Current practices typically fix alignment strategies or network designs, making it difficult to systematically co-design preprocessing, architecture, and hyperparameters in budget-limited training-based evaluations. To address this issue, we propose an auto-configuration framework that outputs a deployable Pareto set of forecasting models balancing error and complexity. At the model level, a Multi-Scale Bi-Branch Convolutional Neural Network (MS--BCNN) is developed, where short- and long-kernel branches capture local fluctuations and long-term trends, respectively, for multi-output regression. At the search level, we unify alignment operators, architectural choices, and training hyperparameters into a hierarchical-conditional mixed configuration space, and apply Player-based Hybrid Multi-Objective Evolutionary Algorithm (PHMOEA) to approximate the error--complexity Pareto frontier within a limited computational budget. Experiments on hierarchical synthetic benchmarks and a real-world sintering dataset demonstrate that our framework outperforms competitive baselines under the same budget and offers flexible deployment choices.
Multi-Task Genetic Algorithm with Multi-Granularity Encoding for Protein-Nucleotide Binding Site Prediction
Mar 16, 2026Accurate identification of protein-nucleotide binding sites is fundamental to deciphering molecular mechanisms and accelerating drug discovery. However, current computational methods often struggle with suboptimal performance due to inadequate feature representation and rigid fusion mechanisms, which hinder the effective exploitation of cross-task information synergy. To bridge this gap, we propose MTGA-MGE, a framework that integrates a Multi-Task Genetic Algorithm with Multi-Granularity Encoding to enhance binding site prediction. Specifically, we develop a Multi-Granularity Encoding (MGE) network that synergizes multi-scale convolutions and self-attention mechanisms to distill discriminative signals from high-dimensional, redundant biological data. To overcome the constraints of static fusion, a genetic algorithm is employed to adaptively evolve task-specific fusion strategies, thereby effectively improving model generalization. Furthermore, to catalyze collaborative learning, we introduce an External-Neighborhood Mechanism (ENM) that leverages biological similarities to facilitate targeted information exchange across tasks. Extensive evaluations on fifteen nucleotide datasets demonstrate that MTGA-MGE not only establishes a new state-of-the-art in data-abundant, high-resource scenarios but also maintains a robust competitive edge in rare, low-resource regimes, presenting a highly adaptive scheme for decoding complex protein-ligand interactions in the post-genomic era.
Multi-objective Genetic Programming with Multi-view Multi-level Feature for Enhanced Protein Secondary Structure Prediction
Mar 11, 2026Predicting protein secondary structure is essential for understanding protein function and advancing drug discovery. However, the intricate sequence-structure relationship poses significant challenges for accurate modeling. To address these, we propose MOGP-MMF, a multi-objective genetic programming framework that reformulates PSSP as an automated optimization task focused on feature selection and fusion. Specifically, MOGP-MMF introduces a multi-view multi-level representation strategy that integrates evolutionary, semantic, and newly introduced structural views to capture the comprehensive protein folding logic. Leveraging an enriched operator set, the framework evolves both linear and nonlinear fusion functions, effectively capturing high-order feature interactions while reducing fusion complexity. To resolve the accuracy-complexity trade-off, an improved multi-objective GP algorithm is developed, incorporating a knowledge transfer mechanism that utilizes prior evolutionary experience to guide the population toward global optima. Extensive experiments across seven benchmark datasets demonstrate that MOGP-MMF surpasses state-of-the-art methods, particularly in Q8 accuracy and structural integrity. Furthermore, MOGP-MMF generates a diverse set of non-dominated solutions, offering flexible model selection schemes for various practical application scenarios. The source code is available on GitHub: https://github.com/qian-ann/MOGP-MMF/tree/main.
AI-empowered Channel Estimation for Block-based Active IRS-enhanced Hybrid-field IoT Network
May 20, 2025In this paper, channel estimation (CE) for uplink hybrid-field communications involving multiple Internet of Things (IoT) devices assisted by an active intelligent reflecting surface (IRS) is investigated. Firstly, to reduce the complexity of near-field (NF) channel modeling and estimation between IoT devices and active IRS, a sub-blocking strategy for active IRS is proposed. Specifically, the entire active IRS is divided into multiple smaller sub-blocks, so that IoT devices are located in the far-field (FF) region of each sub block, while also being located in the NF region of the entire active IRS. This strategy significantly simplifies the channel model and reduces the parameter estimation dimension by decoupling the high-dimensional NF channel parameter space into low dimensional FF sub channels. Subsequently, the relationship between channel approximation error and CE error with respect to the number of sub blocks is derived, and the optimal number of sub blocks is solved based on the criterion of minimizing the total error. In addition, considering that the amplification capability of active IRS requires power consumption, a closed-form expression for the optimal power allocation factor is derived. To further reduce the pilot overhead, a lightweight CE algorithm based on convolutional autoencoder (CAE) and multi-head attention mechanism, called CAEformer, is designed. The Cramer-Rao lower bound is derived to evaluate the proposed algorithm's performance. Finally, simulation results demonstrate the proposed CAEformer network significantly outperforms the conventional least square and minimum mean square error scheme in terms of estimation accuracy.
High-performance Power Allocation Strategies for Active IRS-aided Wireless Network
Nov 10, 2023

Due to its intrinsic ability to combat the double fading effect, the active intelligent reflective surface (IRS) becomes popular. The main feature of active IRS must be supplied by power, and the problem of how to allocate the total power between base station (BS) and IRS to fully explore the rate gain achieved by power allocation (PA) to remove the rate gap between existing PA strategies and optimal exhaustive search (ES) arises naturally. First, the signal-to-noise ratio (SNR) expression is derived to be a function of PA factor beta [0, 1]. Then, to improve the rate performance of the conventional gradient ascent (GA), an equal-spacing-multiple-point-initialization GA (ESMPI-GA) method is proposed. Due to its slow linear convergence from iterative GA, the proposed ESMPI-GA is high-complexity. Eventually, to reduce this high complexity, a low-complexity closed-form PA method with third-order Taylor expansion (TTE) centered at point beta0 = 0.5 is proposed. Simulation results show that the proposed ESMPI-GA harvests about 0.5 bit gain over conventional GA and 1.2 and 0.8 bits gain over existing methods like equal PA and Taylor polynomial approximation (TPA) for small-scale IRS, and the proposed TTE performs much better than TPA and fixed PA strategies using an extremely low complexity.
ETO Meets Scheduling: Learning Key Knowledge from Single-Objective Problems to Multi-Objective Problem
Jun 26, 2022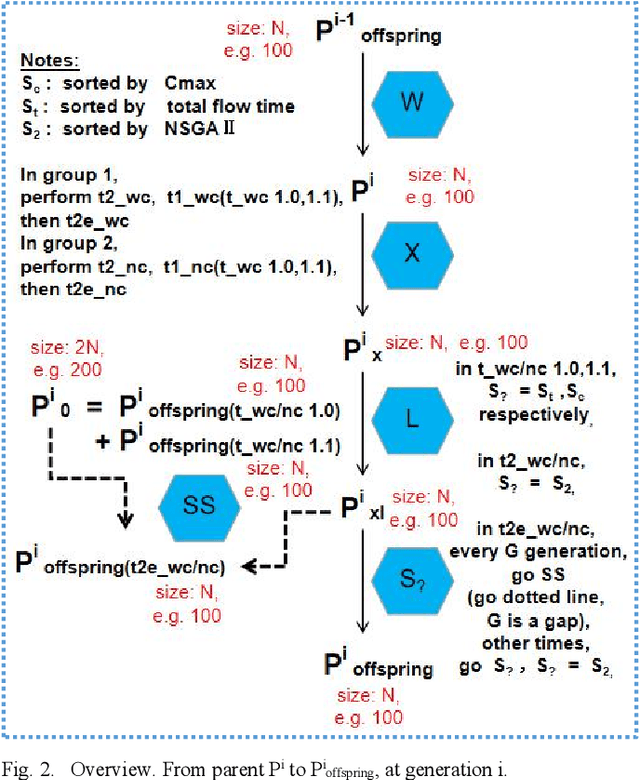
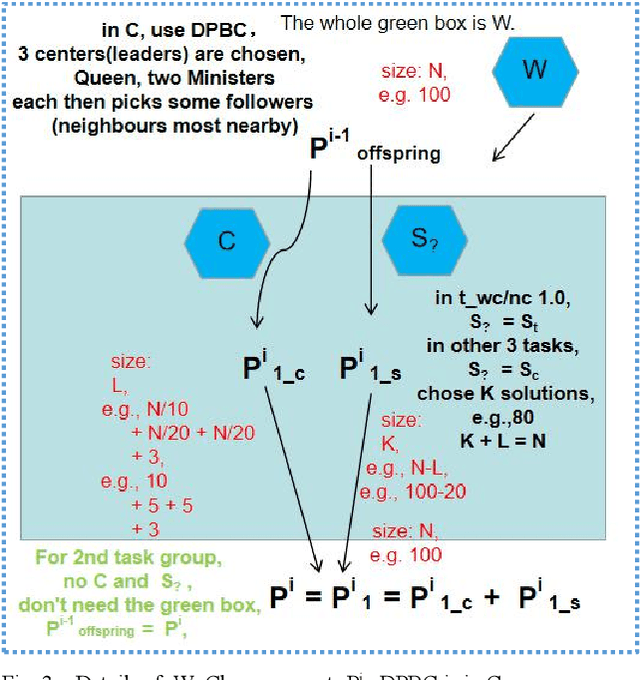
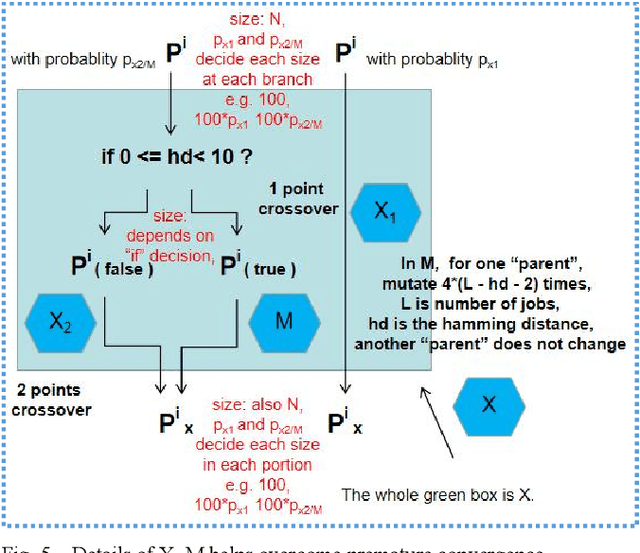
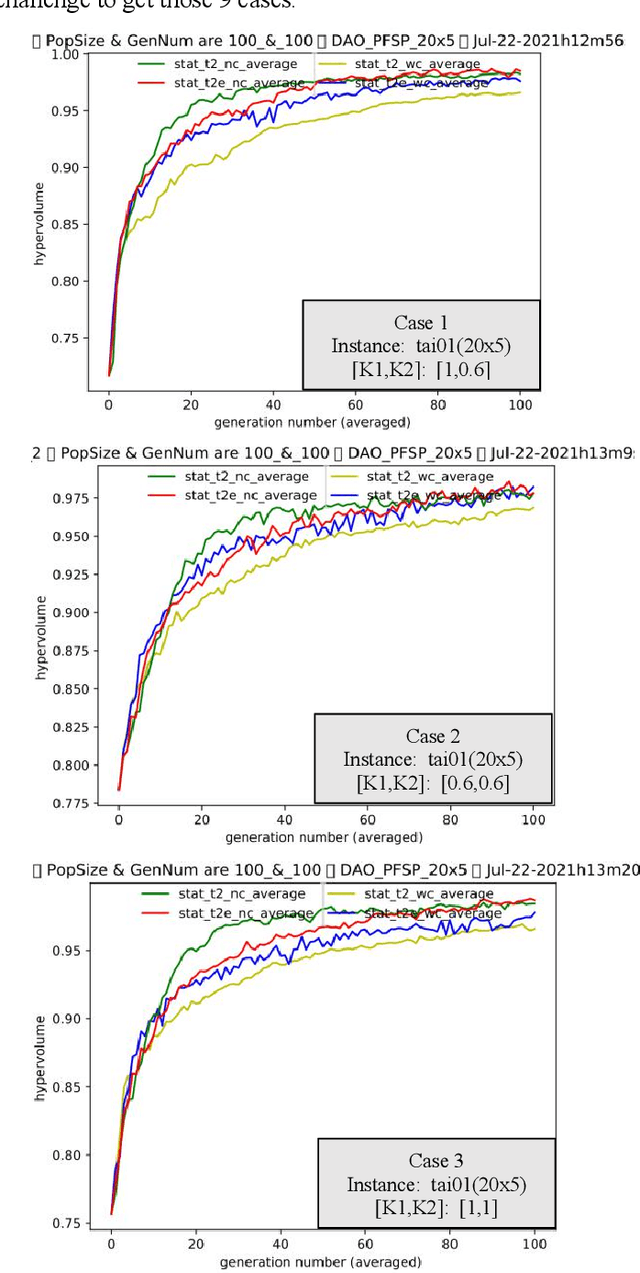
Evolutionary transfer optimization(ETO) serves as "a new frontier in evolutionary computation research", which will avoid zero reuse of experience and knowledge from solved problems in traditional evolutionary computation. In scheduling applications via ETO, a highly competitive "meeting" framework between them could be constituted towards both intelligent scheduling and green scheduling, especially for carbon neutrality within the context of China. To the best of our knowledge, our study on scheduling here, is the 1st work of ETO for complex optimization when multiobjective problem "meets" single-objective problems in combinatorial case (not multitasking optimization). More specifically, key knowledge like positional building blocks clustered, could be learned and transferred for permutation flow shop scheduling problem (PFSP). Empirical studies on well-studied benchmarks validate relatively firm effectiveness and great potential of our proposed ETO-PFSP framework.
Spatial Modulation: an Attractive Secure Solution to Future Wireless Network
Mar 06, 2021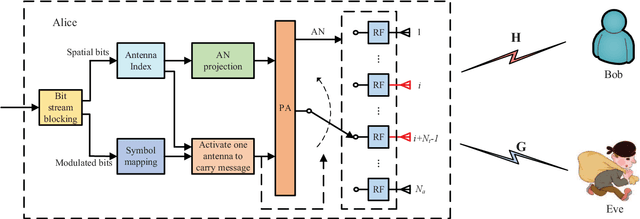
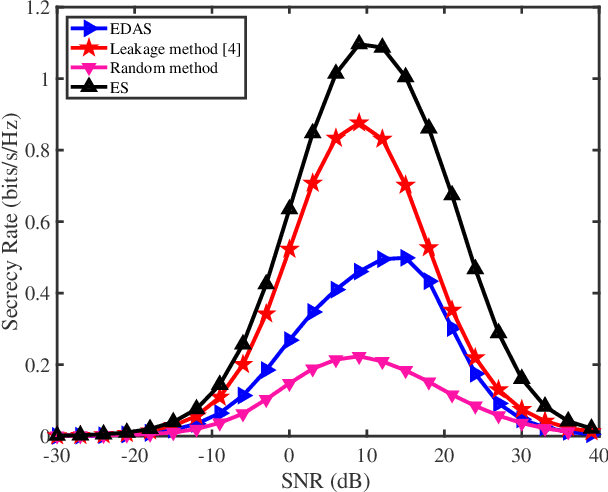
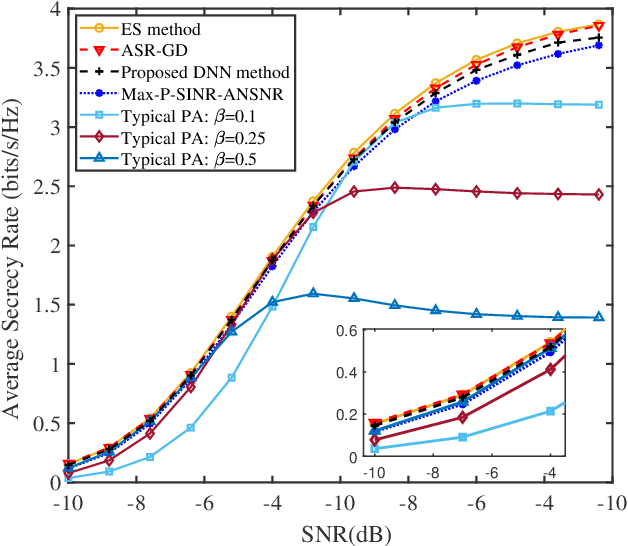
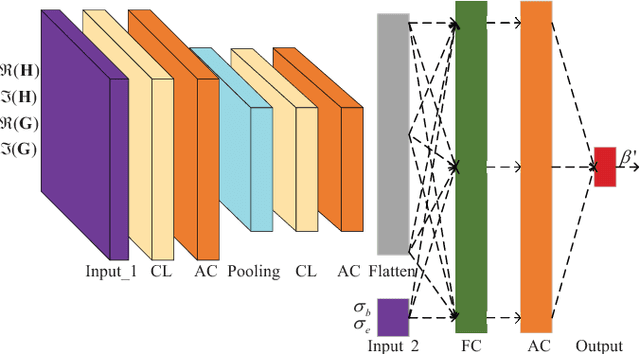
As a green and secure wireless transmission method, secure spatial modulation (SM) is becoming a hot research area. Its basic idea is to exploit both the index of activated transmit antenna and amplitude phase modulation signal to carry messages, improve security, and save energy. In this paper, we review its crucial challenges: transmit antenna selection (TAS), artificial noise (AN) projection, power allocation (PA) and joint detection at the desired receiver. As the size of signal constellation tends to medium-scale or large-scale, the complexity of traditional maximum likelihood detector becomes prohibitive. To reduce this complexity, a low-complexity maximum likelihood (ML) detector is proposed. To further enhance the secrecy rate (SR) performance, a deep-neural-network (DNN) PA strategy is proposed. Simulation results show that the proposed low-complexity ML detector, with a lower-complexity, has the same bit error rate performance as the joint ML method while the proposed DNN method strikes a good balance between complexity and SR performance.