 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdgeLoc: An Edge-IoT Framework for Robust Indoor Localization Using Capsule Networks
Sep 12, 2020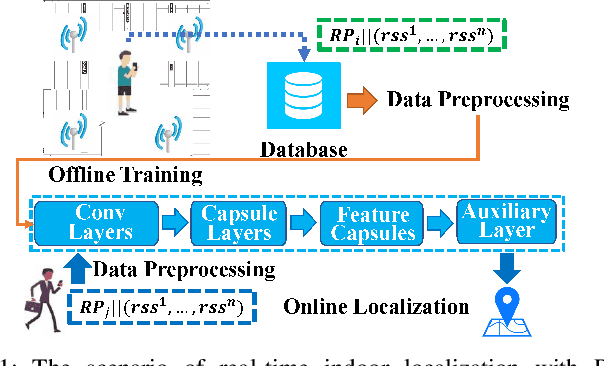
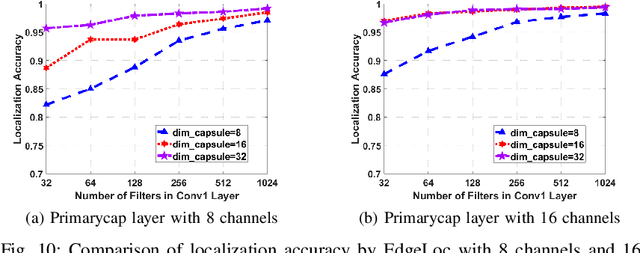
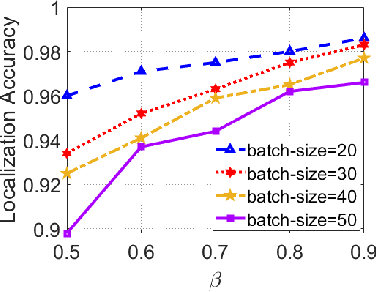
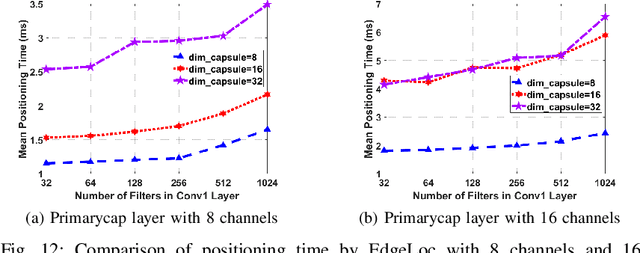
With the unprecedented demand for location-based services in indoor scenarios, wireless indoor localization has become essential for mobile users. While GPS is not available at indoor spaces, WiFi RSS fingerprinting has become popular with its ubiquitous accessibility. However, it is challenging to achieve robust and efficient indoor localization with two major challenges. First, the localization accuracy can be degraded by the random signal fluctuations, which would influence conventional localization algorithms that simply learn handcrafted features from raw fingerprint data. Second, mobile users are sensitive to the localization delay, but conventional indoor localization algorithms are computation-intensive and time-consuming. In this paper, we propose EdgeLoc, an edge-IoT framework for efficient and robust indoor localization using capsule networks. We develop a deep learning model with the CapsNet to efficiently extract hierarchical information from WiFi fingerprint data, thereby significantly improving the localization accuracy. Moreover, we implement an edge-computing prototype system to achieve a nearly real-time localization process, by enabling mobile users with the deep-learning model that has been well-trained by the edge server. We conduct a real-world field experimental study with over 33,600 data points and an extensive synthetic experiment with the open dataset, and the experimental results validate the effectiveness of EdgeLoc. The best trade-off of the EdgeLoc system achieves 98.5% localization accuracy within an average positioning time of only 2.31 ms in the field experiment.
Binarized Graph Neural Network
Apr 19, 2020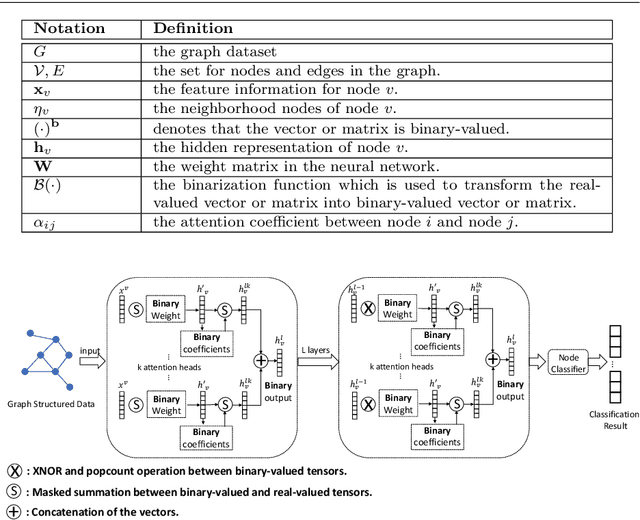
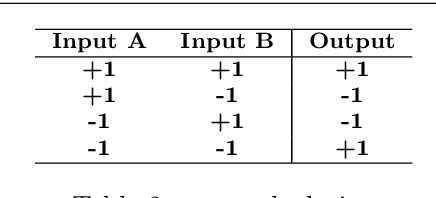
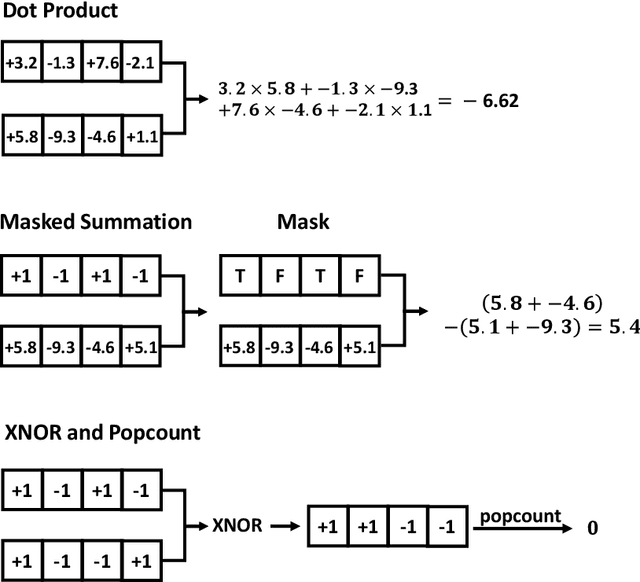
Recently, there have been some breakthroughs in graph analysis by applying the graph neural networks (GNNs) following a neighborhood aggregation scheme, which demonstrate outstanding performance in many tasks. However, we observe that the parameters of the network and the embedding of nodes are represented in real-valued matrices in existing GNN-based graph embedding approaches which may limit the efficiency and scalability of these models. It is well-known that binary vector is usually much more space and time efficient than the real-valued vector. This motivates us to develop a binarized graph neural network to learn the binary representations of the nodes with binary network parameters following the GNN-based paradigm. Our proposed method can be seamlessly integrated into the existing GNN-based embedding approaches to binarize the model parameters and learn the compact embedding. Extensive experiments indicate that the proposed binarized graph neural network, namely BGN, is orders of magnitude more efficient in terms of both time and space while matching the state-of-the-art performance.
PDANet: Pyramid Density-aware Attention Net for Accurate Crowd Counting
Feb 25, 2020
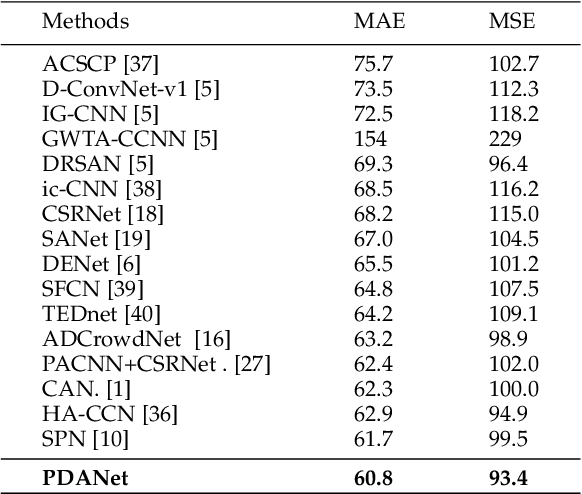
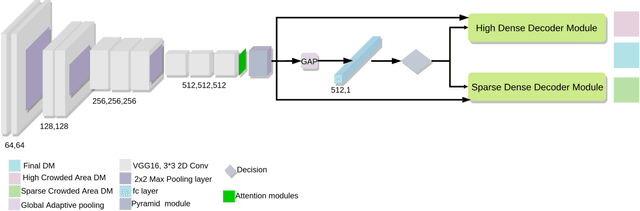
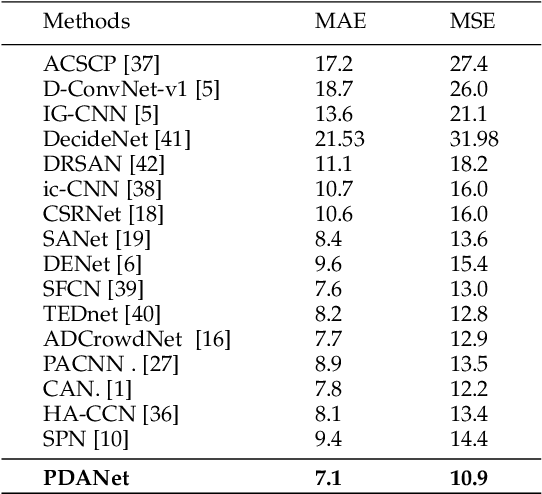
Crowd counting, i.e., estimating the number of people in a crowded area, has attracted much interest in the research community. Although many attempts have been reported, crowd counting remains an open real-world problem due to the vast scale variations in crowd density within the interested area, and severe occlusion among the crowd. In this paper, we propose a novel Pyramid Density-Aware Attention-based network, abbreviated as PDANet, that leverages the attention, pyramid scale feature and two branch decoder modules for density-aware crowd counting. The PDANet utilizes these modules to extract different scale features, focus on the relevant information, and suppress the misleading ones. We also address the variation of crowdedness levels among different images with an exclusive Density-Aware Decoder (DAD). For this purpose, a classifier evaluates the density level of the input features and then passes them to the corresponding high and low crowded DAD modules. Finally, we generate an overall density map by considering the summation of low and high crowded density maps as spatial attention. Meanwhile, we employ two losses to create a precise density map for the input scene. Extensive evaluations conducted on the challenging benchmark datasets well demonstrate the superior performance of the proposed PDANet in terms of the accuracy of counting and generated density maps over the well-known state of the arts.
Security & Privacy in IoT Using Machine Learning & Blockchain: Threats & Countermeasures
Feb 10, 2020
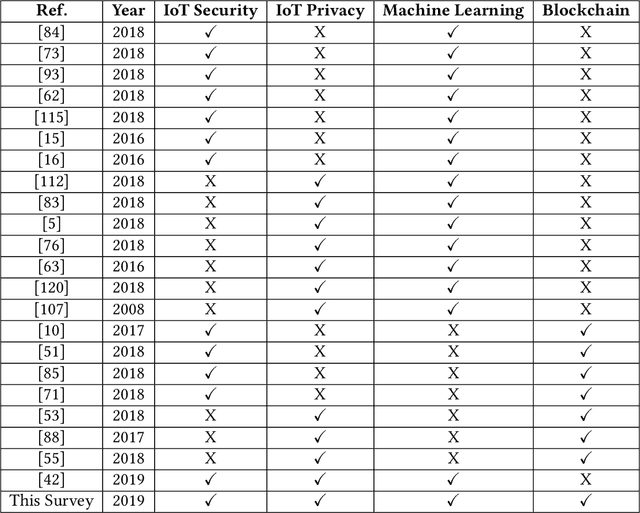
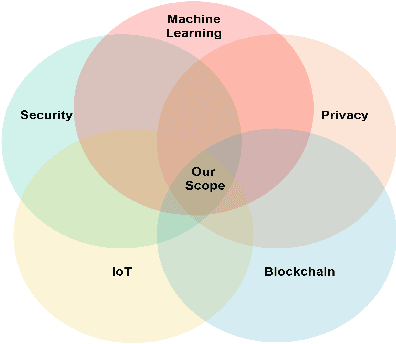
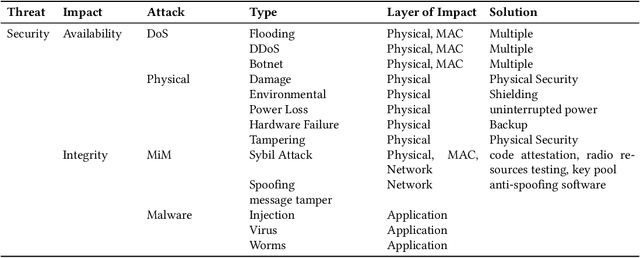
Security and privacy have become significant concerns due to the involvement of the Internet of Things (IoT) devices in different applications. Cyber threats are growing at an explosive pace making the existing security and privacy measures inadequate. Hence, everyone on the Internet is a product for hackers. Consequently, Machine Learning (ML) algorithms are used to produce accurate outputs from large complex databases. The generated outputs can be used to predict and detect vulnerabilities in IoT-based systems. Furthermore, Blockchain (BC) technique is becoming popular in modern IoT applications to deal with security and privacy issues. Several studies have been conducted on either ML algorithms or BC techniques. However, these studies target either security or privacy issues using ML algorithms or BC techniques, thus posing a need for a combined survey on efforts made in recent years addressing both security and privacy issues using ML algorithms and BC techniques. In this paper, we have provided a summary of research efforts made in the past few years addressing security and privacy issues using ML algorithms and BC techniques in the IoT domain. First, we discuss and categorize various security and privacy threats in the IoT domain that were reported in the past few years. Secondly, we classify the literature on security and privacy efforts based on ML algorithms and BC techniques in the IoT domain. In the end, various challenges and future research directions using ML algorithms and BC techniques to address security and privacy issues in the IoT domain are identified and discussed.
See More Than Once -- Kernel-Sharing Atrous Convolution for Semantic Segmentation
Sep 09, 2019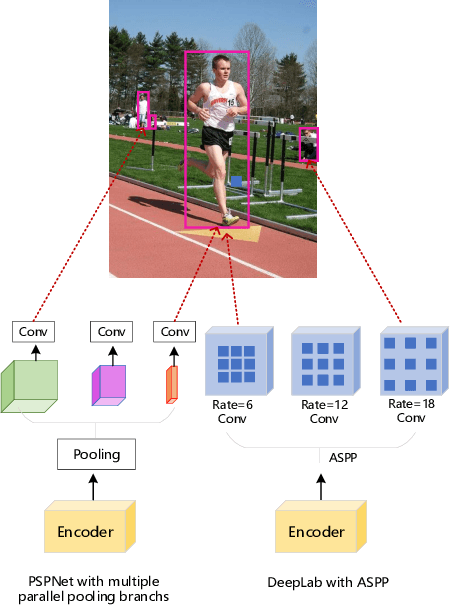
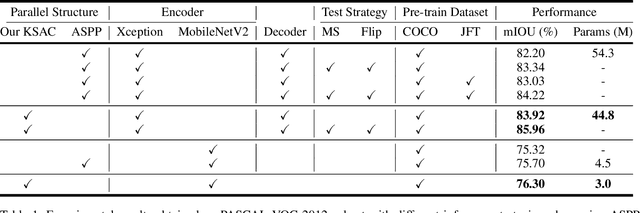
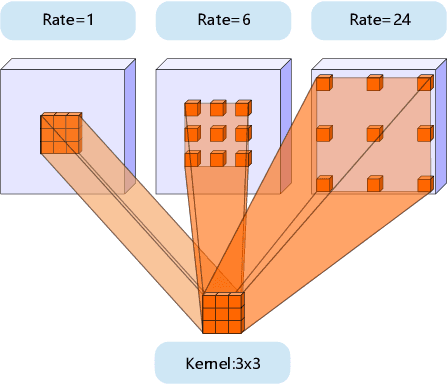
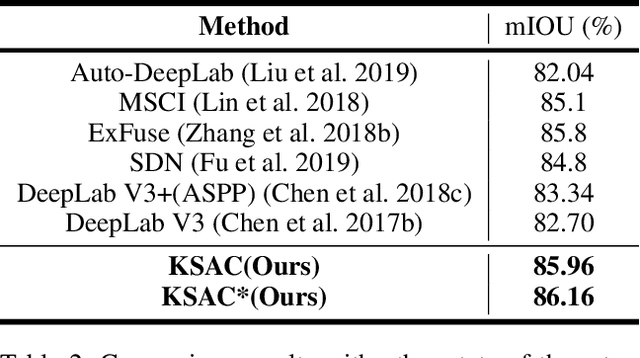
The state-of-the-art semantic segmentation solutions usually leverage different receptive fields via multiple parallel branches to handle objects with different sizes. However, employing separate kernels for individual branches degrades the generalization and representation abilities of the network, and the amount of parameters increases by the times of the number of branches. To tackle this problem, we propose a novel network structure namely Kernel-Sharing Atrous Convolution (KSAC), where branches of different receptive fields share the same kernel, i.e., let a single kernel `see' the input feature maps more than once with different receptive fields, to facilitate communication among branches and perform `feature augmentation' inside the network. Experiments conducted on the benchmark VOC 2012 dataset show that the proposed sharing strategy can not only boost network's generalization and representation abilities but also reduce the model complexity significantly. Specifically, when compared with DeepLabV3+ equipped with MobileNetv2 backbone, 33% parameters are reduced together with an mIOU improvement of 0.6%. When Xception is used as the backbone, the mIOU is elevated from 83.34% to 85.96% with about 10M parameters saved. In addition, different from the widely used ASPP structure, our proposed KSAC is able to further improve the mIOU by taking benefit of wider context with larger atrous rates.
FACLSTM: ConvLSTM with Focused Attention for Scene Text Recognition
Apr 20, 2019

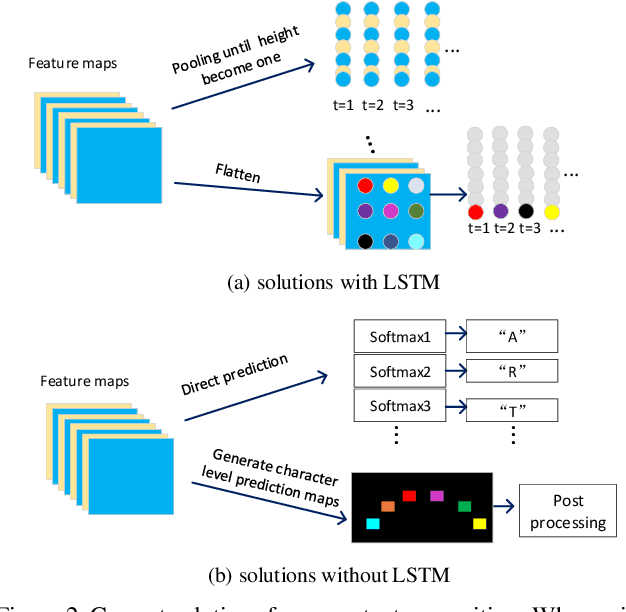
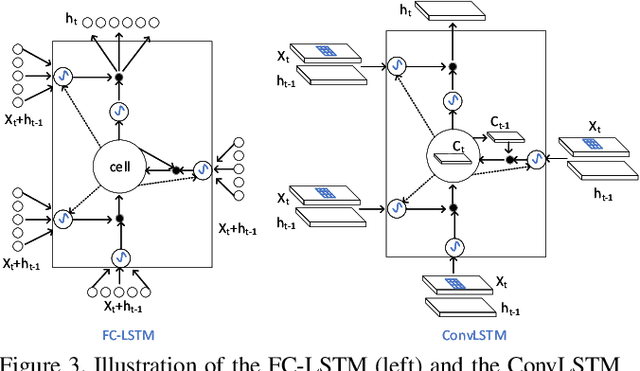
Scene text recognition has recently been widely treated as a sequence-to-sequence prediction problem, where traditional fully-connected-LSTM (FC-LSTM) has played a critical role. Due to the limitation of FC-LSTM, existing methods have to convert 2-D feature maps into 1-D sequential feature vectors, resulting in severe damages of the valuable spatial and structural information of text images. In this paper, we argue that scene text recognition is essentially a spatiotemporal prediction problem for its 2-D image inputs, and propose a convolution LSTM (ConvLSTM)-based scene text recognizer, namely, FACLSTM, i.e., Focused Attention ConvLSTM, where the spatial correlation of pixels is fully leveraged when performing sequential prediction with LSTM. Particularly, the attention mechanism is properly incorporated into an efficient ConvLSTM structure via the convolutional operations and additional character center masks are generated to help focus attention on right feature areas. The experimental results on benchmark datasets IIIT5K, SVT and CUTE demonstrate that our proposed FACLSTM performs competitively on the regular, low-resolution and noisy text images, and outperforms the state-of-the-art approaches on the curved text with large margins.
DENet: A Universal Network for Counting Crowd with Varying Densities and Scales
Apr 17, 2019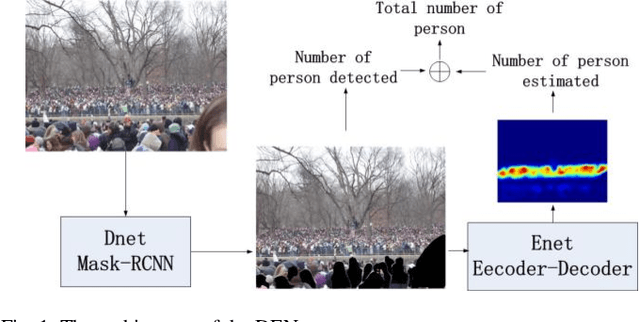

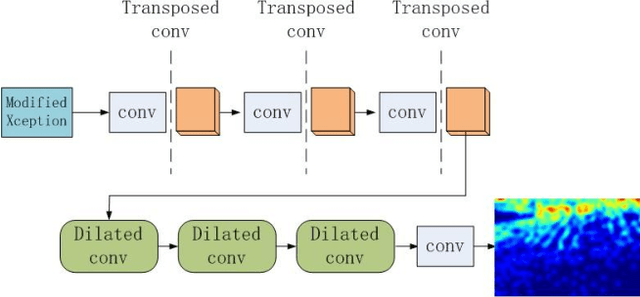
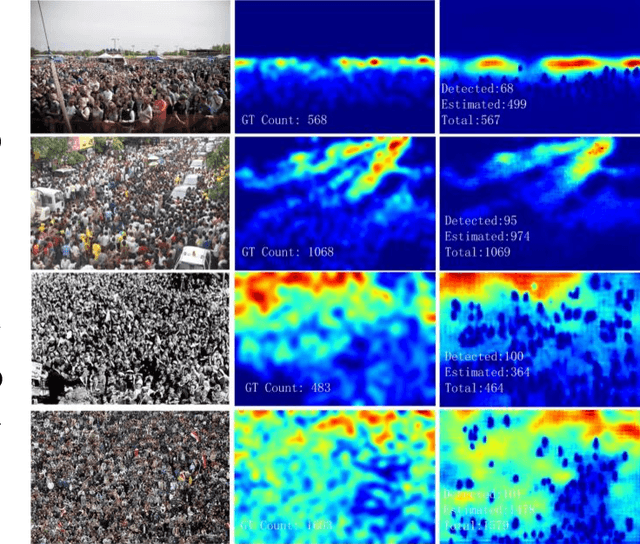
Counting people or objects with significantly varying scales and densities has attracted much interest from the research community and yet it remains an open problem. In this paper, we propose a simple but an efficient and effective network, named DENet, which is composed of two components, i.e., a detection network (DNet) and an encoder-decoder estimation network (ENet). We first run DNet on an input image to detect and count individuals who can be segmented clearly. Then, ENet is utilized to estimate the density maps of the remaining areas, where the numbers of individuals cannot be detected. We propose a modified Xception as an encoder for feature extraction and a combination of dilated convolution and transposed convolution as a decoder. In the ShanghaiTech Part A, UCF and WorldExpo'10 datasets, our DENet achieves lower Mean Absolute Error (MAE) than those of the state-of-the-art methods.
Voiceprint recognition of Parkinson patients based on deep learning
Dec 17, 2018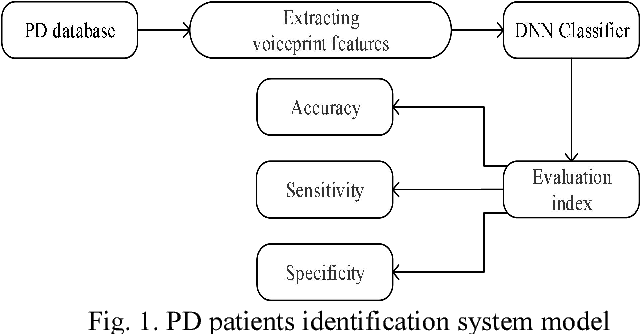
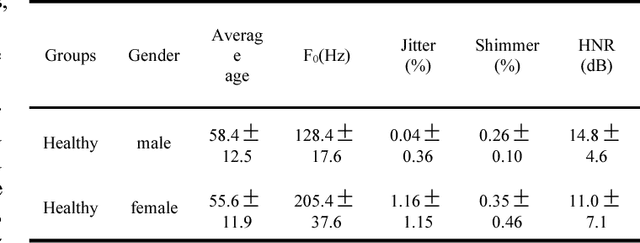
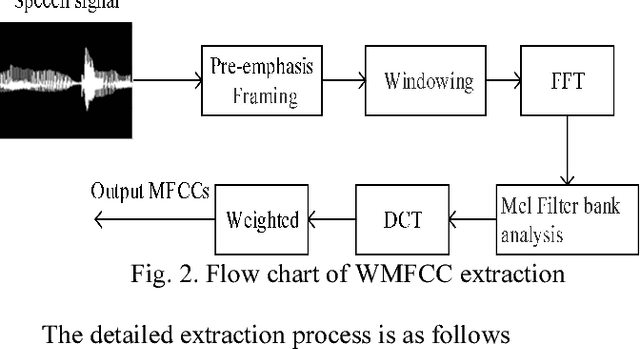
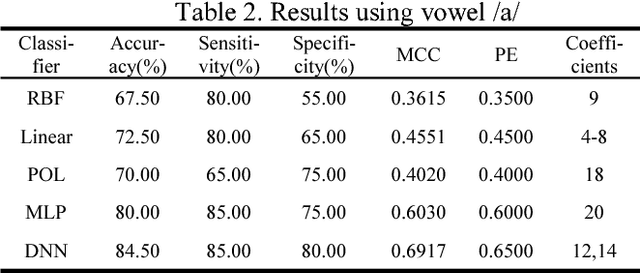
More than 90% of the Parkinson Disease (PD) patients suffer from vocal disorders. Speech impairment is already indicator of PD. This study focuses on PD diagnosis through voiceprint features. In this paper, a method based on Deep Neural Network (DNN) recognition and classification combined with Mini-Batch Gradient Descent (MBGD) is proposed to distinguish PD patients from healthy people using voiceprint features. In order to exact the voiceprint features from patients, Weighted Mel Frequency Cepstrum Coefficients (WMFCC) is applied. The proposed method is tested on experimental data obtained by the voice recordings of three sustained vowels /a/, /o/ and /u/ from participants (48 PD and 20 healthy people). The results show that the proposed method achieves a high accuracy of diagnosis of PD patients from healthy people, than the conventional methods like Support Vector Machine (SVM) and other mentioned in this paper. The accuracy achieved is 89.5%. WMFCC approach can solve the problem that the high-order cepstrum coefficients are small and the features component's representation ability to the audio is weak. MBGD reduces the computational loads of the loss function, and increases the training speed of the system. DNN classifier enhances the classification ability of voiceprint features. Therefore, the above approaches can provide a solid solution for the quick auxiliary diagnosis of PD in early stage.
A-CCNN: adaptive ccnn for density estimation and crowd counting
Apr 20, 2018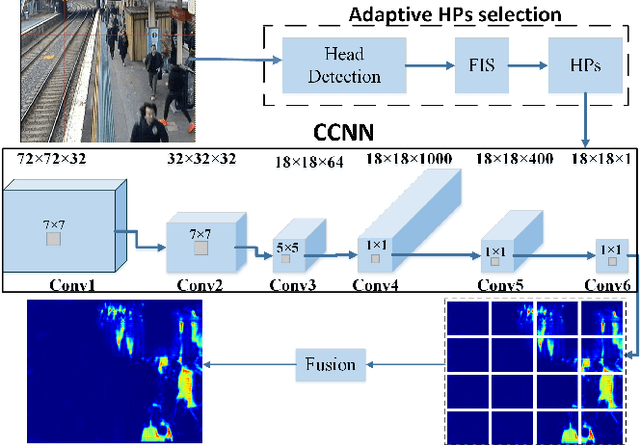
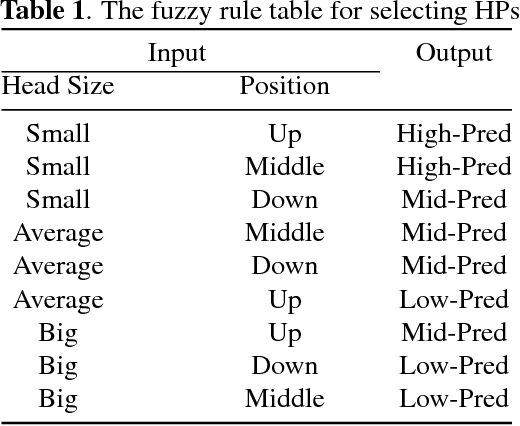

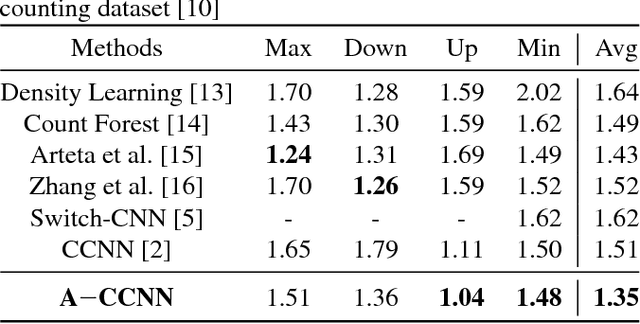
Crowd counting, for estimating the number of people in a crowd using vision-based computer techniques, has attracted much interest in the research community. Although many attempts have been reported, real-world problems, such as huge variation in subjects' sizes in images and serious occlusion among people, make it still a challenging problem. In this paper, we propose an Adaptive Counting Convolutional Neural Network (A-CCNN) and consider the scale variation of objects in a frame adaptively so as to improve the accuracy of counting. Our method takes advantages of contextual information to provide more accurate and adaptive density maps and crowd counting in a scene. Extensively experimental evaluation is conducted using different benchmark datasets for object-counting and shows that the proposed approach is effective and outperforms state-of-the-art approaches.
Beyond Context: Exploring Semantic Similarity for Tiny Face Detection
Mar 05, 2018
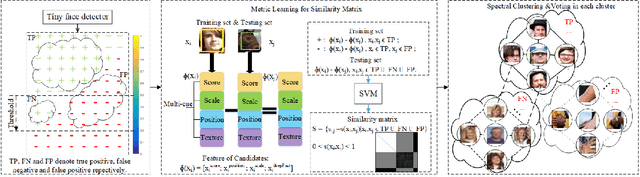
Tiny face detection aims to find faces with high degrees of variability in scale, resolution and occlusion in cluttered scenes. Due to the very little information available on tiny faces, it is not sufficient to detect them merely based on the information presented inside the tiny bounding boxes or their context. In this paper, we propose to exploit the semantic similarity among all predicted targets in each image to boost current face detectors. To this end, we present a novel framework to model semantic similarity as pairwise constraints within the metric learning scheme, and then refine our predictions with the semantic similarity by utilizing the graph cut techniques. Experiments conducted on three widely-used benchmark datasets have demonstrated the improvement over the-state-of-the-arts gained by applying this idea.