 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Topic Selection Model with Latent Variable for Topic-Grounded Dialogue
Oct 17, 2022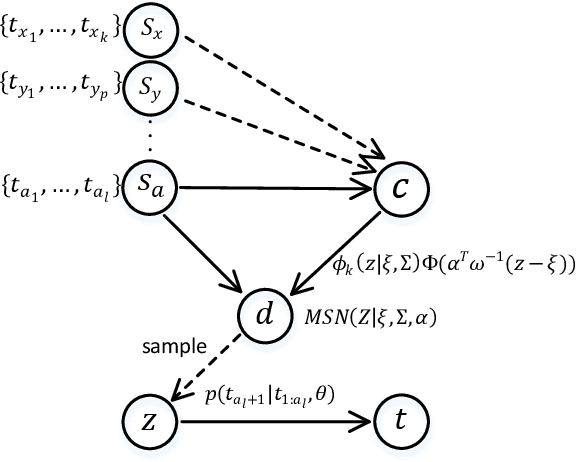
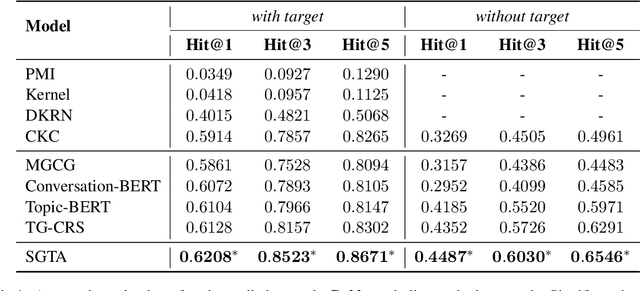
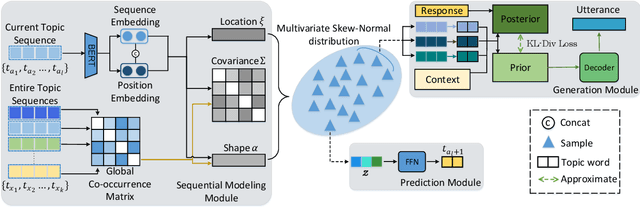
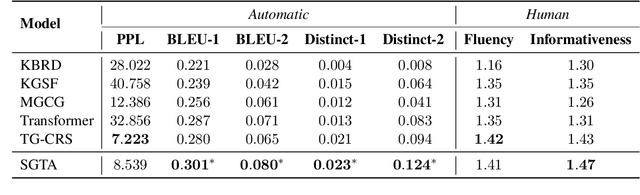
Recently, topic-grounded dialogue system has attracted significant attention due to its effectiveness in predicting the next topic to yield better responses via the historical context and given topic sequence. However, almost all existing topic prediction solutions focus on only the current conversation and corresponding topic sequence to predict the next conversation topic, without exploiting other topic-guided conversations which may contain relevant topic-transitions to current conversation. To address the problem, in this paper we propose a novel approach, named Sequential Global Topic Attention (SGTA) to exploit topic transition over all conversations in a subtle way for better modeling post-to-response topic-transition and guiding the response generation to the current conversation. Specifically, we introduce a latent space modeled as a Multivariate Skew-Normal distribution with hybrid kernel functions to flexibly integrate the global-level information with sequence-level information, and predict the topic based on the distribution sampling results. We also leverage a topic-aware prior-posterior approach for secondary selection of predicted topics, which is utilized to optimize the response generation task. Extensive experiments demonstrate that our model outperforms competitive baselines on prediction and generation tasks.
Capturing Global Structural Information in Long Document Question Answering with Compressive Graph Selector Network
Oct 11, 2022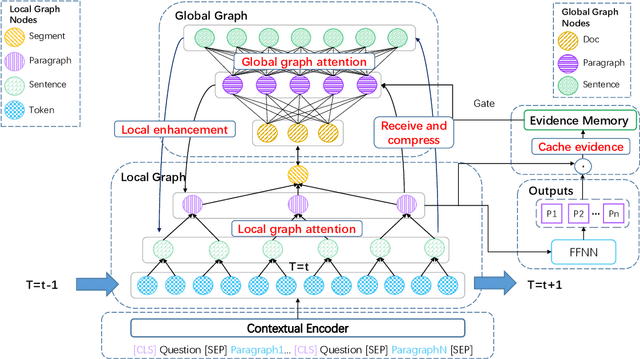
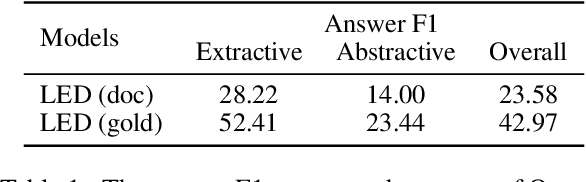
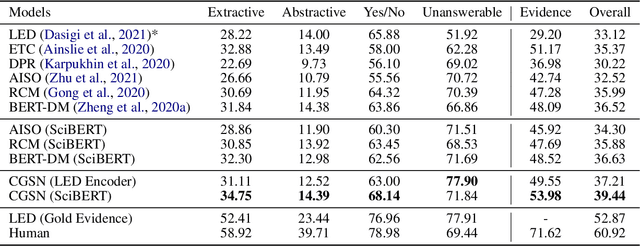
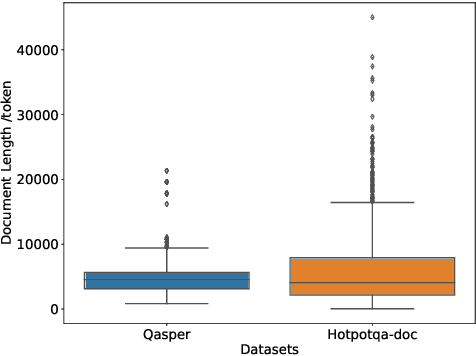
Long document question answering is a challenging task due to its demands for complex reasoning over long text. Previous works usually take long documents as non-structured flat texts or only consider the local structure in long documents. However, these methods usually ignore the global structure of the long document, which is essential for long-range understanding. To tackle this problem, we propose Compressive Graph Selector Network (CGSN) to capture the global structure in a compressive and iterative manner. Specifically, the proposed model consists of three modules: local graph network, global graph network and evidence memory network. Firstly, the local graph network builds the graph structure of the chunked segment in token, sentence, paragraph and segment levels to capture the short-term dependency of the text. Secondly, the global graph network selectively receives the information of each level from the local graph, compresses them into the global graph nodes and applies graph attention into the global graph nodes to build the long-range reasoning over the entire text in an iterative way. Thirdly, the evidence memory network is designed to alleviate the redundancy problem in the evidence selection via saving the selected result in the previous steps. Extensive experiments show that the proposed model outperforms previous methods on two datasets.
ET5: A Novel End-to-end Framework for Conversational Machine Reading Comprehension
Sep 23, 2022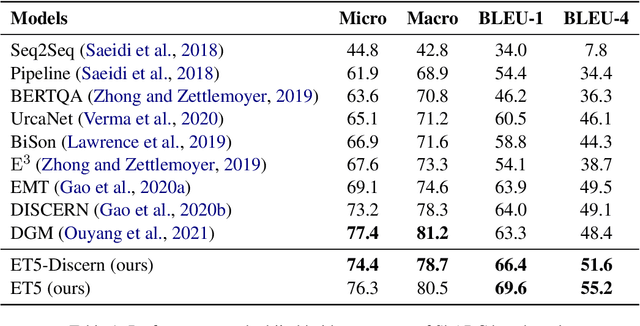
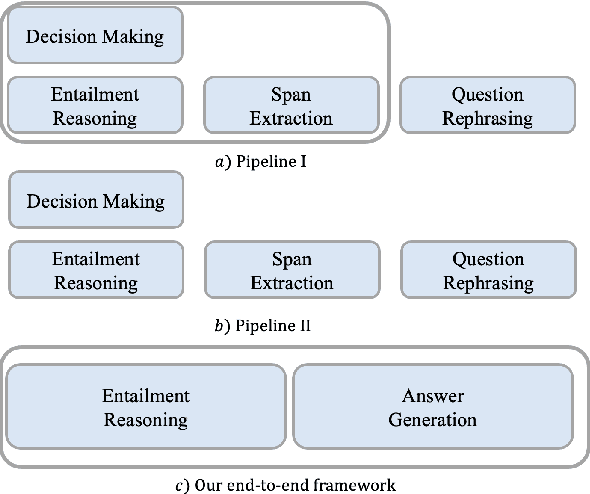
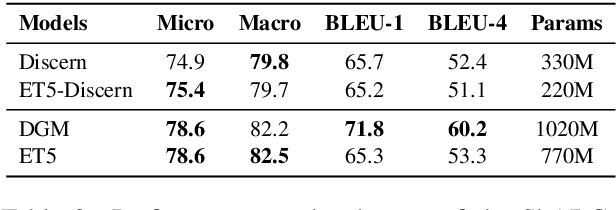
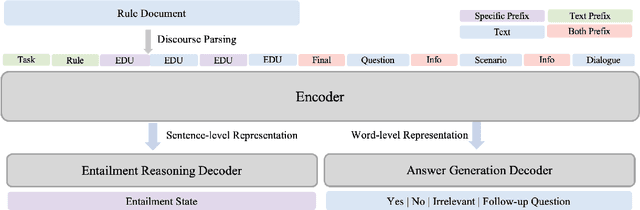
Conversational machine reading comprehension (CMRC) aims to assist computers to understand an natural language text and thereafter engage in a multi-turn conversation to answer questions related to the text. Existing methods typically require three steps: (1) decision making based on entailment reasoning; (2) span extraction if required by the above decision; (3) question rephrasing based on the extracted span. However, for nearly all these methods, the span extraction and question rephrasing steps cannot fully exploit the fine-grained entailment reasoning information in decision making step because of their relative independence, which will further enlarge the information gap between decision making and question phrasing. Thus, to tackle this problem, we propose a novel end-to-end framework for conversational machine reading comprehension based on shared parameter mechanism, called entailment reasoning T5 (ET5). Despite the lightweight of our proposed framework, experimental results show that the proposed ET5 achieves new state-of-the-art results on the ShARC leaderboard with the BLEU-4 score of 55.2. Our model and code are publicly available at https://github.com/Yottaxx/ET5.
Unsupervised Hashing with Semantic Concept Mining
Sep 23, 2022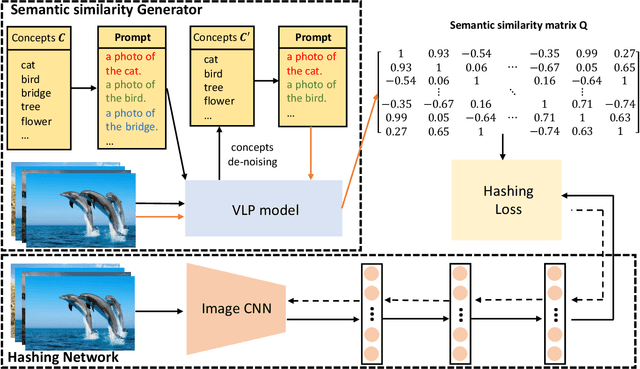
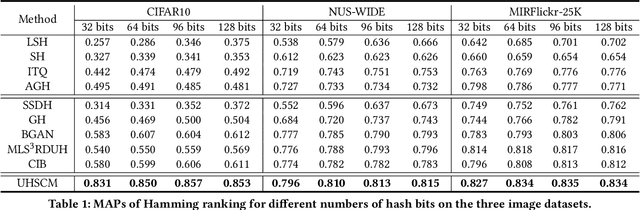
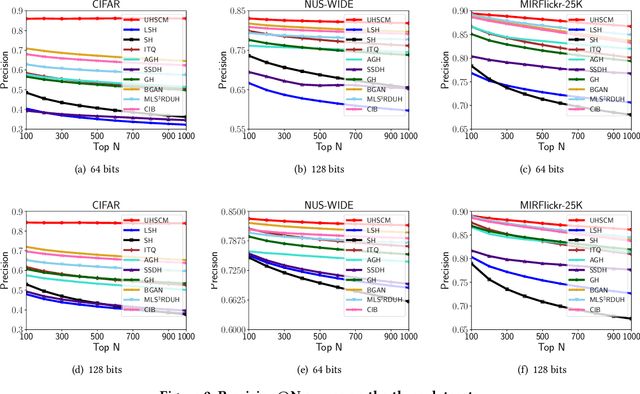
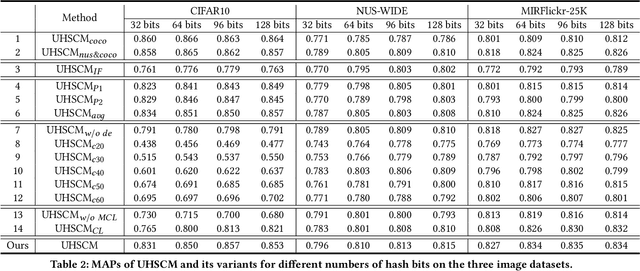
Recently, to improve the unsupervised image retrieval performance, plenty of unsupervised hashing methods have been proposed by designing a semantic similarity matrix, which is based on the similarities between image features extracted by a pre-trained CNN model. However, most of these methods tend to ignore high-level abstract semantic concepts contained in images. Intuitively, concepts play an important role in calculating the similarity among images. In real-world scenarios, each image is associated with some concepts, and the similarity between two images will be larger if they share more identical concepts. Inspired by the above intuition, in this work, we propose a novel Unsupervised Hashing with Semantic Concept Mining, called UHSCM, which leverages a VLP model to construct a high-quality similarity matrix. Specifically, a set of randomly chosen concepts is first collected. Then, by employing a vision-language pretraining (VLP) model with the prompt engineering which has shown strong power in visual representation learning, the set of concepts is denoised according to the training images. Next, the proposed method UHSCM applies the VLP model with prompting again to mine the concept distribution of each image and construct a high-quality semantic similarity matrix based on the mined concept distributions. Finally, with the semantic similarity matrix as guiding information, a novel hashing loss with a modified contrastive loss based regularization item is proposed to optimize the hashing network. Extensive experiments on three benchmark datasets show that the proposed method outperforms the state-of-the-art baselines in the image retrieval task.
Multi-level Contrastive Learning Framework for Sequential Recommendation
Aug 27, 2022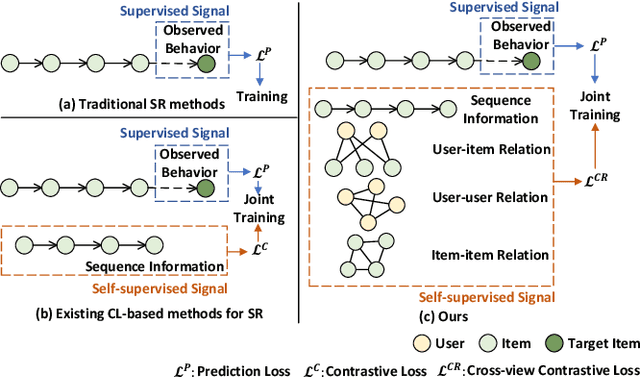
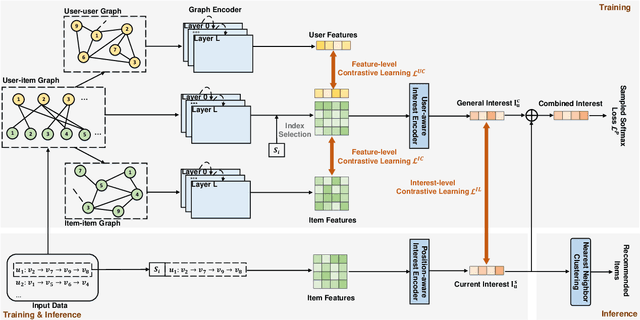
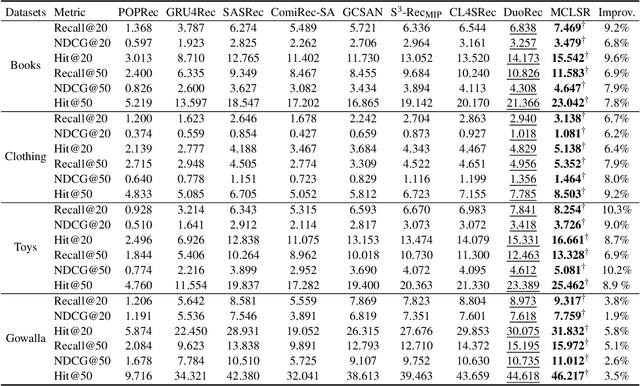
Sequential recommendation (SR) aims to predict the subsequent behaviors of users by understanding their successive historical behaviors. Recently, some methods for SR are devoted to alleviating the data sparsity problem (i.e., limited supervised signals for training), which take account of contrastive learning to incorporate self-supervised signals into SR. Despite their achievements, it is far from enough to learn informative user/item embeddings due to the inadequacy modeling of complex collaborative information and co-action information, such as user-item relation, user-user relation, and item-item relation. In this paper, we study the problem of SR and propose a novel multi-level contrastive learning framework for sequential recommendation, named MCLSR. Different from the previous contrastive learning-based methods for SR, MCLSR learns the representations of users and items through a cross-view contrastive learning paradigm from four specific views at two different levels (i.e., interest- and feature-level). Specifically, the interest-level contrastive mechanism jointly learns the collaborative information with the sequential transition patterns, and the feature-level contrastive mechanism re-observes the relation between users and items via capturing the co-action information (i.e., co-occurrence). Extensive experiments on four real-world datasets show that the proposed MCLSR outperforms the state-of-the-art methods consistently.
Unsupervised Question Answering via Answer Diversifying
Aug 23, 2022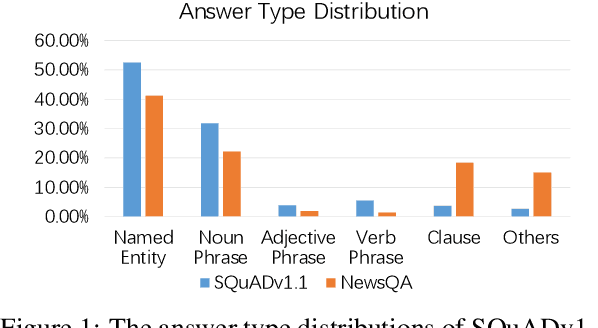
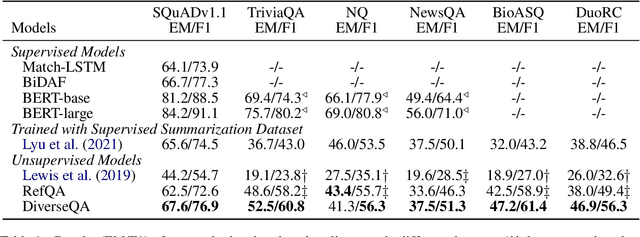
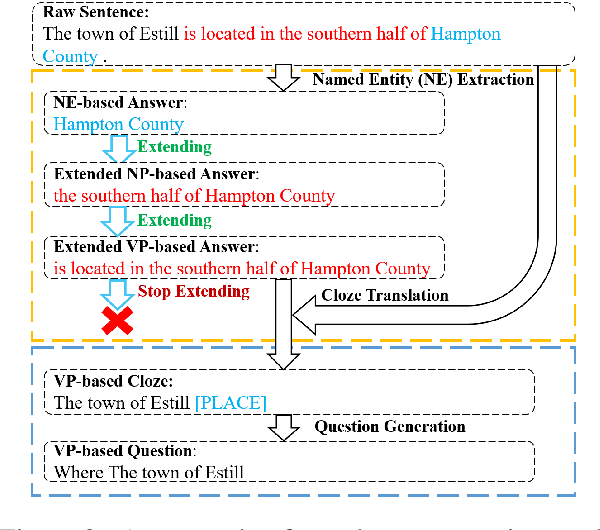
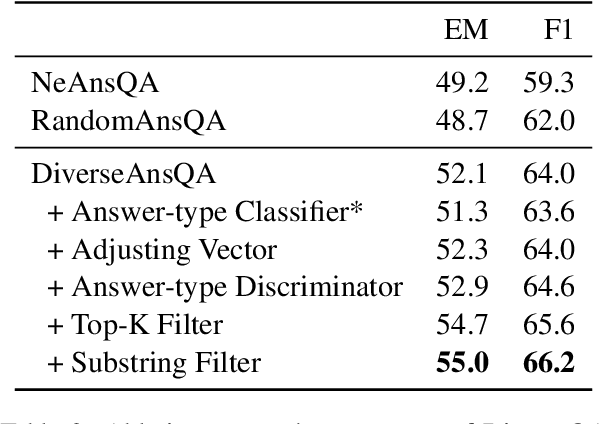
Unsupervised question answering is an attractive task due to its independence on labeled data. Previous works usually make use of heuristic rules as well as pre-trained models to construct data and train QA models. However, most of these works regard named entity (NE) as the only answer type, which ignores the high diversity of answers in the real world. To tackle this problem, we propose a novel unsupervised method by diversifying answers, named DiverseQA. Specifically, the proposed method is composed of three modules: data construction, data augmentation and denoising filter. Firstly, the data construction module extends the extracted named entity into a longer sentence constituent as the new answer span to construct a QA dataset with diverse answers. Secondly, the data augmentation module adopts an answer-type dependent data augmentation process via adversarial training in the embedding level. Thirdly, the denoising filter module is designed to alleviate the noise in the constructed data. Extensive experiments show that the proposed method outperforms previous unsupervised models on five benchmark datasets, including SQuADv1.1, NewsQA, TriviaQA, BioASQ, and DuoRC. Besides, the proposed method shows strong performance in the few-shot learning setting.
Improving Knowledge-aware Recommendation with Multi-level Interactive Contrastive Learning
Aug 22, 2022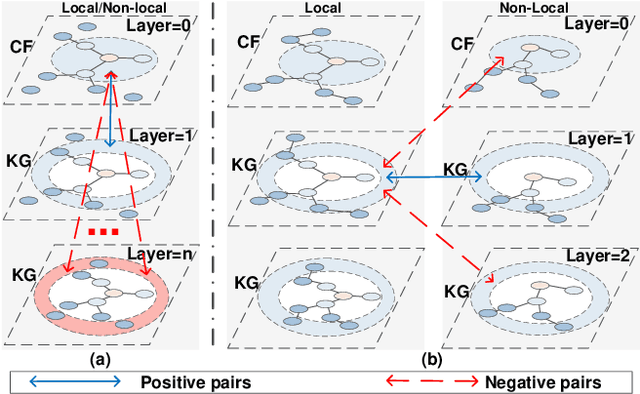
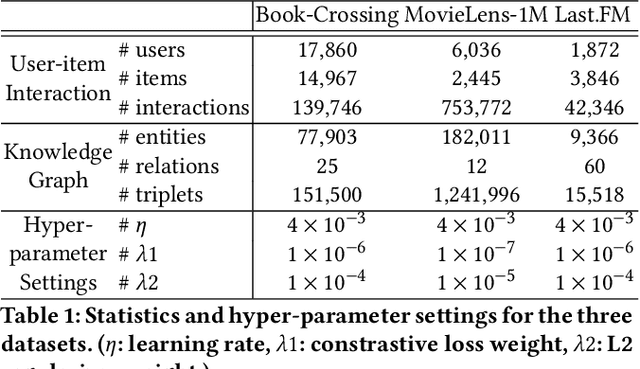
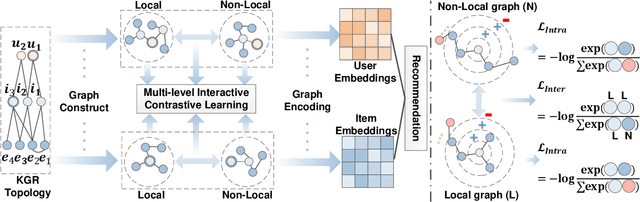
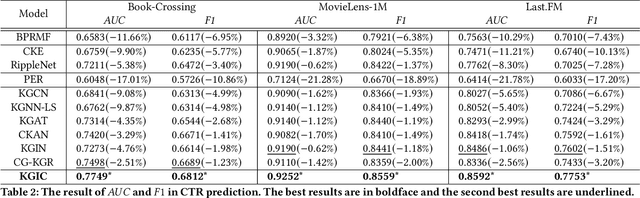
Incorporating Knowledge Graphs (KG) into recommeder system has attracted considerable attention. Recently, the technical trend of Knowledge-aware Recommendation (KGR) is to develop end-to-end models based on graph neural networks (GNNs). However, the extremely sparse user-item interactions significantly degrade the performance of the GNN-based models, as: 1) the sparse interaction, means inadequate supervision signals and limits the supervised GNN-based models; 2) the combination of sparse interactions (CF part) and redundant KG facts (KG part) results in an unbalanced information utilization. Besides, the GNN paradigm aggregates local neighbors for node representation learning, while ignoring the non-local KG facts and making the knowledge extraction insufficient. Inspired by the recent success of contrastive learning in mining supervised signals from data itself, in this paper, we focus on exploring contrastive learning in KGR and propose a novel multi-level interactive contrastive learning mechanism. Different from traditional contrastive learning methods which contrast nodes of two generated graph views, interactive contrastive mechanism conducts layer-wise self-supervised learning by contrasting layers of different parts within graphs, which is also an "interaction" action. Specifically, we first construct local and non-local graphs for user/item in KG, exploring more KG facts for KGR. Then an intra-graph level interactive contrastive learning is performed within each graph, which contrasts layers of the CF and KG parts, for more consistent information leveraging. Besides, an inter-graph level interactive contrastive learning is performed between the local and non-local graphs, for sufficiently and coherently extracting non-local KG signals. Extensive experiments conducted on three benchmark datasets show the superior performance of our proposed method over the state-of-the-arts.
Person-job fit estimation from candidate profile and related recruitment history with co-attention neural networks
Jun 18, 2022
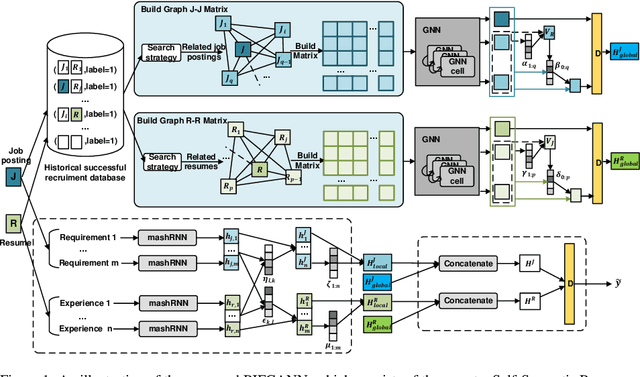
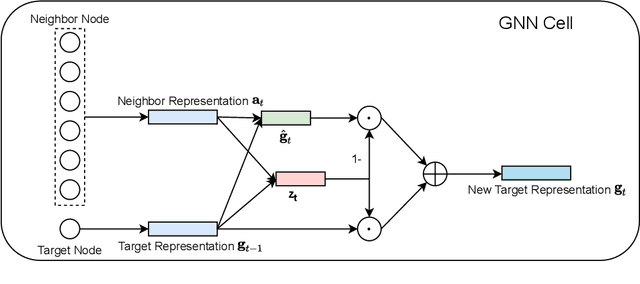
Existing online recruitment platforms depend on automatic ways of conducting the person-job fit, whose goal is matching appropriate job seekers with job positions. Intuitively, the previous successful recruitment records contain important information, which should be helpful for the current person-job fit. Existing studies on person-job fit, however, mainly focus on calculating the similarity between the candidate resumes and the job postings on the basis of their contents, without taking the recruiters' experience (i.e., historical successful recruitment records) into consideration. In this paper, we propose a novel neural network approach for person-job fit, which estimates person-job fit from candidate profile and related recruitment history with co-attention neural networks (named PJFCANN). Specifically, given a target resume-job post pair, PJFCANN generates local semantic representations through co-attention neural networks and global experience representations via graph neural networks. The final matching degree is calculated by combining these two representations. In this way, the historical successful recruitment records are introduced to enrich the features of resumes and job postings and strengthen the current matching process. Extensive experiments conducted on a large-scale recruitment dataset verify the effectiveness of PJFCANN compared with several state-of-the-art baselines. The codes are released at: https://github.com/CCIIPLab/PJFCANN.
Relational Triple Extraction: One Step is Enough
May 11, 2022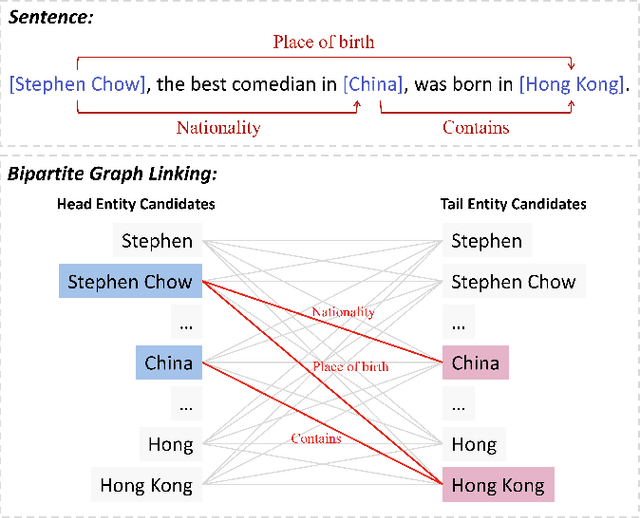
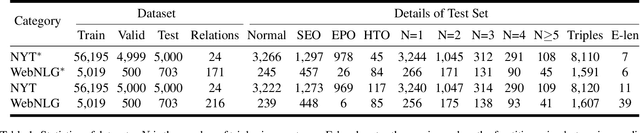
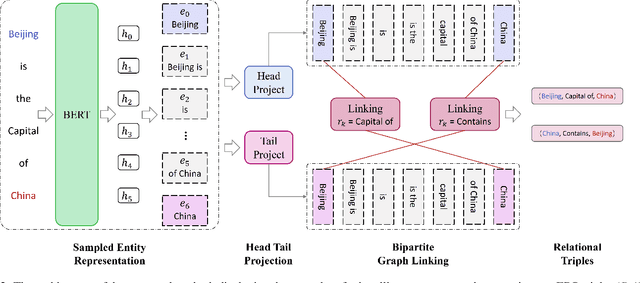
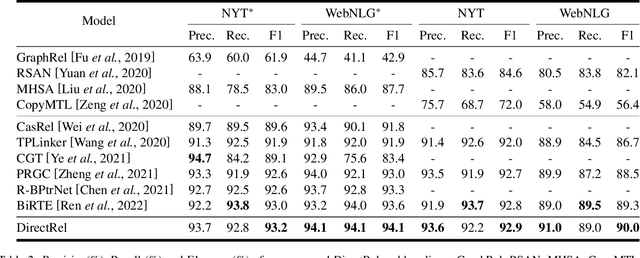
Extracting relational triples from unstructured text is an essential task in natural language processing and knowledge graph construction. Existing approaches usually contain two fundamental steps: (1) finding the boundary positions of head and tail entities; (2) concatenating specific tokens to form triples. However, nearly all previous methods suffer from the problem of error accumulation, i.e., the boundary recognition error of each entity in step (1) will be accumulated into the final combined triples. To solve the problem, in this paper, we introduce a fresh perspective to revisit the triple extraction task, and propose a simple but effective model, named DirectRel. Specifically, the proposed model first generates candidate entities through enumerating token sequences in a sentence, and then transforms the triple extraction task into a linking problem on a "head $\rightarrow$ tail" bipartite graph. By doing so, all triples can be directly extracted in only one step. Extensive experimental results on two widely used datasets demonstrate that the proposed model performs better than the state-of-the-art baselines.
Cross-Lingual Phrase Retrieval
Apr 19, 2022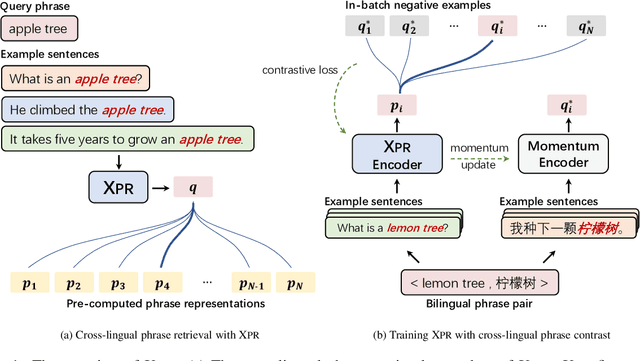

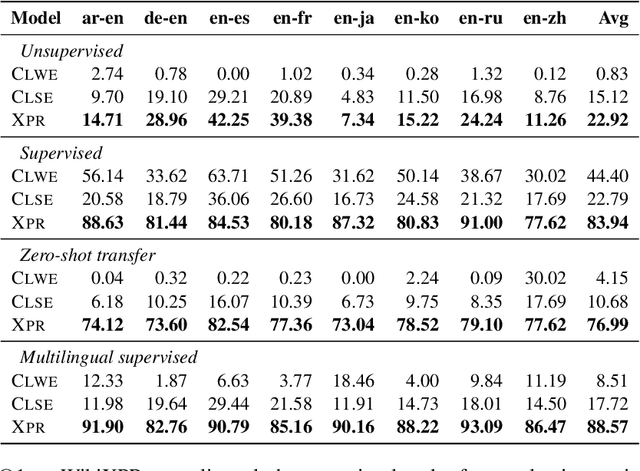
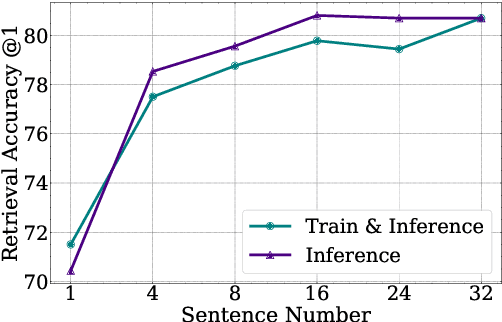
Cross-lingual retrieval aims to retrieve relevant text across languages. Current methods typically achieve cross-lingual retrieval by learning language-agnostic text representations in word or sentence level. However, how to learn phrase representations for cross-lingual phrase retrieval is still an open problem. In this paper, we propose XPR, a cross-lingual phrase retriever that extracts phrase representations from unlabeled example sentences. Moreover, we create a large-scale cross-lingual phrase retrieval dataset, which contains 65K bilingual phrase pairs and 4.2M example sentences in 8 English-centric language pairs. Experimental results show that XPR outperforms state-of-the-art baselines which utilize word-level or sentence-level representations. XPR also shows impressive zero-shot transferability that enables the model to perform retrieval in an unseen language pair during training. Our dataset, code, and trained models are publicly available at www.github.com/cwszz/XPR/.