 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD3T-GAN: Data-Dependent Domain Transfer GANs for Few-shot Image Generation
May 12, 2022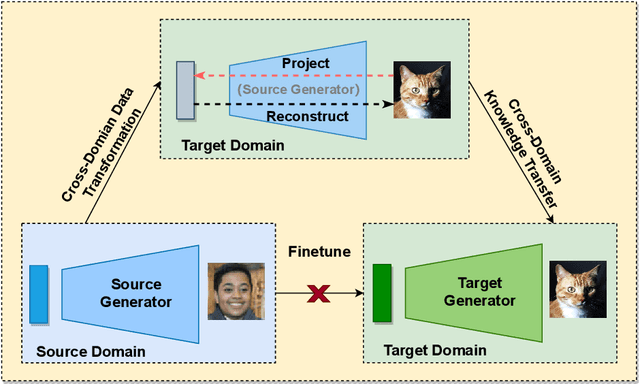
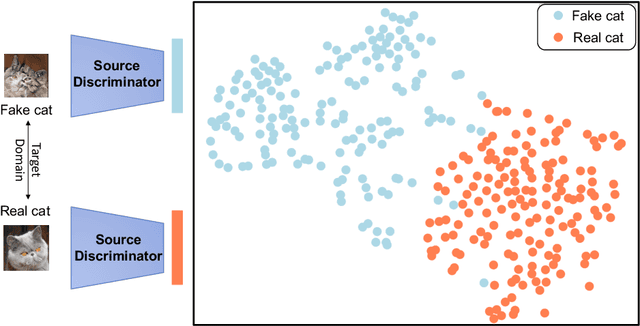
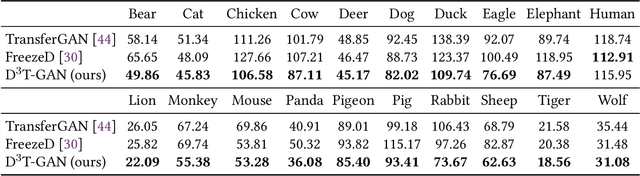
As an important and challenging problem, few-shot image generation aims at generating realistic images through training a GAN model given few samples. A typical solution for few-shot generation is to transfer a well-trained GAN model from a data-rich source domain to the data-deficient target domain. In this paper, we propose a novel self-supervised transfer scheme termed D3T-GAN, addressing the cross-domain GANs transfer in few-shot image generation. Specifically, we design two individual strategies to transfer knowledge between generators and discriminators, respectively. To transfer knowledge between generators, we conduct a data-dependent transformation, which projects and reconstructs the target samples into the source generator space. Then, we perform knowledge transfer from transformed samples to generated samples. To transfer knowledge between discriminators, we design a multi-level discriminant knowledge distillation from the source discriminator to the target discriminator on both the real and fake samples. Extensive experiments show that our method improve the quality of generated images and achieves the state-of-the-art FID scores on commonly used datasets.
OROS: Orchestrating ROS-driven Collaborative Connected Robots in Mission-Critical Operations
May 06, 2022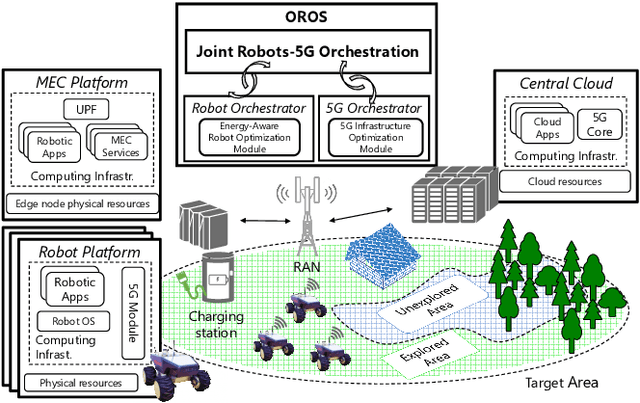
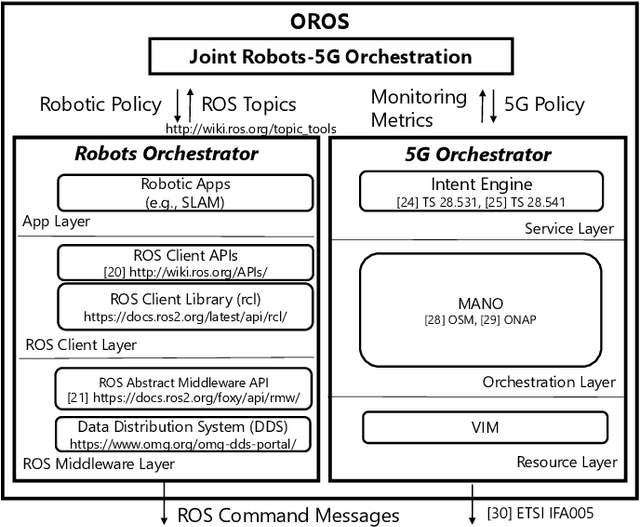
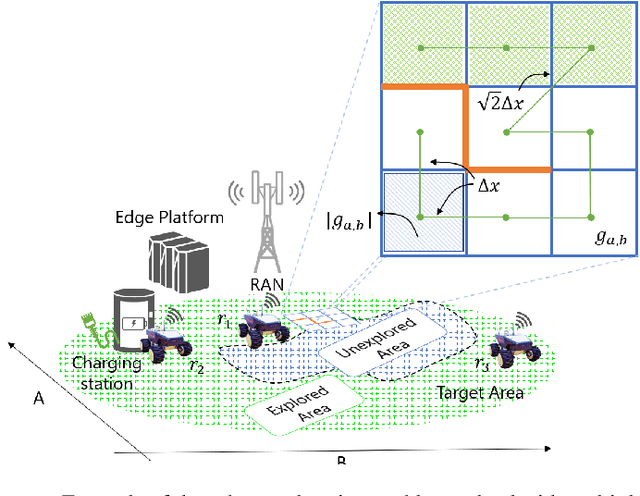
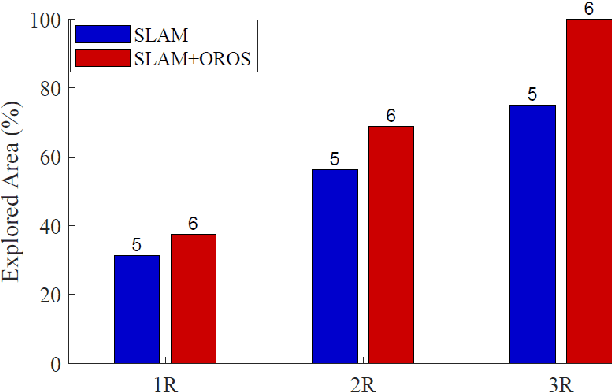
Battery life for collaborative robotics scenarios is a key challenge limiting operational uses and deployment in real life. Mission-Critical tasks are among the most relevant and challenging scenarios. As multiple and heterogeneous on-board sensors are required to explore unknown environments in simultaneous localization and mapping (SLAM) tasks, battery life problems are further exacerbated. Given the time-sensitivity of mission-critical operations, the successful completion of specific tasks in the minimum amount of time is of paramount importance. In this paper, we analyze the benefits of 5G-enabled collaborative robots by enhancing the Robot Operating System (ROS) capabilities with network orchestration features for energy-saving purposes. We propose OROS, a novel orchestration approach that minimizes mission-critical task completion times of 5G-connected robots by jointly optimizing robotic navigation and sensing together with infrastructure resources. Our results show that OROS significantly outperforms state-of-the-art solutions in exploration tasks completion times by exploiting 5G orchestration features for battery life extension.
MIPR:Automatic Annotation of Medical Images with Pixel Rearrangement
Apr 22, 2022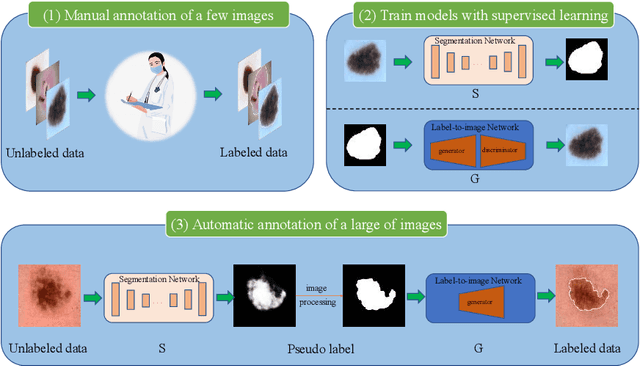
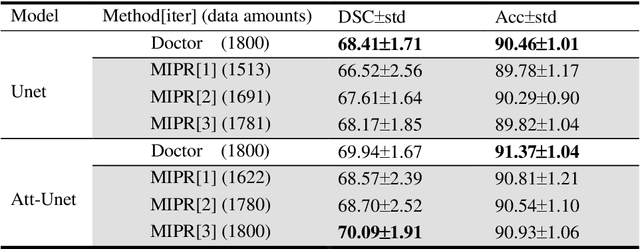
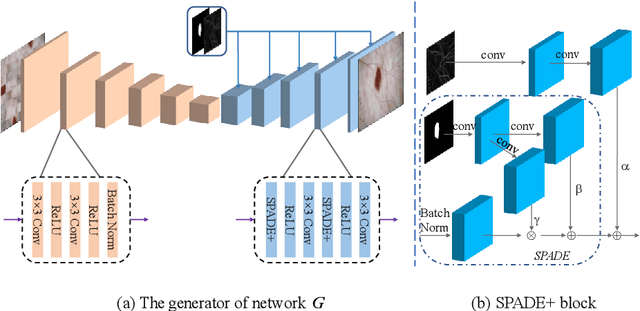
Most of the state-of-the-art semantic segmentation reported in recent years is based on fully supervised deep learning in the medical domain. How?ever, the high-quality annotated datasets require intense labor and domain knowledge, consuming enormous time and cost. Previous works that adopt semi?supervised and unsupervised learning are proposed to address the lack of anno?tated data through assisted training with unlabeled data and achieve good perfor?mance. Still, these methods can not directly get the image annotation as doctors do. In this paper, inspired by self-training of semi-supervised learning, we pro?pose a novel approach to solve the lack of annotated data from another angle, called medical image pixel rearrangement (short in MIPR). The MIPR combines image-editing and pseudo-label technology to obtain labeled data. As the number of iterations increases, the edited image is similar to the original image, and the labeled result is similar to the doctor annotation. Therefore, the MIPR is to get labeled pairs of data directly from amounts of unlabled data with pixel rearrange?ment, which is implemented with a designed conditional Generative Adversarial Networks and a segmentation network. Experiments on the ISIC18 show that the effect of the data annotated by our method for segmentation task is is equal to or even better than that of doctors annotations
Referring Expression Comprehension via Cross-Level Multi-Modal Fusion
Apr 21, 2022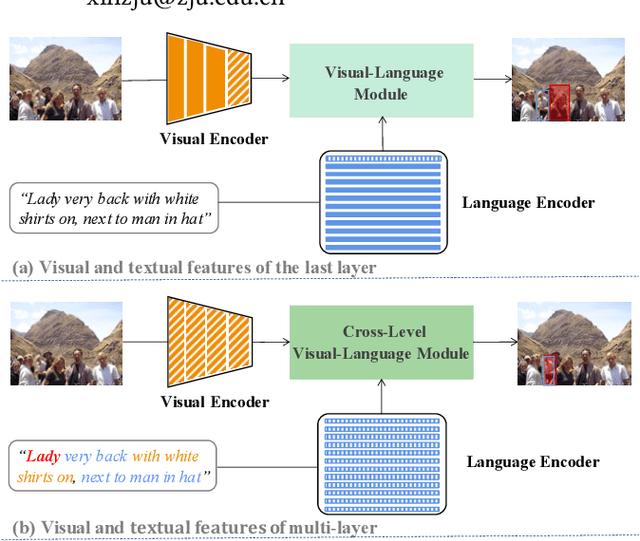
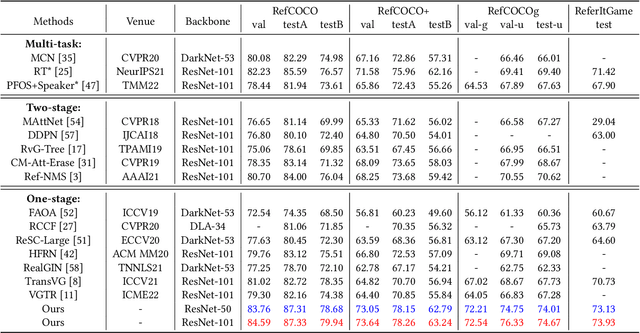
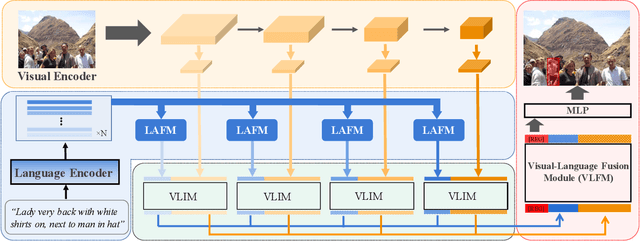

As an important and challenging problem in vision-language tasks, referring expression comprehension (REC) aims to localize the target object specified by a given referring expression. Recently, most of the state-of-the-art REC methods mainly focus on multi-modal fusion while overlooking the inherent hierarchical information contained in visual and language encoders. Considering that REC requires visual and textual hierarchical information for accurate target localization, and encoders inherently extract features in a hierarchical fashion, we propose to effectively utilize the rich hierarchical information contained in different layers of visual and language encoders. To this end, we design a Cross-level Multi-modal Fusion (CMF) framework, which gradually integrates visual and textual features of multi-layer through intra- and inter-modal. Experimental results on RefCOCO, RefCOCO+, RefCOCOg, and ReferItGame datasets demonstrate the proposed framework achieves significant performance improvements over state-of-the-art methods.
RBC: Rectifying the Biased Context in Continual Semantic Segmentation
Mar 16, 2022
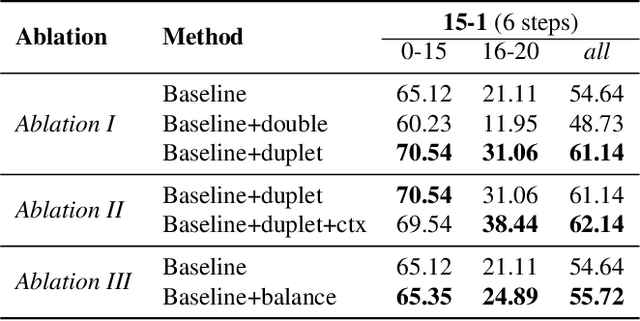
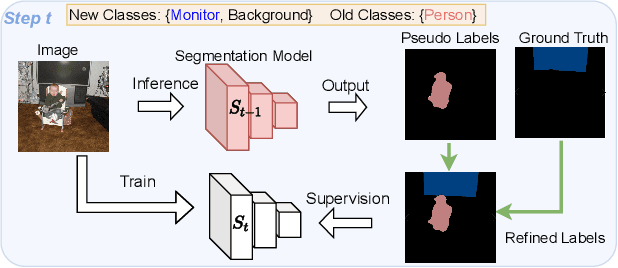
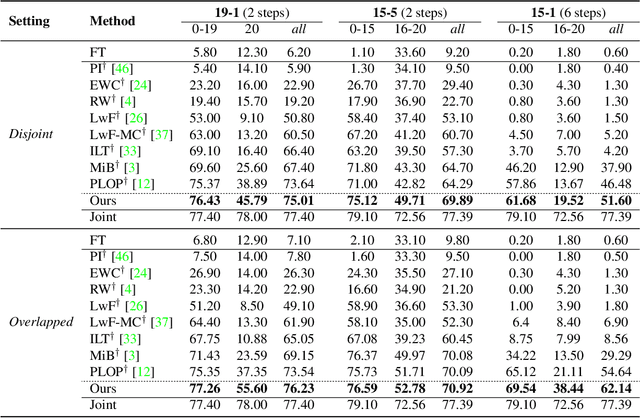
Recent years have witnessed a great development of Convolutional Neural Networks in semantic segmentation, where all classes of training images are simultaneously available. In practice, new images are usually made available in a consecutive manner, leading to a problem called Continual Semantic Segmentation (CSS). Typically, CSS faces the forgetting problem since previous training images are unavailable, and the semantic shift problem of the background class. Considering the semantic segmentation as a context-dependent pixel-level classification task, we explore CSS from a new perspective of context analysis in this paper. We observe that the context of old-class pixels in the new images is much more biased on new classes than that in the old images, which can sharply aggravate the old-class forgetting and new-class overfitting. To tackle the obstacle, we propose a biased-context-rectified CSS framework with a context-rectified image-duplet learning scheme and a biased-context-insensitive consistency loss. Furthermore, we propose an adaptive re-weighting class-balanced learning strategy for the biased class distribution. Our approach outperforms state-of-the-art methods by a large margin in existing CSS scenarios.
A Review on Methods and Applications in Multimodal Deep Learning
Feb 18, 2022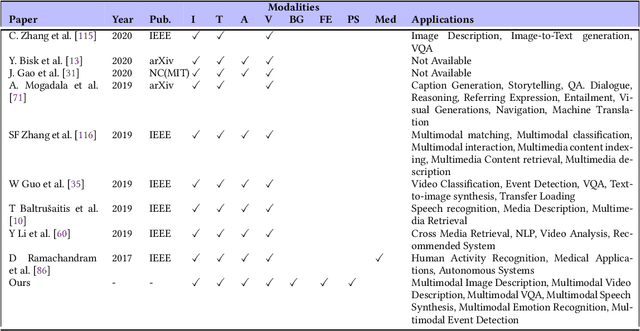
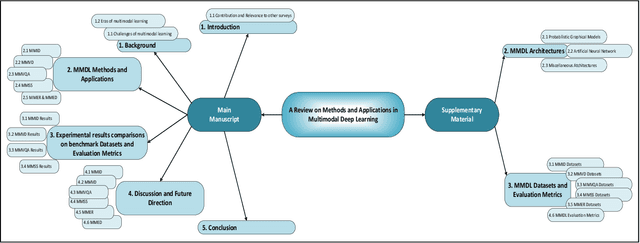
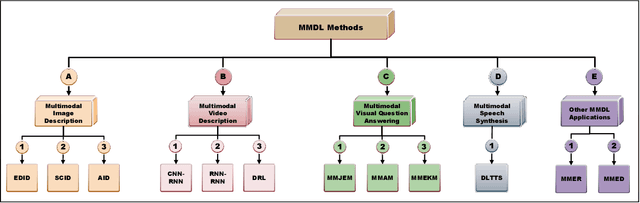
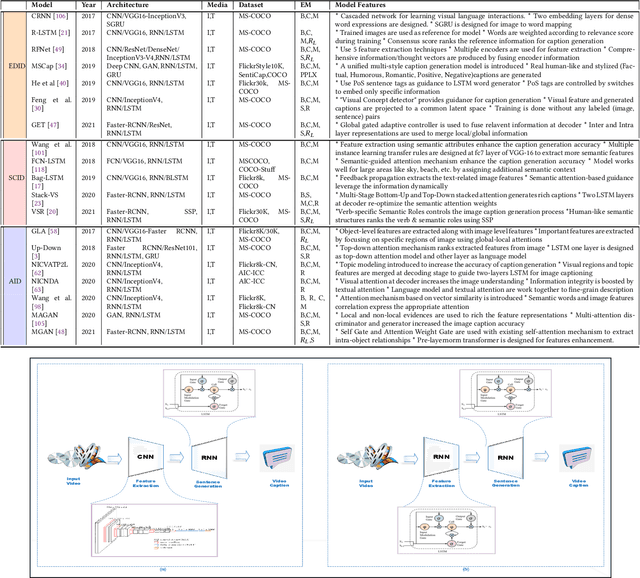
Deep Learning has implemented a wide range of applications and has become increasingly popular in recent years. The goal of multimodal deep learning (MMDL) is to create models that can process and link information using various modalities. Despite the extensive development made for unimodal learning, it still cannot cover all the aspects of human learning. Multimodal learning helps to understand and analyze better when various senses are engaged in the processing of information. This paper focuses on multiple types of modalities, i.e., image, video, text, audio, body gestures, facial expressions, and physiological signals. Detailed analysis of the baseline approaches and an in-depth study of recent advancements during the last five years (2017 to 2021) in multimodal deep learning applications has been provided. A fine-grained taxonomy of various multimodal deep learning methods is proposed, elaborating on different applications in more depth. Lastly, main issues are highlighted separately for each domain, along with their possible future research directions.
* 29 pages. arXiv admin note: substantial text overlap with arXiv:2105.11087
Bias-Eliminated Semantic Refinement for Any-Shot Learning
Feb 10, 2022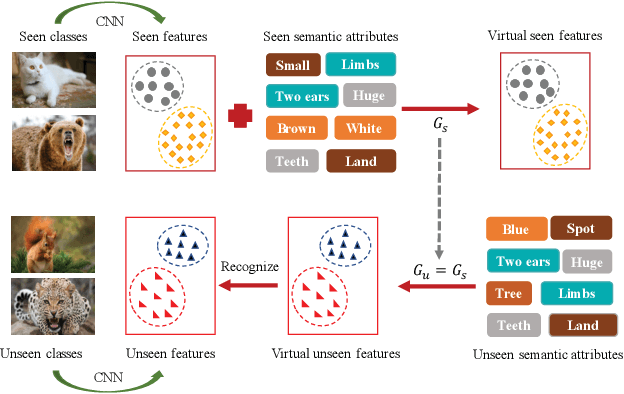
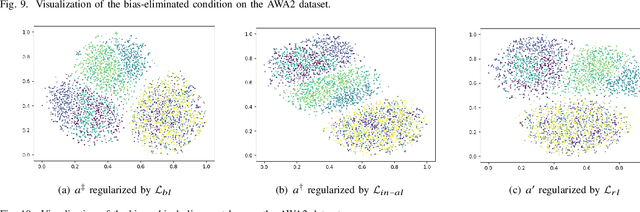
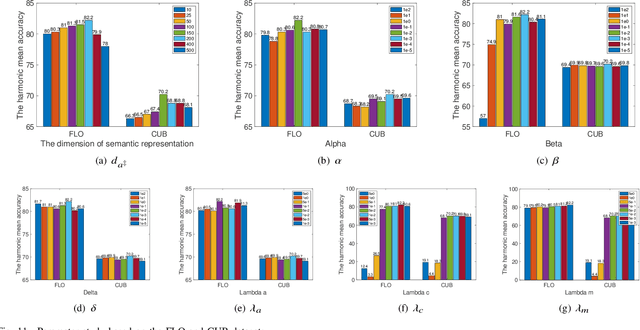
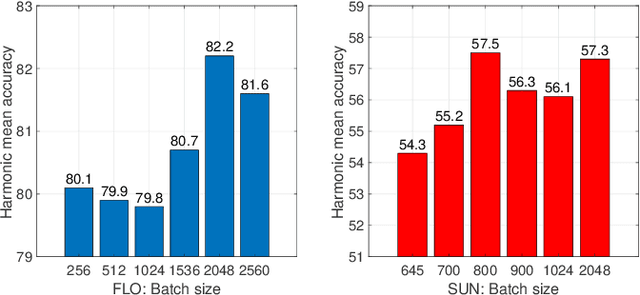
When training samples are scarce, the semantic embedding technique, ie, describing class labels with attributes, provides a condition to generate visual features for unseen objects by transferring the knowledge from seen objects. However, semantic descriptions are usually obtained in an external paradigm, such as manual annotation, resulting in weak consistency between descriptions and visual features. In this paper, we refine the coarse-grained semantic description for any-shot learning tasks, ie, zero-shot learning (ZSL), generalized zero-shot learning (GZSL), and few-shot learning (FSL). A new model, namely, the semantic refinement Wasserstein generative adversarial network (SRWGAN) model, is designed with the proposed multihead representation and hierarchical alignment techniques. Unlike conventional methods, semantic refinement is performed with the aim of identifying a bias-eliminated condition for disjoint-class feature generation and is applicable in both inductive and transductive settings. We extensively evaluate model performance on six benchmark datasets and observe state-of-the-art results for any-shot learning; eg, we obtain 70.2% harmonic accuracy for the Caltech UCSD Birds (CUB) dataset and 82.2% harmonic accuracy for the Oxford Flowers (FLO) dataset in the standard GZSL setting. Various visualizations are also provided to show the bias-eliminated generation of SRWGAN. Our code is available.
Dual-Tasks Siamese Transformer Framework for Building Damage Assessment
Jan 26, 2022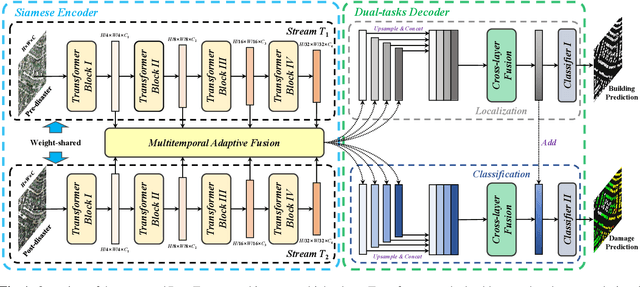
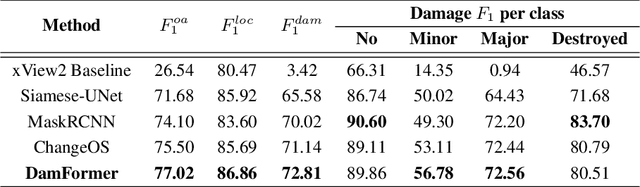
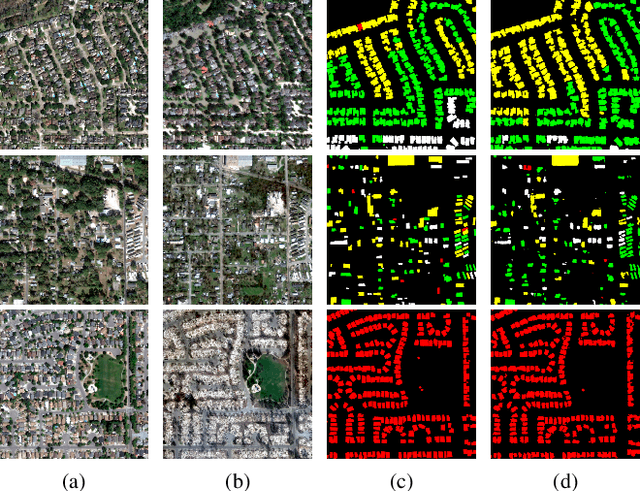
Accurate and fine-grained information about the extent of damage to buildings is essential for humanitarian relief and disaster response. However, as the most commonly used architecture in remote sensing interpretation tasks, Convolutional Neural Networks (CNNs) have limited ability to model the non-local relationship between pixels. Recently, Transformer architecture first proposed for modeling long-range dependency in natural language processing has shown promising results in computer vision tasks. Considering the frontier advances of Transformer architecture in the computer vision field, in this paper, we present the first attempt at designing a Transformer-based damage assessment architecture (DamFormer). In DamFormer, a siamese Transformer encoder is first constructed to extract non-local and representative deep features from input multitemporal image-pairs. Then, a multitemporal fusion module is designed to fuse information for downstream tasks. Finally, a lightweight dual-tasks decoder aggregates multi-level features for final prediction. To the best of our knowledge, it is the first time that such a deep Transformer-based network is proposed for multitemporal remote sensing interpretation tasks. The experimental results on the large-scale damage assessment dataset xBD demonstrate the potential of the Transformer-based architecture.
Phocus: Picking Valuable Research from a Sea of Citations
Jan 14, 2022
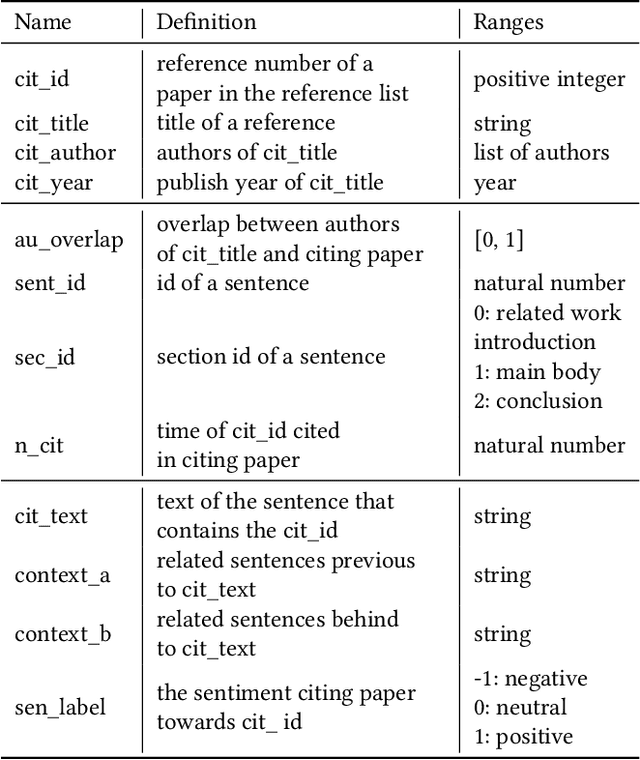
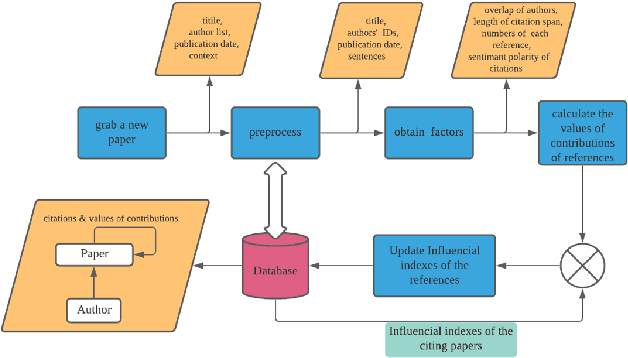

The deluge of new papers has significantly blocked the development of academics, which is mainly caused by author-level and publication-level evaluation metrics that only focus on quantity. Those metrics have resulted in several severe problems that trouble scholars focusing on the important research direction for a long time and even promote an impetuous academic atmosphere. To solve those problems, we propose Phocus, a novel academic evaluation mechanism for authors and papers. Phocus analyzes the sentence containing a citation and its contexts to predict the sentiment towards the corresponding reference. Combining others factors, Phocus classifies citations coarsely, ranks all references within a paper, and utilizes the results of the classifier and the ranking model to get the local influential factor of a reference to the citing paper. The global influential factor of the reference to the citing paper is the product of the local influential factor and the total influential factor of the citing paper. Consequently, an author's academic influential factor is the sum of his contributions to each paper he co-authors.
CFNet: Learning Correlation Functions for One-Stage Panoptic Segmentation
Jan 13, 2022
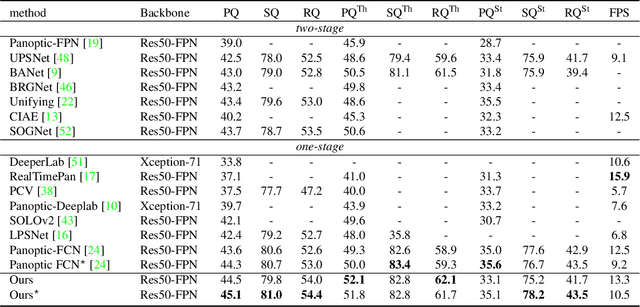
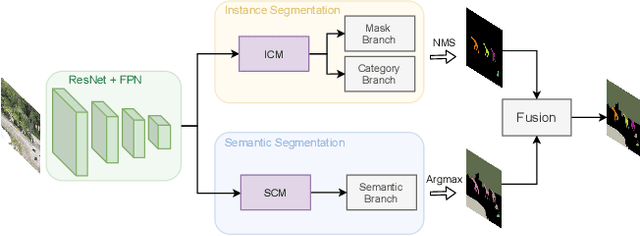
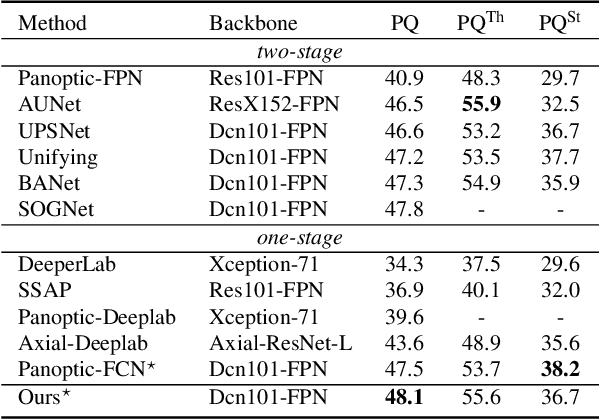
Recently, there is growing attention on one-stage panoptic segmentation methods which aim to segment instances and stuff jointly within a fully convolutional pipeline efficiently. However, most of the existing works directly feed the backbone features to various segmentation heads ignoring the demands for semantic and instance segmentation are different: The former needs semantic-level discriminative features, while the latter requires features to be distinguishable across instances. To alleviate this, we propose to first predict semantic-level and instance-level correlations among different locations that are utilized to enhance the backbone features, and then feed the improved discriminative features into the corresponding segmentation heads, respectively. Specifically, we organize the correlations between a given location and all locations as a continuous sequence and predict it as a whole. Considering that such a sequence can be extremely complicated, we adopt Discrete Fourier Transform (DFT), a tool that can approximate an arbitrary sequence parameterized by amplitudes and phrases. For different tasks, we generate these parameters from the backbone features in a fully convolutional way which is optimized implicitly by corresponding tasks. As a result, these accurate and consistent correlations contribute to producing plausible discriminative features which meet the requirements of the complicated panoptic segmentation task. To verify the effectiveness of our methods, we conduct experiments on several challenging panoptic segmentation datasets and achieve state-of-the-art performance on MS COCO with $45.1$\% PQ and ADE20k with $32.6$\% PQ.