 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal LLMs under Pairwise Modalities
May 20, 2026Despite the impressive results achieved by multimodal large language models (MLLMs), their training typically relies on jointly curated multimodal data, requiring substantial human effort to construct multi-way aligned datasets and thereby limiting scalability across domains. In this work, we explore training MLLMs by only leveraging multiple paired modalities as a surrogate for the full joint multimodal distribution. Specifically, we first provide a theoretical analysis of the conditions under which the representations are identifiable with only observing pairwise modalities. Building on this analysis, we propose a representation learning framework for aligning latent representations across modalities using only pairwise data. The framework consists of two stages: latent representation alignment and cross-modal recomposition. Specifically, in the first stage, we learn the shared latent space across modalities by both self-modal reconstruction and pair-wise contrastive learning. We also incorporate an inductive bias in the contrastive learning process by partially aligning and minimal latent specification. In stage two, we integrate the encoder of newly introduced modalities with the decoders of the pre-trained modalities to facilitate cross-modal transfer and generation. We evaluate our method by newly adding 3D point clouds and tactile modalities into pre-trained MLLMs with three modality pairs and show that, by learning an aligned latent representation space, our model achieves strong cross-modal performance.
A Dialogue between Causal and Traditional Representation Learning: Toward Mutual Benefits in a Unified Formulation
May 20, 2026Causal representation learning (CRL) and traditional representation learning have largely developed along different trajectories. Traditional representation learning has been driven mainly by applications and empirical objectives, whereas CRL has focused more on theoretical questions, particularly identifiability. This difference in emphasis has created a gap between the two fields in terminology, problem formulation, and evaluation, limiting communication and sometimes leading to disconnected or redundant efforts. In this paper, we argue that these two fields should be brought into dialogue rather than treated as separate paradigms. To this end, we introduce a unified formulation in which the representation learning is characterized by two components: a task component, which specifies what information the learned representation is required to preserve, and a constraint component, which specifies what structure is imposed on the latent space. Under this formulation, the benefits run in both directions. CRL provides theoretical tools for understanding when structured latent constraints are useful or necessary, while traditional representation learning offers practical insights on task design and objective choice that can improve the development of CRL methods. To illustrate this interaction, we experimentally study how different task components affect the behavior of CRL methods under different structured constraints. Results on CausalVerse show that the effectiveness of causal constraints depends strongly on the tasks with which they are paired.
Should Bias Always be Eliminated? A Principled Framework to Use Data Bias for OOD Generation
Jul 22, 2025



Most existing methods for adapting models to out-of-distribution (OOD) domains rely on invariant representation learning to eliminate the influence of biased features. However, should bias always be eliminated -- and if not, when should it be retained, and how can it be leveraged? To address these questions, we first present a theoretical analysis that explores the conditions under which biased features can be identified and effectively utilized. Building on this theoretical foundation, we introduce a novel framework that strategically leverages bias to complement invariant representations during inference. The framework comprises two key components that leverage bias in both direct and indirect ways: (1) using invariance as guidance to extract predictive ingredients from bias, and (2) exploiting identified bias to estimate the environmental condition and then use it to explore appropriate bias-aware predictors to alleviate environment gaps. We validate our approach through experiments on both synthetic datasets and standard domain generalization benchmarks. Results consistently demonstrate that our method outperforms existing approaches, underscoring its robustness and adaptability.
Reflection-Window Decoding: Text Generation with Selective Refinement
Feb 05, 2025



The autoregressive decoding for text generation in large language models (LLMs), while widely used, is inherently suboptimal due to the lack of a built-in mechanism to perform refinement and/or correction of the generated content. In this paper, we consider optimality in terms of the joint probability over the generated response, when jointly considering all tokens at the same time. We theoretically characterize the potential deviation of the autoregressively generated response from its globally optimal counterpart that is of the same length. Our analysis suggests that we need to be cautious when noticeable uncertainty arises during text generation, which may signal the sub-optimality of the generation history. To address the pitfall of autoregressive decoding for text generation, we propose an approach that incorporates a sliding reflection window and a pausing criterion, such that refinement and generation can be carried out interchangeably as the decoding proceeds. Our selective refinement framework strikes a balance between efficiency and optimality, and our extensive experimental results demonstrate the effectiveness of our approach.
Phocus: Picking Valuable Research from a Sea of Citations
Jan 14, 2022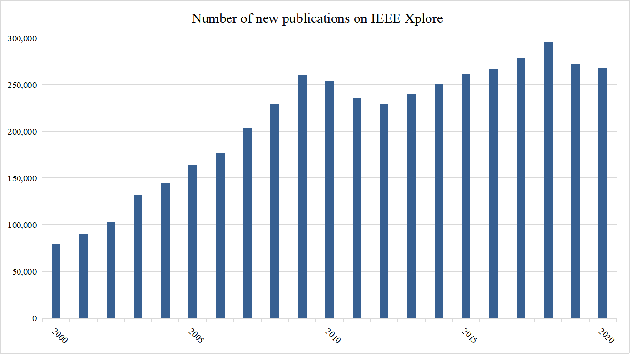
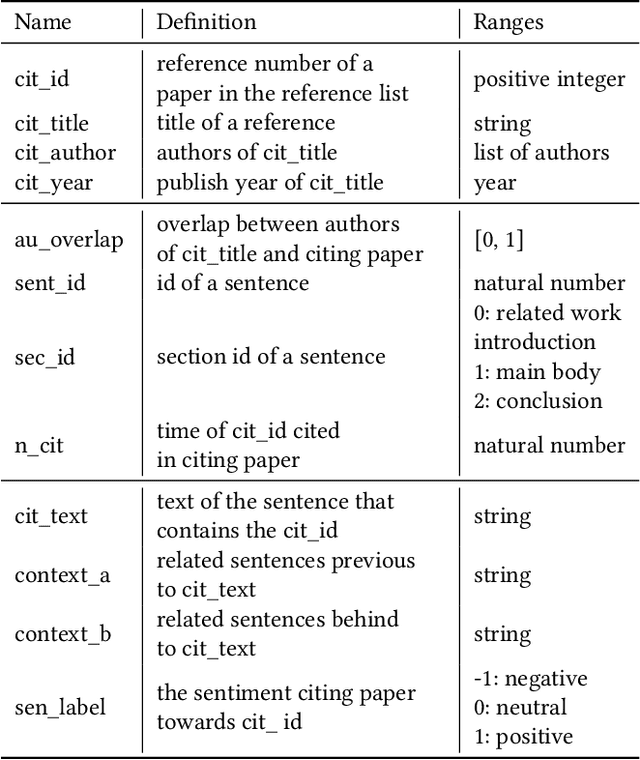
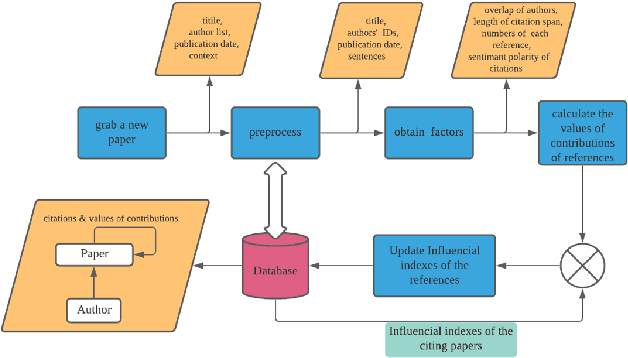

The deluge of new papers has significantly blocked the development of academics, which is mainly caused by author-level and publication-level evaluation metrics that only focus on quantity. Those metrics have resulted in several severe problems that trouble scholars focusing on the important research direction for a long time and even promote an impetuous academic atmosphere. To solve those problems, we propose Phocus, a novel academic evaluation mechanism for authors and papers. Phocus analyzes the sentence containing a citation and its contexts to predict the sentiment towards the corresponding reference. Combining others factors, Phocus classifies citations coarsely, ranks all references within a paper, and utilizes the results of the classifier and the ranking model to get the local influential factor of a reference to the citing paper. The global influential factor of the reference to the citing paper is the product of the local influential factor and the total influential factor of the citing paper. Consequently, an author's academic influential factor is the sum of his contributions to each paper he co-authors.