 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCFNet: Learning Correlation Functions for One-Stage Panoptic Segmentation
Jan 13, 2022
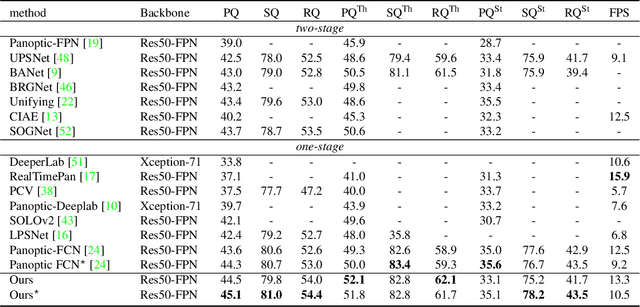
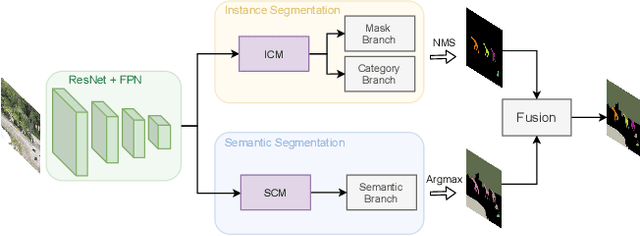
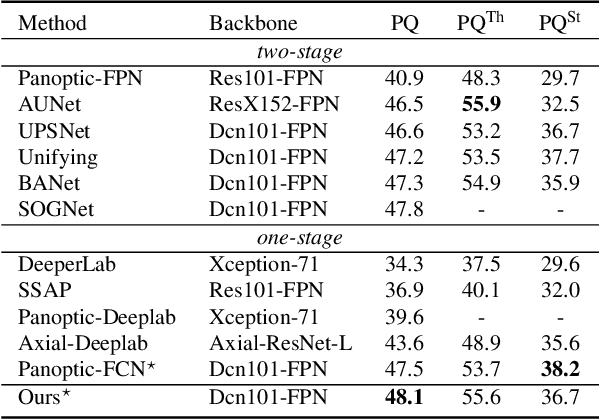
Recently, there is growing attention on one-stage panoptic segmentation methods which aim to segment instances and stuff jointly within a fully convolutional pipeline efficiently. However, most of the existing works directly feed the backbone features to various segmentation heads ignoring the demands for semantic and instance segmentation are different: The former needs semantic-level discriminative features, while the latter requires features to be distinguishable across instances. To alleviate this, we propose to first predict semantic-level and instance-level correlations among different locations that are utilized to enhance the backbone features, and then feed the improved discriminative features into the corresponding segmentation heads, respectively. Specifically, we organize the correlations between a given location and all locations as a continuous sequence and predict it as a whole. Considering that such a sequence can be extremely complicated, we adopt Discrete Fourier Transform (DFT), a tool that can approximate an arbitrary sequence parameterized by amplitudes and phrases. For different tasks, we generate these parameters from the backbone features in a fully convolutional way which is optimized implicitly by corresponding tasks. As a result, these accurate and consistent correlations contribute to producing plausible discriminative features which meet the requirements of the complicated panoptic segmentation task. To verify the effectiveness of our methods, we conduct experiments on several challenging panoptic segmentation datasets and achieve state-of-the-art performance on MS COCO with $45.1$\% PQ and ADE20k with $32.6$\% PQ.
Test-Time Detection of Backdoor Triggers for Poisoned Deep Neural Networks
Dec 06, 2021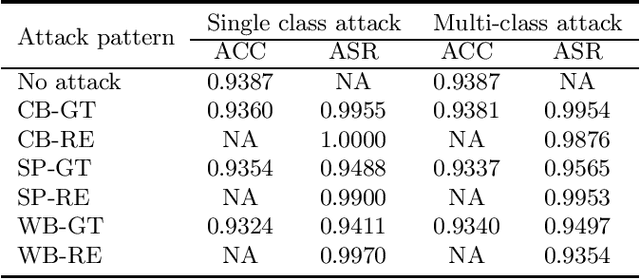
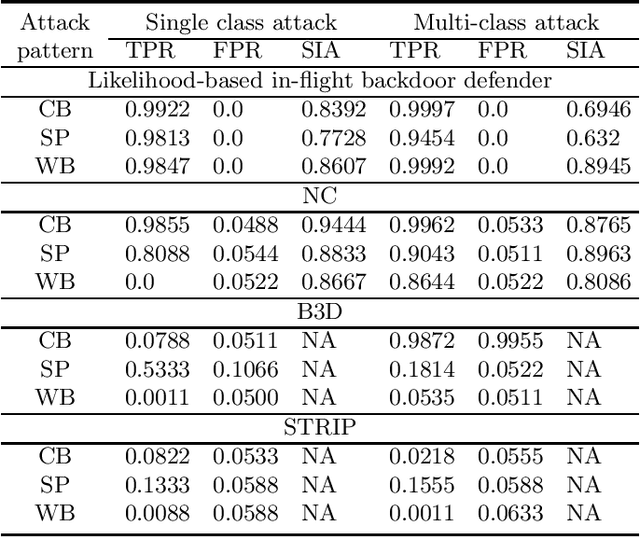

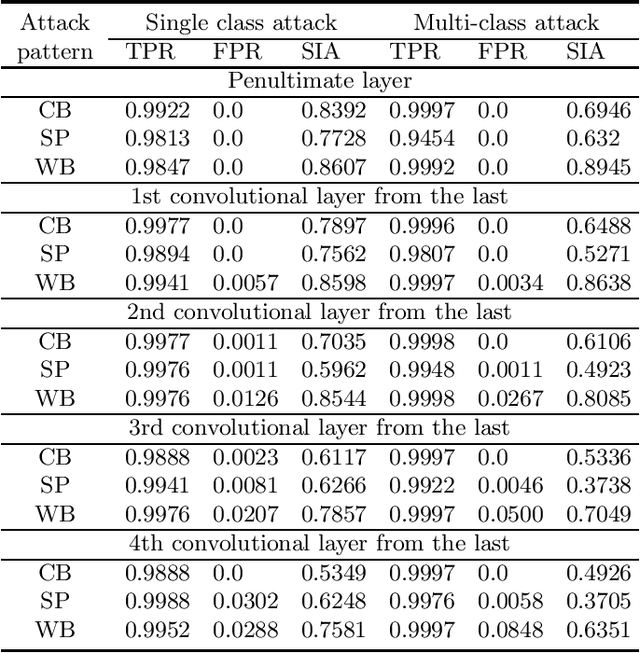
Backdoor (Trojan) attacks are emerging threats against deep neural networks (DNN). A DNN being attacked will predict to an attacker-desired target class whenever a test sample from any source class is embedded with a backdoor pattern; while correctly classifying clean (attack-free) test samples. Existing backdoor defenses have shown success in detecting whether a DNN is attacked and in reverse-engineering the backdoor pattern in a "post-training" regime: the defender has access to the DNN to be inspected and a small, clean dataset collected independently, but has no access to the (possibly poisoned) training set of the DNN. However, these defenses neither catch culprits in the act of triggering the backdoor mapping, nor mitigate the backdoor attack at test-time. In this paper, we propose an "in-flight" defense against backdoor attacks on image classification that 1) detects use of a backdoor trigger at test-time; and 2) infers the class of origin (source class) for a detected trigger example. The effectiveness of our defense is demonstrated experimentally against different strong backdoor attacks.
Detecting Backdoor Attacks Against Point Cloud Classifiers
Oct 20, 2021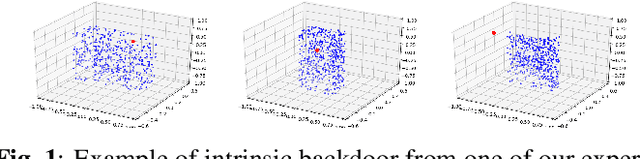

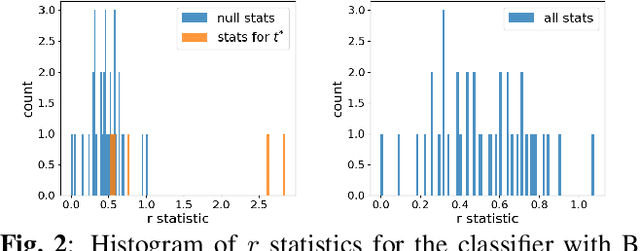
Backdoor attacks (BA) are an emerging threat to deep neural network classifiers. A classifier being attacked will predict to the attacker's target class when a test sample from a source class is embedded with the backdoor pattern (BP). Recently, the first BA against point cloud (PC) classifiers was proposed, creating new threats to many important applications including autonomous driving. Such PC BAs are not detectable by existing BA defenses due to their special BP embedding mechanism. In this paper, we propose a reverse-engineering defense that infers whether a PC classifier is backdoor attacked, without access to its training set or to any clean classifiers for reference. The effectiveness of our defense is demonstrated on the benchmark ModeNet40 dataset for PCs.
MGH: Metadata Guided Hypergraph Modeling for Unsupervised Person Re-identification
Oct 12, 2021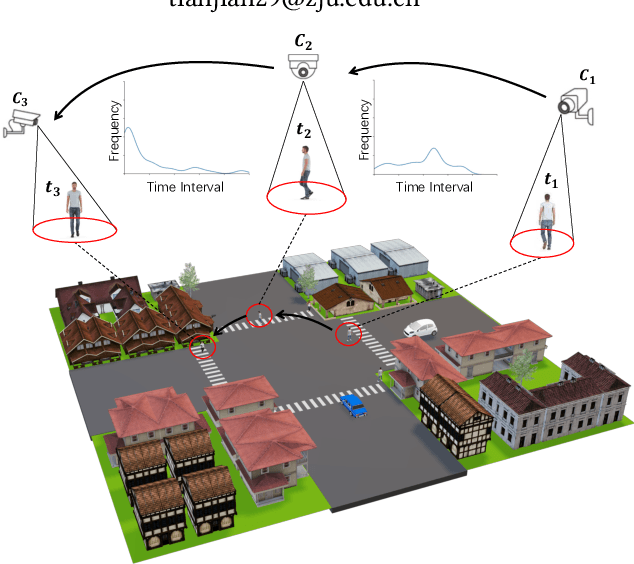

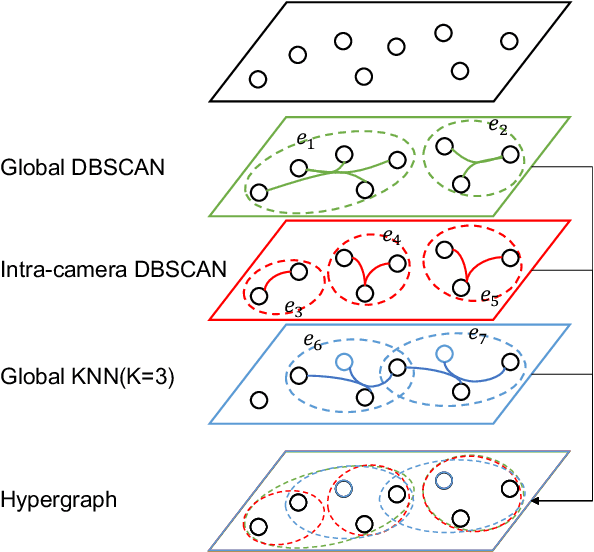
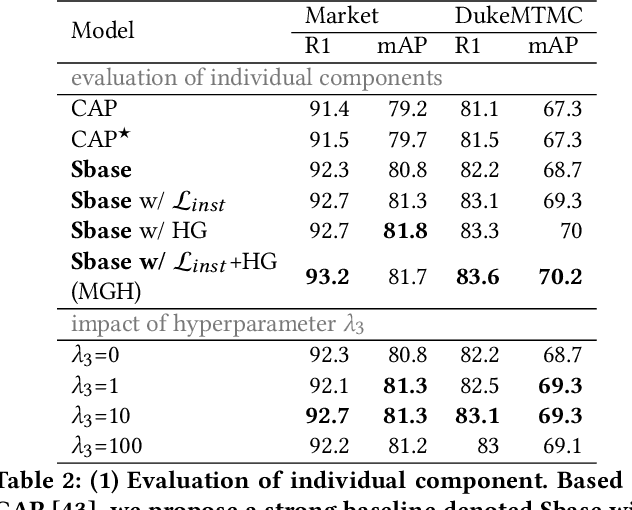
As a challenging task, unsupervised person ReID aims to match the same identity with query images which does not require any labeled information. In general, most existing approaches focus on the visual cues only, leaving potentially valuable auxiliary metadata information (e.g., spatio-temporal context) unexplored. In the real world, such metadata is normally available alongside captured images, and thus plays an important role in separating several hard ReID matches. With this motivation in mind, we propose~\textbf{MGH}, a novel unsupervised person ReID approach that uses meta information to construct a hypergraph for feature learning and label refinement. In principle, the hypergraph is composed of camera-topology-aware hyperedges, which can model the heterogeneous data correlations across cameras. Taking advantage of label propagation on the hypergraph, the proposed approach is able to effectively refine the ReID results, such as correcting the wrong labels or smoothing the noisy labels. Given the refined results, We further present a memory-based listwise loss to directly optimize the average precision in an approximate manner. Extensive experiments on three benchmarks demonstrate the effectiveness of the proposed approach against the state-of-the-art.
Backdoor Attack and Defense for Deep Regression
Sep 06, 2021
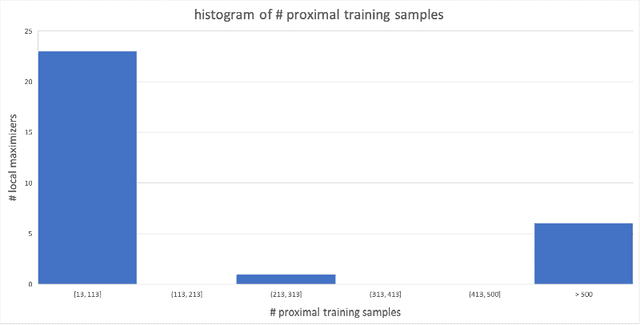
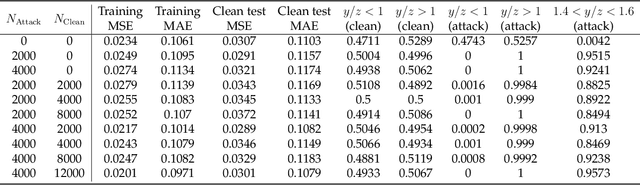
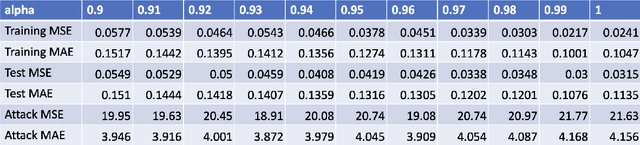
We demonstrate a backdoor attack on a deep neural network used for regression. The backdoor attack is localized based on training-set data poisoning wherein the mislabeled samples are surrounded by correctly labeled ones. We demonstrate how such localization is necessary for attack success. We also study the performance of a backdoor defense using gradient-based discovery of local error maximizers. Local error maximizers which are associated with significant (interpolation) error, and are proximal to many training samples, are suspicious. This method is also used to accurately train for deep regression in the first place by active (deep) learning leveraging an "oracle" capable of providing real-valued supervision (a regression target) for samples. Such oracles, including traditional numerical solvers of PDEs or SDEs using finite difference or Monte Carlo approximations, are far more computationally costly compared to deep regression.
Robust and Active Learning for Deep Neural Network Regression
Jul 28, 2021
We describe a gradient-based method to discover local error maximizers of a deep neural network (DNN) used for regression, assuming the availability of an "oracle" capable of providing real-valued supervision (a regression target) for samples. For example, the oracle could be a numerical solver which, operationally, is much slower than the DNN. Given a discovered set of local error maximizers, the DNN is either fine-tuned or retrained in the manner of active learning.
A Survey on Deep Domain Adaptation and Tiny Object Detection Challenges, Techniques and Datasets
Jul 16, 2021

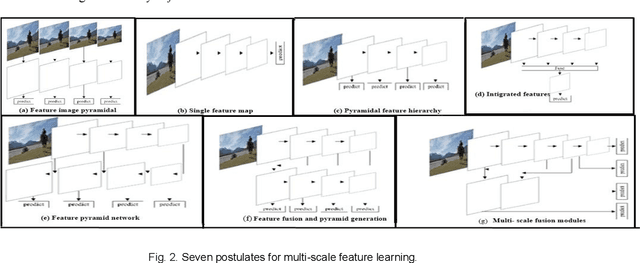
This survey paper specially analyzed computer vision-based object detection challenges and solutions by different techniques. We mainly highlighted object detection by three different trending strategies, i.e., 1) domain adaptive deep learning-based approaches (discrepancy-based, Adversarial-based, Reconstruction-based, Hybrid). We examined general as well as tiny object detection-related challenges and offered solutions by historical and comparative analysis. In part 2) we mainly focused on tiny object detection techniques (multi-scale feature learning, Data augmentation, Training strategy (TS), Context-based detection, GAN-based detection). In part 3), To obtain knowledge-able findings, we discussed different object detection methods, i.e., convolutions and convolutional neural networks (CNN), pooling operations with trending types. Furthermore, we explained results with the help of some object detection algorithms, i.e., R-CNN, Fast R-CNN, Faster R-CNN, YOLO, and SSD, which are generally considered the base bone of CV, CNN, and OD. We performed comparative analysis on different datasets such as MS-COCO, PASCAL VOC07,12, and ImageNet to analyze results and present findings. At the end, we showed future directions with existing challenges of the field. In the future, OD methods and models can be analyzed for real-time object detection, tracking strategies.
Multitask Identity-Aware Image Steganography via Minimax Optimization
Jul 13, 2021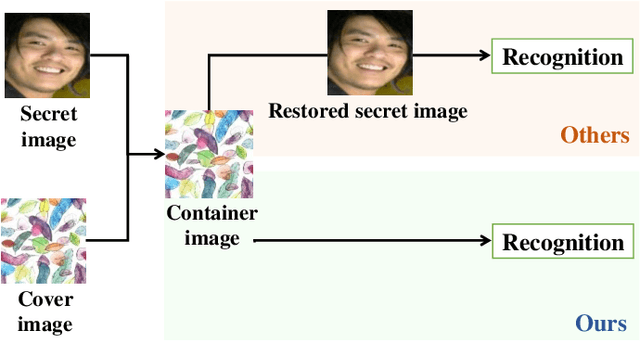

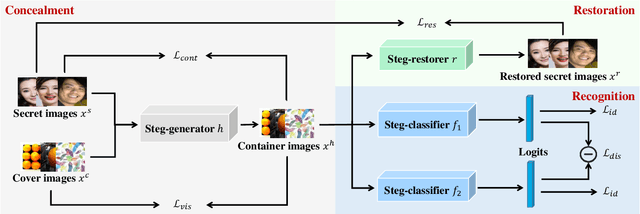
High-capacity image steganography, aimed at concealing a secret image in a cover image, is a technique to preserve sensitive data, e.g., faces and fingerprints. Previous methods focus on the security during transmission and subsequently run a risk of privacy leakage after the restoration of secret images at the receiving end. To address this issue, we propose a framework, called Multitask Identity-Aware Image Steganography (MIAIS), to achieve direct recognition on container images without restoring secret images. The key issue of the direct recognition is to preserve identity information of secret images into container images and make container images look similar to cover images at the same time. Thus, we introduce a simple content loss to preserve the identity information, and design a minimax optimization to deal with the contradictory aspects. We demonstrate that the robustness results can be transferred across different cover datasets. In order to be flexible for the secret image restoration in some cases, we incorporate an optional restoration network into our method, providing a multitask framework. The experiments under the multitask scenario show the effectiveness of our framework compared with other visual information hiding methods and state-of-the-art high-capacity image steganography methods.
When Video Classification Meets Incremental Classes
Jun 30, 2021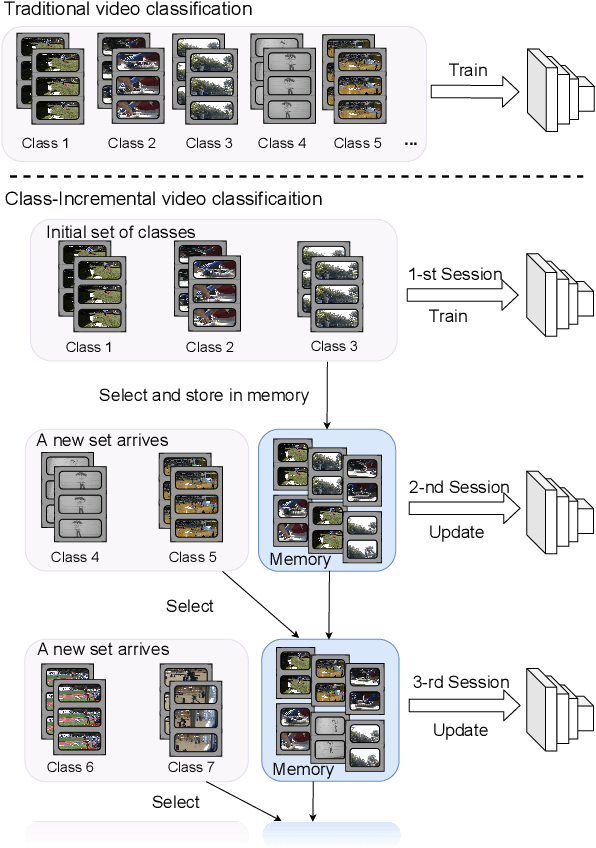

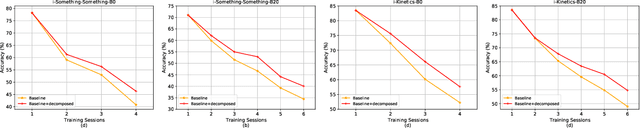
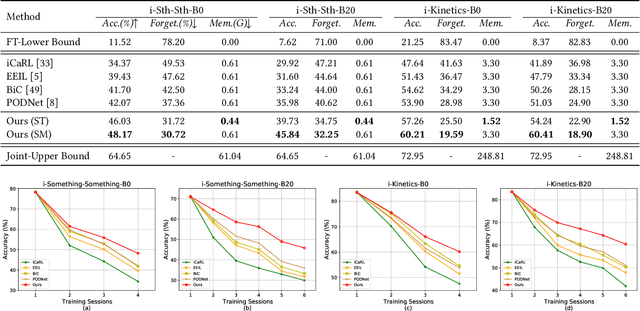
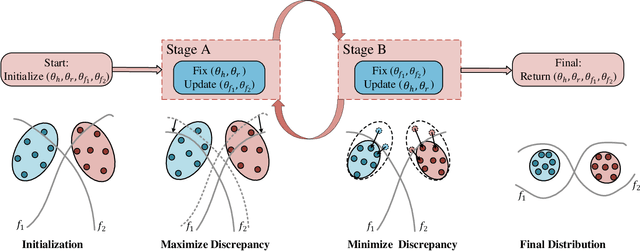
With the rapid development of social media, tremendous videos with new classes are generated daily, which raise an urgent demand for video classification methods that can continuously update new classes while maintaining the knowledge of old videos with limited storage and computing resources. In this paper, we summarize this task as \textit{Class-Incremental Video Classification (CIVC)} and propose a novel framework to address it. As a subarea of incremental learning tasks, the challenge of \textit{catastrophic forgetting} is unavoidable in CIVC. To better alleviate it, we utilize some characteristics of videos. First, we decompose the spatio-temporal knowledge before distillation rather than treating it as a whole in the knowledge transfer process; trajectory is also used to refine the decomposition. Second, we propose a dual granularity exemplar selection method to select and store representative video instances of old classes and key-frames inside videos under a tight storage budget. We benchmark our method and previous SOTA class-incremental learning methods on Something-Something V2 and Kinetics datasets, and our method outperforms previous methods significantly.
Progressive Class-based Expansion Learning For Image Classification
Jun 28, 2021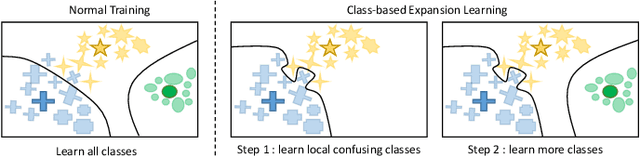
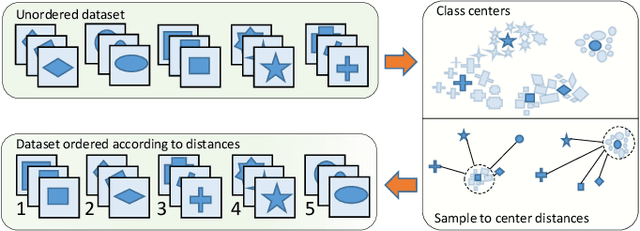
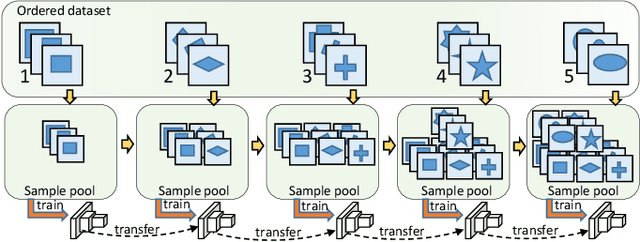
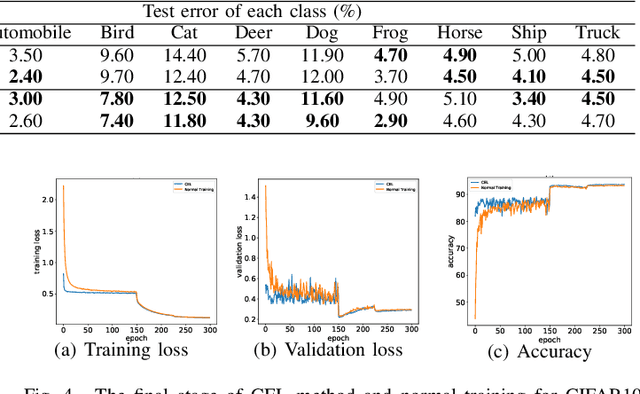
In this paper, we propose a novel image process scheme called class-based expansion learning for image classification, which aims at improving the supervision-stimulation frequency for the samples of the confusing classes. Class-based expansion learning takes a bottom-up growing strategy in a class-based expansion optimization fashion, which pays more attention to the quality of learning the fine-grained classification boundaries for the preferentially selected classes. Besides, we develop a class confusion criterion to select the confusing class preferentially for training. In this way, the classification boundaries of the confusing classes are frequently stimulated, resulting in a fine-grained form. Experimental results demonstrate the effectiveness of the proposed scheme on several benchmarks.