 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Resource Named Entity Recognition: Can One-vs-All AUC Maximization Help?
Nov 02, 2023Named entity recognition (NER), a task that identifies and categorizes named entities such as persons or organizations from text, is traditionally framed as a multi-class classification problem. However, this approach often overlooks the issues of imbalanced label distributions, particularly in low-resource settings, which is common in certain NER contexts, like biomedical NER (bioNER). To address these issues, we propose an innovative reformulation of the multi-class problem as a one-vs-all (OVA) learning problem and introduce a loss function based on the area under the receiver operating characteristic curve (AUC). To enhance the efficiency of our OVA-based approach, we propose two training strategies: one groups labels with similar linguistic characteristics, and another employs meta-learning. The superiority of our approach is confirmed by its performance, which surpasses traditional NER learning in varying NER settings.
Reward Engineering for Generating Semi-structured Explanation
Sep 15, 2023



Semi-structured explanation depicts the implicit process of a reasoner with an explicit representation. This explanation highlights how available information in a specific query is supplemented with information a reasoner produces from its internal weights towards generating an answer. Despite the recent improvements in generative capabilities of language models, producing structured explanations to verify model's true reasoning capabilities remains a challenge. This issue is particularly pronounced for not-so-large LMs, as the reasoner is expected to couple a sequential answer with a structured explanation which embodies both the correct presentation and the correct reasoning process. In this work, we first underscore the limitations of supervised fine-tuning (SFT) in tackling this challenge, and then introduce a carefully crafted reward engineering method in reinforcement learning (RL) to better address this problem. We investigate multiple reward aggregation methods and provide a detailed discussion which sheds light on the promising potential of RL for future research. Our proposed reward on two semi-structured explanation generation benchmarks (ExplaGraph and COPA-SSE) achieves new state-of-the-art results.
A Survey on Out-of-Distribution Evaluation of Neural NLP Models
Jun 27, 2023



Adversarial robustness, domain generalization and dataset biases are three active lines of research contributing to out-of-distribution (OOD) evaluation on neural NLP models. However, a comprehensive, integrated discussion of the three research lines is still lacking in the literature. In this survey, we 1) compare the three lines of research under a unifying definition; 2) summarize the data-generating processes and evaluation protocols for each line of research; and 3) emphasize the challenges and opportunities for future work.
PiVe: Prompting with Iterative Verification Improving Graph-based Generative Capability of LLMs
May 21, 2023Large language models (LLMs) have shown great abilities of solving various natural language tasks in different domains. Due to the training objective of LLMs and their pretraining data, LLMs are not very well equipped for tasks involving structured data generation. We propose a framework, Prompting with Iterative Verification (PiVe), to improve graphbased generative capability of LLMs. We show how a small language model could be trained to act as a verifier module for the output of an LLM (i.e., ChatGPT), and to iteratively improve its performance via fine-grained corrective instructions. Additionally, we show how the verifier module could apply iterative corrections offline for a more cost-effective solution to the text-to-graph generation task. Experiments on three graph-based datasets show consistent improvement gained via PiVe. Additionally, we highlight how the proposed verifier module can be used as a data augmentation tool to help improve the quality of automatically generated parallel text-graph datasets. Our code and data are available at https://github.com/Jiuzhouh/PiVe.
Robust Educational Dialogue Act Classifiers with Low-Resource and Imbalanced Datasets
Apr 15, 2023



Dialogue acts (DAs) can represent conversational actions of tutors or students that take place during tutoring dialogues. Automating the identification of DAs in tutoring dialogues is significant to the design of dialogue-based intelligent tutoring systems. Many prior studies employ machine learning models to classify DAs in tutoring dialogues and invest much effort to optimize the classification accuracy by using limited amounts of training data (i.e., low-resource data scenario). However, beyond the classification accuracy, the robustness of the classifier is also important, which can reflect the capability of the classifier on learning the patterns from different class distributions. We note that many prior studies on classifying educational DAs employ cross entropy (CE) loss to optimize DA classifiers on low-resource data with imbalanced DA distribution. The DA classifiers in these studies tend to prioritize accuracy on the majority class at the expense of the minority class which might not be robust to the data with imbalanced ratios of different DA classes. To optimize the robustness of classifiers on imbalanced class distributions, we propose to optimize the performance of the DA classifier by maximizing the area under the ROC curve (AUC) score (i.e., AUC maximization). Through extensive experiments, our study provides evidence that (i) by maximizing AUC in the training process, the DA classifier achieves significant performance improvement compared to the CE approach under low-resource data, and (ii) AUC maximization approaches can improve the robustness of the DA classifier under different class imbalance ratios.
Does Informativeness Matter? Active Learning for Educational Dialogue Act Classification
Apr 12, 2023



Dialogue Acts (DAs) can be used to explain what expert tutors do and what students know during the tutoring process. Most empirical studies adopt the random sampling method to obtain sentence samples for manual annotation of DAs, which are then used to train DA classifiers. However, these studies have paid little attention to sample informativeness, which can reflect the information quantity of the selected samples and inform the extent to which a classifier can learn patterns. Notably, the informativeness level may vary among the samples and the classifier might only need a small amount of low informative samples to learn the patterns. Random sampling may overlook sample informativeness, which consumes human labelling costs and contributes less to training the classifiers. As an alternative, researchers suggest employing statistical sampling methods of Active Learning (AL) to identify the informative samples for training the classifiers. However, the use of AL methods in educational DA classification tasks is under-explored. In this paper, we examine the informativeness of annotated sentence samples. Then, the study investigates how the AL methods can select informative samples to support DA classifiers in the AL sampling process. The results reveal that most annotated sentences present low informativeness in the training dataset and the patterns of these sentences can be easily captured by the DA classifier. We also demonstrate how AL methods can reduce the cost of manual annotation in the AL sampling process.
AUC Maximization for Low-Resource Named Entity Recognition
Dec 16, 2022



Current work in named entity recognition (NER) uses either cross entropy (CE) or conditional random fields (CRF) as the objective/loss functions to optimize the underlying NER model. Both of these traditional objective functions for the NER problem generally produce adequate performance when the data distribution is balanced and there are sufficient annotated training examples. But since NER is inherently an imbalanced tagging problem, the model performance under the low-resource settings could suffer using these standard objective functions. Based on recent advances in area under the ROC curve (AUC) maximization, we propose to optimize the NER model by maximizing the AUC score. We give evidence that by simply combining two binary-classifiers that maximize the AUC score, significant performance improvement over traditional loss functions is achieved under low-resource NER settings. We also conduct extensive experiments to demonstrate the advantages of our method under the low-resource and highly-imbalanced data distribution settings. To the best of our knowledge, this is the first work that brings AUC maximization to the NER setting. Furthermore, we show that our method is agnostic to different types of NER embeddings, models and domains. The code to replicate this work will be provided upon request.
Cross-Domain Graph Anomaly Detection via Anomaly-aware Contrastive Alignment
Dec 02, 2022Cross-domain graph anomaly detection (CD-GAD) describes the problem of detecting anomalous nodes in an unlabelled target graph using auxiliary, related source graphs with labelled anomalous and normal nodes. Although it presents a promising approach to address the notoriously high false positive issue in anomaly detection, little work has been done in this line of research. There are numerous domain adaptation methods in the literature, but it is difficult to adapt them for GAD due to the unknown distributions of the anomalies and the complex node relations embedded in graph data. To this end, we introduce a novel domain adaptation approach, namely Anomaly-aware Contrastive alignmenT (ACT), for GAD. ACT is designed to jointly optimise: (i) unsupervised contrastive learning of normal representations of nodes in the target graph, and (ii) anomaly-aware one-class alignment that aligns these contrastive node representations and the representations of labelled normal nodes in the source graph, while enforcing significant deviation of the representations of the normal nodes from the labelled anomalous nodes in the source graph. In doing so, ACT effectively transfers anomaly-informed knowledge from the source graph to learn the complex node relations of the normal class for GAD on the target graph without any specification of the anomaly distributions. Extensive experiments on eight CD-GAD settings demonstrate that our approach ACT achieves substantially improved detection performance over 10 state-of-the-art GAD methods. Code is available at https://github.com/QZ-WANG/ACT.
Hardness-guided domain adaptation to recognise biomedical named entities under low-resource scenarios
Nov 11, 2022



Domain adaptation is an effective solution to data scarcity in low-resource scenarios. However, when applied to token-level tasks such as bioNER, domain adaptation methods often suffer from the challenging linguistic characteristics that clinical narratives possess, which leads to unsatisfactory performance. In this paper, we present a simple yet effective hardness-guided domain adaptation (HGDA) framework for bioNER tasks that can effectively leverage the domain hardness information to improve the adaptability of the learnt model in low-resource scenarios. Experimental results on biomedical datasets show that our model can achieve significant performance improvement over the recently published state-of-the-art (SOTA) MetaNER model
Diversity Enhanced Active Learning with Strictly Proper Scoring Rules
Oct 27, 2021
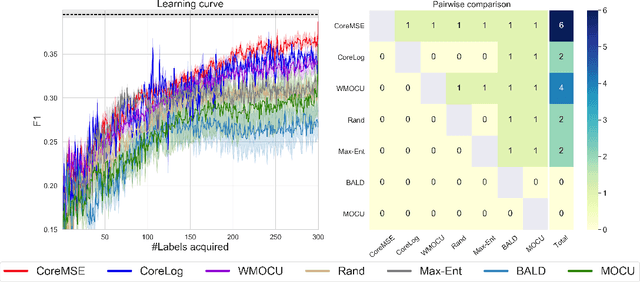

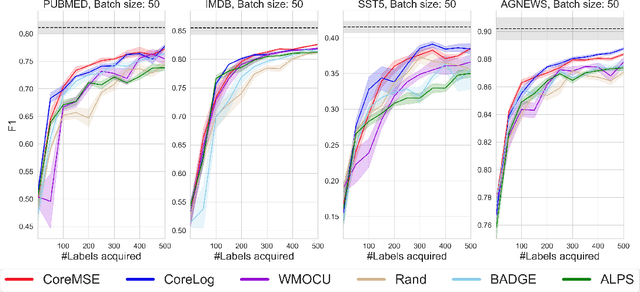
We study acquisition functions for active learning (AL) for text classification. The Expected Loss Reduction (ELR) method focuses on a Bayesian estimate of the reduction in classification error, recently updated with Mean Objective Cost of Uncertainty (MOCU). We convert the ELR framework to estimate the increase in (strictly proper) scores like log probability or negative mean square error, which we call Bayesian Estimate of Mean Proper Scores (BEMPS). We also prove convergence results borrowing techniques used with MOCU. In order to allow better experimentation with the new acquisition functions, we develop a complementary batch AL algorithm, which encourages diversity in the vector of expected changes in scores for unlabelled data. To allow high performance text classifiers, we combine ensembling and dynamic validation set construction on pretrained language models. Extensive experimental evaluation then explores how these different acquisition functions perform. The results show that the use of mean square error and log probability with BEMPS yields robust acquisition functions, which consistently outperform the others tested.