 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Transformer for High Dimensional Multivariate Time Series Forecasting
Aug 08, 2024



Deep models for Multivariate Time Series (MTS) forecasting have recently demonstrated significant success. Channel-dependent models capture complex dependencies that channel-independent models cannot capture. However, the number of channels in real-world applications outpaces the capabilities of existing channel-dependent models, and contrary to common expectations, some models underperform the channel-independent models in handling high-dimensional data, which raises questions about the performance of channel-dependent models. To address this, our study first investigates the reasons behind the suboptimal performance of these channel-dependent models on high-dimensional MTS data. Our analysis reveals that two primary issues lie in the introduced noise from unrelated series that increases the difficulty of capturing the crucial inter-channel dependencies, and challenges in training strategies due to high-dimensional data. To address these issues, we propose STHD, the Scalable Transformer for High-Dimensional Multivariate Time Series Forecasting. STHD has three components: a) Relation Matrix Sparsity that limits the noise introduced and alleviates the memory issue; b) ReIndex applied as a training strategy to enable a more flexible batch size setting and increase the diversity of training data; and c) Transformer that handles 2-D inputs and captures channel dependencies. These components jointly enable STHD to manage the high-dimensional MTS while maintaining computational feasibility. Furthermore, experimental results show STHD's considerable improvement on three high-dimensional datasets: Crime-Chicago, Wiki-People, and Traffic. The source code and dataset are publicly available https://github.com/xinzzzhou/ScalableTransformer4HighDimensionMTSF.git.
OntoMedRec: Logically-Pretrained Model-Agnostic Ontology Encoders for Medication Recommendation
Jan 29, 2024



Most existing medication recommendation models learn representations for medical concepts based on electronic health records (EHRs) and make recommendations with learnt representations. However, most medications appear in the dataset for limited times, resulting in insufficient learning of their representations. Medical ontologies are the hierarchical classification systems for medical terms where similar terms are in the same class on a certain level. In this paper, we propose OntoMedRec, the logically-pretrained and model-agnostic medical Ontology Encoders for Medication Recommendation that addresses data sparsity problem with medical ontologies. We conduct comprehensive experiments on benchmark datasets to evaluate the effectiveness of OntoMedRec, and the result shows the integration of OntoMedRec improves the performance of various models in both the entire EHR datasets and the admissions with few-shot medications. We provide the GitHub repository for the source code on https://anonymous.4open.science/r/OntoMedRec-D123
HiTSKT: A Hierarchical Transformer Model for Session-Aware Knowledge Tracing
Dec 23, 2022



Knowledge tracing (KT) aims to leverage students' learning histories to estimate their mastery levels on a set of pre-defined skills, based on which the corresponding future performance can be accurately predicted. In practice, a student's learning history comprises answers to sets of massed questions, each known as a session, rather than merely being a sequence of independent answers. Theoretically, within and across these sessions, students' learning dynamics can be very different. Therefore, how to effectively model the dynamics of students' knowledge states within and across the sessions is crucial for handling the KT problem. Most existing KT models treat student's learning records as a single continuing sequence, without capturing the sessional shift of students' knowledge state. To address the above issue, we propose a novel hierarchical transformer model, named HiTSKT, comprises an interaction(-level) encoder to capture the knowledge a student acquires within a session, and a session(-level) encoder to summarise acquired knowledge across the past sessions. To predict an interaction in the current session, a knowledge retriever integrates the summarised past-session knowledge with the previous interactions' information into proper knowledge representations. These representations are then used to compute the student's current knowledge state. Additionally, to model the student's long-term forgetting behaviour across the sessions, a power-law-decay attention mechanism is designed and deployed in the session encoder, allowing it to emphasize more on the recent sessions. Extensive experiments on three public datasets demonstrate that HiTSKT achieves new state-of-the-art performance on all the datasets compared with six state-of-the-art KT models.
Transformer over Pre-trained Transformer for Neural Text Segmentation with Enhanced Topic Coherence
Oct 14, 2021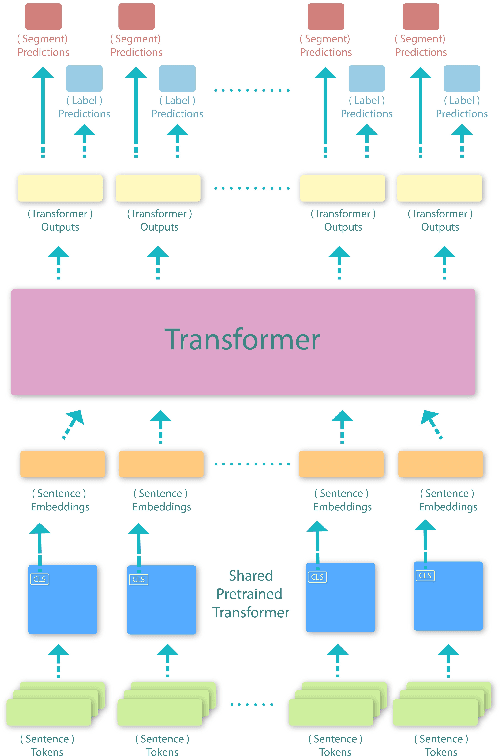


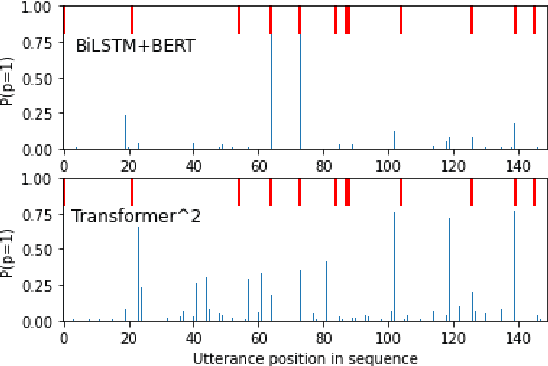
This paper proposes a transformer over transformer framework, called Transformer$^2$, to perform neural text segmentation. It consists of two components: bottom-level sentence encoders using pre-trained transformers, and an upper-level transformer-based segmentation model based on the sentence embeddings. The bottom-level component transfers the pre-trained knowledge learned from large external corpora under both single and pair-wise supervised NLP tasks to model the sentence embeddings for the documents. Given the sentence embeddings, the upper-level transformer is trained to recover the segmentation boundaries as well as the topic labels of each sentence. Equipped with a multi-task loss and the pre-trained knowledge, Transformer$^2$ can better capture the semantic coherence within the same segments. Our experiments show that (1) Transformer$^2$ manages to surpass state-of-the-art text segmentation models in terms of a commonly-used semantic coherence measure; (2) in most cases, both single and pair-wise pre-trained knowledge contribute to the model performance; (3) bottom-level sentence encoders pre-trained on specific languages yield better performance than those pre-trained on specific domains.