 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFixed Point Networks: Implicit Depth Models with Jacobian-Free Backprop
Mar 23, 2021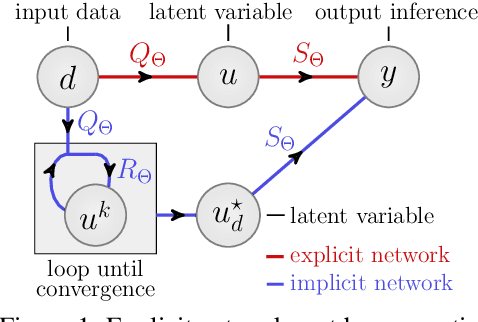
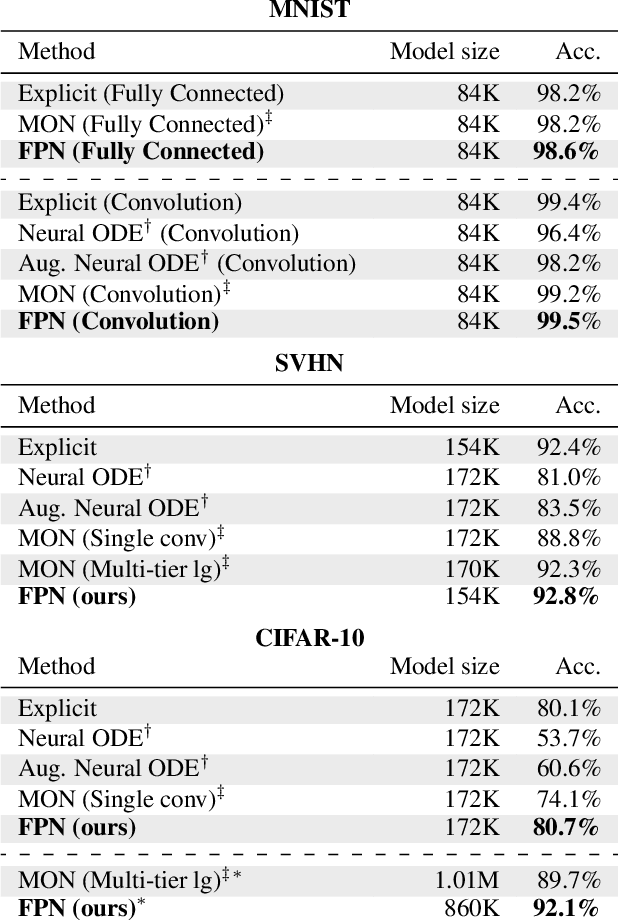
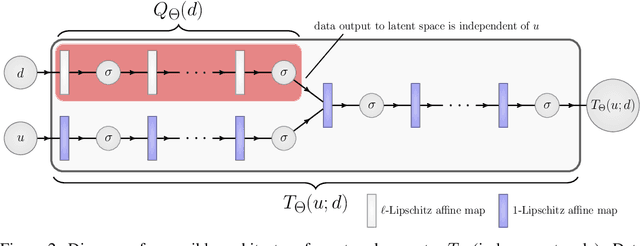
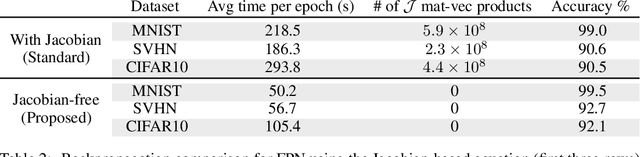
A growing trend in deep learning replaces fixed depth models by approximations of the limit as network depth approaches infinity. This approach uses a portion of network weights to prescribe behavior by defining a limit condition. This makes network depth implicit, varying based on the provided data and an error tolerance. Moreover, existing implicit models can be implemented and trained with fixed memory costs in exchange for additional computational costs. In particular, backpropagation through implicit depth models requires solving a Jacobian-based equation arising from the implicit function theorem. We propose fixed point networks (FPNs), a simple setup for implicit depth learning that guarantees convergence of forward propagation to a unique limit defined by network weights and input data. Our key contribution is to provide a new Jacobian-free backpropagation (JFB) scheme that circumvents the need to solve Jacobian-based equations while maintaining fixed memory costs. This makes FPNs much cheaper to train and easy to implement. Our numerical examples yield state of the art classification results for implicit depth models and outperform corresponding explicit models.
Provably Correct Optimization and Exploration with Non-linear Policies
Mar 22, 2021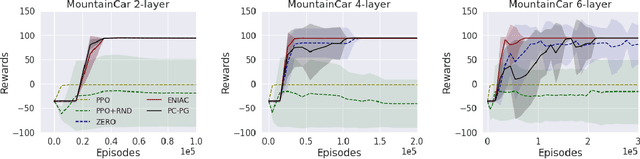
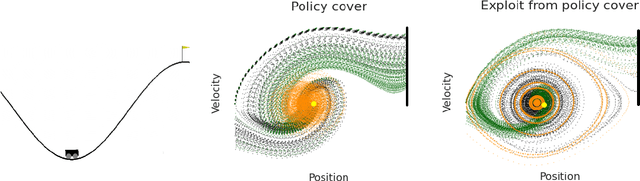
Policy optimization methods remain a powerful workhorse in empirical Reinforcement Learning (RL), with a focus on neural policies that can easily reason over complex and continuous state and/or action spaces. Theoretical understanding of strategic exploration in policy-based methods with non-linear function approximation, however, is largely missing. In this paper, we address this question by designing ENIAC, an actor-critic method that allows non-linear function approximation in the critic. We show that under certain assumptions, e.g., a bounded eluder dimension $d$ for the critic class, the learner finds a near-optimal policy in $O(\poly(d))$ exploration rounds. The method is robust to model misspecification and strictly extends existing works on linear function approximation. We also develop some computational optimizations of our approach with slightly worse statistical guarantees and an empirical adaptation building on existing deep RL tools. We empirically evaluate this adaptation and show that it outperforms prior heuristics inspired by linear methods, establishing the value via correctly reasoning about the agent's uncertainty under non-linear function approximation.
A Single-Timescale Stochastic Bilevel Optimization Method
Feb 22, 2021
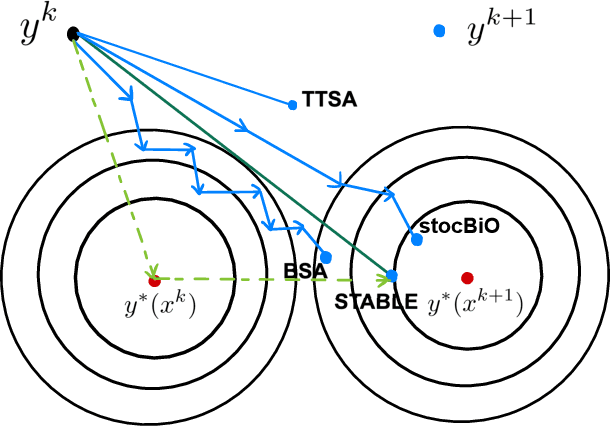
Stochastic bilevel optimization generalizes the classic stochastic optimization from the minimization of a single objective to the minimization of an objective function that depends the solution of another optimization problem. Recently, stochastic bilevel optimization is regaining popularity in emerging machine learning applications such as hyper-parameter optimization and model-agnostic meta learning. To solve this class of stochastic optimization problems, existing methods require either double-loop or two-timescale updates, which are sometimes less efficient. This paper develops a new optimization method for a class of stochastic bilevel problems that we term Single-Timescale stochAstic BiLevEl optimization (STABLE) method. STABLE runs in a single loop fashion, and uses a single-timescale update with a fixed batch size. To achieve an $\epsilon$-stationary point of the bilevel problem, STABLE requires ${\cal O}(\epsilon^{-2})$ samples in total; and to achieve an $\epsilon$-optimal solution in the strongly convex case, STABLE requires ${\cal O}(\epsilon^{-1})$ samples. To the best of our knowledge, this is the first bilevel optimization algorithm achieving the same order of sample complexity as the stochastic gradient descent method for the single-level stochastic optimization.
A Zeroth-Order Block Coordinate Descent Algorithm for Huge-Scale Black-Box Optimization
Feb 21, 2021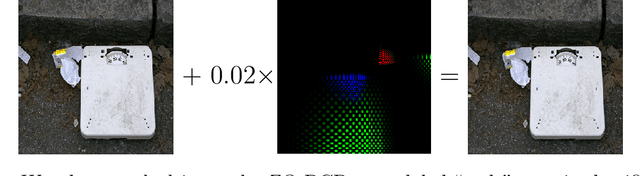
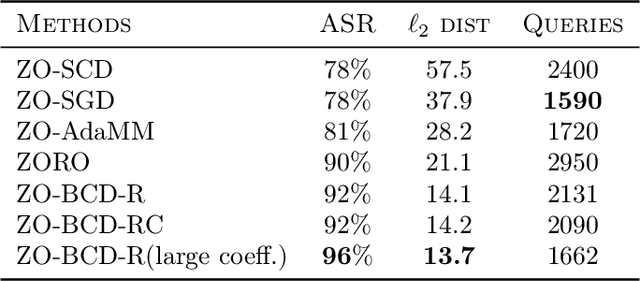
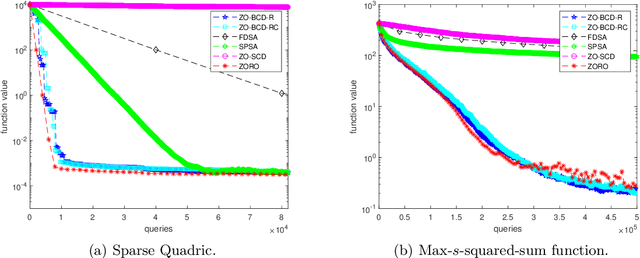
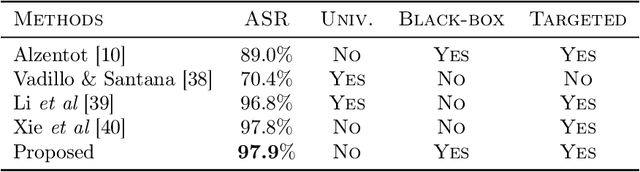
We consider the zeroth-order optimization problem in the huge-scale setting, where the dimension of the problem is so large that performing even basic vector operations on the decision variables is infeasible. In this paper, we propose a novel algorithm, coined ZO-BCD, that exhibits favorable overall query complexity and has a much smaller per-iteration computational complexity. In addition, we discuss how the memory footprint of ZO-BCD can be reduced even further by the clever use of circulant measurement matrices. As an application of our new method, we propose the idea of crafting adversarial attacks on neural network based classifiers in a wavelet domain, which can result in problem dimensions of over 1.7 million. In particular, we show that crafting adversarial examples to audio classifiers in a wavelet domain can achieve the state-of-the-art attack success rate of 97.9%.
CADA: Communication-Adaptive Distributed Adam
Dec 31, 2020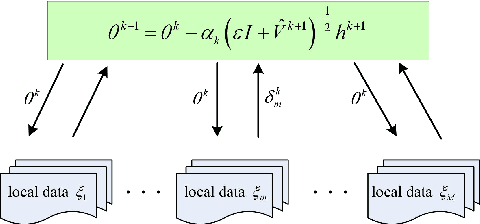

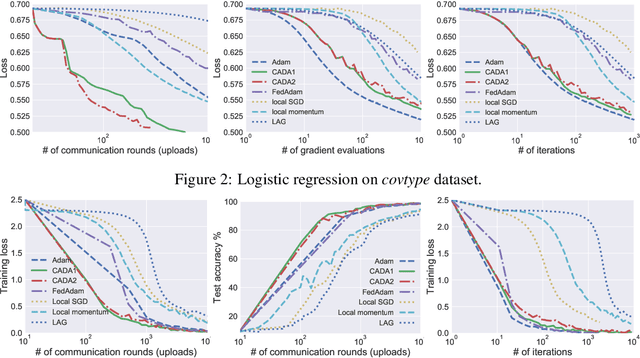
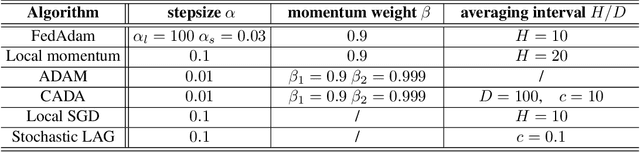
Stochastic gradient descent (SGD) has taken the stage as the primary workhorse for large-scale machine learning. It is often used with its adaptive variants such as AdaGrad, Adam, and AMSGrad. This paper proposes an adaptive stochastic gradient descent method for distributed machine learning, which can be viewed as the communication-adaptive counterpart of the celebrated Adam method - justifying its name CADA. The key components of CADA are a set of new rules tailored for adaptive stochastic gradients that can be implemented to save communication upload. The new algorithms adaptively reuse the stale Adam gradients, thus saving communication, and still have convergence rates comparable to original Adam. In numerical experiments, CADA achieves impressive empirical performance in terms of total communication round reduction.
Hybrid Federated Learning: Algorithms and Implementation
Dec 29, 2020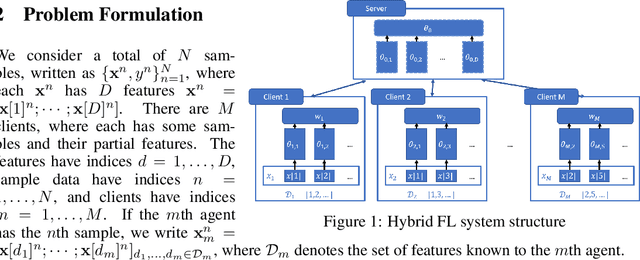

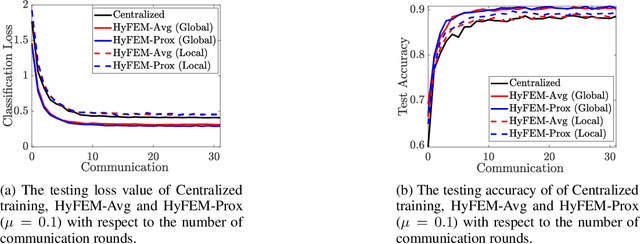
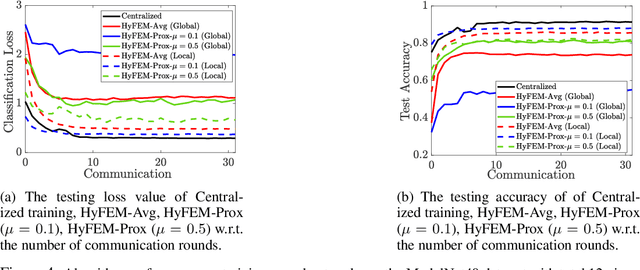
Federated learning (FL) is a recently proposed distributed machine learning paradigm dealing with distributed and private data sets. Based on the data partition pattern, FL is often categorized into horizontal, vertical, and hybrid settings. Despite the fact that many works have been developed for the first two approaches, the hybrid FL setting (which deals with partially overlapped feature space and sample space) remains less explored, though this setting is extremely important in practice. In this paper, we first set up a new model-matching-based problem formulation for hybrid FL, then propose an efficient algorithm that can collaboratively train the global and local models to deal with full and partial featured data. We conduct numerical experiments on the multi-view ModelNet40 data set to validate the performance of the proposed algorithm. To the best of our knowledge, this is the first formulation and algorithm developed for the hybrid FL.
Attentional Biased Stochastic Gradient for Imbalanced Classification
Dec 13, 2020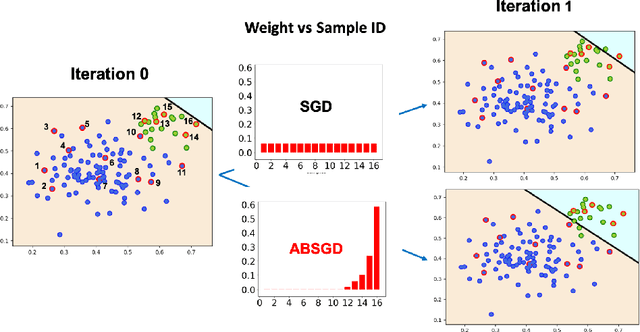
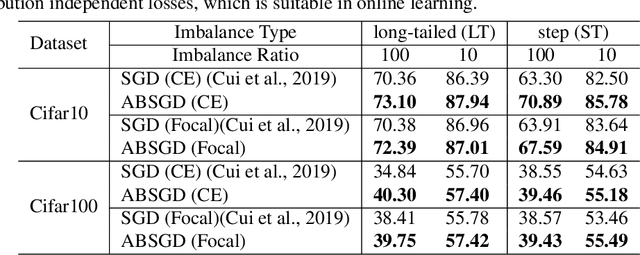

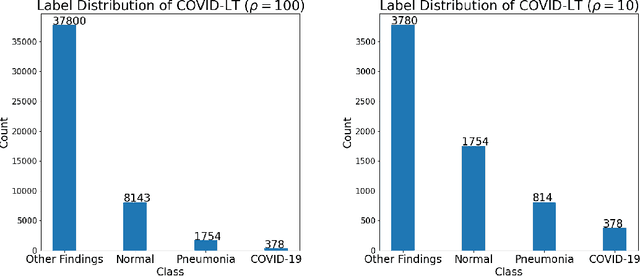
In this paper~\footnote{The original title is "Momentum SGD with Robust Weighting For Imbalanced Classification"}, we present a simple yet effective method (ABSGD) for addressing the data imbalance issue in deep learning. Our method is a simple modification to momentum SGD where we leverage an attentional mechanism to assign an individual importance weight to each gradient in the mini-batch. Unlike existing individual weighting methods that learn the individual weights by meta-learning on a separate balanced validation data, our weighting scheme is self-adaptive and is grounded in distributionally robust optimization. The weight of a sampled data is systematically proportional to exponential of a scaled loss value of the data, where the scaling factor is interpreted as the regularization parameter in the framework of information-regularized distributionally robust optimization. We employ a step damping strategy for the scaling factor to balance between the learning of feature extraction layers and the learning of the classifier layer. Compared with exiting meta-learning methods that require three backward propagations for computing mini-batch stochastic gradients at three different points at each iteration, our method is more efficient with only one backward propagation at each iteration as in standard deep learning methods. Compared with existing class-level weighting schemes, our method can be applied to online learning without any knowledge of class prior, while enjoying further performance boost in offline learning combined with existing class-level weighting schemes. Our empirical studies on several benchmark datasets also demonstrate the effectiveness of our proposed method
SCOBO: Sparsity-Aware Comparison Oracle Based Optimization
Oct 06, 2020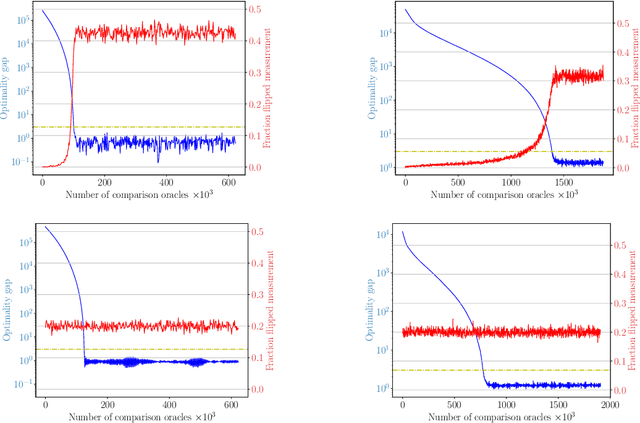
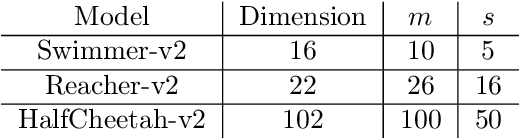
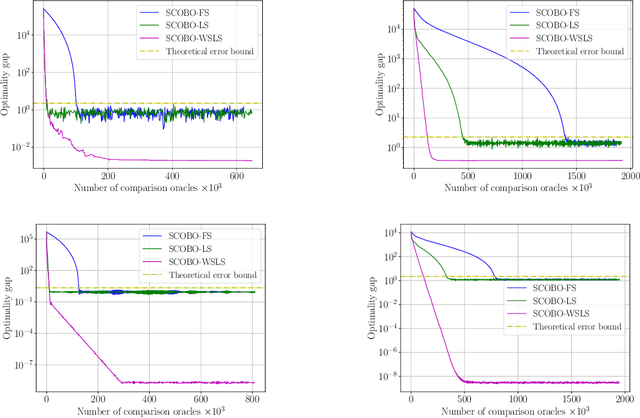
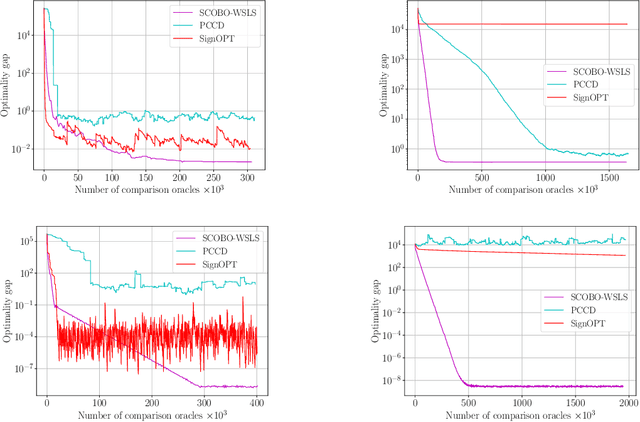
We study derivative-free optimization for convex functions where we further assume that function evaluations are unavailable. Instead, one only has access to a comparison oracle, which, given two points $x$ and $y$, and returns a single bit of information indicating which point has larger function value, $f(x)$ or $f(y)$, with some probability of being incorrect. This probability may be constant or it may depend on $|f(x)-f(y)|$. Previous algorithms for this problem have been hampered by a query complexity which is polynomially dependent on the problem dimension, $d$. We propose a novel algorithm that breaks this dependence: it has query complexity only logarithmically dependent on $d$ if the function in addition has low dimensional structure that can be exploited. Numerical experiments on synthetic data and the MuJoCo dataset show that our algorithm outperforms state-of-the-art methods for comparison based optimization, and is even competitive with other derivative-free algorithms that require explicit function evaluations.
Solving Stochastic Compositional Optimization is Nearly as Easy as Solving Stochastic Optimization
Aug 31, 2020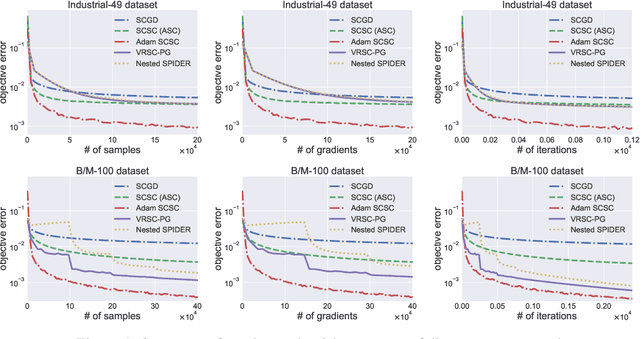
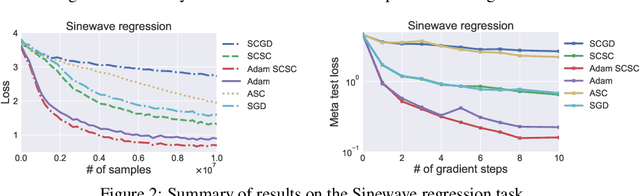
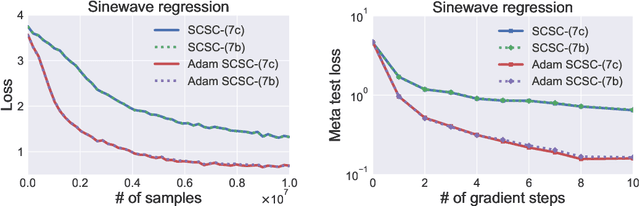
Stochastic compositional optimization generalizes classic (non-compositional) stochastic optimization to the minimization of compositions of functions. Each composition may introduce an additional expectation. The series of expectations may be nested. Stochastic compositional optimization is gaining popularity in applications such as reinforcement learning and meta learning. This paper presents a new Stochastically Corrected Stochastic Compositional gradient method (SCSC). SCSC runs in a single-time scale with a single loop, uses a fixed batch size, and guarantees to converge at the same rate as the stochastic gradient descent (SGD) method for non-compositional stochastic optimization. This is achieved by making a careful improvement to a popular stochastic compositional gradient method. It is easy to apply SGD-improvement techniques to accelerate SCSC. This helps SCSC achieve state-of-the-art performance for stochastic compositional optimization. In particular, we apply Adam to SCSC, and the exhibited rate of convergence matches that of the original Adam on non-compositional stochastic optimization. We test SCSC using the portfolio management and model-agnostic meta-learning tasks.
Projecting to Manifolds via Unsupervised Learning
Aug 05, 2020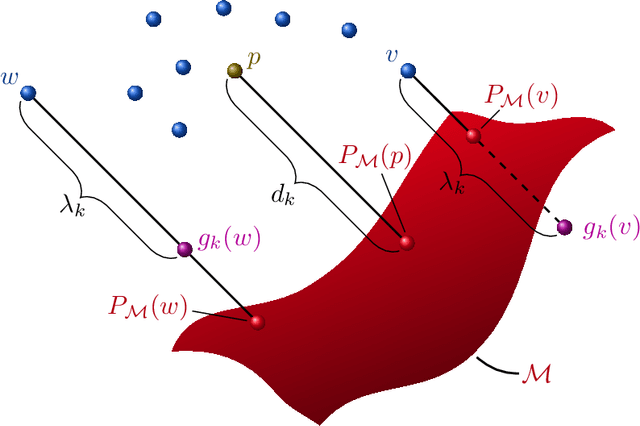
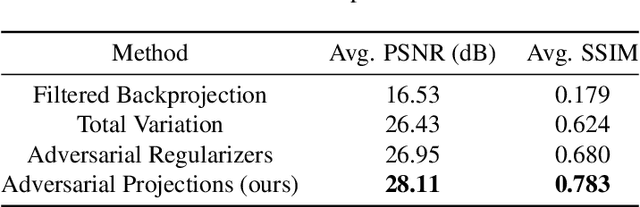
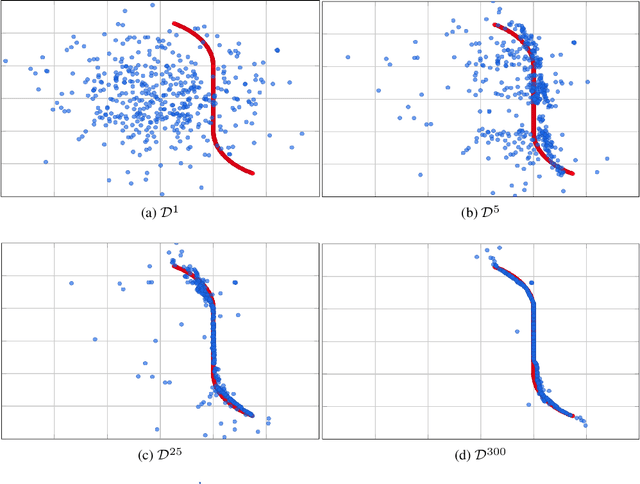

We present a new framework, called adversarial projections, for solving inverse problems by learning to project onto manifolds. Our goal is to recover a signal from a collection of noisy measurements. Traditional methods for this task often minimize the addition of a regularization term and an expression that measures compliance with measurements (e.g., least squares). However, it has been shown that convex regularization can introduce bias, preventing recovery of the true signal. Our approach avoids this issue by iteratively projecting signals toward the (possibly nonlinear) manifold of true signals. This is accomplished by first solving a sequence of unsupervised learning problems. The solution to each learning problem provides a collection of parameters that enables access to an iteration-dependent step size and access to the direction to project each signal toward the closest true signal. Given a signal estimate (e.g., recovered from a pseudo-inverse), we prove our method generates a sequence that converges in mean square to the projection onto this manifold. Several numerical illustrations are provided.