 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoML for Climate Change: A Call to Action
Oct 07, 2022

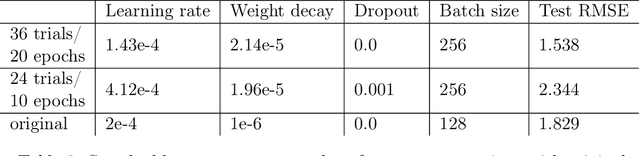

The challenge that climate change poses to humanity has spurred a rapidly developing field of artificial intelligence research focused on climate change applications. The climate change AI (CCAI) community works on a diverse, challenging set of problems which often involve physics-constrained ML or heterogeneous spatiotemporal data. It would be desirable to use automated machine learning (AutoML) techniques to automatically find high-performing architectures and hyperparameters for a given dataset. In this work, we benchmark popular AutoML libraries on three high-leverage CCAI applications: climate modeling, wind power forecasting, and catalyst discovery. We find that out-of-the-box AutoML libraries currently fail to meaningfully surpass the performance of human-designed CCAI models. However, we also identify a few key weaknesses, which stem from the fact that most AutoML techniques are tailored to computer vision and NLP applications. For example, while dozens of search spaces have been designed for image and language data, none have been designed for spatiotemporal data. Addressing these key weaknesses can lead to the discovery of novel architectures that yield substantial performance gains across numerous CCAI applications. Therefore, we present a call to action to the AutoML community, since there are a number of concrete, promising directions for future work in the space of AutoML for CCAI. We release our code and a list of resources at https://github.com/climate-change-automl/climate-change-automl.
Exploration via Planning for Information about the Optimal Trajectory
Oct 06, 2022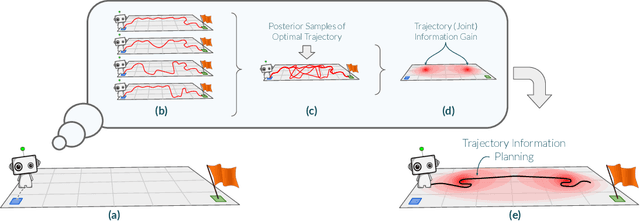

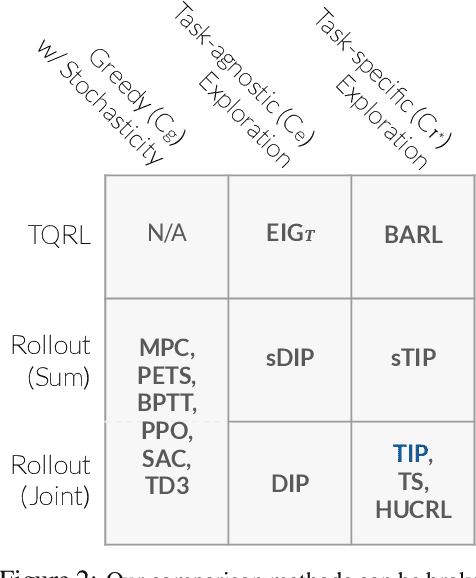
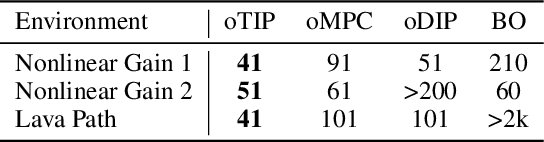
Many potential applications of reinforcement learning (RL) are stymied by the large numbers of samples required to learn an effective policy. This is especially true when applying RL to real-world control tasks, e.g. in the sciences or robotics, where executing a policy in the environment is costly. In popular RL algorithms, agents typically explore either by adding stochasticity to a reward-maximizing policy or by attempting to gather maximal information about environment dynamics without taking the given task into account. In this work, we develop a method that allows us to plan for exploration while taking both the task and the current knowledge about the dynamics into account. The key insight to our approach is to plan an action sequence that maximizes the expected information gain about the optimal trajectory for the task at hand. We demonstrate that our method learns strong policies with 2x fewer samples than strong exploration baselines and 200x fewer samples than model free methods on a diverse set of low-to-medium dimensional control tasks in both the open-loop and closed-loop control settings.
Generalizing Bayesian Optimization with Decision-theoretic Entropies
Oct 04, 2022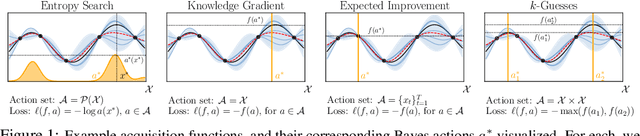
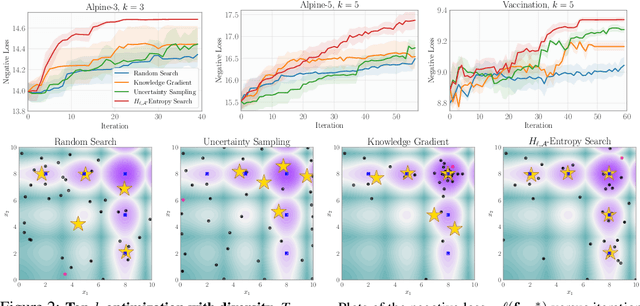
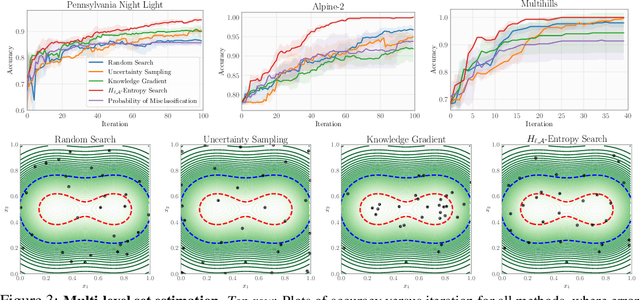
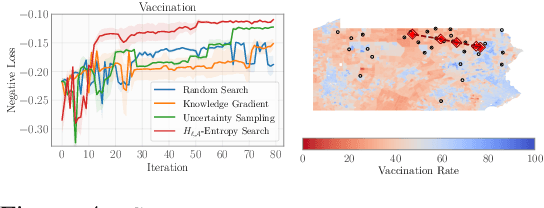
Bayesian optimization (BO) is a popular method for efficiently inferring optima of an expensive black-box function via a sequence of queries. Existing information-theoretic BO procedures aim to make queries that most reduce the uncertainty about optima, where the uncertainty is captured by Shannon entropy. However, an optimal measure of uncertainty would, ideally, factor in how we intend to use the inferred quantity in some downstream procedure. In this paper, we instead consider a generalization of Shannon entropy from work in statistical decision theory (DeGroot 1962, Rao 1984), which contains a broad class of uncertainty measures parameterized by a problem-specific loss function corresponding to a downstream task. We first show that special cases of this entropy lead to popular acquisition functions used in BO procedures such as knowledge gradient, expected improvement, and entropy search. We then show how alternative choices for the loss yield a flexible family of acquisition functions that can be customized for use in novel optimization settings. Additionally, we develop gradient-based methods to efficiently optimize our proposed family of acquisition functions, and demonstrate strong empirical performance on a diverse set of sequential decision making tasks, including variants of top-$k$ optimization, multi-level set estimation, and sequence search.
Bayesian Algorithm Execution for Tuning Particle Accelerator Emittance with Partial Measurements
Sep 10, 2022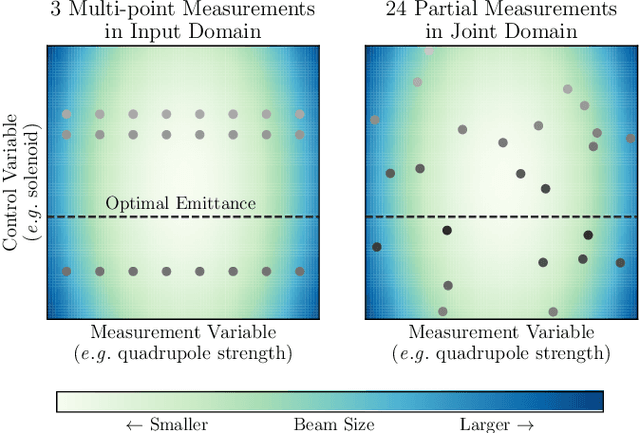
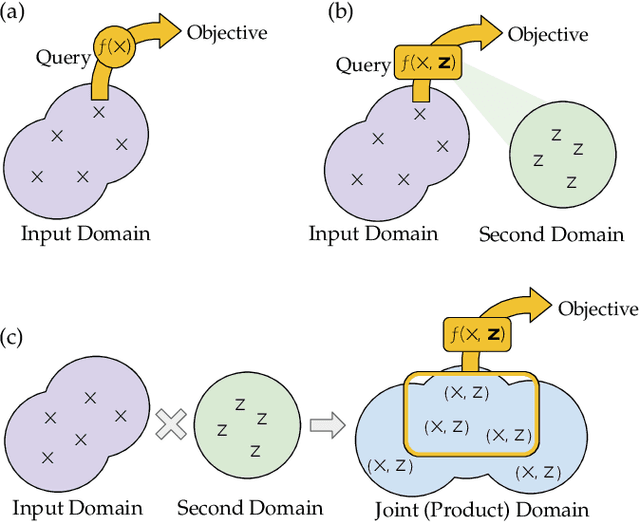
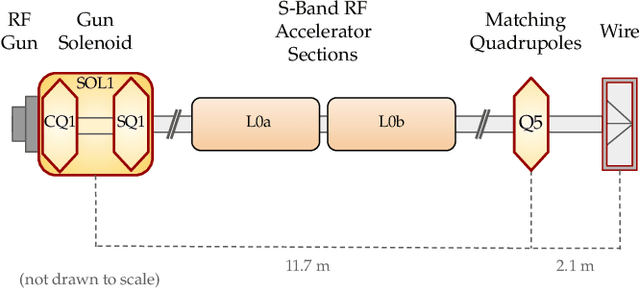
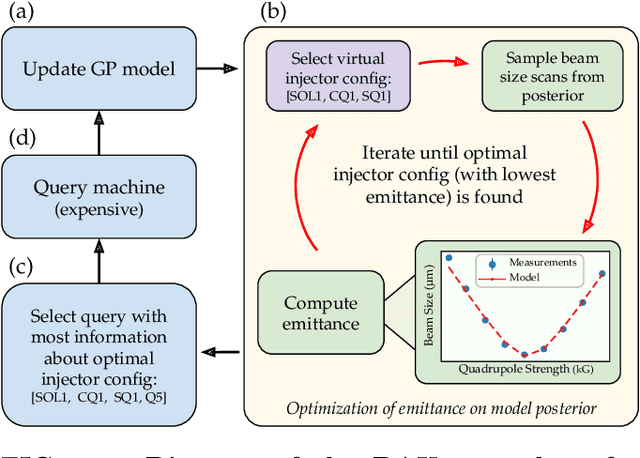
Traditional black-box optimization methods are inefficient when dealing with multi-point measurement, i.e. when each query in the control domain requires a set of measurements in a secondary domain to calculate the objective. In particle accelerators, emittance tuning from quadrupole scans is an example of optimization with multi-point measurements. Although the emittance is a critical parameter for the performance of high-brightness machines, including X-ray lasers and linear colliders, comprehensive optimization is often limited by the time required for tuning. Here, we extend the recently-proposed Bayesian Algorithm Execution (BAX) to the task of optimization with multi-point measurements. BAX achieves sample-efficiency by selecting and modeling individual points in the joint control-measurement domain. We apply BAX to emittance minimization at the Linac Coherent Light Source (LCLS) and the Facility for Advanced Accelerator Experimental Tests II (FACET-II) particle accelerators. In an LCLS simulation environment, we show that BAX delivers a 20x increase in efficiency while also being more robust to noise compared to traditional optimization methods. Additionally, we ran BAX live at both LCLS and FACET-II, matching the hand-tuned emittance at FACET-II and achieving an optimal emittance that was 24% lower than that obtained by hand-tuning at LCLS. We anticipate that our approach can readily be adapted to other types of optimization problems involving multi-point measurements commonly found in scientific instruments.
Modular Conformal Calibration
Jul 05, 2022

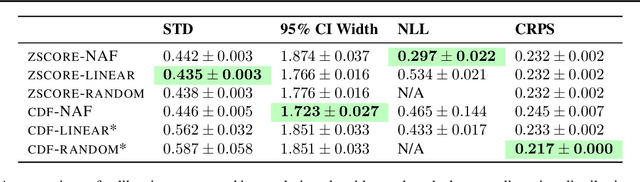

Uncertainty estimates must be calibrated (i.e., accurate) and sharp (i.e., informative) in order to be useful. This has motivated a variety of methods for recalibration, which use held-out data to turn an uncalibrated model into a calibrated model. However, the applicability of existing methods is limited due to their assumption that the original model is also a probabilistic model. We introduce a versatile class of algorithms for recalibration in regression that we call Modular Conformal Calibration (MCC). This framework allows one to transform any regression model into a calibrated probabilistic model. The modular design of MCC allows us to make simple adjustments to existing algorithms that enable well-behaved distribution predictions. We also provide finite-sample calibration guarantees for MCC algorithms. Our framework recovers isotonic recalibration, conformal calibration, and conformal interval prediction, implying that our theoretical results apply to those methods as well. Finally, we conduct an empirical study of MCC on 17 regression datasets. Our results show that new algorithms designed in our framework achieve near-perfect calibration and improve sharpness relative to existing methods.
Betty: An Automatic Differentiation Library for Multilevel Optimization
Jul 05, 2022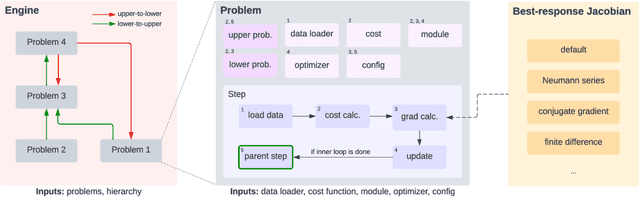
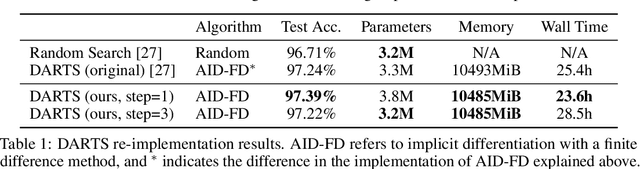
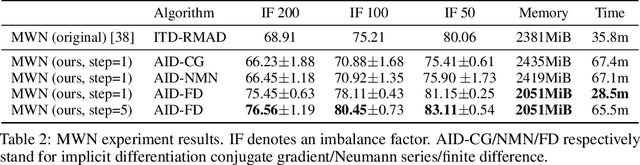

Multilevel optimization has been widely adopted as a mathematical foundation for a myriad of machine learning problems, such as hyperparameter optimization, meta-learning, and reinforcement learning, to name a few. Nonetheless, implementing multilevel optimization programs oftentimes requires expertise in both mathematics and programming, stunting research in this field. We take an initial step towards closing this gap by introducing Betty, a high-level software library for gradient-based multilevel optimization. To this end, we develop an automatic differentiation procedure based on a novel interpretation of multilevel optimization as a dataflow graph. We further abstract the main components of multilevel optimization as Python classes, to enable easy, modular, and maintainable programming. We empirically demonstrate that Betty can be used as a high-level programming interface for an array of multilevel optimization programs, while also observing up to 11\% increase in test accuracy, 14\% decrease in GPU memory usage, and 20\% decrease in wall time over existing implementations on multiple benchmarks. The code is available at http://github.com/leopard-ai/betty .
A General Recipe for Likelihood-free Bayesian Optimization
Jun 27, 2022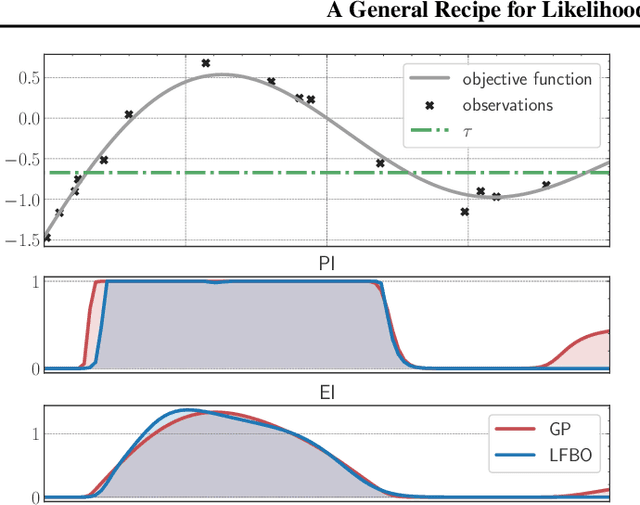

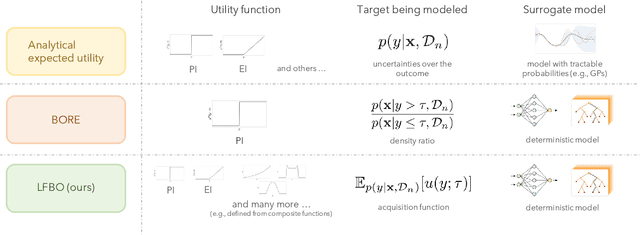
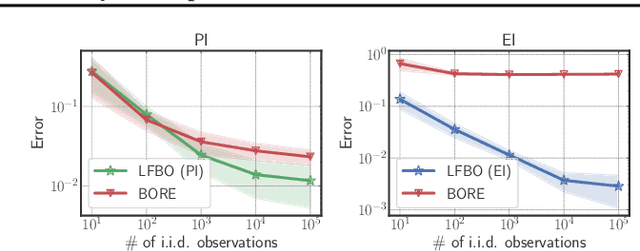
The acquisition function, a critical component in Bayesian optimization (BO), can often be written as the expectation of a utility function under a surrogate model. However, to ensure that acquisition functions are tractable to optimize, restrictions must be placed on the surrogate model and utility function. To extend BO to a broader class of models and utilities, we propose likelihood-free BO (LFBO), an approach based on likelihood-free inference. LFBO directly models the acquisition function without having to separately perform inference with a probabilistic surrogate model. We show that computing the acquisition function in LFBO can be reduced to optimizing a weighted classification problem, where the weights correspond to the utility being chosen. By choosing the utility function for expected improvement (EI), LFBO outperforms various state-of-the-art black-box optimization methods on several real-world optimization problems. LFBO can also effectively leverage composite structures of the objective function, which further improves its regret by several orders of magnitude.
Generative Modeling Helps Weak Supervision (and Vice Versa)
Mar 22, 2022
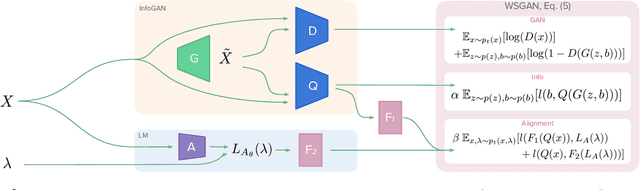
Many promising applications of supervised machine learning face hurdles in the acquisition of labeled data in sufficient quantity and quality, creating an expensive bottleneck. To overcome such limitations, techniques that do not depend on ground truth labels have been developed, including weak supervision and generative modeling. While these techniques would seem to be usable in concert, improving one another, how to build an interface between them is not well-understood. In this work, we propose a model fusing weak supervision and generative adversarial networks. It captures discrete variables in the data alongside the weak supervision derived label estimate. Their alignment allows for better modeling of sample-dependent accuracies of the weak supervision sources, improving the unobserved ground truth estimate. It is the first approach to enable data augmentation through weakly supervised synthetic images and pseudolabels. Additionally, its learned discrete variables can be inspected qualitatively. The model outperforms baseline weak supervision label models on a number of multiclass classification datasets, improves the quality of generated images, and further improves end-model performance through data augmentation with synthetic samples.
IS-COUNT: Large-scale Object Counting from Satellite Images with Covariate-based Importance Sampling
Dec 16, 2021
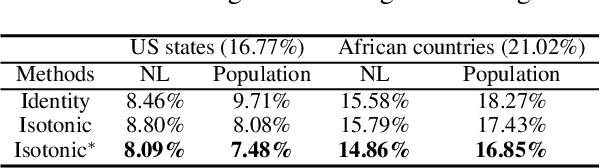
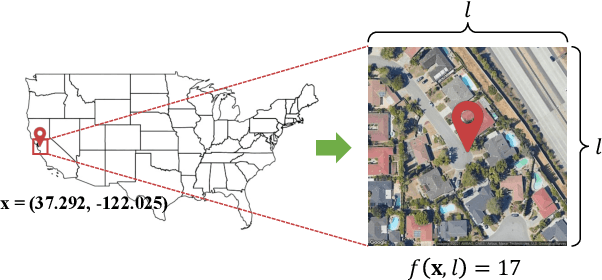
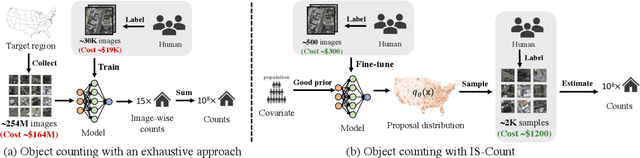
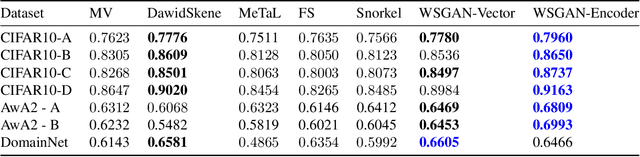
Object detection in high-resolution satellite imagery is emerging as a scalable alternative to on-the-ground survey data collection in many environmental and socioeconomic monitoring applications. However, performing object detection over large geographies can still be prohibitively expensive due to the high cost of purchasing imagery and compute. Inspired by traditional survey data collection strategies, we propose an approach to estimate object count statistics over large geographies through sampling. Given a cost budget, our method selects a small number of representative areas by sampling from a learnable proposal distribution. Using importance sampling, we are able to accurately estimate object counts after processing only a small fraction of the images compared to an exhaustive approach. We show empirically that the proposed framework achieves strong performance on estimating the number of buildings in the United States and Africa, cars in Kenya, brick kilns in Bangladesh, and swimming pools in the U.S., while requiring as few as 0.01% of satellite images compared to an exhaustive approach.
An Experimental Design Perspective on Model-Based Reinforcement Learning
Dec 09, 2021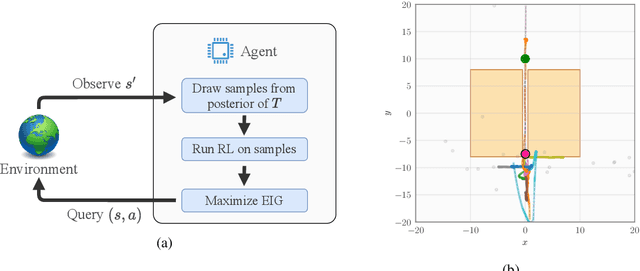
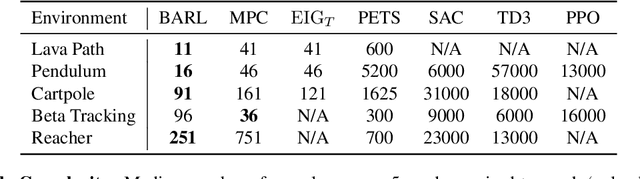
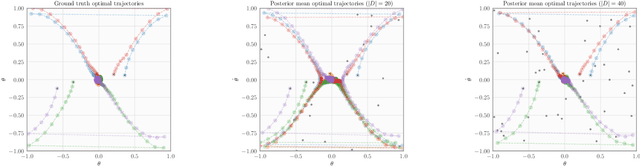

In many practical applications of RL, it is expensive to observe state transitions from the environment. For example, in the problem of plasma control for nuclear fusion, computing the next state for a given state-action pair requires querying an expensive transition function which can lead to many hours of computer simulation or dollars of scientific research. Such expensive data collection prohibits application of standard RL algorithms which usually require a large number of observations to learn. In this work, we address the problem of efficiently learning a policy while making a minimal number of state-action queries to the transition function. In particular, we leverage ideas from Bayesian optimal experimental design to guide the selection of state-action queries for efficient learning. We propose an acquisition function that quantifies how much information a state-action pair would provide about the optimal solution to a Markov decision process. At each iteration, our algorithm maximizes this acquisition function, to choose the most informative state-action pair to be queried, thus yielding a data-efficient RL approach. We experiment with a variety of simulated continuous control problems and show that our approach learns an optimal policy with up to $5$ -- $1,000\times$ less data than model-based RL baselines and $10^3$ -- $10^5\times$ less data than model-free RL baselines. We also provide several ablated comparisons which point to substantial improvements arising from the principled method of obtaining data.