 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
Flee the Flaw: Annotating the Underlying Logic of Fallacious Arguments Through Templates and Slot-filling
Jun 18, 2024



Prior research in computational argumentation has mainly focused on scoring the quality of arguments, with less attention on explicating logical errors. In this work, we introduce four sets of explainable templates for common informal logical fallacies designed to explicate a fallacy's implicit logic. Using our templates, we conduct an annotation study on top of 400 fallacious arguments taken from LOGIC dataset and achieve a high agreement score (Krippendorf's alpha of 0.54) and reasonable coverage (0.83). Finally, we conduct an experiment for detecting the structure of fallacies and discover that state-of-the-art language models struggle with detecting fallacy templates (0.47 accuracy). To facilitate research on fallacies, we make our dataset and guidelines publicly available.
Teach Me How to Improve My Argumentation Skills: A Survey on Feedback in Argumentation
Jul 28, 2023



The use of argumentation in education has been shown to improve critical thinking skills for end-users such as students, and computational models for argumentation have been developed to assist in this process. Although these models are useful for evaluating the quality of an argument, they oftentimes cannot explain why a particular argument is considered poor or not, which makes it difficult to provide constructive feedback to users to strengthen their critical thinking skills. In this survey, we aim to explore the different dimensions of feedback (Richness, Visualization, Interactivity, and Personalization) provided by the current computational models for argumentation, and the possibility of enhancing the power of explanations of such models, ultimately helping learners improve their critical thinking skills.
Comparison of machine learning methods for classifying mediastinal lymph node metastasis of non-small cell lung cancer from 18F-FDG PET/CT images
Feb 07, 2017
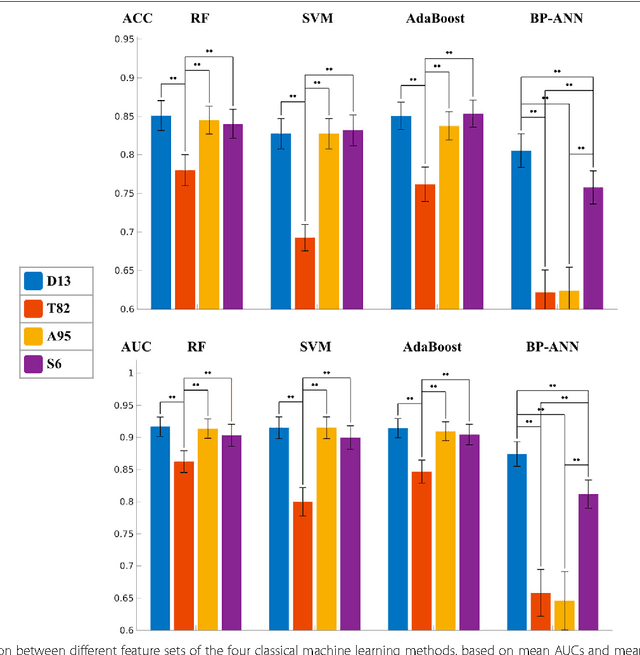
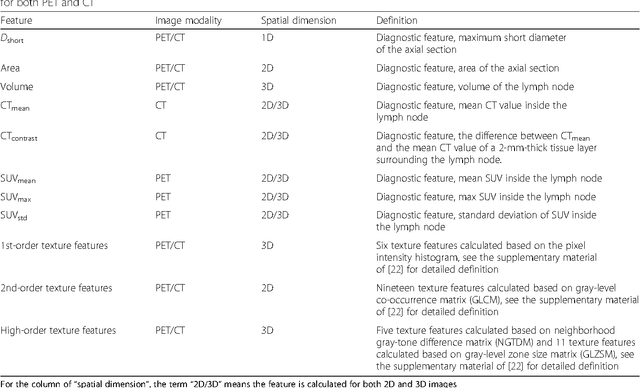
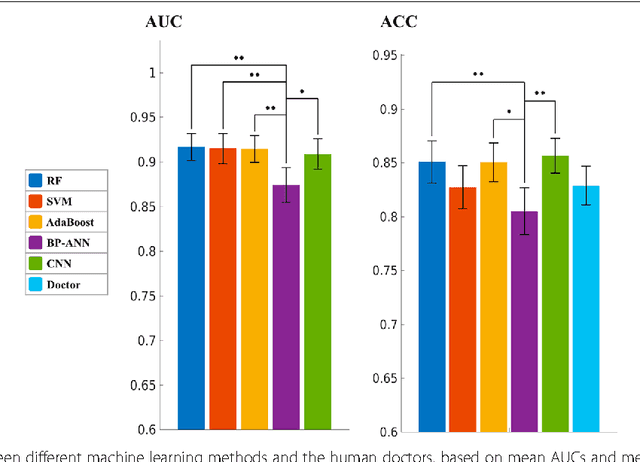
The present study shows that the performance of CNN is not significantly different from the best classical methods and human doctors for classifying mediastinal lymph node metastasis of NSCLC from PET/CT images. Because CNN does not need tumor segmentation or feature calculation, it is more convenient and more objective than the classical methods. However, CNN does not make use of the import diagnostic features, which have been proved more discriminative than the texture features for classifying small-sized lymph nodes. Therefore, incorporating the diagnostic features into CNN is a promising direction for future research.