 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlayVirtual: Augmenting Cycle-Consistent Virtual Trajectories for Reinforcement Learning
Jun 08, 2021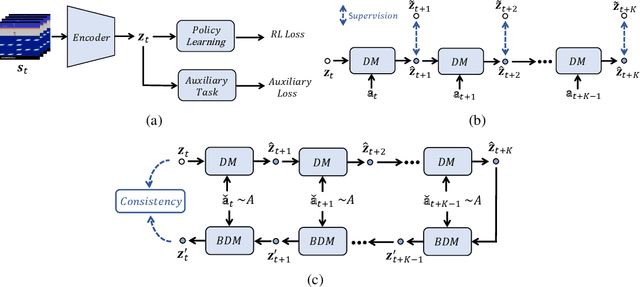
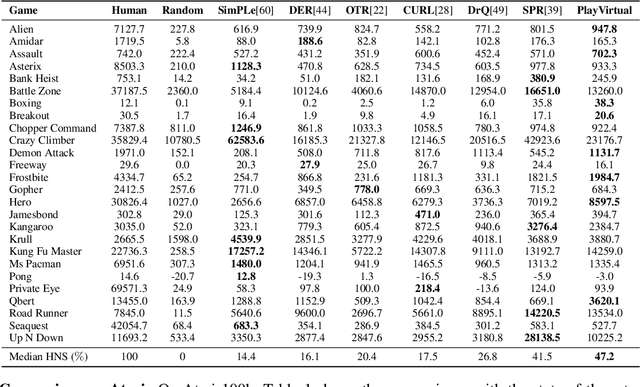
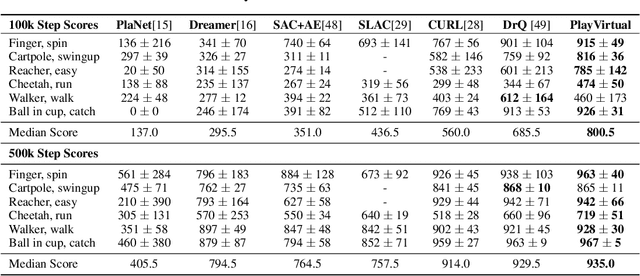
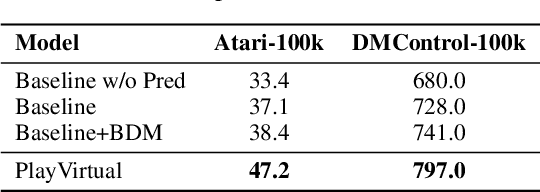
Learning good feature representations is important for deep reinforcement learning (RL). However, with limited experience, RL often suffers from data inefficiency for training. For un-experienced or less-experienced trajectories (i.e., state-action sequences), the lack of data limits the use of them for better feature learning. In this work, we propose a novel method, dubbed PlayVirtual, which augments cycle-consistent virtual trajectories to enhance the data efficiency for RL feature representation learning. Specifically, PlayVirtual predicts future states based on the current state and action by a dynamics model and then predicts the previous states by a backward dynamics model, which forms a trajectory cycle. Based on this, we augment the actions to generate a large amount of virtual state-action trajectories. Being free of groudtruth state supervision, we enforce a trajectory to meet the cycle consistency constraint, which can significantly enhance the data efficiency. We validate the effectiveness of our designs on the Atari and DeepMind Control Suite benchmarks. Our method outperforms the current state-of-the-art methods by a large margin on both benchmarks.
Understanding Mobile GUI: from Pixel-Words to Screen-Sentences
May 25, 2021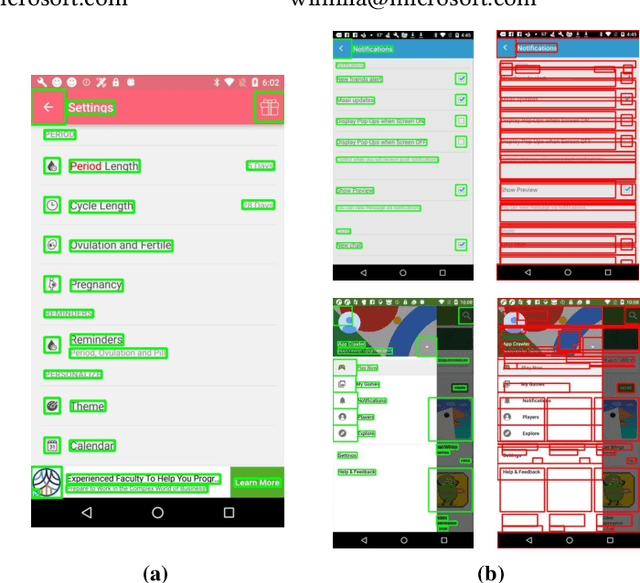
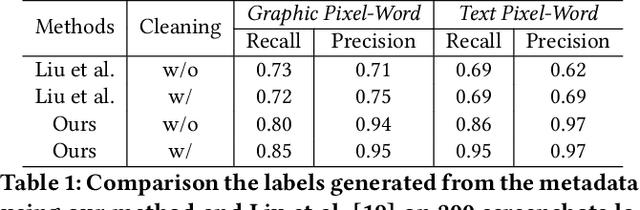
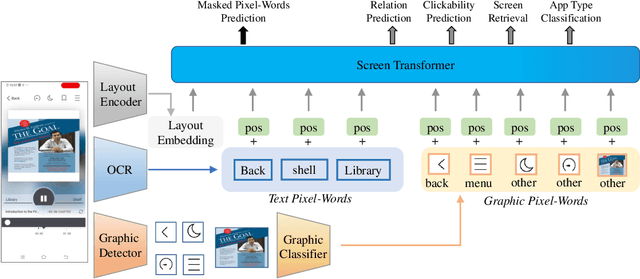
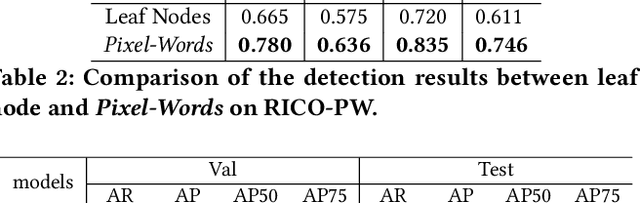
The ubiquity of mobile phones makes mobile GUI understanding an important task. Most previous works in this domain require human-created metadata of screens (e.g. View Hierarchy) during inference, which unfortunately is often not available or reliable enough for GUI understanding. Inspired by the impressive success of Transformers in NLP tasks, targeting for purely vision-based GUI understanding, we extend the concepts of Words/Sentence to Pixel-Words/Screen-Sentence, and propose a mobile GUI understanding architecture: Pixel-Words to Screen-Sentence (PW2SS). In analogy to the individual Words, we define the Pixel-Words as atomic visual components (text and graphic components), which are visually consistent and semantically clear across screenshots of a large variety of design styles. The Pixel-Words extracted from a screenshot are aggregated into Screen-Sentence with a Screen Transformer proposed to model their relations. Since the Pixel-Words are defined as atomic visual components, the ambiguity between their visual appearance and semantics is dramatically reduced. We are able to make use of metadata available in training data to auto-generate high-quality annotations for Pixel-Words. A dataset, RICO-PW, of screenshots with Pixel-Words annotations is built based on the public RICO dataset, which will be released to help to address the lack of high-quality training data in this area. We train a detector to extract Pixel-Words from screenshots on this dataset and achieve metadata-free GUI understanding during inference. We conduct experiments and show that Pixel-Words can be well extracted on RICO-PW and well generalized to a new dataset, P2S-UI, collected by ourselves. The effectiveness of PW2SS is further verified in the GUI understanding tasks including relation prediction, clickability prediction, screen retrieval, and app type classification.
Unsupervised Visual Representation Learning by Tracking Patches in Video
May 06, 2021
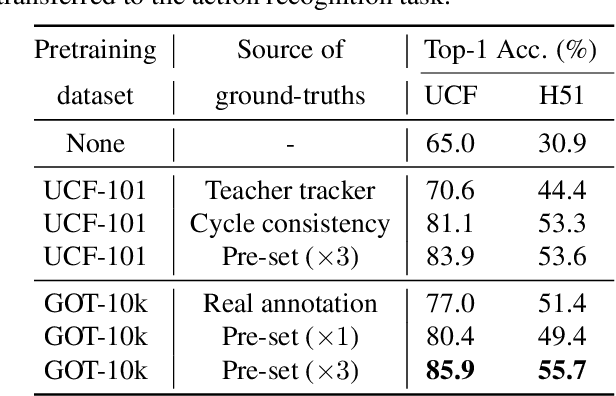
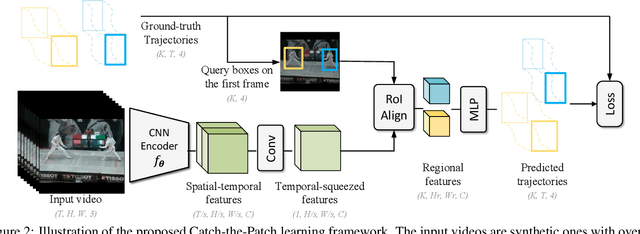
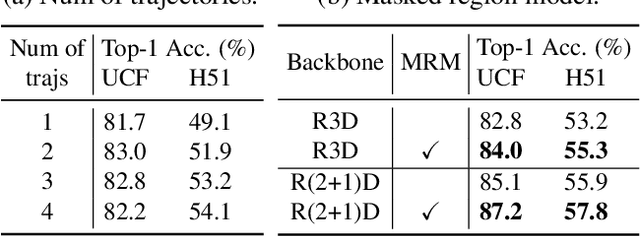
Inspired by the fact that human eyes continue to develop tracking ability in early and middle childhood, we propose to use tracking as a proxy task for a computer vision system to learn the visual representations. Modelled on the Catch game played by the children, we design a Catch-the-Patch (CtP) game for a 3D-CNN model to learn visual representations that would help with video-related tasks. In the proposed pretraining framework, we cut an image patch from a given video and let it scale and move according to a pre-set trajectory. The proxy task is to estimate the position and size of the image patch in a sequence of video frames, given only the target bounding box in the first frame. We discover that using multiple image patches simultaneously brings clear benefits. We further increase the difficulty of the game by randomly making patches invisible. Extensive experiments on mainstream benchmarks demonstrate the superior performance of CtP against other video pretraining methods. In addition, CtP-pretrained features are less sensitive to domain gaps than those trained by a supervised action recognition task. When both trained on Kinetics-400, we are pleasantly surprised to find that CtP-pretrained representation achieves much higher action classification accuracy than its fully supervised counterpart on Something-Something dataset. Code is available online: github.com/microsoft/CtP.
S2R-DepthNet: Learning a Generalizable Depth-specific Structural Representation
Apr 02, 2021
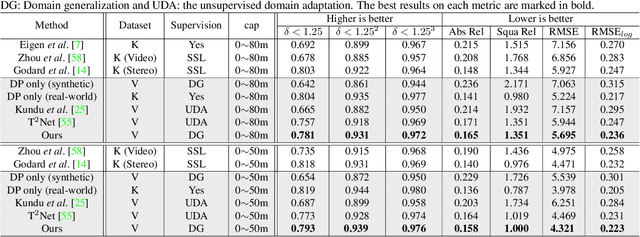
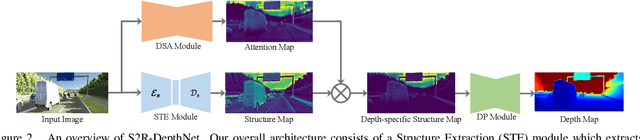
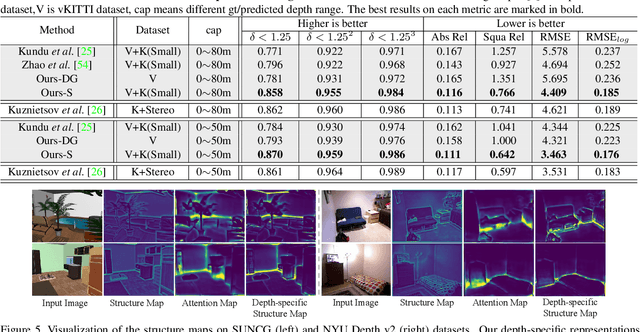
Human can infer the 3D geometry of a scene from a sketch instead of a realistic image, which indicates that the spatial structure plays a fundamental role in understanding the depth of scenes. We are the first to explore the learning of a depth-specific structural representation, which captures the essential feature for depth estimation and ignores irrelevant style information. Our S2R-DepthNet (Synthetic to Real DepthNet) can be well generalized to unseen real-world data directly even though it is only trained on synthetic data. S2R-DepthNet consists of: a) a Structure Extraction (STE) module which extracts a domaininvariant structural representation from an image by disentangling the image into domain-invariant structure and domain-specific style components, b) a Depth-specific Attention (DSA) module, which learns task-specific knowledge to suppress depth-irrelevant structures for better depth estimation and generalization, and c) a depth prediction module (DP) to predict depth from the depth-specific representation. Without access of any real-world images, our method even outperforms the state-of-the-art unsupervised domain adaptation methods which use real-world images of the target domain for training. In addition, when using a small amount of labeled real-world data, we achieve the state-ofthe-art performance under the semi-supervised setting.
Disentanglement-based Cross-Domain Feature Augmentation for Effective Unsupervised Domain Adaptive Person Re-identification
Mar 25, 2021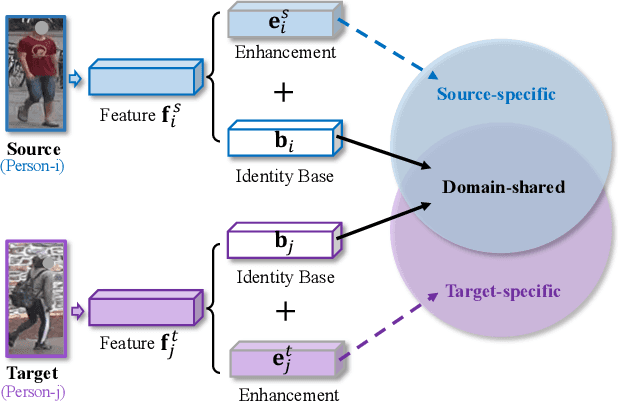
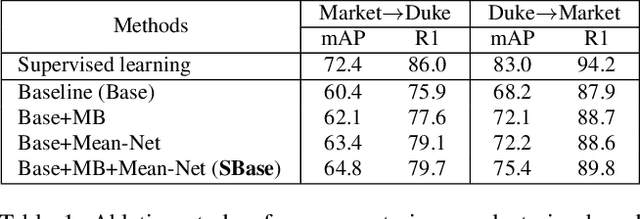
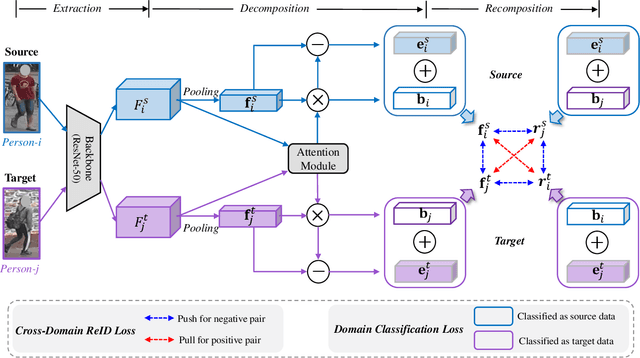
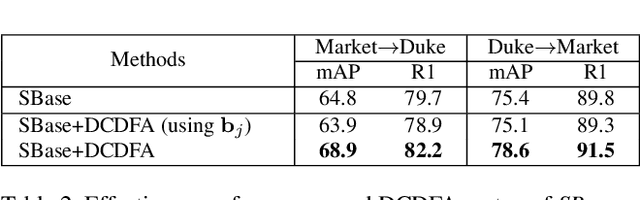
Unsupervised domain adaptive (UDA) person re-identification (ReID) aims to transfer the knowledge from the labeled source domain to the unlabeled target domain for person matching. One challenge is how to generate target domain samples with reliable labels for training. To address this problem, we propose a Disentanglement-based Cross-Domain Feature Augmentation (DCDFA) strategy, where the augmented features characterize well the target and source domain data distributions while inheriting reliable identity labels. Particularly, we disentangle each sample feature into a robust domain-invariant/shared feature and a domain-specific feature, and perform cross-domain feature recomposition to enhance the diversity of samples used in the training, with the constraints of cross-domain ReID loss and domain classification loss. Each recomposed feature, obtained based on the domain-invariant feature (which enables a reliable inheritance of identity) and an enhancement from a domain specific feature (which enables the approximation of real distributions), is thus an "ideal" augmentation. Extensive experimental results demonstrate the effectiveness of our method, which achieves the state-of-the-art performance.
MetaAlign: Coordinating Domain Alignment and Classification for Unsupervised Domain Adaptation
Mar 25, 2021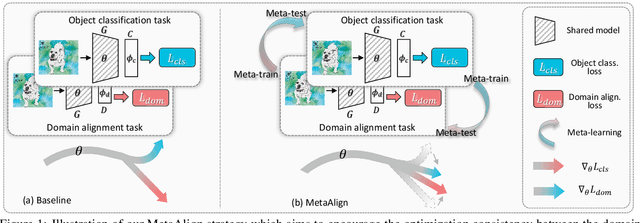
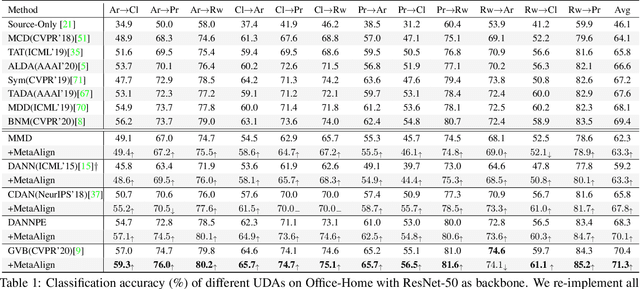
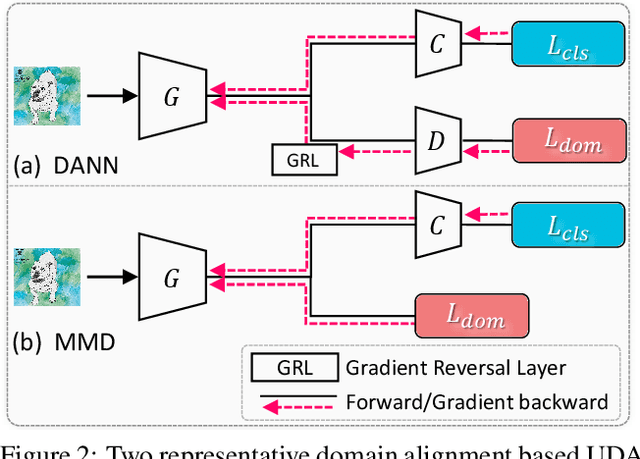
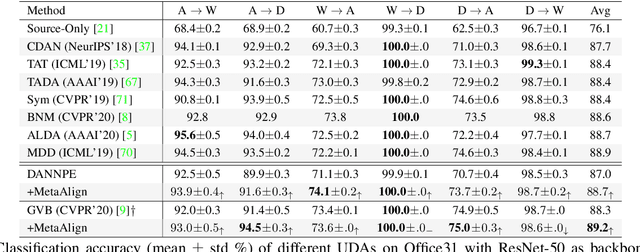
For unsupervised domain adaptation (UDA), to alleviate the effect of domain shift, many approaches align the source and target domains in the feature space by adversarial learning or by explicitly aligning their statistics. However, the optimization objective of such domain alignment is generally not coordinated with that of the object classification task itself such that their descent directions for optimization may be inconsistent. This will reduce the effectiveness of domain alignment in improving the performance of UDA. In this paper, we aim to study and alleviate the optimization inconsistency problem between the domain alignment and classification tasks. We address this by proposing an effective meta-optimization based strategy dubbed MetaAlign, where we treat the domain alignment objective and the classification objective as the meta-train and meta-test tasks in a meta-learning scheme. MetaAlign encourages both tasks to be optimized in a coordinated way, which maximizes the inner product of the gradients of the two tasks during training. Experimental results demonstrate the effectiveness of our proposed method on top of various alignment-based baseline approaches, for tasks of object classification and object detection. MetaAlign helps achieve the state-of-the-art performance.
Re-energizing Domain Discriminator with Sample Relabeling for Adversarial Domain Adaptation
Mar 22, 2021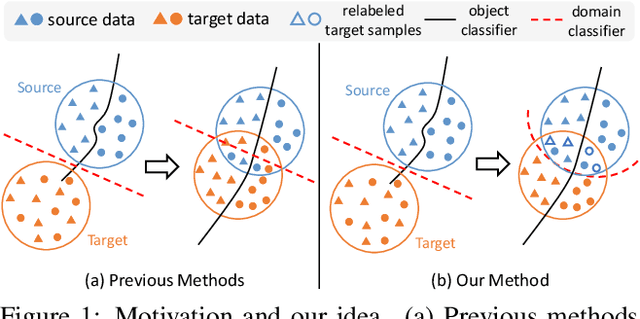
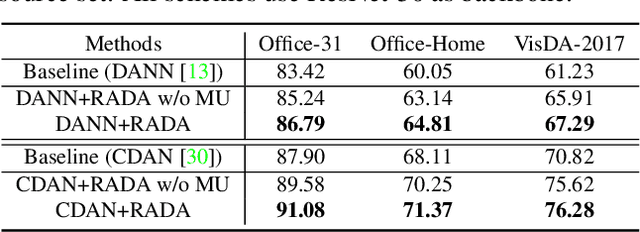
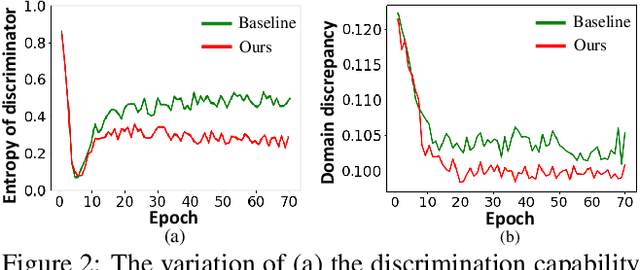
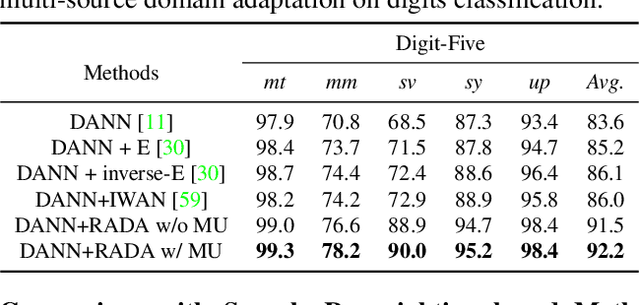
Many unsupervised domain adaptation (UDA) methods exploit domain adversarial training to align the features to reduce domain gap, where a feature extractor is trained to fool a domain discriminator in order to have aligned feature distributions. The discrimination capability of the domain classifier w.r.t the increasingly aligned feature distributions deteriorates as training goes on, thus cannot effectively further drive the training of feature extractor. In this work, we propose an efficient optimization strategy named Re-enforceable Adversarial Domain Adaptation (RADA) which aims to re-energize the domain discriminator during the training by using dynamic domain labels. Particularly, we relabel the well aligned target domain samples as source domain samples on the fly. Such relabeling makes the less separable distributions more separable, and thus leads to a more powerful domain classifier w.r.t. the new data distributions, which in turn further drives feature alignment. Extensive experiments on multiple UDA benchmarks demonstrate the effectiveness and superiority of our RADA.
Rethinking Content and Style: Exploring Bias for Unsupervised Disentanglement
Feb 21, 2021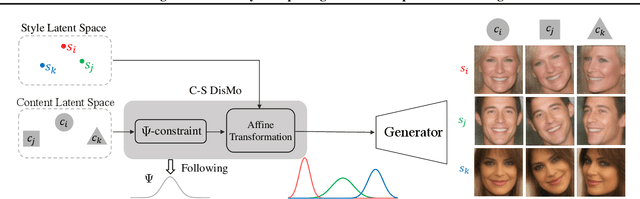
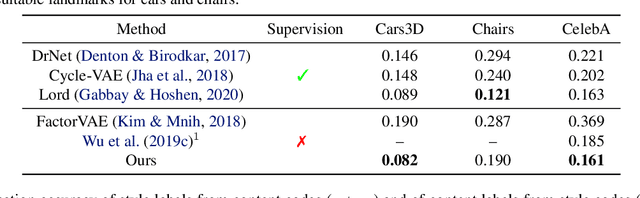


Content and style (C-S) disentanglement intends to decompose the underlying explanatory factors of objects into two independent subspaces. From the unsupervised disentanglement perspective, we rethink content and style and propose a formulation for unsupervised C-S disentanglement based on our assumption that different factors are of different importance and popularity for image reconstruction, which serves as a data bias. The corresponding model inductive bias is introduced by our proposed C-S disentanglement Module (C-S DisMo), which assigns different and independent roles to content and style when approximating the real data distributions. Specifically, each content embedding from the dataset, which encodes the most dominant factors for image reconstruction, is assumed to be sampled from a shared distribution across the dataset. The style embedding for a particular image, encoding the remaining factors, is used to customize the shared distribution through an affine transformation. The experiments on several popular datasets demonstrate that our method achieves the state-of-the-art unsupervised C-S disentanglement, which is comparable or even better than supervised methods. We verify the effectiveness of our method by downstream tasks: domain translation and single-view 3D reconstruction. Project page at https://github.com/xrenaa/CS-DisMo.
Do Generative Models Know Disentanglement? Contrastive Learning is All You Need
Feb 21, 2021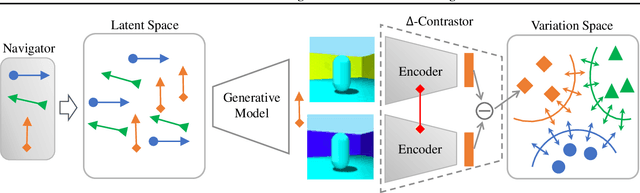
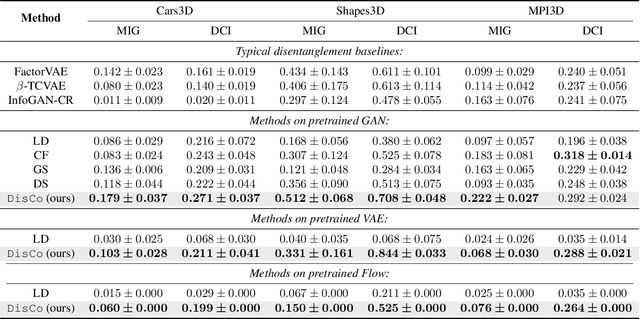
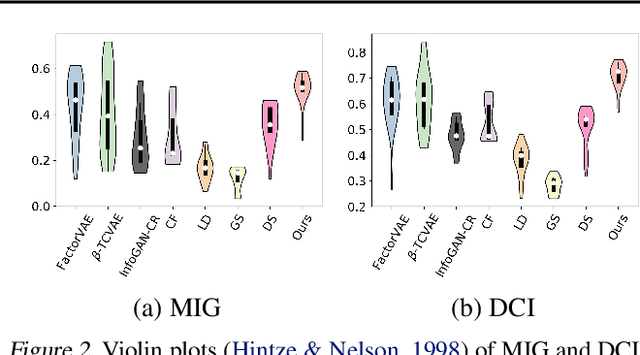
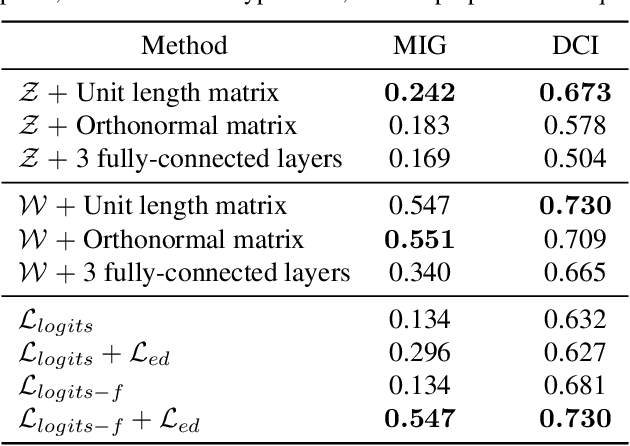
Disentangled generative models are typically trained with an extra regularization term, which encourages the traversal of each latent factor to make a distinct and independent change at the cost of generation quality. When traversing the latent space of generative models trained without the disentanglement term, the generated samples show semantically meaningful change, raising the question: do generative models know disentanglement? We propose an unsupervised and model-agnostic method: Disentanglement via Contrast (DisCo) in the Variation Space. DisCo consists of: (i) a Navigator providing traversal directions in the latent space, and (ii) a $\Delta$-Contrastor composed of two shared-weight Encoders, which encode image pairs along these directions to disentangled representations respectively, and a difference operator to map the encoded representations to the Variation Space. We propose two more key techniques for DisCo: entropy-based domination loss to make the encoded representations more disentangled and the strategy of flipping hard negatives to address directions with the same semantic meaning. By optimizing the Navigator to discover disentangled directions in the latent space and Encoders to extract disentangled representations from images with Contrastive Learning, DisCo achieves the state-of-the-art disentanglement given pretrained non-disentangled generative models, including GAN, VAE, and Flow. Project page at https://github.com/xrenaa/DisCo.
GroupifyVAE: from Group-based Definition to VAE-based Unsupervised Representation Disentanglement
Feb 20, 2021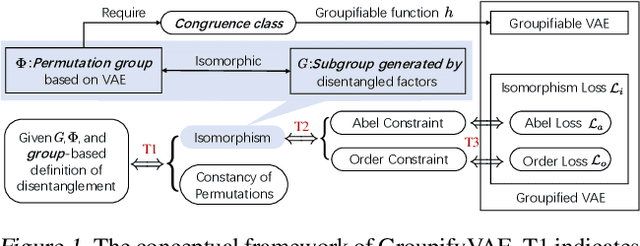
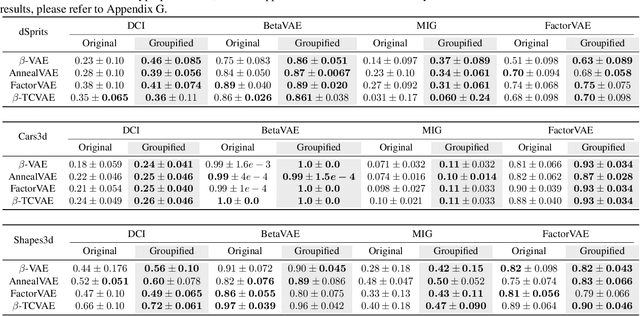
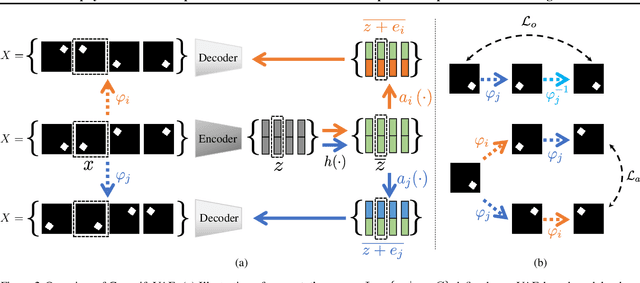
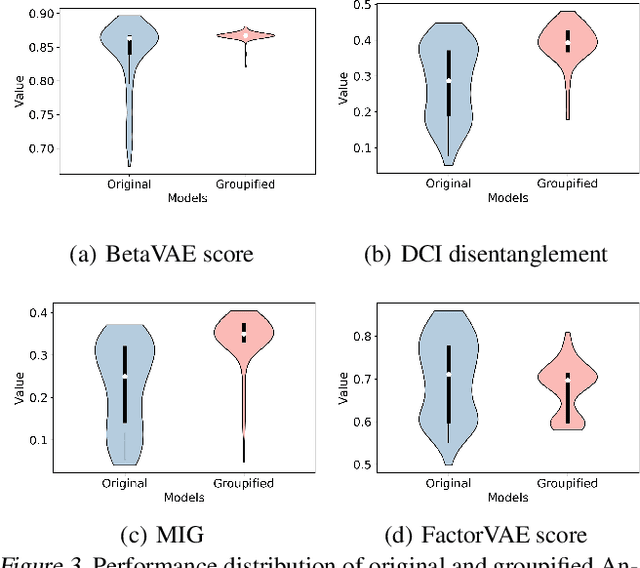
The key idea of the state-of-the-art VAE-based unsupervised representation disentanglement methods is to minimize the total correlation of the latent variable distributions. However, it has been proved that VAE-based unsupervised disentanglement can not be achieved without introducing other inductive bias. In this paper, we address VAE-based unsupervised disentanglement by leveraging the constraints derived from the Group Theory based definition as the non-probabilistic inductive bias. More specifically, inspired by the nth dihedral group (the permutation group for regular polygons), we propose a specific form of the definition and prove its two equivalent conditions: isomorphism and "the constancy of permutations". We further provide an implementation of isomorphism based on two Group constraints: the Abel constraint for the exchangeability and Order constraint for the cyclicity. We then convert them into a self-supervised training loss that can be incorporated into VAE-based models to bridge their gaps from the Group Theory based definition. We train 1800 models covering the most prominent VAE-based models on five datasets to verify the effectiveness of our method. Compared to the original models, the Groupidied VAEs consistently achieve better mean performance with smaller variances, and make meaningful dimensions controllable.