 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Topological Improvement of the Overall Performance of Sparse Evolutionary Training: Motif-Based Structural Optimization of Sparse MLPs Project
Jun 10, 2025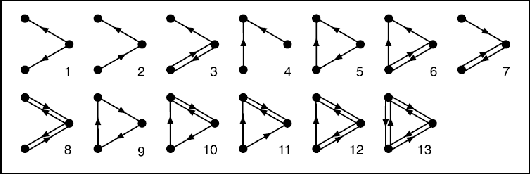

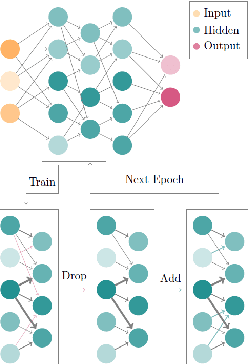
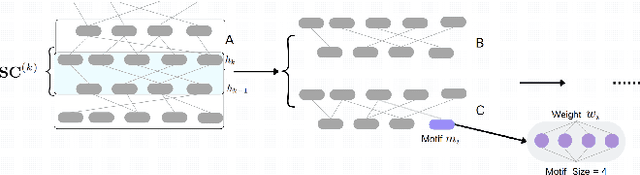
Deep Neural Networks (DNNs) have been proven to be exceptionally effective and have been applied across diverse domains within deep learning. However, as DNN models increase in complexity, the demand for reduced computational costs and memory overheads has become increasingly urgent. Sparsity has emerged as a leading approach in this area. The robustness of sparse Multi-layer Perceptrons (MLPs) for supervised feature selection, along with the application of Sparse Evolutionary Training (SET), illustrates the feasibility of reducing computational costs without compromising accuracy. Moreover, it is believed that the SET algorithm can still be improved through a structural optimization method called motif-based optimization, with potential efficiency gains exceeding 40% and a performance decline of under 4%. This research investigates whether the structural optimization of Sparse Evolutionary Training applied to Multi-layer Perceptrons (SET-MLP) can enhance performance and to what extent this improvement can be achieved.
S2R-DepthNet: Learning a Generalizable Depth-specific Structural Representation
Apr 02, 2021
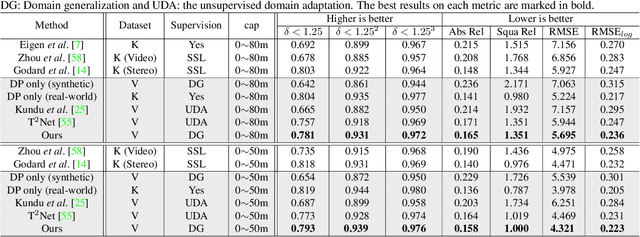
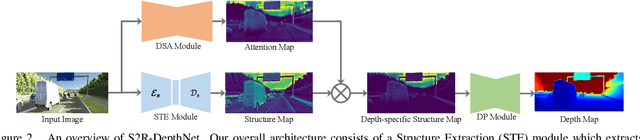
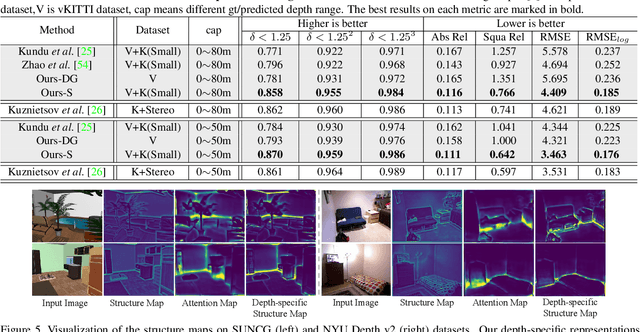
Human can infer the 3D geometry of a scene from a sketch instead of a realistic image, which indicates that the spatial structure plays a fundamental role in understanding the depth of scenes. We are the first to explore the learning of a depth-specific structural representation, which captures the essential feature for depth estimation and ignores irrelevant style information. Our S2R-DepthNet (Synthetic to Real DepthNet) can be well generalized to unseen real-world data directly even though it is only trained on synthetic data. S2R-DepthNet consists of: a) a Structure Extraction (STE) module which extracts a domaininvariant structural representation from an image by disentangling the image into domain-invariant structure and domain-specific style components, b) a Depth-specific Attention (DSA) module, which learns task-specific knowledge to suppress depth-irrelevant structures for better depth estimation and generalization, and c) a depth prediction module (DP) to predict depth from the depth-specific representation. Without access of any real-world images, our method even outperforms the state-of-the-art unsupervised domain adaptation methods which use real-world images of the target domain for training. In addition, when using a small amount of labeled real-world data, we achieve the state-ofthe-art performance under the semi-supervised setting.
Structure-Aware Residual Pyramid Network for Monocular Depth Estimation
Jul 13, 2019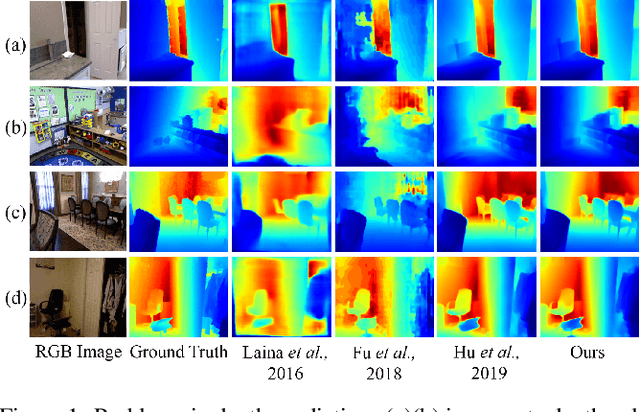
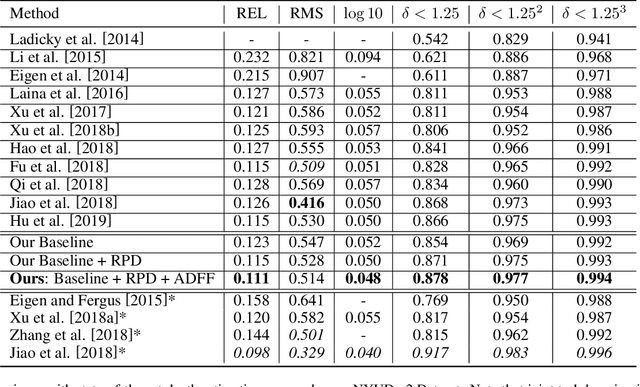
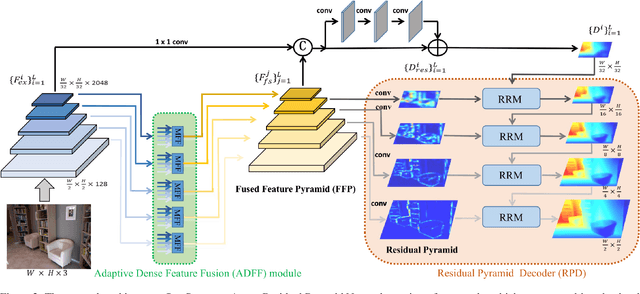
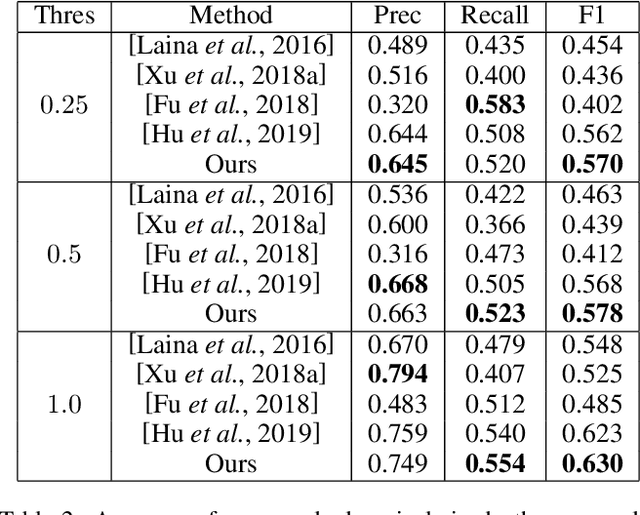
Monocular depth estimation is an essential task for scene understanding. The underlying structure of objects and stuff in a complex scene is critical to recovering accurate and visually-pleasing depth maps. Global structure conveys scene layouts, while local structure reflects shape details. Recently developed approaches based on convolutional neural networks (CNNs) significantly improve the performance of depth estimation. However, few of them take into account multi-scale structures in complex scenes. In this paper, we propose a Structure-Aware Residual Pyramid Network (SARPN) to exploit multi-scale structures for accurate depth prediction. We propose a Residual Pyramid Decoder (RPD) which expresses global scene structure in upper levels to represent layouts, and local structure in lower levels to present shape details. At each level, we propose Residual Refinement Modules (RRM) that predict residual maps to progressively add finer structures on the coarser structure predicted at the upper level. In order to fully exploit multi-scale image features, an Adaptive Dense Feature Fusion (ADFF) module, which adaptively fuses effective features from all scales for inferring structures of each scale, is introduced. Experiment results on the challenging NYU-Depth v2 dataset demonstrate that our proposed approach achieves state-of-the-art performance in both qualitative and quantitative evaluation. The code is available at https://github.com/Xt-Chen/SARPN.