 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeANCHOR: Abductive Network Construction with Hierarchical Orchestration for Reliable Probability Inference in Large Language Models
May 11, 2026A central challenge in large-scale decision-making under incomplete information is estimating reliable probabilities. Recent approaches leverage Large Language Models (LLMs) to generate explanatory factors and elicit coarse-grained probability estimates. Typically, an LLM performs forward abduction to propose factors, each paired with two mutually exclusive attributes, and a Naïve Bayes model is trained over factor combinations to refine the final probabilities. However, sparse factor spaces often yield ``unknown'' outcomes, while expanding factors increases noise and spurious correlations, weakening conditional independence and degrading reliability. To address these limitations, we propose \textsc{Anchor}, an inference framework that orchestrates aggregated Bayesian inference over a hierarchically structured factor space. \textsc{Anchor} first constructs a dense and organized factor space via iterative generation and hierarchical clustering. It then performs context-aware mapping through hierarchical retrieval and refinement, substantially reducing ``unknown'' predictions. Finally, \textsc{Anchor} augments Naïve Bayes with a Causal Bayesian Network to capture latent dependencies among factors, relaxing the strict independence assumption. Experiments show that \textsc{Anchor} markedly reduces ``unknown'' predictions and produces more reliable probability estimates than direct LLM baselines, achieving state-of-the-art performance while significantly reducing time and token overhead.
GCoT-Decoding: Unlocking Deep Reasoning Paths for Universal Question Answering
Apr 08, 2026Chain-of-Thought reasoning can enhance large language models, but it requires manually designed prompts to guide the model. Recently proposed CoT-decoding enables the model to generate CoT-style reasoning paths without prompts, but it is only applicable to problems with fixed answer sets. To address this limitation, we propose a general decoding strategy GCoT-decoding that extends applicability to a broader range of question-answering tasks. GCoT-decoding employs a two-stage branching method combining Fibonacci sampling and heuristic error backtracking to generate candidate decoding paths. It then splits each path into a reasoning span and an answer span to accurately compute path confidence, and finally aggregates semantically similar paths to identify a consensus answer, replacing traditional majority voting. We conduct extensive experiments on six datasets covering both fixed and free QA tasks. Our method not only maintains strong performance on fixed QA but also achieves significant improvements on free QA, demonstrating its generality.
DTCRS: Dynamic Tree Construction for Recursive Summarization
Apr 08, 2026Retrieval-Augmented Generation (RAG) mitigates the hallucination problem of Large Language Models (LLMs) by incorporating external knowledge. Recursive summarization constructs a hierarchical summary tree by clustering text chunks, integrating information from multiple parts of a document to provide evidence for abstractive questions involving multi-step reasoning. However, summary trees often contain a large number of redundant summary nodes, which not only increase construction time but may also negatively impact question answering. Moreover, recursive summarization is not suitable for all types of questions. We introduce DTCRS, a method that dynamically generates summary trees based on document structure and query semantics. DTCRS determines whether a summary tree is necessary by analyzing the question type. It then decomposes the question and uses the embeddings of sub-questions as initial cluster centers, reducing redundant summaries while improving the relevance between summaries and the question. Our approach significantly reduces summary tree construction time and achieves substantial improvements across three QA tasks. Additionally, we investigate the applicability of recursive summarization to different question types, providing valuable insights for future research.
AGSC: Adaptive Granularity and Semantic Clustering for Uncertainty Quantification in Long-text Generation
Apr 08, 2026Large Language Models (LLMs) have demonstrated impressive capabilities in long-form generation, yet their application is hindered by the hallucination problem. While Uncertainty Quantification (UQ) is essential for assessing reliability, the complex structure makes reliable aggregation across heterogeneous themes difficult, in addition, existing methods often overlook the nuance of neutral information and suffer from the high computational cost of fine-grained decomposition. To address these challenges, we propose AGSC (Adaptive Granularity and GMM-based Semantic Clustering), a UQ framework tailored for long-form generation. AGSC first uses NLI neutral probabilities as triggers to distinguish irrelevance from uncertainty, reducing unnecessary computation. It then applies Gaussian Mixture Model (GMM) soft clustering to model latent semantic themes and assign topic-aware weights for downstream aggregation. Experiments on BIO and LongFact show that AGSC achieves state-of-the-art correlation with factuality while reducing inference time by about 60% compared to full atomic decomposition.
I^2R-Net: Intra- and Inter-Human Relation Network for Multi-Person Pose Estimation
Jun 27, 2022
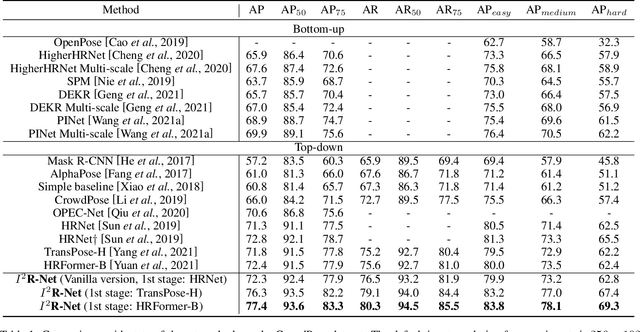
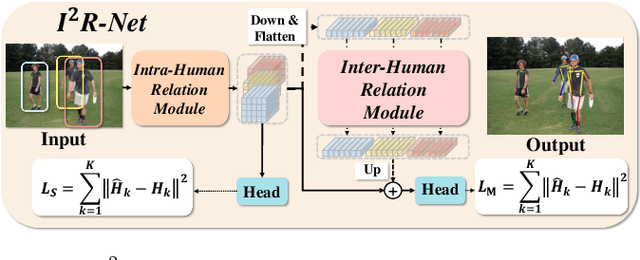
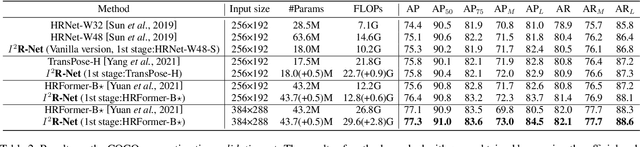
In this paper, we present the Intra- and Inter-Human Relation Networks (I^2R-Net) for Multi-Person Pose Estimation. It involves two basic modules. First, the Intra-Human Relation Module operates on a single person and aims to capture Intra-Human dependencies. Second, the Inter-Human Relation Module considers the relation between multiple instances and focuses on capturing Inter-Human interactions. The Inter-Human Relation Module can be designed very lightweight by reducing the resolution of feature map, yet learn useful relation information to significantly boost the performance of the Intra-Human Relation Module. Even without bells and whistles, our method can compete or outperform current competition winners. We conduct extensive experiments on COCO, CrowdPose, and OCHuman datasets. The results demonstrate that the proposed model surpasses all the state-of-the-art methods. Concretely, the proposed method achieves 77.4% AP on CrowPose dataset and 67.8% AP on OCHuman dataset respectively, outperforming existing methods by a large margin. Additionally, the ablation study and visualization analysis also prove the effectiveness of our model.