 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaWriter: Personalized Handwritten Text Recognition Using Meta-Learned Prompt Tuning
May 26, 2025



Recent advancements in handwritten text recognition (HTR) have enabled the effective conversion of handwritten text to digital formats. However, achieving robust recognition across diverse writing styles remains challenging. Traditional HTR methods lack writer-specific personalization at test time due to limitations in model architecture and training strategies. Existing attempts to bridge this gap, through gradient-based meta-learning, still require labeled examples and suffer from parameter-inefficient fine-tuning, leading to substantial computational and memory overhead. To overcome these challenges, we propose an efficient framework that formulates personalization as prompt tuning, incorporating an auxiliary image reconstruction task with a self-supervised loss to guide prompt adaptation with unlabeled test-time examples. To ensure self-supervised loss effectively minimizes text recognition error, we leverage meta-learning to learn the optimal initialization of the prompts. As a result, our method allows the model to efficiently capture unique writing styles by updating less than 1% of its parameters and eliminating the need for time-intensive annotation processes. We validate our approach on the RIMES and IAM Handwriting Database benchmarks, where it consistently outperforms previous state-of-the-art methods while using 20x fewer parameters. We believe this represents a significant advancement in personalized handwritten text recognition, paving the way for more reliable and practical deployment in resource-constrained scenarios.
Generalizing Spatial Transformers to Projective Geometry with Applications to 2D/3D Registration
Mar 24, 2020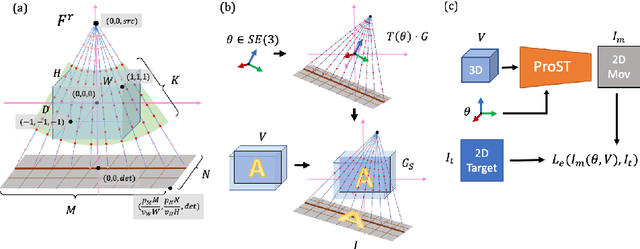
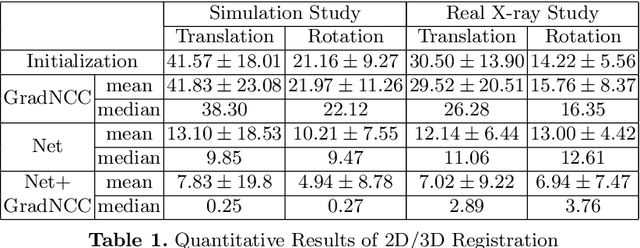
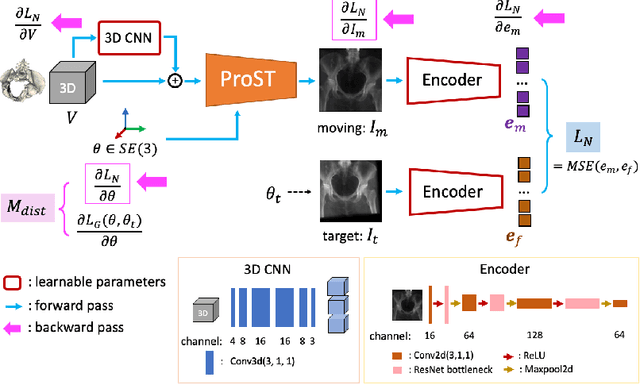
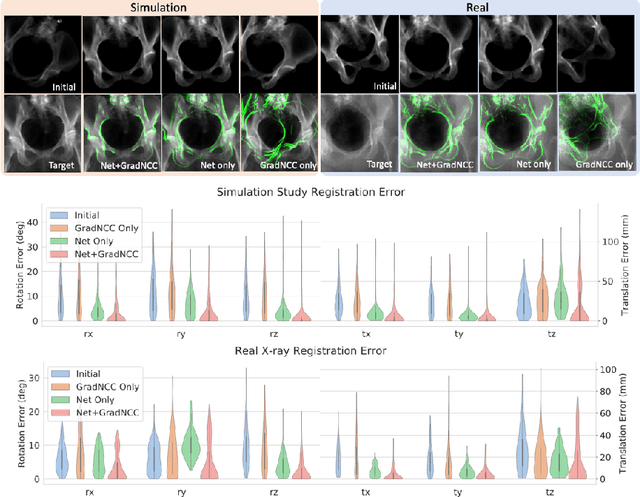
Differentiable rendering is a technique to connect 3D scenes with corresponding 2D images. Since it is differentiable, processes during image formation can be learned. Previous approaches to differentiable rendering focus on mesh-based representations of 3D scenes, which is inappropriate for medical applications where volumetric, voxelized models are used to represent anatomy. We propose a novel Projective Spatial Transformer module that generalizes spatial transformers to projective geometry, thus enabling differentiable volume rendering. We demonstrate the usefulness of this architecture on the example of 2D/3D registration between radiographs and CT scans. Specifically, we show that our transformer enables end-to-end learning of an image processing and projection model that approximates an image similarity function that is convex with respect to the pose parameters, and can thus be optimized effectively using conventional gradient descent. To the best of our knowledge, this is the first time that spatial transformers have been described for projective geometry. The source code will be made public upon publication of this manuscript and we hope that our developments will benefit related 3D research applications.