 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMTrack: State-Aware Mamba for Efficient Temporal Modeling in Visual Tracking
Feb 02, 2026Visual tracking aims to automatically estimate the state of a target object in a video sequence, which is challenging especially in dynamic scenarios. Thus, numerous methods are proposed to introduce temporal cues to enhance tracking robustness. However, conventional CNN and Transformer architectures exhibit inherent limitations in modeling long-range temporal dependencies in visual tracking, often necessitating either complex customized modules or substantial computational costs to integrate temporal cues. Inspired by the success of the state space model, we propose a novel temporal modeling paradigm for visual tracking, termed State-aware Mamba Tracker (SMTrack), providing a neat pipeline for training and tracking without needing customized modules or substantial computational costs to build long-range temporal dependencies. It enjoys several merits. First, we propose a novel selective state-aware space model with state-wise parameters to capture more diverse temporal cues for robust tracking. Second, SMTrack facilitates long-range temporal interactions with linear computational complexity during training. Third, SMTrack enables each frame to interact with previously tracked frames via hidden state propagation and updating, which releases computational costs of handling temporal cues during tracking. Extensive experimental results demonstrate that SMTrack achieves promising performance with low computational costs.
Correlation and Temporal Consistency Analysis of Mono-static and Bi-static ISAC Channels
Nov 05, 2025Integrated Sensing and Communication (ISAC) is critical for efficient spectrum and hardware utilization in future wireless networks like 6G. However, existing channel models lack comprehensive characterization of ISAC-specific dynamics, particularly the relationship between mono-static (co-located Tx/Rx) and bi-static (separated Tx/Rx) sensing configurations. Empirical measurements in dynamic urban microcell (UMi) environments using a 79-GHz FMCW channel sounder help bridge this gap. Two key findings are demonstrated: (1) mono-static and bi-static channels exhibit consistently low instantaneous correlation due to divergent propagation geometries; (2) despite low instantaneous correlation, both channels share unified temporal consistency, evolving predictably under environmental kinematics. These insights, validated across seven real-world scenarios with moving targets/transceivers, inform robust ISAC system design and future standardization.
Frequency-responsive RCS characteristics and scaling implications for ISAC development
Jul 16, 2025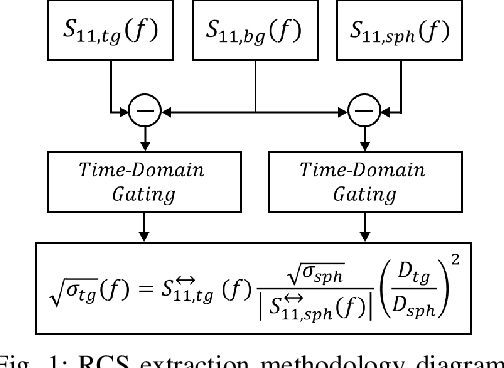
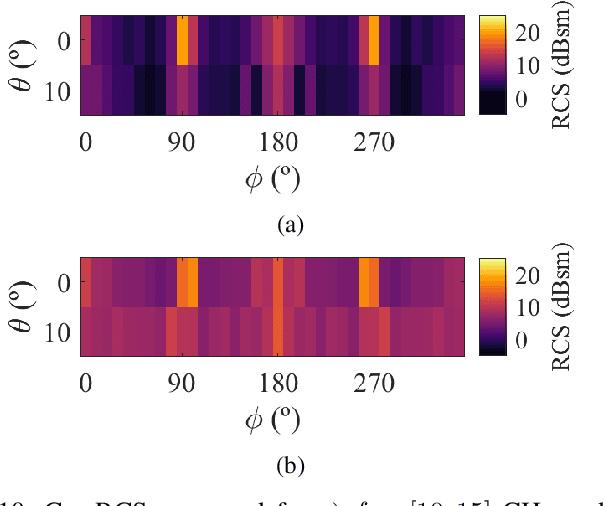
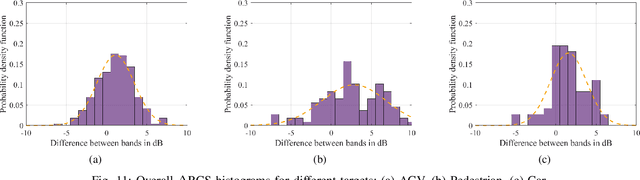
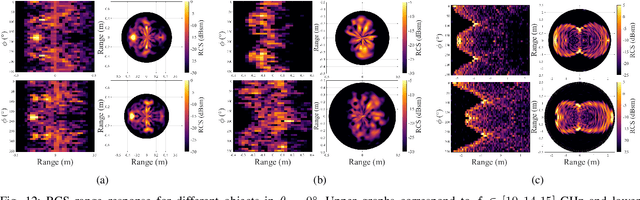
This paper presents an investigation on the Radar Cross-Section (RCS) of various targets, with the objective of analysing how RCS properties vary with frequency. Targets such as an Automated Guided Vehicle (AGV), a pedestrian, and a full-scale car were measured in the frequency bands referred to in industry standards as FR2 and FR3. Measurements were taken in diverse environments, indoors and outdoors, to ensure comprehensive scenario coverage. The methodology employed in RCS extraction performs background subtraction, followed by time-domain gating to isolate the influence of the target. This analysis compares the RCS values and how the points of greatest contribution are distributed across different bands based on the range response of the RCS. Analysis of the results demonstrated how RCS values change with frequency and target shape, providing insights into the electromagnetic behaviour of these targets. Key findings highlight how much scaling RCS values based on frequency and geometry is complex and varies among different types of materials and shapes. These insights are instrumental for advancing sensing systems and enhancing 3GPP channel models, particularly for Integrated Sensing and Communications (ISAC) techniques proposed for 6G standards.
* 6 pages, 12 figures, 3 tables. Accepted for publication at the 2024 IEEE Global Communications Conference (GLOBECOM), WS-02: Workshop on Propagation Channel Models and Evaluation Methodologies for 6G
CA-I2P: Channel-Adaptive Registration Network with Global Optimal Selection
Jun 26, 2025Detection-free methods typically follow a coarse-to-fine pipeline, extracting image and point cloud features for patch-level matching and refining dense pixel-to-point correspondences. However, differences in feature channel attention between images and point clouds may lead to degraded matching results, ultimately impairing registration accuracy. Furthermore, similar structures in the scene could lead to redundant correspondences in cross-modal matching. To address these issues, we propose Channel Adaptive Adjustment Module (CAA) and Global Optimal Selection Module (GOS). CAA enhances intra-modal features and suppresses cross-modal sensitivity, while GOS replaces local selection with global optimization. Experiments on RGB-D Scenes V2 and 7-Scenes demonstrate the superiority of our method, achieving state-of-the-art performance in image-to-point cloud registration.
StruMamba3D: Exploring Structural Mamba for Self-supervised Point Cloud Representation Learning
Jun 26, 2025Recently, Mamba-based methods have demonstrated impressive performance in point cloud representation learning by leveraging State Space Model (SSM) with the efficient context modeling ability and linear complexity. However, these methods still face two key issues that limit the potential of SSM: Destroying the adjacency of 3D points during SSM processing and failing to retain long-sequence memory as the input length increases in downstream tasks. To address these issues, we propose StruMamba3D, a novel paradigm for self-supervised point cloud representation learning. It enjoys several merits. First, we design spatial states and use them as proxies to preserve spatial dependencies among points. Second, we enhance the SSM with a state-wise update strategy and incorporate a lightweight convolution to facilitate interactions between spatial states for efficient structure modeling. Third, our method reduces the sensitivity of pre-trained Mamba-based models to varying input lengths by introducing a sequence length-adaptive strategy. Experimental results across four downstream tasks showcase the superior performance of our method. In addition, our method attains the SOTA 95.1% accuracy on ModelNet40 and 92.75% accuracy on the most challenging split of ScanObjectNN without voting strategy.
Structure-Aware Correspondence Learning for Relative Pose Estimation
Mar 24, 2025Relative pose estimation provides a promising way for achieving object-agnostic pose estimation. Despite the success of existing 3D correspondence-based methods, the reliance on explicit feature matching suffers from small overlaps in visible regions and unreliable feature estimation for invisible regions. Inspired by humans' ability to assemble two object parts that have small or no overlapping regions by considering object structure, we propose a novel Structure-Aware Correspondence Learning method for Relative Pose Estimation, which consists of two key modules. First, a structure-aware keypoint extraction module is designed to locate a set of kepoints that can represent the structure of objects with different shapes and appearance, under the guidance of a keypoint based image reconstruction loss. Second, a structure-aware correspondence estimation module is designed to model the intra-image and inter-image relationships between keypoints to extract structure-aware features for correspondence estimation. By jointly leveraging these two modules, the proposed method can naturally estimate 3D-3D correspondences for unseen objects without explicit feature matching for precise relative pose estimation. Experimental results on the CO3D, Objaverse and LineMOD datasets demonstrate that the proposed method significantly outperforms prior methods, i.e., with 5.7{\deg}reduction in mean angular error on the CO3D dataset.
Learning Shape-Independent Transformation via Spherical Representations for Category-Level Object Pose Estimation
Mar 19, 2025



Category-level object pose estimation aims to determine the pose and size of novel objects in specific categories. Existing correspondence-based approaches typically adopt point-based representations to establish the correspondences between primitive observed points and normalized object coordinates. However, due to the inherent shape-dependence of canonical coordinates, these methods suffer from semantic incoherence across diverse object shapes. To resolve this issue, we innovatively leverage the sphere as a shared proxy shape of objects to learn shape-independent transformation via spherical representations. Based on this insight, we introduce a novel architecture called SpherePose, which yields precise correspondence prediction through three core designs. Firstly, We endow the point-wise feature extraction with SO(3)-invariance, which facilitates robust mapping between camera coordinate space and object coordinate space regardless of rotation transformation. Secondly, the spherical attention mechanism is designed to propagate and integrate features among spherical anchors from a comprehensive perspective, thus mitigating the interference of noise and incomplete point cloud. Lastly, a hyperbolic correspondence loss function is designed to distinguish subtle distinctions, which can promote the precision of correspondence prediction. Experimental results on CAMERA25, REAL275 and HouseCat6D benchmarks demonstrate the superior performance of our method, verifying the effectiveness of spherical representations and architectural innovations.
State Space Model Meets Transformer: A New Paradigm for 3D Object Detection
Mar 19, 2025



DETR-based methods, which use multi-layer transformer decoders to refine object queries iteratively, have shown promising performance in 3D indoor object detection. However, the scene point features in the transformer decoder remain fixed, leading to minimal contributions from later decoder layers, thereby limiting performance improvement. Recently, State Space Models (SSM) have shown efficient context modeling ability with linear complexity through iterative interactions between system states and inputs. Inspired by SSMs, we propose a new 3D object DEtection paradigm with an interactive STate space model (DEST). In the interactive SSM, we design a novel state-dependent SSM parameterization method that enables system states to effectively serve as queries in 3D indoor detection tasks. In addition, we introduce four key designs tailored to the characteristics of point cloud and SSM: The serialization and bidirectional scanning strategies enable bidirectional feature interaction among scene points within the SSM. The inter-state attention mechanism models the relationships between state points, while the gated feed-forward network enhances inter-channel correlations. To the best of our knowledge, this is the first method to model queries as system states and scene points as system inputs, which can simultaneously update scene point features and query features with linear complexity. Extensive experiments on two challenging datasets demonstrate the effectiveness of our DEST-based method. Our method improves the GroupFree baseline in terms of AP50 on ScanNet V2 (+5.3) and SUN RGB-D (+3.2) datasets. Based on the VDETR baseline, Our method sets a new SOTA on the ScanNetV2 and SUN RGB-D datasets.
DN-4DGS: Denoised Deformable Network with Temporal-Spatial Aggregation for Dynamic Scene Rendering
Oct 17, 2024



Dynamic scenes rendering is an intriguing yet challenging problem. Although current methods based on NeRF have achieved satisfactory performance, they still can not reach real-time levels. Recently, 3D Gaussian Splatting (3DGS) has gar?nered researchers attention due to their outstanding rendering quality and real?time speed. Therefore, a new paradigm has been proposed: defining a canonical 3D gaussians and deforming it to individual frames in deformable fields. How?ever, since the coordinates of canonical 3D gaussians are filled with noise, which can transfer noise into the deformable fields, and there is currently no method that adequately considers the aggregation of 4D information. Therefore, we pro?pose Denoised Deformable Network with Temporal-Spatial Aggregation for Dy?namic Scene Rendering (DN-4DGS). Specifically, a Noise Suppression Strategy is introduced to change the distribution of the coordinates of the canonical 3D gaussians and suppress noise. Additionally, a Decoupled Temporal-Spatial Ag?gregation Module is designed to aggregate information from adjacent points and frames. Extensive experiments on various real-world datasets demonstrate that our method achieves state-of-the-art rendering quality under a real-time level.
MotionGS: Exploring Explicit Motion Guidance for Deformable 3D Gaussian Splatting
Oct 10, 2024



Dynamic scene reconstruction is a long-term challenge in the field of 3D vision. Recently, the emergence of 3D Gaussian Splatting has provided new insights into this problem. Although subsequent efforts rapidly extend static 3D Gaussian to dynamic scenes, they often lack explicit constraints on object motion, leading to optimization difficulties and performance degradation. To address the above issues, we propose a novel deformable 3D Gaussian splatting framework called MotionGS, which explores explicit motion priors to guide the deformation of 3D Gaussians. Specifically, we first introduce an optical flow decoupling module that decouples optical flow into camera flow and motion flow, corresponding to camera movement and object motion respectively. Then the motion flow can effectively constrain the deformation of 3D Gaussians, thus simulating the motion of dynamic objects. Additionally, a camera pose refinement module is proposed to alternately optimize 3D Gaussians and camera poses, mitigating the impact of inaccurate camera poses. Extensive experiments in the monocular dynamic scenes validate that MotionGS surpasses state-of-the-art methods and exhibits significant superiority in both qualitative and quantitative results. Project page: https://ruijiezhu94.github.io/MotionGS_page